AI大模型:Python交通分析预测可视化系统 大数据毕业设计 Python+Tensorflow+LSTM+Flask+SQLite+Echarts✅
AI大模型:Python交通分析预测可视化系统 大数据毕业设计 Python+Tensorflow+LSTM+Flask+SQLite+Echarts✅
·
博主介绍:✌全网粉丝50W+,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久,累计开发项目作品上万套。凭借丰富的经验与专业实力,已帮助成千上万的学生顺利毕业,选择我们,就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
毕业设计:基于LSTM算法的交通分析预测可视化系统 深度学习 Tensorflow 智慧交通 交通大数据 Flask框架(源码)✅
1、项目介绍
项目介绍
- 数据处理模块:基于Python与Pandas完成交通数据的查询、清洗与预处理,涵盖车流量、车速、道路占有率等核心数据维度,将处理后的数据存入SQLite数据库,为后续预测分析奠定数据基础。
- 预测分析模块:依托TensorFlow框架搭建LSTM深度学习模型,针对车流量、车速、道路占有率三类核心交通指标开展时间序列预测,挖掘交通数据的时序规律,输出精准的未来趋势预测结果。
- 可视化展示模块:通过Echarts可视化库将交通数据及预测结果以趋势图形式呈现,分别展示车流量变化趋势、车速趋势预测、占有率趋势预测,直观呈现数据特征与预测走向,辅助决策判断。
- 系统交互模块:设计注册登录界面,依托Flask框架实现用户身份验证与权限管控,保障系统数据安全;同时搭建前后端交互接口,实现前端可视化界面与后端预测模型、数据库的高效联动。
- 后端支撑模块:以Flask框架构建后端服务,承接数据查询、模型运算、请求响应等核心任务,打通数据处理、模型预测、可视化展示的全流程链路,保障系统稳定运行。
基于LSTM的交通分析预测可视化系统
基于LSTM的交通分析预测可视化项目整合了先进的数据分析技术,利用Python、Pandas进行数据查询与处理,通过LSTM模型预测未来车流量、车速以及道路占有率。
项目采用SQLite作为数据库存储数据,Flask构建后端服务,结合ECharts实现数据的可视化,为用户提供直观、准确的交通预测结果。
所用技术:
python语言 + Tensorflow深度学习 +LSTM算法+ sqlite数据库+ flask框架 +echarts +hmtl
2、项目界面
(1)注册登录
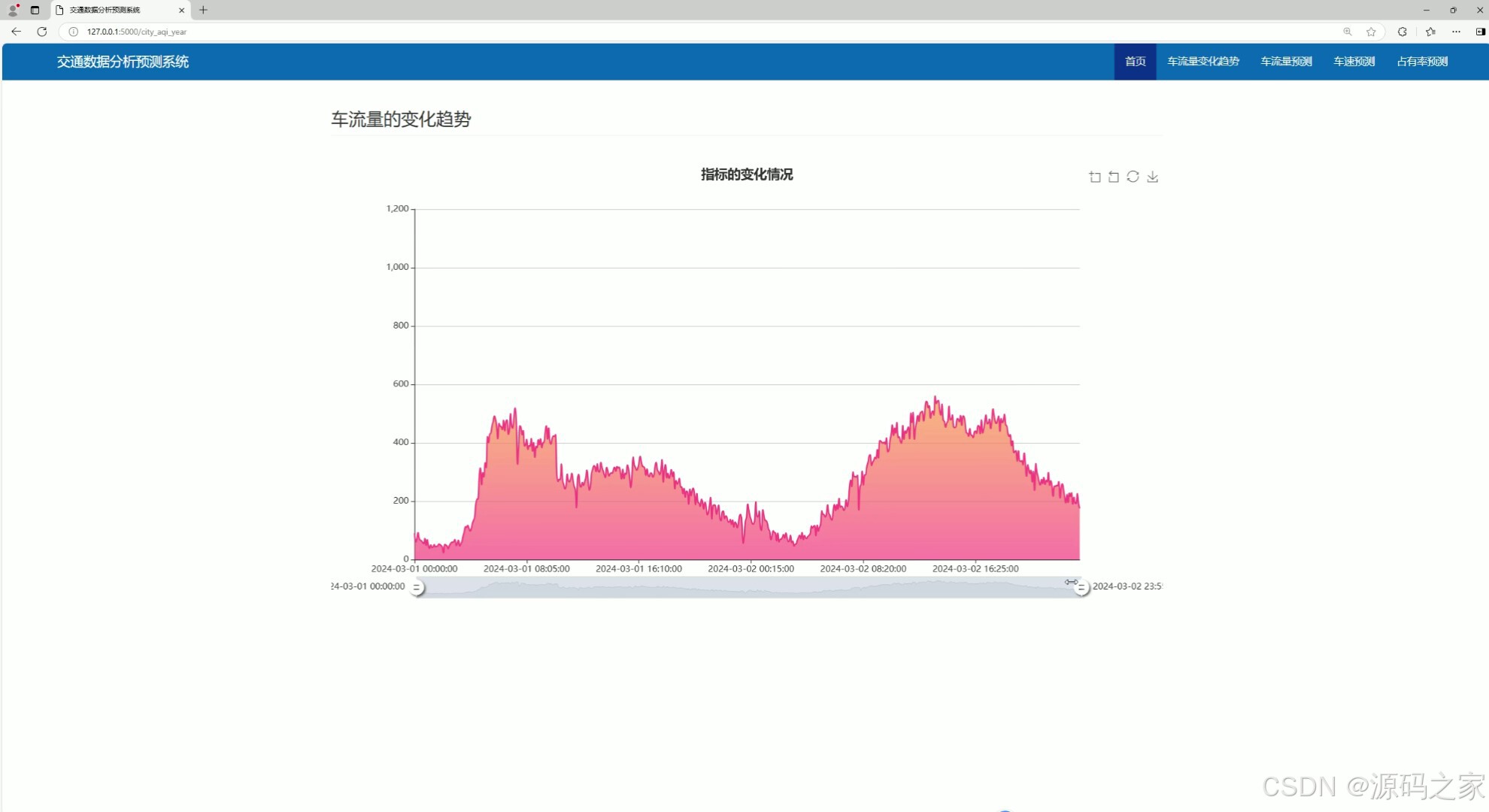
(2)车流量的变化趋势
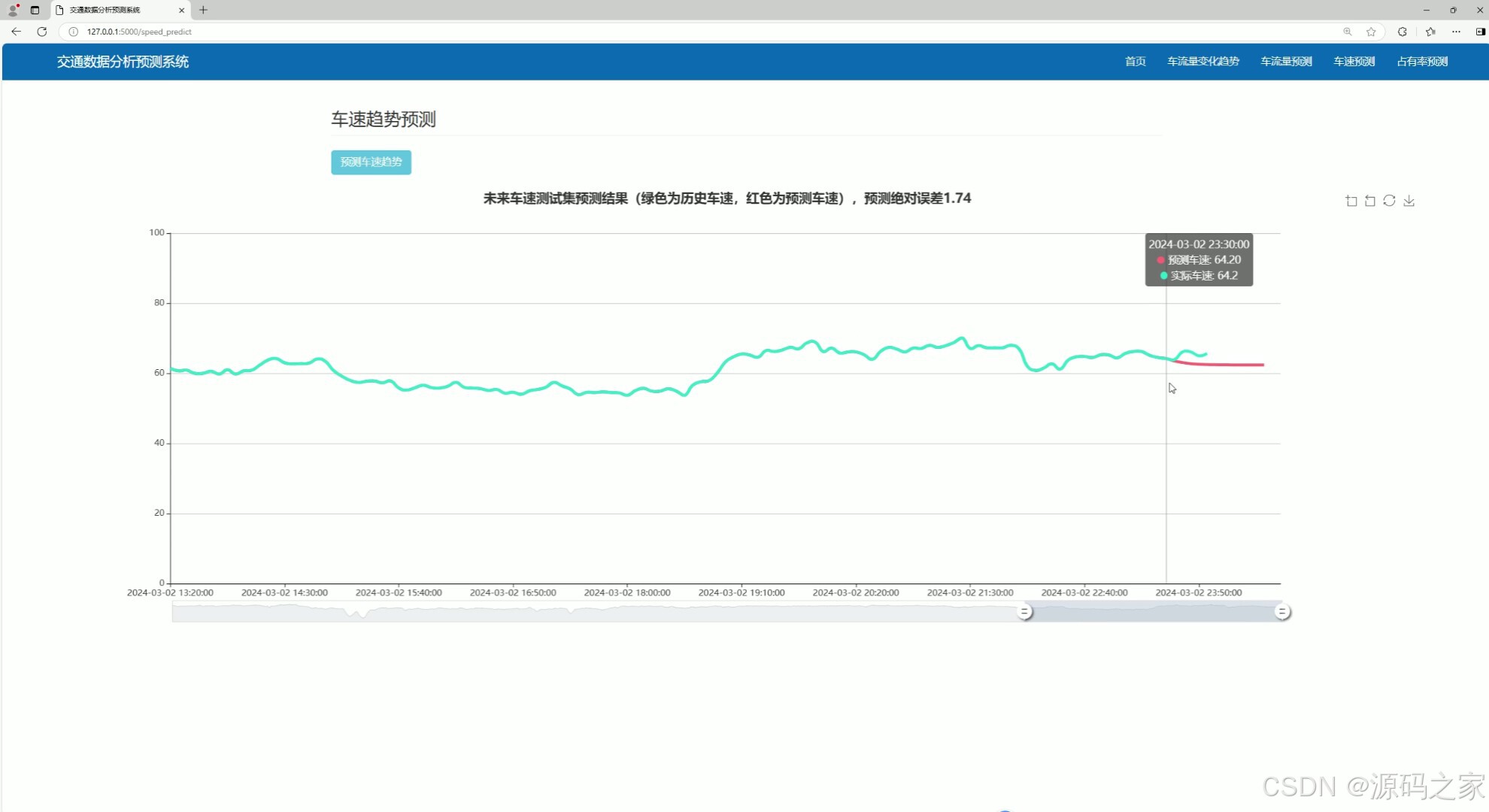
(3)车速趋势预测
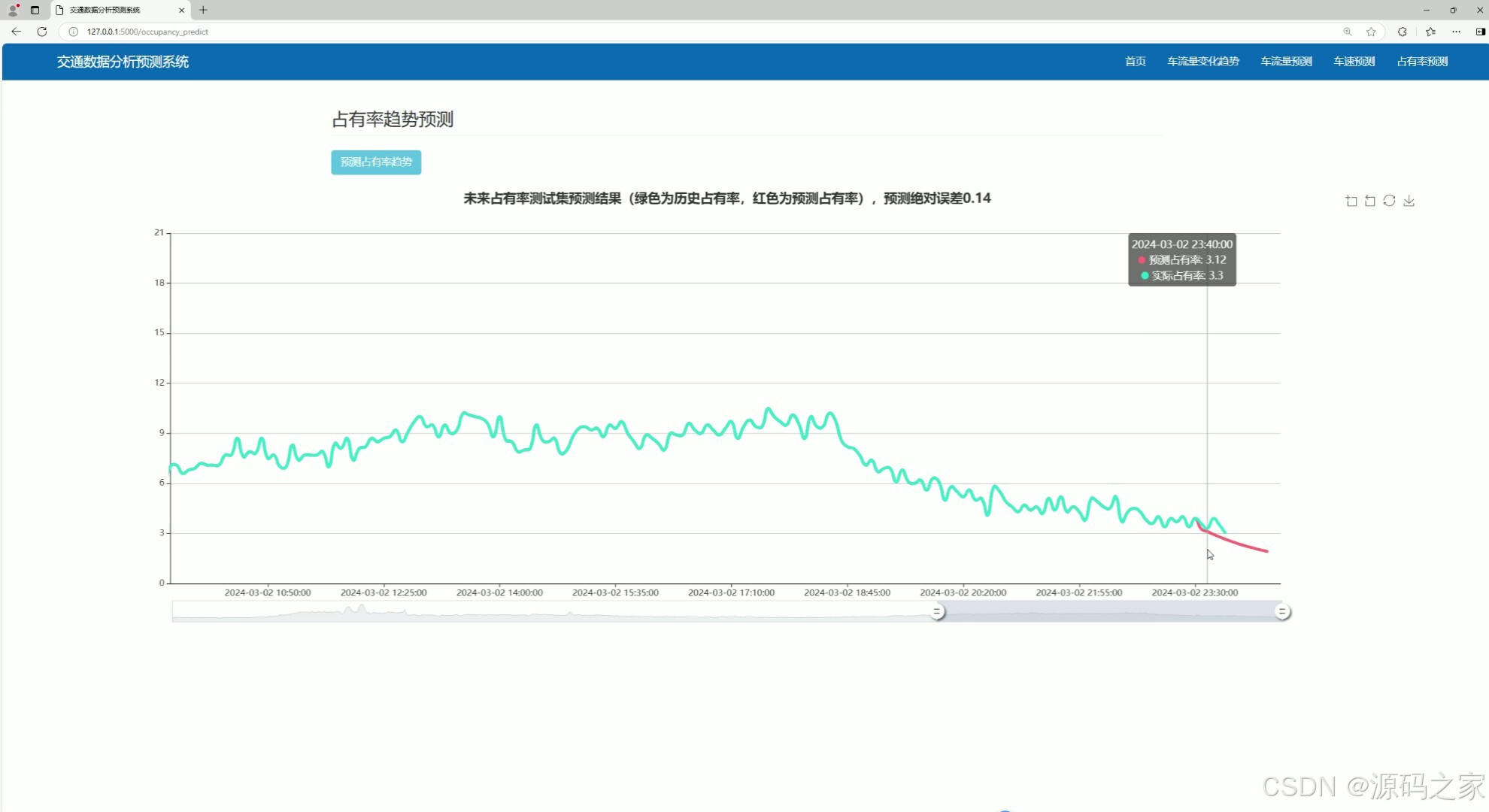
(4)占有率趋势预测
3、项目说明
基于LSTM的交通分析预测可视化系统
基于LSTM的交通分析预测可视化项目整合了先进的数据分析技术,利用Python、Pandas进行数据查询与处理,通过LSTM模型预测未来车流量、车速以及道路占有率。
项目采用SQLite作为数据库存储数据,Flask构建后端服务,结合ECharts实现数据的可视化,为用户提供直观、准确的交通预测结果。
所用技术:
python语言 +pandas +LSTM算法+ sqlite数据库+ flask框架 +echarts +hmtl
项目介绍
- 数据处理模块:基于Python与Pandas完成交通数据的查询、清洗与预处理,涵盖车流量、车速、道路占有率等核心数据维度,将处理后的数据存入SQLite数据库,为后续预测分析奠定数据基础。
- 预测分析模块:依托TensorFlow框架搭建LSTM深度学习模型,针对车流量、车速、道路占有率三类核心交通指标开展时间序列预测,挖掘交通数据的时序规律,输出精准的未来趋势预测结果。
- 可视化展示模块:通过Echarts可视化库将交通数据及预测结果以趋势图形式呈现,分别展示车流量变化趋势、车速趋势预测、占有率趋势预测,直观呈现数据特征与预测走向,辅助决策判断。
- 系统交互模块:设计注册登录界面,依托Flask框架实现用户身份验证与权限管控,保障系统数据安全;同时搭建前后端交互接口,实现前端可视化界面与后端预测模型、数据库的高效联动。
- 后端支撑模块:以Flask框架构建后端服务,承接数据查询、模型运算、请求响应等核心任务,打通数据处理、模型预测、可视化展示的全流程链路,保障系统稳定运行。
标题
AI大模型:Python交通分析预测可视化系统 大数据毕业设计 Python+Tensorflow+LSTM+Flask+SQLite+Echarts✅
4、核心代码
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense
import numpy as np
def lstm_model_train_eval(train_data, test_data, future_count):
# 数据转换成适合LSTM模型的格式
def create_dataset(dataset, time_steps=1):
dataX, dataY = [], []
for i in range(len(dataset) - time_steps):
a = dataset[i:(i + time_steps)]
dataX.append(a)
dataY.append(dataset[i + time_steps])
return np.array(dataX), np.array(dataY)
# 设定随机种子,以便重现结果
np.random.seed(7)
# 创建训练集和测试集的数据结构
time_steps = 3 # 这个值需要根据你的数据进行调整
trainX, trainY = create_dataset(train_data, time_steps)
testX, testY = create_dataset(test_data, time_steps)
# 调整数据形状以适应LSTM模型的输入要求 [样本, 时间步, 特征]
trainX = np.reshape(trainX, (trainX.shape[0], time_steps, 1))
testX = np.reshape(testX, (testX.shape[0], time_steps, 1))
# 构建LSTM模型
model = Sequential()
model.add(LSTM(50, input_shape=(time_steps, 1)))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
# 训练模型
model.fit(trainX, trainY, epochs=10, batch_size=1, verbose=2)
# model.fit(trainX, trainY, epochs=2, batch_size=1, verbose=2)
# 预测未来
testPredict = model.predict(testX)
# 预测
future_predictions = []
current_batch = testX[-1].reshape((1, time_steps, 1))
for i in range(future_count):
future_pred = model.predict(current_batch)[0, 0]
future_predictions.append(future_pred)
current_batch = np.concatenate((current_batch[:, 1:, :], np.array([[[future_pred]]])), axis=1)
return testPredict, future_predictions
@app.route('/predict_future_flow')
def predict_future_flow():
df = flow_df.sort_values(by='five_min', ascending=True)
# 数据集划分
train = df[:-5]['flow'].values
test = df[-5:]['flow'].values
# 使用LSTM模型训练和预测
future_count = 12
lstm_predictions, future_predictions = lstm_model_train_eval(train, test, future_count)
lstm_error = mean_absolute_error(test[3:], lstm_predictions)
print('Test MAE: %.3f' % lstm_error)
print("lstm_predictions:", lstm_predictions)
print("lstm_predictions的type:", type(lstm_predictions))
lstm_error1 = mean_absolute_error(test[3:], lstm_predictions)
lstm_error = float(lstm_error1)
print('Test MAE: %.3f' % lstm_error1)
# 格式化预测结果和时间序列
future_x = lstm_predictions.flatten().tolist()
print("future_x:", future_x)
print("future_x", type(future_x))
all_time = df['five_min'].values.tolist()
print("all_time:", all_time)
print("all_time的type:", type(all_time))
all_time = df['five_min'].astype(str).values.tolist()
all_data = df['flow'].values.tolist() + [None] * future_count
future_predictions_float = [float(val) for val in future_predictions]
add_predict = list(train) + future_predictions_float
# all_time_truncated = [t // 1000 for t in all_time]
all_data = [str(i) for i in all_data]
add_predict = [str(i) for i in add_predict]
print('all_time==> ',all_time+ ['未来{}日'.format(i + 1) for i in range(future_count - 3)])
print('all_data==> ',all_data)
print('add_predict==> ',add_predict)
print('test_count==> ',future_count - 3)
print('error==> ',lstm_error)
# 返回预测结果
return jsonify({'all_time': all_time+ ['未来{}日'.format(i + 1) for i in range(future_count - 3)],
'all_data': all_data,
'add_predict': add_predict,
'test_count': future_count - 3,
'error': lstm_error})
@app.route('/predict_future_speed')
def predict_future_speed():
df = speed_df.sort_values(by='five_min', ascending=True)
# 数据集划分
train = df[:-5]['speed'].values
test = df[-5:]['speed'].values
# 使用LSTM模型训练和预测
future_count = 12
lstm_predictions, future_predictions = lstm_model_train_eval(train, test, future_count)
lstm_error = mean_absolute_error(test[3:], lstm_predictions)
print('Test MAE: %.3f' % lstm_error)
print("lstm_predictions:", lstm_predictions)
print("lstm_predictions的type:", type(lstm_predictions))
lstm_error1 = mean_absolute_error(test[3:], lstm_predictions)
lstm_error = float(lstm_error1)
print('Test MAE: %.3f' % lstm_error1)
# 格式化预测结果和时间序列
future_x = lstm_predictions.flatten().tolist()
print("future_x:", future_x)
print("future_x", type(future_x))
all_time = df['five_min'].values.tolist()
print("all_time:", all_time)
print("all_time的type:", type(all_time))
# 格式化预测结果和时间序列
# 格式化预测结果和时间序列
all_time = df['five_min'].astype(str).values.tolist() + ['未来{}日'.format(i + 1) for i in range(future_count - 3)]
all_data = df['speed'].values.tolist() + [None] * future_count
future_predictions_float = [float(val) for val in future_predictions]
add_predict = list(train) + future_predictions_float
# 返回预测结果
return jsonify({'all_time': all_time,
'all_data': all_data,
'add_predict': add_predict,
'test_count': future_count - 3,
'error': lstm_error})
@app.route('/predict_future_occupancy')
def predict_future_temperature():
df = occupancy_df.sort_values(by='five_min', ascending=True)
# 数据集划分
train = df[:-5]['occ'].values
test = df[-5:]['occ'].values
# 使用LSTM模型训练和预测
future_count = 12
lstm_predictions, future_predictions = lstm_model_train_eval(train, test, future_count)
lstm_error = mean_absolute_error(test[3:], lstm_predictions)
print('Test MAE: %.3f' % lstm_error)
print("lstm_predictions:", lstm_predictions)
print("lstm_predictions的type:", type(lstm_predictions))
lstm_error1 = mean_absolute_error(test[3:], lstm_predictions)
lstm_error = float(lstm_error1)
print('Test MAE: %.3f' % lstm_error1)
# 格式化预测结果和时间序列
future_x = lstm_predictions.flatten().tolist()
print("future_x:", future_x)
print("future_x", type(future_x))
all_time = df['five_min'].values.tolist()
print("all_time:", all_time)
print("all_time的type:", type(all_time))
# 格式化预测结果和时间序列
# 格式化预测结果和时间序列
all_time = df['five_min'].astype(str).values.tolist() + ['未来{}日'.format(i + 1) for i in range(future_count - 3)]
all_data = df['occ'].values.tolist() + [None] * future_count
future_predictions_float = [float(val) for val in future_predictions]
add_predict = list(train) + future_predictions_float
# 返回预测结果
return jsonify({'all_time': all_time,
'all_data': all_data,
'add_predict': add_predict,
'test_count': future_count - 3,
'error': lstm_error})
if __name__ == "__main__":
app.run(host='127.0.0.1', debug=True)
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目编程以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻



有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 42
42 0
0- 0



 已为社区贡献42条内容
已为社区贡献42条内容

所有评论(0)