抛弃黑盒!从LoRA到自注意力,Oracle研究员手推Transformer全链路梯度!
这篇论文是一份面向深度学习初学者的硬核教程,旨在揭开 Transformer 模型训练过程中的数学黑盒。它不依赖现成的深度学习框架自动求导功能,而是通过手算推导,展示了 Transformer 架构中各个组件(如自注意力机制、层归一化、LoRA 等)是如何通过反向传播算法计算梯度的。这篇论文通过纯数学的方式,让读者理解数据和误差信号如何在网络中流动,从而帮助读者从底层逻辑上掌握大模型是如何“学习”
这篇论文是一份面向深度学习初学者的硬核教程,旨在揭开 Transformer 模型训练过程中的数学黑盒。它不依赖现成的深度学习框架自动求导功能,而是通过手算推导,展示了 Transformer 架构中各个组件(如自注意力机制、层归一化、LoRA 等)是如何通过反向传播算法计算梯度的。这篇论文通过纯数学的方式,让读者理解数据和误差信号如何在网络中流动,从而帮助读者从底层逻辑上掌握大模型是如何“学习”的。
研究背景与模型框架:
当前深度学习工具极大简化了模型训练,但自动求导掩盖了底层运算逻辑,导致研究者难以深入理解操作对输出的影响,特别是在涉及损失函数微分时。
为了解决该问题,本论文提出了基于向量化推导的 Transformer 反向传播数学框架,不仅给出了完整的梯度解析公式,还证明了某些参数(如 Key 的偏置)在理论上是冗余的。
一、论文基本信息

- 论文标题:Deep learning for pedestrians: backpropagation in Transformers
- 作者姓名与单位:Laurent Boué (Oracle)
- 论文链接:arXiv:2512.23329v1
二、主要贡献与创新
- 全流程手动推导:提供了Transformer架构中所有关键层(Embedding、多头注意力、LayerNorm)的向量化反向传播公式,填补了自动微分工具背后的理论空白。
- 揭示参数特性:通过数学推导证明了自注意力机制中Keys(键)的偏置项梯度恒为零,从理论上解释了为何该参数在实际训练中是“无效”的。
- LoRA梯度解析:详细推导了低秩适应(LoRA)技术的梯度更新公式,从数学角度阐释了为何这种方法能实现参数高效的微调。
- 极简架构参考:设计并分析了一个极简版的GPT-2架构,提供了完整的参数计数逻辑和PyTorch实现细节,便于初学者理解模型构造。
三、研究方法与原理
该论文的核心思路是抛弃自动微分工具的黑盒,回归线性代数基础,通过矩阵微积分手动推导Transformer各组件的前向计算与反向误差传播过程。
【模型结构图】
文中使用表格形式展示了数据流向,具体参考文中 Table 1(自注意力头的数据流)和 Table 2(极简GPT架构的数据流)。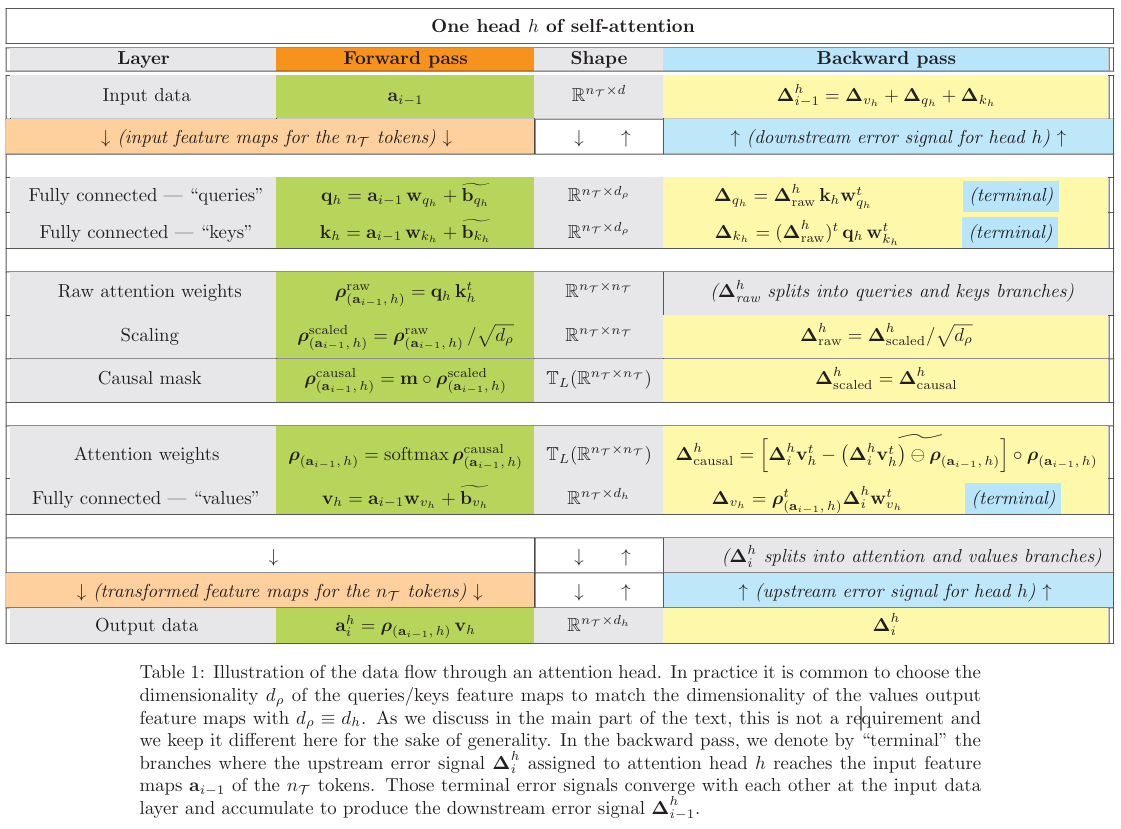
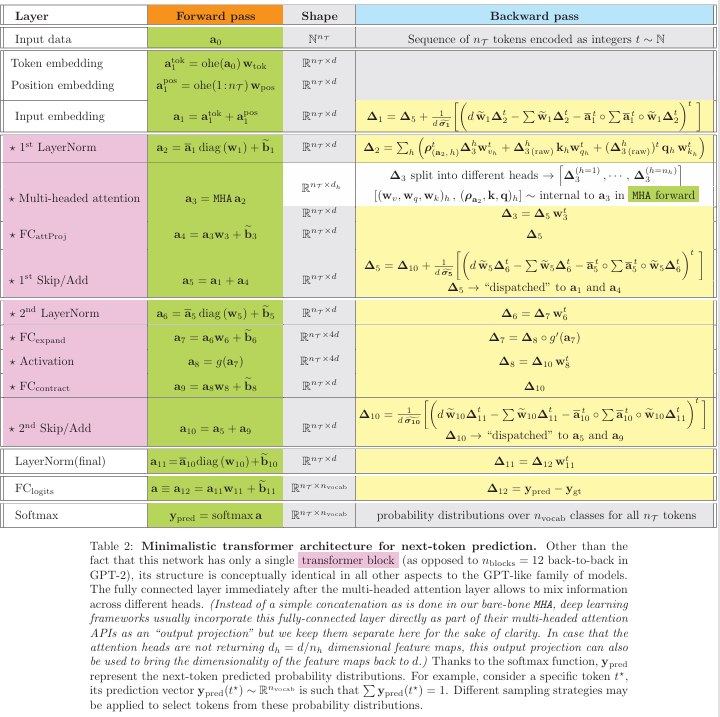
1. 嵌入层 (Embedding Layer) 的解析
论文首先定义了输入数据为Token序列,前向传播中,嵌入层通过One Hot Encoded (OHE) 矩阵与嵌入矩阵 w e m b w_{emb} wemb 相乘来提取特征。公式表示为 a i = ohe ( a i − 1 ) w e m b a_i = \text{ohe}(a_{i-1}) w_{emb} ai=ohe(ai−1)wemb。在反向传播时,误差信号 Δ i \Delta_i Δi 需要传回嵌入矩阵。推导显示,嵌入权重的梯度仅仅是输入数据的OHE矩阵转置与上游误差信号的乘积:
∂ L s e q ∂ w e m b = ohe ( a i − 1 ) t Δ i \frac{\partial L_{seq}}{\partial w_{emb}} = \text{ohe}(a_{i-1})^t \Delta_i ∂wemb∂Lseq=ohe(ai−1)tΔi
这表明只有输入序列中出现的Token对应的嵌入向量才会获得梯度更新。
2. 自注意力机制 (Self-Attention) 的深度推导
这是全最为核心的部分。作者将自注意力分解为查询 (Queries, Q)、键 (Keys, K) 和 值 (Values, V) 三个分支。
在前向传播中,注意力权重矩阵 ρ \rho ρ 的计算包含缩放点积和Softmax归一化:
a i h = softmax ( m ∘ q h k h t d ρ ) v h a^h_i = \text{softmax} \left( m \circ \frac{q_h k_h^t}{\sqrt{d_\rho}} \right) v_h aih=softmax(m∘dρqhkht)vh
其中 m m m 是因果掩码(Causal Mask),保证模型只能看到过去的Token。
在反向传播中,误差流 Δ i h \Delta^h_i Δih 被分为两路。一路直接流向 V V V,另一路流向注意力矩阵 ρ \rho ρ。作者通过推导得出了一个极其重要的结论:由于Softmax函数的平移不变性(Shift Invariance),Keys层偏置项 b k h b^h_k bkh 的梯度恒为零。
∂ L s e q ∂ b k h = 0 \frac{\partial L_{seq}}{\partial b^h_k} = 0 ∂bkh∂Lseq=0
这意味着在标准自注意力机制中,Keys的偏置参数是冗余的。此外,论文还详细描述了KV Cache技术,通过缓存 K K K 和 V V V 的特征图,将推理复杂度从 O ( n T 2 ) O(n_T^2) O(nT2) 降低到 O ( n T ) O(n_T) O(nT),这对自回归生成至关重要。
3. 层归一化 (Layer Normalization) 与 批归一化 (Batch Norm) 的对偶性
论文指出,Layer Normalization 本质上是 Batch Normalization 的“转置”版本。BN是在样本(Batch)维度求均值方差,而LN是在特征(Feature)维度求均值方差。
前向公式为:
a i = a i − 1 − μ ~ σ ~ ∘ w ~ i − 1 + b ~ i − 1 a_i = \frac{a_{i-1} - \tilde{\mu}}{\tilde{\sigma}} \circ \tilde{w}_{i-1} + \tilde{b}_{i-1} ai=σ~ai−1−μ~∘w~i−1+b~i−1
反向传播时,作者利用这种转置对偶性,直接将BN的梯度公式进行转置操作,从而得到了LN的梯度表达,大大简化了推导过程。
4. LoRA (Low-Rank Adaptation) 的梯度流
针对大模型微调,论文分析了LoRA层。LoRA将原本的高维权重矩阵 W W W 分解为两个低秩矩阵 d i − 1 ∈ R f × r d_{i-1} \in \mathbb{R}^{f \times r} di−1∈Rf×r 和 u i − 1 ∈ R r × f u_{i-1} \in \mathbb{R}^{r \times f} ui−1∈Rr×f 的乘积。
前向传播: a i = α a i − 1 d i − 1 u i − 1 a_i = \alpha a_{i-1} d_{i-1} u_{i-1} ai=αai−1di−1ui−1。
反向传播时,利用迹(Trace)的循环性质,推导出误差信号 Δ i \Delta_i Δi 如何分别更新这两个小矩阵:
∂ L s e q ∂ d i − 1 = α a i − 1 t Δ i u i − 1 t \frac{\partial L_{seq}}{\partial d_{i-1}} = \alpha a_{i-1}^t \Delta_i u_{i-1}^t ∂di−1∂Lseq=αai−1tΔiui−1t
∂ L s e q ∂ u i − 1 = α ( a i − 1 d i − 1 ) t Δ i \frac{\partial L_{seq}}{\partial u_{i-1}} = \alpha (a_{i-1} d_{i-1})^t \Delta_i ∂ui−1∂Lseq=α(ai−1di−1)tΔi
这清晰地展示了LoRA如何通过极少量的参数更新来影响整个网络的行为。
四、实验设计与结果分析
需要说明的是,本文是一篇理论推导与教学性质的论文,而非传统的实证研究论文。因此,它没有在大规模数据集(如ImageNet或CommonCrawl)上进行跑分对比,而是构建了一个极简版的GPT架构来验证其推导的正确性并分析模型规模。
1. 极简GPT-2架构设置
论文设计了一个简化的GPT-2模型,具体参数设置如下:
- 嵌入维度 (d): 768
- 上下文长度: 1,024
- 词表大小: 50,257
- Transformer层数: 仅使用 1 层(标准GPT-2 Small为12层)来演示原理。
2. 参数量分析与对比
作者详细计算了该架构的参数数量。对于单层Transformer块,参数量约为 700 万。加上巨大的词表嵌入层(约 3800 万参数),该极简模型的总参数量为 85,120,849。
作者将此与标准 12 层 GPT-2 Small 模型进行了对比:标准模型参数量约为 1.63 亿。这表明,虽然层数增加了11倍,但由于嵌入层参数占比较大,总参数量仅增加了约一倍。
3. LoRA微调的效率验证
为了展示LoRA的高效性,作者计算了若将输出层的全连接层替换为LoRA层后的参数变化。
- 原始全连接层参数量:约 3860 万。
- LoRA层参数量(秩 r=16):仅约 81.6 万。
- 结论:LoRA使得可训练参数量减少了约 98%。这在数值上证明了为何LoRA适合在显存受限的情况下进行大模型微调。
4. 梯度公式汇总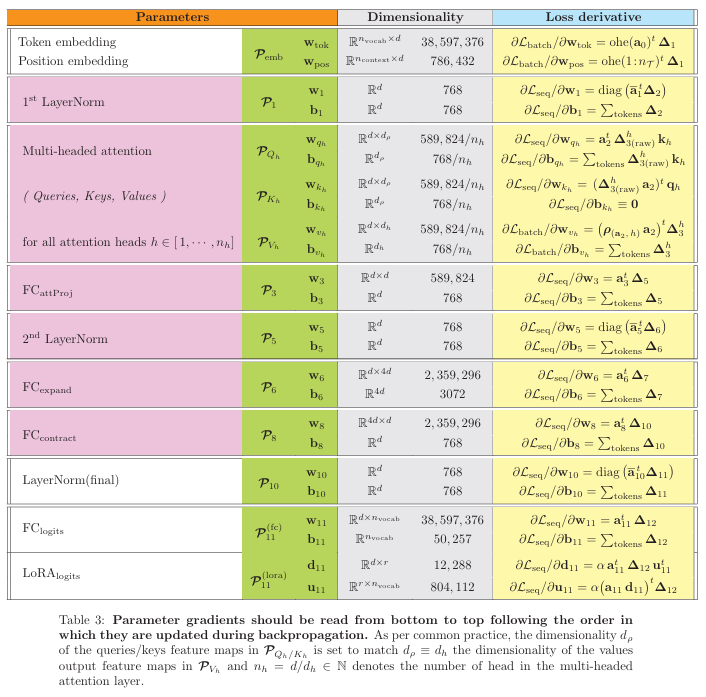
论文在 Table 3 中汇总了所有层的梯度公式。这不仅仅是一个结果表格,更是对全文推导的验证。它清晰地列出了从输出层(Logits)一直反向传播到输入嵌入层所需的每一个数学运算步骤,证明了手动反向传播的可行性。
五、论文结论与评价
本论文通过严谨的数学推导,深入剖析了Transformer模型的内部运作机制。在理论上,它最显著的结论是证明了自注意力机制中Key层的偏置参数对模型输出及梯度更新没有任何贡献,这为模型压缩或结构简化提供了理论依据。同时,通过对LoRA和KV Cache的解析,论文从底层运算角度解释了现代大模型推理加速与高效微调的本质原因。
对于实际应用和后续研究而言,这篇文章极具价值。它不仅是一份针对深度学习初学者的“白盒”指南,帮助开发者跳出API调用的舒适区,去理解梯度消失或爆炸的根本原因;也为底层算子优化(如FlashAttention的开发)提供了清晰的数学蓝图。理解这些梯度流动细节,有助于研究者设计更高效的模型结构或排查极端的数值稳定性问题。
该论文方法的优缺点分析:
- 优点:理论基础极其扎实,公式推导详尽且逻辑自洽;语言风格通俗(正如标题“for pedestrians”所示),将复杂的矩阵微积分通过向量化表达简化,避免了繁琐的索引求和符号;涵盖了LoRA等前沿技术,紧跟时代。
- 缺点:作为一篇理论综述,缺乏大规模真实数据的训练曲线或下游任务的性能评估;极简架构虽然利于理解,但无法完全反映深层网络(如100+层)中可能出现的复杂动力学问题。
批判性讨论与建议:
虽然自动微分工具已经非常成熟,但本文提醒我们“想不写下来就思考,只是自以为在思考”。建议读者在阅读时,不仅仅是浏览公式,而是尝试用代码(如Python/Numpy)复现文中的反向传播过程。这将极大加深对Transformer架构的直觉理解。此外,考虑到文中提到的Key偏置无效性,后续在设计新架构时应默认移除该参数以减少冗余。对于希望深入CUDA编程或底层算子优化的工程师,这篇论文提供的矩阵视角是必读的基础读物。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 15
15 0
0- 0



 已为社区贡献35条内容
已为社区贡献35条内容

所有评论(0)