RAG(七)基于 LangChain + 通义千问构建本地化文档问答系统
·
在大语言模型时代,基于自有文档构建专属问答系统成为企业和开发者的核心需求。本文将手把手教你使用 LangChain 框架结合阿里云通义千问大模型,实现本地化 Word 文档的智能问答 —— 只需上传行业文档,就能精准回答关于文档内容的各类问题,全程无需依赖外部知识库,数据安全可控。
一、核心技术栈与实现思路
在开始编码前,先理清整个文档问答系统的核心逻辑和依赖工具:
- 核心工具:
- LangChain:一站式 LLM 应用开发框架,提供文档加载、切分、检索、链调用等全流程能力;
- Docx2txtLoader:LangChain 内置的 Word 文档加载工具,支持解析.docx 格式文档;
- Chroma:轻量级本地向量数据库,用于存储文档嵌入向量,实现相似度检索;
- DashScopeEmbeddings:阿里云通义千问嵌入模型,将文本转化为可计算相似度的向量;
- ChatOpenAI(兼容模式):通过阿里云 DashScope 接口调用通义千问大模型(qwen-plus);
- python-dotenv:管理环境变量,安全存储 API 密钥。
- 实现流程:
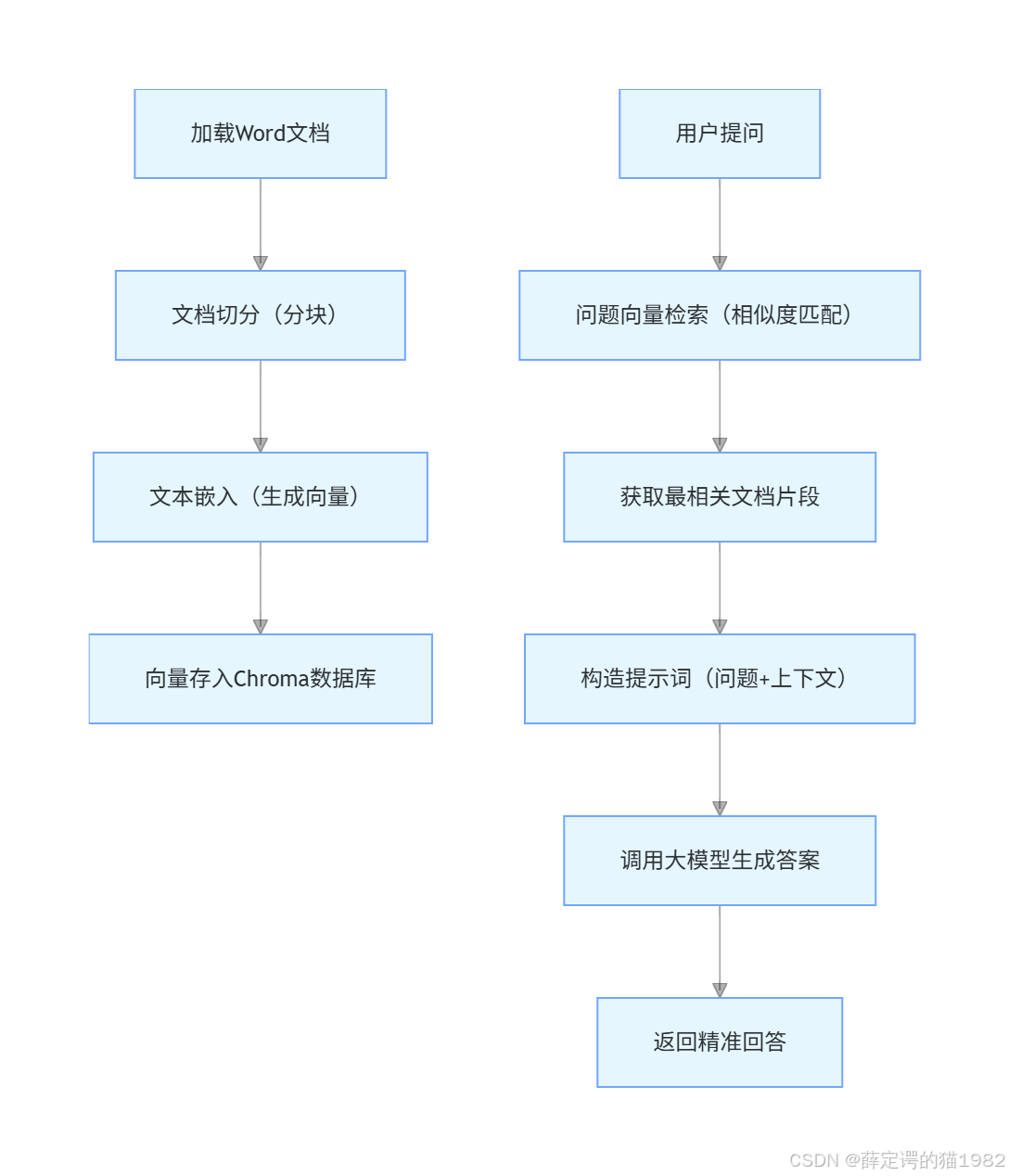
二、完整代码实现与逐行解析
接下来我们分模块拆解代码,同时讲解每个环节的核心作用。
1. 环境准备与依赖安装
首先安装所需依赖包,在终端执行:
pip install langchain langchain-community langchain-core langchain-text-splitters chromadb docx2txt python-dotenv pydantic openai dashscope
然后在项目根目录创建.env文件,存入阿里云通义千问 API 密钥(需提前在阿里云控制台申请):
env
DASHSCOPE_API_KEY=你的通义千问API密钥
2. 完整代码与核心解析
# 1. 导入核心依赖
from langchain_community.document_loaders import Docx2txtLoader # Word文档加载器
from dotenv import load_dotenv # 加载环境变量
from langchain_community.embeddings import DashScopeEmbeddings # 通义千问嵌入模型
from langchain_core.runnables import RunnableLambda, RunnablePassthrough # 链执行工具
from langchain_text_splitters import RecursiveCharacterTextSplitter # 文档切分器
from langchain_community.vectorstores import Chroma # 本地向量数据库
from pydantic import SecretStr # 安全存储密钥
from langchain_core.prompts import ChatPromptTemplate # 提示词模板
from langchain_openai import ChatOpenAI # 大模型调用接口
import os
# 2. 加载环境变量,读取API密钥
load_dotenv()
# 3. 初始化通义千问大模型(兼容OpenAI接口格式)
llm = ChatOpenAI(
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1", # 阿里云兼容接口
model="qwen-plus", # 通义千问增强版模型
api_key=SecretStr(os.environ["DASHSCOPE_API_KEY"]), # 安全读取API密钥
)
# 4. 文档加载与预处理:构建本地知识库
# 4.1 加载Word文档(替换为你的文档路径)
loader = Docx2txtLoader("./行业.docx")
docs = loader.load() # 加载后得到LangChain的Document对象,包含文本内容和元数据
# 4.2 文档切分:解决大模型上下文长度限制
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=300, # 每个文本块300字符
chunk_overlap=30, # 块之间重叠30字符,保证上下文连贯
separators=['\n\n\n\n', ''] # 优先按空行切分,保证语义完整
)
documents = text_splitter.split_documents(docs) # 切分后得到多个小文本块
# 4.3 初始化嵌入模型:将文本转为向量
embeddings = DashScopeEmbeddings(model="text-embedding-v2") # 通义千问嵌入模型v2
# 4.4 向量入库:将切分后的文档存入Chroma本地向量库
db = Chroma.from_documents(
collection_name='demo', # 向量库集合名称,便于管理
documents=documents, # 待入库的文本块
embedding=embeddings, # 使用的嵌入模型
# persist_directory="./chroma_db" # 可选:指定本地存储路径,实现向量库持久化
)
# 5. 相似度检索:从知识库中匹配最相关内容
# 5.1 基础相似度查询(返回前2个最相关文档)
print("基础相似度检索结果:")
print(db.similarity_search("建筑行业的审标系统应用的业务场景有哪几条", k=2))
# 5.2 带相似度得分的查询(分数越小,相似度越高,基于L2距离)
print("\n带得分的检索结果:")
print(db.similarity_search_with_score("建筑行业的审标系统应用的业务场景有哪几条"))
# 5.3 封装检索逻辑为可调用链(便于后续集成)
docs_find = RunnableLambda(db.similarity_search).bind(k=2) # 绑定k=2,固定返回前2条
print("\n封装后的检索链调用结果:")
print(docs_find.invoke("建筑行业的审标系统应用的业务场景有哪几条"))
# 6. 构建问答链:检索+大模型生成答案
# 6.1 定义提示词模板:约束大模型仅基于上下文回答
message = """
仅使用提供的上下文回答下面的问题:
{question}
上下文:
{context}
"""
prompt_template = ChatPromptTemplate([('human', message)]) # 构建Chat格式的提示词
# 6.2 组装问答链:用户问题→检索上下文→构造提示词→调用大模型
chain = {
"question": RunnablePassthrough(), # 透传用户输入的问题
"context": docs_find # 调用检索链获取上下文
} | prompt_template | llm # 按顺序执行:组装参数→渲染提示词→调用大模型
# 6.3 执行问答链,获取最终答案
response = chain.invoke("建筑行业的审标系统应用的业务场景有哪几条")
print("\n最终智能回答:")
print(response.content)
3. 核心代码关键点解析
- 文档切分:
RecursiveCharacterTextSplitter是 LangChain 最常用的文本切分器,chunk_size和chunk_overlap的设置需根据文档内容调整 —— 短文本(如问答库)可设为 200-300,长文本(如技术文档)可设为 500-1000,重叠字符保证切分后语义不割裂; - 向量检索:Chroma 是本地化部署的轻量级向量库,无需额外安装数据库,适合快速原型开发;
similarity_search默认使用余弦相似度,similarity_search_with_score返回的分数越小,代表文档与问题越匹配; - Runnable 链:
RunnablePassthrough实现用户问题的动态透传,RunnableLambda将普通函数(如db.similarity_search)封装为 LangChain 可调用的链,最终通过|运算符实现 “检索→提示词→大模型” 的流水线执行; - 提示词约束:模板中明确要求 “仅使用提供的上下文回答”,避免大模型编造信息,保证答案的准确性和来源可追溯。
三、功能扩展与优化建议
- 向量库持久化:取消代码中
persist_directory的注释,将向量库存储到本地文件夹,避免每次运行都重新加载和嵌入文档,提升效率; - 多格式文档支持:扩展
Docx2txtLoader为UnstructuredFileLoader或PyPDFLoader,支持 PDF、TXT、Markdown 等格式; - 检索策略优化:使用
MMR(最大边际相关性)检索替代单纯的相似度检索,避免返回重复内容,提升回答丰富度; - 错误处理:添加
try-except块,处理文档加载失败、API 调用超时、向量库连接异常等情况,增强代码健壮性; - 界面封装:结合 Streamlit 快速构建可视化界面,实现 “上传文档→输入问题→查看答案” 的一站式操作,降低使用门槛。
四、应用场景与价值
这套方案可广泛应用于:
- 企业内部知识库问答(如规章制度、产品手册、技术文档);
- 行业报告、政策文件的智能解读;
- 个人学习笔记的快速检索与问答;
- 客服机器人的本地化知识库构建。
相比传统的关键词检索,基于向量和大模型的问答系统能理解语义,精准匹配用户的真实需求,大幅提升信息获取效率。
总结
- 本文基于 LangChain + 通义千问实现了本地化 Word 文档问答系统,核心流程为 “文档加载→切分→嵌入→检索→大模型生成答案”;
- 关键技术点包括文本切分的参数设置、向量检索的封装、提示词的约束性设计;
- 该方案可灵活扩展,适配多格式文档和复杂业务场景,兼具实用性和可落地性。
通过这套代码,你可以快速搭建专属的文档问答系统,让大模型成为你的 “私人文档解读助手”,高效挖掘自有文档的价值。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 8
8 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)