如何实现SSE流式输出前端-简单实现知识库agent模型, 让你深入了解SSE到底是什么
对接收到的数据块进行清洗定位和分发1. 清洗: 寻找有效数据行SSE 协议规定,一次完整的数据推送(Event)可能包含多行(如。
什么是流式输出?
流式输出就和它的名字一样, 呈现一种水流形式一点一点进行输出, 它是服务端对客户端的一种响应形式, 这样输出使得响应数据可以一点点加载到页面上, 避免用户等待很长时间, 极大提高了用户体验, 本文主要讲前端如何实现SSE输出加载
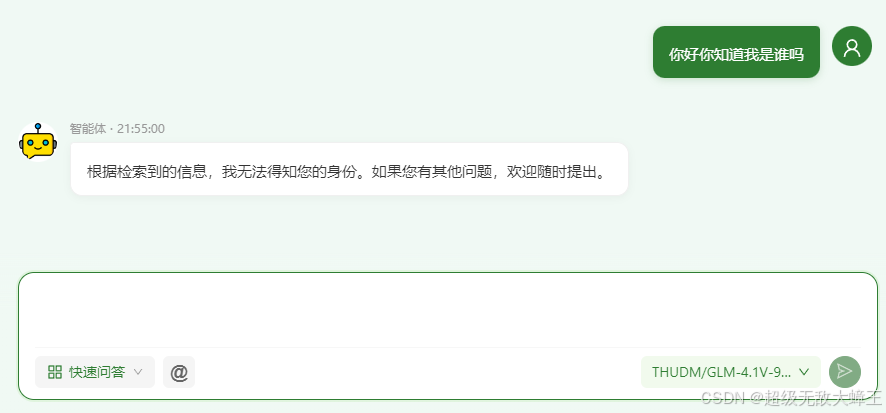
图中所示就是一种典型的流失输出(用户和聊天机器人聊天的网络请求响应) :
SSE是单向输出, 仅支持服务器向客户端发送消息, 但是用户需要向服务端传输body信息数据, 所以大多数的流式输出都是POST形式的HTTP请求

为什么要有流失输出?
1. 早期的大语言模型生成内容时, 是逐个token产生的, 如果等待内容全部生成才显示内容, 那用户需要一直等待
2. 流失输出的存在可以解决这种问题, 减少用户感知的延迟, 并且极大提高了用户的感应速度
对于这种不寻常的输出, 前端应该怎么做?
SSE有它自己独特的响应接收形式的, 我们需要使用最底层的请求方式来一点点实现它
我们通过Fetch这个API来实现网络请求
-
EventSource 的局限性:原生 EventSource 只支持 GET 请求,无法在 Body 中发送复杂的 JSON 数据(比如用户的 prompt、上下文 history)。而且它不支持自定义 Headers(如 Authorization: Bearer token ),这在鉴权系统中是致命的。
-
Fetch 的优势:Fetch 支持 POST,支持自定义 Headers,且通过response.body.getReader()可以实现与 SSE 完全一致的流式读取
第一步: 建立连接
1. 建立连接: 流式输出虽然要获取数据, 但是因为需要携带复杂的data, 需要使用post方法
2. headers: 配置请求头
第二步: 使用streams API来实现流式读取
传统的API是等待整个response下载完成, 但是使用stream可以实现流式读取,后端生成一个字,前端收到一个字。内存占用极低,且用户能立即看到反馈
const reader = response.body.getReader();
const { done, value } = await reader.read();第三步: 使用Buffer机制实现数据拼接(防止分包)
什么是分包? 网络传输可能会导致一个sse消息被分成两段
1. 实现一个缓存池, buffer, 暂存接收到的数据
2. 进行数据的拼接
3. 分割, SSE协议规定了消息之间使用双换行分隔, 利用这个特性分割出来完整的消息块
4. 回退, 数组中的最后一个元素通常都是不完整的, 我们需要通过回退的方式来补全数据, 通过下一次的read()
最后一步:
对接收到的数据块进行清洗定位和分发
1. 清洗: 寻找有效数据行
SSE 协议规定,一次完整的数据推送(Event)可能包含多行(如 event:, id:, data:)。
for (const block of blocks) {
// block 是一次 split("\n\n") 切割出来的一整个 SSE 消息包
// 例如: "event: message\ndata: {...}"
if (!block.trim()) continue; // 如果是空包,直接跳过
// 将这个包按行切开
const lines = block.split("\n");
for (const line of lines) {
// line 是具体的每一行,例如 "data: {...}"
// ...
}
}2. JSON提取:
由于后端返回的data json格式的不一致性, 用 indexOf("{") 可以有效解析出正确标准的json格式,完全无视前面的格式差异。
// 1. 粗筛:这行必须以 "data:" 开头 (忽略空格)
if (line.trim().startsWith("data:")) {
// 2. 精定:不假设 "data:" 后面有几个空格,而是直接找 JSON 的起点 "{"
const jsonStartIndex = line.indexOf("{");
if (jsonStartIndex !== -1) {
// 3. 截取:从 "{" 开始一直截取到行尾,得到纯净的 JSON 字符串
const jsonStr = line.substring(jsonStartIndex);
// jsonStr 现在就是: {"content":"你好", "response_type":"answer"}
// ...
}
}3. 分发:业务逻辑路由
拿到 JSON 对象后,代码根据后端定义的 response_type 字段,决定把数据送到 UI 的哪里。
try {
const json = JSON.parse(jsonStr);
const msgId = json.id || json.message_id; // 兼容不同后端字段名
switch (json.response_type) {
// 场景 A: 这是一个标题更新
case "session_title":
if (onTitleUpdate && json.content) {
onTitleUpdate(json.content); // 比如把侧边栏标题改成 "Java学习"
}
break;
// 场景 B: AI 正在思考 (通常显示为灰色的思维链文字)
case "thinking":
if (json.content) {
// 参数: 内容, 是否结束(false), ID, 类型
onMessage(json.content, false, msgId, "thinking");
}
break;
// 场景 C: AI 正式回答 (显示为黑色的正文)
case "answer":
if (json.content) {
onMessage(json.content, false, msgId, "answer");
}
break;
// 场景 D: 结束信号 (不再有数据了)
case "complete":
// 内容为空,isDone = true
onMessage("", true, msgId, "complete");
break;
// 场景 E: 业务错误 (比如 Token 超限)
case "error":
onMessage(json.content, true, msgId, "error");
continue;
}
} catch (err) {
// 防御性编程:万一 parse 失败,不要让整个循环崩溃,只打印警告
console.warn("解析错误:", jsonStr, err);
}完整接口封装实现:
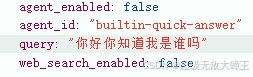

export const sendSessionChat = (
sessionId: string,
data: SendMessageRequest,
onMessage: (
content: string,
isDone: boolean,
messageId?: string,
responseType?: string,
) => void,
onTitleUpdate?: (title: string) => void,
): AbortController => {
// <--- 明确返回类型为 AbortController,而不是 Promise
// 立即创建控制器 (这是同步代码,会立刻执行)
const controller = new AbortController();
// 准备 Token 和 Headers
const token = storage.getItem(config.tokenKey);
const headers: HeadersInit = {
"Content-Type": "application/json",
Authorization: token ? `Bearer ${token}` : "",
"X-Request-ID": Math.random().toString(36).substring(2, 15),
"X-API-Key": "sk-2MkG_J92J2Kwz2q4kqp5HxOtErKNNZ99oCTlZq45esEf8HrA",
priority: "u=1, i",
};
// 发起 Fetch 请求
fetch(`${PATH_URL_AGENT}/agent-chat/${sessionId}`, {
method: "POST",
headers: headers,
body: JSON.stringify(data),
signal: controller.signal, // 绑定信号
})
.then(async (response) => {
// --- 步骤 A: 检查 HTTP 状态 ---
if (!response.ok) {
if (response.status === 401) {
// handle401Error(); // 如果有需要,取消注释
throw new Error("Token Expired");
}
const errText = await response.text();
throw new Error(`接口报错 ${response.status}: ${errText}`);
}
if (!response.body) throw new Error("Response body is empty");
// --- 准备读取流 ---
const reader = response.body.getReader();
const decoder = new TextDecoder("utf-8");
let buffer = "";
// --- 循环读取 (核心) ---
while (true) {
const { done, value } = await reader.read();
if (done) {
onMessage("", true); // 触发完成回调
break;
}
// 解码二进制流
const chunk = decoder.decode(value, { stream: true });
buffer += chunk;
// 按照 SSE 标准 (双换行) 切割数据块
const blocks = buffer.split("\n\n");
// 拿出最后一个可能不完整的块,放回 buffer 等待下次拼接
buffer = blocks.pop() || "";
// 处理每一个完整的块
for (const block of blocks) {
// block 内容示例: "event:message\ndata:{\"content\":\"你好\"}"
if (!block.trim()) continue;
// 按行切割,找到 data 开头的那一行
const lines = block.split("\n");
for (const line of lines) {
// 使用 trim() 去掉可能存在的空格
if (line.trim().startsWith("data:")) {
// 更加稳健的截取方式:找到第一个 '{' 的位置
// 这样即使 data: 后面没有空格,或者有多个空格,都能正确截取
const jsonStartIndex = line.indexOf("{");
if (jsonStartIndex !== -1) {
const jsonStr = line.substring(jsonStartIndex);
try {
const json = JSON.parse(jsonStr);
// 提取 content 和 message_id
const msgId = json.id || json.message_id;
switch (json.response_type) {
case "session_title":
if (onTitleUpdate && json.content) {
onTitleUpdate(json.content);
}
break;
case "agent_query":
if (json.content) {
onMessage(json.content, false, msgId, "agent_query");
}
break;
case "thinking":
if (json.content) {
onMessage(json.content, false, msgId, "thinking");
}
break;
case "answer":
if (json.content) {
onMessage(json.content, false, msgId, "answer");
}
break;
case "complete":
// 处理结束信号
onMessage("", true, msgId, "complete");
break;
case "error":
onMessage(json.content, true, msgId, "error");
continue;
}
} catch (err) {
console.warn("解析错误:", jsonStr, err);
}
}
}
}
}
}
})
.catch((err) => {
// 忽略用户手动停止的错误
if (err.name === "AbortError") {
console.log("用户手动停止生成");
} else {
console.error("流式请求出错:", err);
}
});
return controller;
};

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 29
29 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)