速通AlphaProof:Google DeepMind 的 AI 数学证明系统
速通AlphaProof:Google DeepMind 的 AI 数学证明系统
文章目录
🍃作者介绍:25届双非本科网络工程专业,阿里云专家博主,深耕 AI 原理 / 应用开发 / 产品设计。前几年深耕Java技术体系,现专注把 AI 能力落地到实际产品与业务场景。
🦅个人主页:@逐梦苍穹
📕所属专栏:🌩专栏①:人工智能; 🌩专栏②:速通人工智能相关论文
✈ 您的一键三连,是我创作的最大动力🌹
AlphaProof:Google DeepMind 的 AI 数学证明系统
首个在国际数学奥林匹克竞赛中达到银牌水平的人工智能系统
引言
2024年,Google DeepMind 推出了一项令人瞩目的成果——AlphaProof,这是一个基于强化学习的形式化数学推理系统。在2024年国际数学奥林匹克竞赛(IMO)中,AlphaProof 与 AlphaGeometry 2 联手,成功解决了6道题目中的4道,获得了相当于银牌水平的成绩,这是 AI 系统首次在 IMO 中达到奖牌级别的表现。

什么是 AlphaProof?
AlphaProof 是一个将预训练语言模型与 AlphaZero 强化学习算法相结合的数学证明系统。它在形式化语言 Lean 中进行工作,这使得每一步数学推理都可以被自动验证其正确性。
用一句话概括:AlphaProof = 语言模型 + AlphaZero 风格强化学习 + Lean 形式化环境。
核心特点
| 特性 | 说明 |
|---|---|
| 100% 准确性 | 与传统 LLM 不同,AlphaProof 通过 Lean 证明助手验证每一个逻辑步骤 |
| 自我学习 | 通过强化学习不断提升解题能力 |
| 形式化证明 | 输出的证明是机器可验证的,不存在"幻觉"问题 |
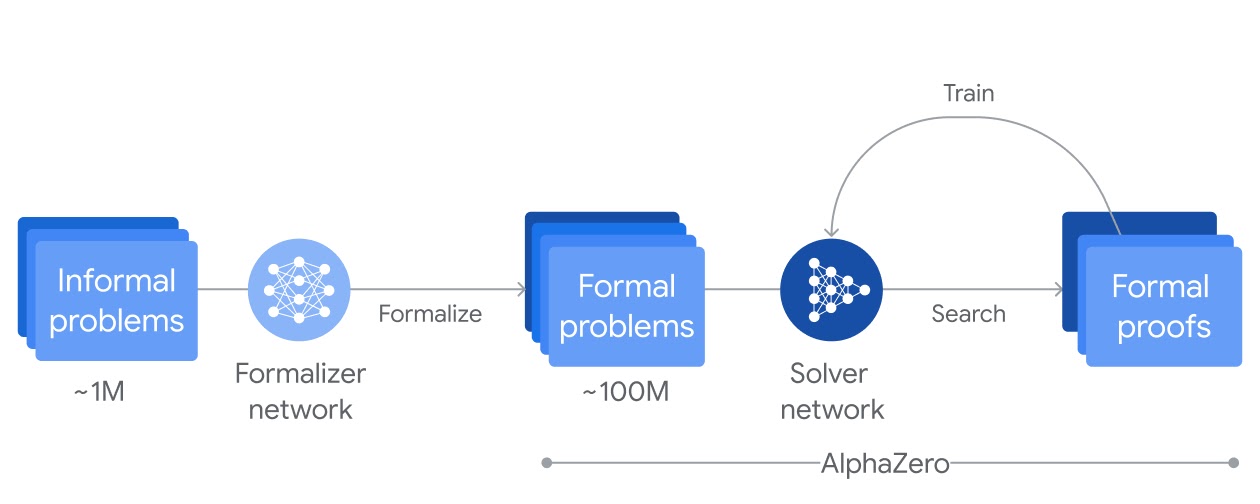
系统架构
AlphaProof 的架构由三个核心组件构成:
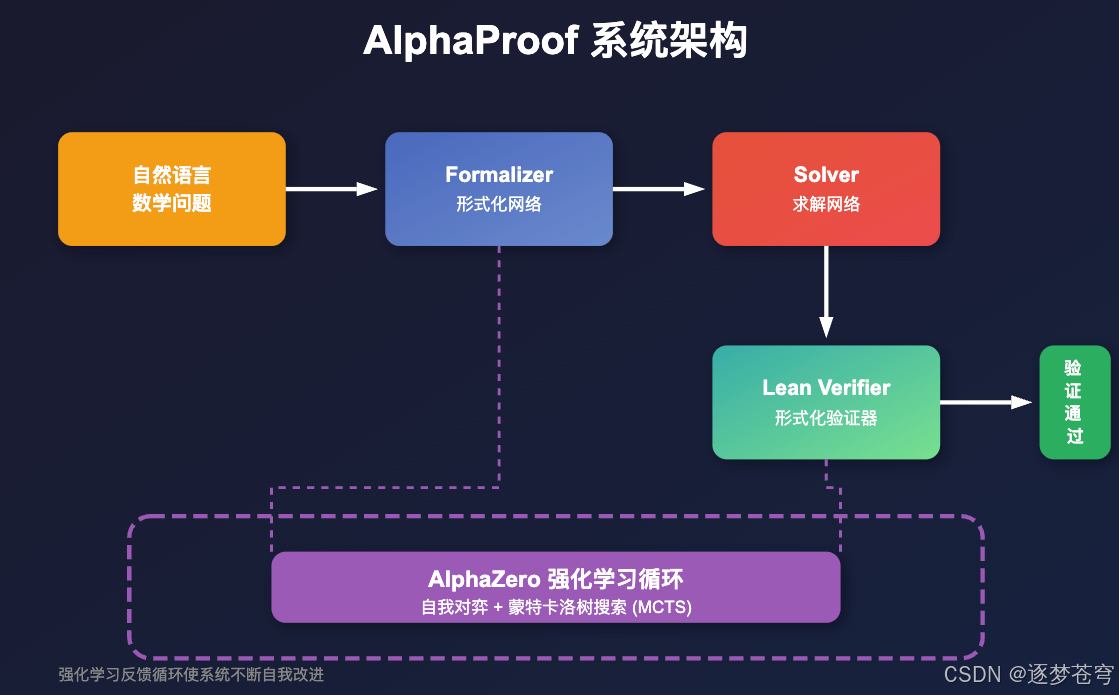
组件详解
1. Formalizer Network(形式化网络)
把自然语言题目(或题目变体)翻译成 Lean 形式化语言。
2. Solver Network(求解网络)
在 Lean 中尝试一串 tactic,把目标一步步推到"证明完成"。使用 Lean 环境搜索证明或反证,结合 AlphaZero 的策略进行智能搜索。
3. Lean Verifier(验证器)
担任"严苛裁判",每一步都要过类型检查与内核验证,确保证明过程无误。
4. 强化学习循环
把成功的证明路径当作"正反馈",不断让模型更擅长走向能证明的分支。
训练过程
AlphaProof 的训练分为三个阶段:
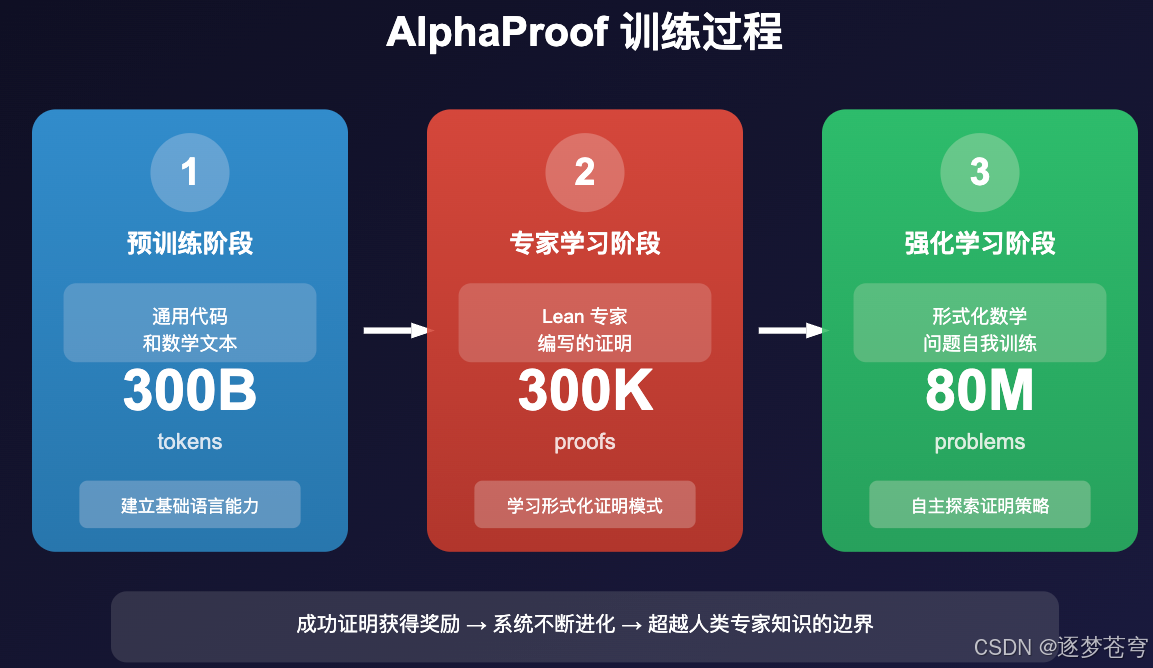
关键创新点
- 自我进化:在强化学习阶段,AlphaProof 能够自己生成问题的变体,并从解决这些变体中学习
- 竞赛期间继续训练:在实际比赛中,系统继续针对竞赛问题的变体进行训练,直到找到完整解答
理解 AlphaProof 的"速度"
如果把 Lean 的"验证"看成裁判,AlphaProof 的难点不在裁判判得慢,而在于:要在巨大的证明空间里尽快找到一条能被裁判认可的路。
AlphaProof 的"速度"需要从两个时间尺度来理解:
- 验证很快:给定一个 Lean 证明,Lean 可以高效地逐步检查每个 tactic 是否正确。
- 搜索很难:真正花时间的是"找证明"——要在大量候选 proof step(tactic)里做搜索与回溯。
因此,论文/补充材料更喜欢用 TPU 设备时间(compute budget) 来描述推理成本,例如 “2 TPU-min” 或 “50 TPU-days(TTRL)”。这相当于告诉你:为了提升成功率,系统愿意为每道题"烧掉"多少算力。
TPU 预算的计算方式
补充材料明确给出了按题目计的推理预算刻度,分成两类:
- 树搜索(tree search):用 TPU-minutes / TPU-hours 表示;
- TTRL(Test-Time Reinforcement Learning,推理时强化学习):用 TPU-days 表示。
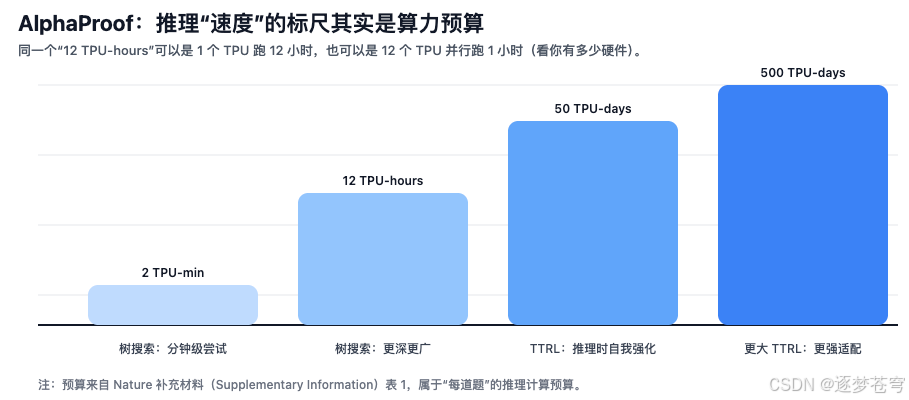
一个容易踩的坑:TPU-hours / TPU-days 是"设备时间"。例如:
- 12 TPU-hours 可以是
1 TPU × 12 小时,也可以是12 TPU × 1 小时; - 若某题预算为
B TPU-hours,并行使用N个 TPU,则墙钟时间约为B / N小时; - 若预算为
D TPU-days,墙钟时间约为D / N × 24小时。
推理预算与成功率
补充材料把 AlphaProof 在两个基准上的"按学科拆分的求解率"列得很清楚,并且给出四档推理预算:
- 树搜索:2 TPU-min、12 TPU-hours
- 加上 TTRL:50 TPU-days、500 TPU-days
formal-imo(按学科)
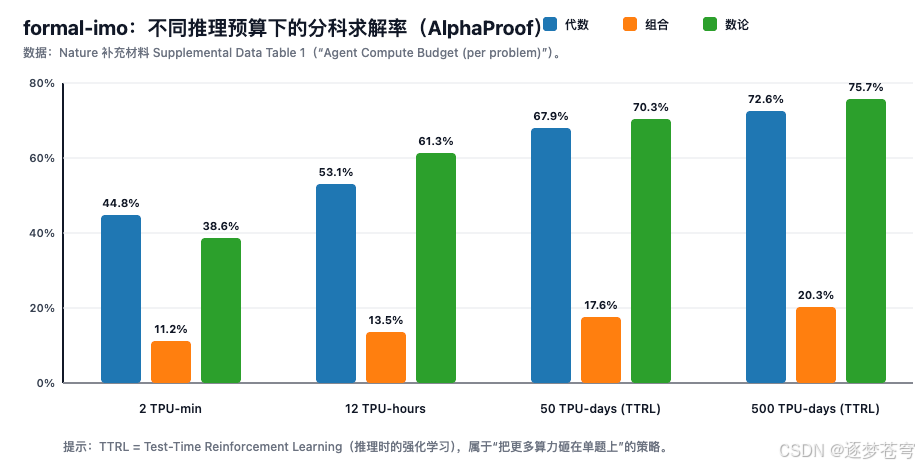
| 推理预算(每题) | 代数 | 组合 | 数论 |
|---|---|---|---|
| AlphaProof(树搜索)2 TPU-min | 44.8% | 11.2% | 38.6% |
| AlphaProof(树搜索)12 TPU-hours | 53.1% | 13.5% | 61.3% |
| AlphaProof + TTRL 50 TPU-days | 67.9% | 17.6% | 70.3% |
| AlphaProof + TTRL 500 TPU-days | 72.6% | 20.3% | 75.7% |
putnam-test(按学科)
| 推理预算(每题) | 代数 | 分析 | 几何 | 线性代数 | 数论 |
|---|---|---|---|---|---|
| AlphaProof(树搜索)2 TPU-min | 26.9% | 40.1% | 4.3% | 16.5% | 27.2% |
| AlphaProof(树搜索)12 TPU-hours | 41.2% | 43.0% | 39.5% | 16.7% | 39.5% |
| AlphaProof + TTRL 50 TPU-days | 48.7% | 51.8% | 30.0% | 27.8% | 57.6% |
| AlphaProof + TTRL 500 TPU-days | 61.5% | 64.3% | 35.0% | 38.9% | 66.7% |
如何理解这些数据
- 同一模型,不同预算:它不是"换了一个更大的模型",而是"同一个系统在推理阶段投入更多搜索/学习"。
- TTRL 是"单题深挖":从 minutes/hours 跨到 days,表示系统愿意为"最难题"做更强的、问题相关的适配。
- 收益递减很明显:从 50 TPU-days 到 500 TPU-days 的提升仍在,但边际变小;这正是"速度/成本 vs 成功率"的经典折中。
为什么最难题需要"天"级算力:TTRL 的直觉
在形式化证明里,困难往往来自:
- 分支因子大:每一步可能有很多 tactic 选择;
- 长程依赖:正确路径可能需要几十到上百步;
- 反馈稀疏:大多数尝试走到中途就卡住,成功信号很少。
TTRL(Test-Time RL)的直觉是:当你遇到一题"怎么都推不动"时,不只是加大搜索深度,而是:
- 在推理阶段生成大量相关的变体(可以理解为"围绕这题做海量针对性练习");
- 用这些变体上的成功/失败继续更新策略,学到更适合这道题的证明策略;
- 再回到原题,尝试把学到的策略迁移回来。
这也解释了 Nature 摘要中提到的 “multi-day computation”:要拿到奥赛级别的稳定成功率,可能需要把大量算力集中在少数难题上。
IMO 2024 表现
成绩总览

AlphaProof 与 AlphaGeometry 2 联合取得 28 分(满分 42 分),达到银牌水平。
问题解决详情
| 问题 | 领域 | AI系统 | 结果 | 备注 |
|---|---|---|---|---|
| P1 | 代数 | AlphaProof | 已解决 | 几分钟内完成 |
| P2 | 代数 | AlphaProof | 已解决 | - |
| P3 | 几何 | AlphaGeometry 2 | 已解决 | 仅用19秒! |
| P4 | 组合 | - | 未解决 | - |
| P5 | 组合 | - | 未解决 | - |
| P6 | 数论 | AlphaProof | 已解决 | 最难题目 |
亮点:攻克最难题目 P6
P6 被认为是2024年 IMO 中最具挑战性的问题。在609名参赛选手中,只有5人获得了该题的满分。AlphaProof 成功证明了这道题,展现了其在复杂数学推理方面的强大能力。
技术原理深度解析
AlphaZero 与数学证明的结合
AlphaZero 最初是为棋类游戏设计的,它通过自我对弈和蒙特卡洛树搜索(MCTS) 来学习最优策略。AlphaProof 将这一思想应用到数学证明领域:
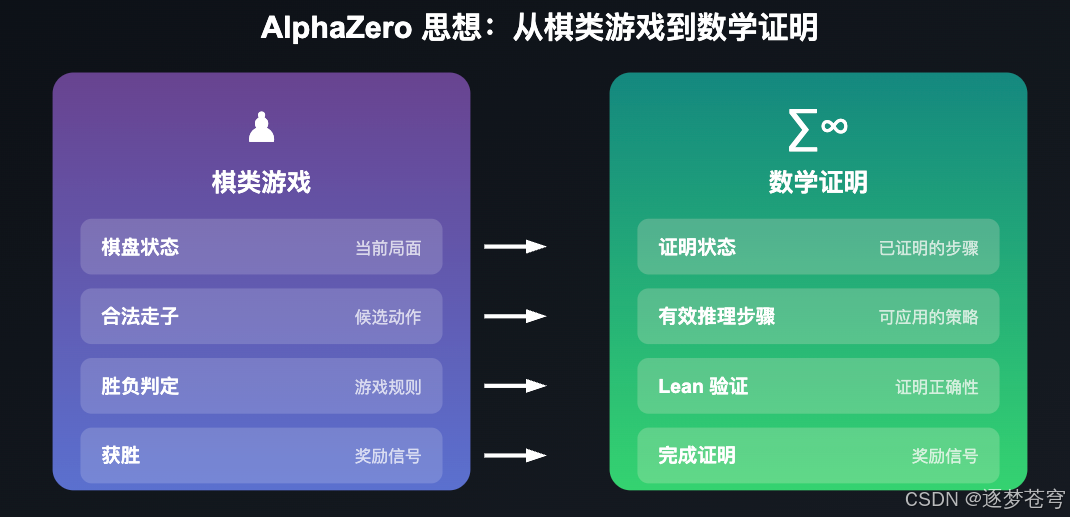
| 棋类游戏 | 数学证明 |
|---|---|
| 棋盘状态 | 证明状态(goals) |
| 落子 | 应用 tactic |
| 胜负判定 | Lean 验证成功/失败 |
| 自我对弈 | 自我证明练习 |
为什么使用 Lean?
Lean 是一种形式化证明语言,它的优势在于:
- 机器可验证:每一步推理都可以自动检查
- 无歧义性:避免自然语言的模糊性
- 完整性:证明要么完全正确,要么无法通过验证
这与传统 LLM 的"概率性"输出形成鲜明对比——AlphaProof 的答案要么 100% 正确,要么根本不给出答案。
与人类选手的对比
在 IMO 2024 中,共有 609 名来自世界各地的顶尖数学选手参赛:
| 奖牌等级 | 分数线 | 人数 | 占比 |
|---|---|---|---|
| 金牌 | 29+ 分 | 58 人 | 9.5% |
| AlphaProof | 28 分 | 银牌水平 | - |
| 银牌 | 22-28 分 | ~100 人 | 16% |
| 铜牌 | 16-21 分 | ~150 人 | 25% |
| 无奖牌 | <16 分 | ~300 人 | 49% |
AlphaProof 仅差 1 分就能达到金牌水平,其表现已超越了约 90% 的人类参赛选手。
意义与展望
突破性意义
-
首个奖牌级 AI:这是人工智能首次在 IMO 这样的顶级数学竞赛中达到奖牌水平
-
超越"猜测":与常见的 LLM 不同,AlphaProof 不会"胡说八道",它的每一个证明都经过严格验证
-
自主发现能力:系统能够发现人类未曾想到的证明路径
后续发展
2025年,DeepMind 进一步推出了配备 Deep Think 的高级版 Gemini,该系统:
- 解决了6道 IMO 问题中的5道
- 获得了35分(满分42分)
- 达到了金牌水平
- 完全在4.5小时的比赛时限内完成
对实际应用的启示
如果你的目标是"让 AI 在写 Lean 时给提示":
- 更关心的是 TPU-min / TPU-hours 档位:在合理预算里,快速给出可验证的下一步或局部 lemma;
- "多日算力"更像是 离线攻坚模式:适合证明难题、整理长期项目、或者冲极限 benchmark。
如果你的目标是"看懂 AlphaProof 的工程折中":
- 这篇工作的关键不只是模型更大,而是把 搜索(tree search)+ 学习(RL) 做成一个能规模化自我提升的闭环;
- "速度"在这里本质上是:你愿意为每道题付出多少 compute budget,以及能不能并行化这份预算。
总结
AlphaProof 代表了 AI 在数学推理领域的一个重要里程碑:
| 维度 | 传统 LLM | AlphaProof |
|---|---|---|
| 准确性 | 概率性,可能出错 | 100% 可验证 |
| 推理能力 | 模式匹配为主 | 真正的逻辑推理 |
| 可信度 | 需要人工验证 | 机器自动验证 |
| 复杂问题 | 容易"幻觉" | 严格形式化 |
虽然 AlphaProof 在解题时间上还无法与人类竞赛选手相比(有些问题需要数天算力才能解决),但它展示了一条通往可靠 AI 数学推理的清晰路径。
随着 2025 年 Gemini Deep Think 取得金牌级成绩,我们可以期待 AI 在数学领域继续取得更大的突破。
参考资料
- AI achieves silver-medal standard solving International Mathematical Olympiad problems - Google DeepMind
- Olympiad-level formal mathematical reasoning with reinforcement learning | Nature
- Advanced version of Gemini with Deep Think officially achieves gold-medal standard at the International Mathematical Olympiad
- Nature 补充材料(含详细数据表)
- Lean:形式化语言与证明助手

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 18
18 0
0- 0



 已为社区贡献45条内容
已为社区贡献45条内容

所有评论(0)