RAG架构完全指南:从标准到自适应,AI开发者必备的检索增强生成知识体系
本文介绍了9种RAG架构及其适用场景,包括标准RAG、对话式RAG、CRAG、Adaptive RAG等。RAG通过检索外部知识库增强大模型回答的准确性,解决"幻觉"问题。不同架构针对不同需求设计,如对话式RAG处理上下文,CRAG加入自我校验,Adaptive RAG按问题复杂度匹配资源。文章强调应根据实际需求选择架构,从简单开始逐步优化。正确实现的RAG系统能显著提升大模型
文章详细介绍了9种RAG架构,包括标准RAG、对话式RAG、CRAG、Adaptive RAG等,分析了它们各自的适用场景、工作流程和优缺点。强调选择合适架构对项目成功至关重要,建议从简单开始,根据需求逐步增加复杂度,避免过度设计。正确实现的RAG能将大模型从"自信的说谎者"转变为可靠的信息系统。
RAG有多种架构,每一种都在解决不同的问题。 选错架构,可能浪费你几个月时间。
本指南将拆解真正能在生产环境中发挥作用的 RAG 架构。
让我们从理解 RAG 开始。
什么是 RAG?它为什么真的重要?
在深入具体架构之前,先明确概念。
**RAG(Retrieval-Augmented Generation,检索增强生成)**通过在生成回答前引用外部知识库,来优化语言模型的输出。
模型不再只依赖训练阶段学到的知识,而是从你的文档、数据库或知识图谱中,动态检索相关且最新的信息。
实际流程如下:
- 用户提出问题
- RAG 系统根据问题从外部数据源中检索相关信息
- 将原始问题 + 检索到的上下文一并输入语言模型
- 模型基于可验证的真实信息生成回答,而不是凭训练记忆“编造”
RAG 实际解决了哪些问题?
1️⃣ 标准 RAG(Standard RAG):从这里开始
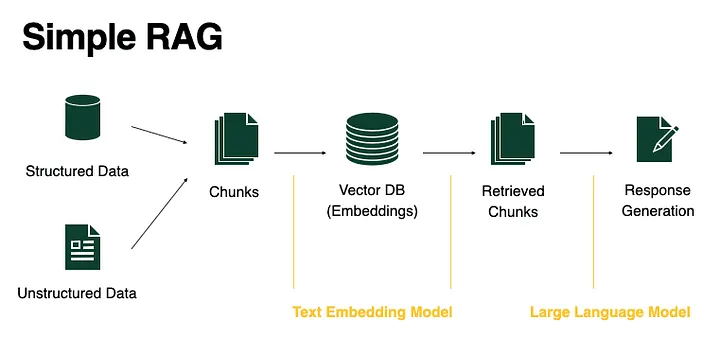
标准 RAG 是整个生态的 “Hello World”。
它把检索视为一次性的简单查找,用来让模型“落地”到特定数据上,而不需要微调。但它隐含的假设是:你的检索系统本身是完美的。
适用场景
低风险场景中,速度比绝对事实密度更重要。
工作流程:
- 切分(Chunking):将文档拆分成小段文本
- 向量化(Embedding):将每段转成向量,存入向量数据库(如 Pinecone、Weaviate)
- 检索(Retrieval):对用户问题向量化,用余弦相似度找 Top-K 相似片段
- 生成(Generation):将这些片段作为 Context 输入 LLM 生成回答
示例
创业公司的内部员工手册机器人。 用户问:“公司的宠物政策是什么?” 机器人检索 HR 手册中的对应段落并作答。
优点
- 亚秒级延迟
- 计算成本极低
- 易于调试与监控
缺点
- 容易检索到噪声(无关内容)
- 无法处理复杂、多步问题
- 如果检索错了,无法自我纠错
2️⃣ 对话式 RAG(Conversational RAG):加入记忆
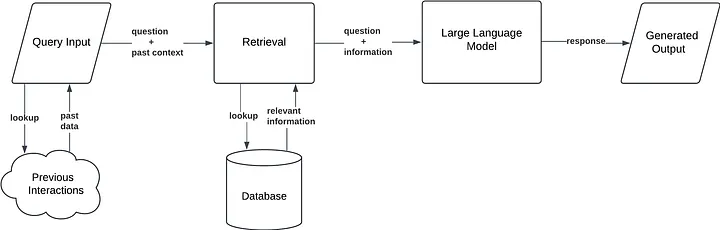
对话式 RAG 解决的是**“上下文失明”**问题。
在标准 RAG 中,如果用户追问一句:“那它多少钱?” 系统并不知道“它”指的是什么。
该架构引入有状态的记忆层,为每一轮对话重新构建上下文。
工作流程:
- 上下文加载:保存最近 5–10 轮对话
- 查询重写:LLM 根据历史 + 当前问题生成“独立查询”(如“企业版的价格是多少?”)
- 检索:用重写后的查询做向量搜索
- 生成:基于新上下文回答
示例
SaaS 客服机器人: 用户:“我的 API Key 有问题。” 接着问:“你能帮我重置吗?” 系统知道“它”指的是 API Key。
优点
- 更自然的人类对话体验
- 用户无需重复背景信息
缺点
- 记忆漂移:10 分钟前的无关内容可能污染当前检索
- 查询重写会增加 token 成本
3️⃣ Corrective RAG(CRAG):自我校验器
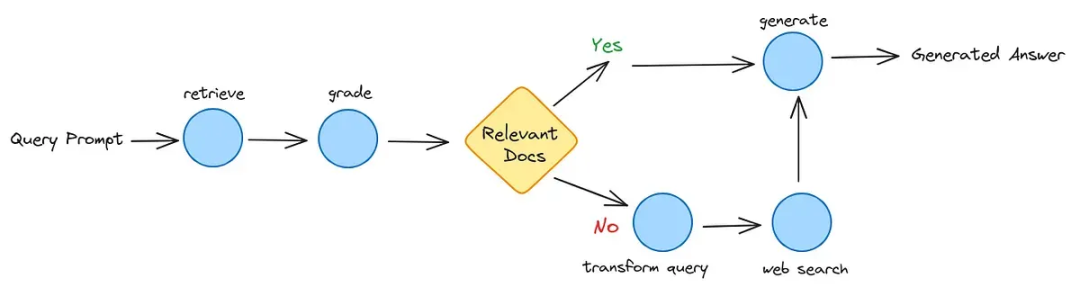
CRAG 面向高风险场景设计。
它在检索与生成之间加入一个**“决策门”**,用于评估检索文档的质量。 如果内部数据不足或错误,就触发外部实时搜索。
在实际部署 CRAG 风格评估器的团队中,相比 Naive RAG,幻觉显著下降。
工作流程:
- 从内部向量库检索
- 使用轻量级“评分模型”为每个文档块打分(正确 / 模糊 / 错误)
- 决策门:
- 正确 → 进入生成
- 错误 → 丢弃并调用外部 API(Google Search、Tavily 等)
- 使用可信数据生成最终回答
示例
金融顾问机器人被问到某只股票的最新价格。 数据库只有 2024 年数据,CRAG 发现缺失,转而从金融新闻 API 获取实时价格。
优点
- 大幅减少幻觉
- 打通内部数据与现实世界
缺点
- 延迟明显增加(2–4 秒)
- 外部 API 成本与限流管理复杂
4️⃣ Adaptive RAG:按问题复杂度匹配资源
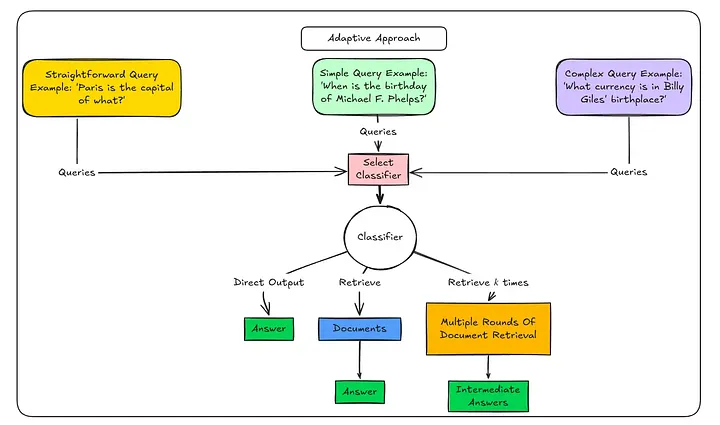
Adaptive RAG 是效率之王。
并非每个问题都需要“重型武器”。 它通过路由器判断问题复杂度,选择最便宜、最快的路径。
工作流程:
- 复杂度分析:小型分类模型做路由
- 路径 A:无需检索(问候、常识)
- 路径 B:标准 RAG(简单事实)
- 路径 C:多步 Agent(复杂分析)
示例
大学助手:
- “你好” → 直接回答
- “图书馆几点开?” → 简单检索
- “对比 CS 专业过去 5 年学费变化” → 复杂分析
优点
- 大幅节省成本
- 简单问题延迟最优
缺点
- 误分类风险
- 路由模型必须足够可靠
5️⃣ Self-RAG:会反思的 AI
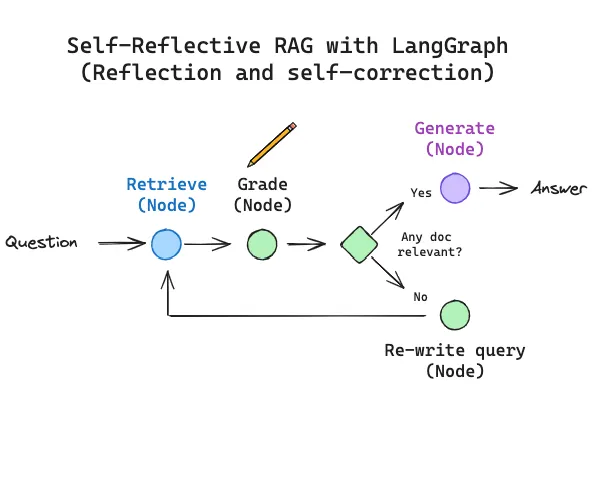
Self-RAG 是一种自我批判式架构。 模型不仅生成内容,还生成反思 token,实时审计自己的回答。
工作流程:
- 模型自主触发检索
- 在生成过程中输出 [IsRel]、[IsSup]、[IsUse] 等 token
- 若检测到 [NoSup],则暂停、重新检索并改写
示例
法律检索工具。 模型发现某判例并不支持自己的论断,于是自动换一个判例。
优点
- 最高级别的事实可靠性
- 推理过程高度透明
缺点
- 需要专门微调的模型
- 计算开销极大
6️⃣ Fusion RAG:多视角,更高召回
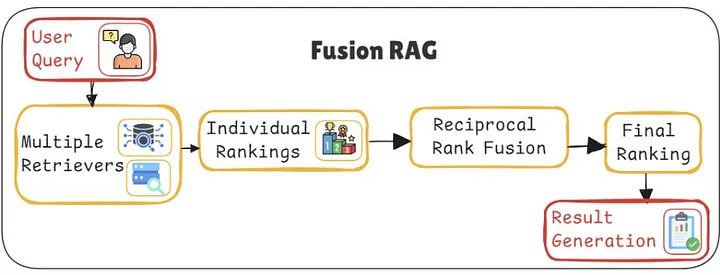
Fusion RAG 解决的是用户搜索能力差的问题。
工作流程:
- 查询扩展:生成 3–5 个问题变体
- 并行检索
- 使用 Reciprocal Rank Fusion (RRF) 重排序
- 多次排名靠前的文档权重更高
示例
医学研究者搜索“失眠治疗”,系统同时搜索药物、非药物、CBT-I 等方向。
优点
- 极高召回率
- 抗用户表述噪声
缺点
- 检索成本 ×3–5
- 延迟增加
7️⃣ HyDE:先生成答案,再找文档
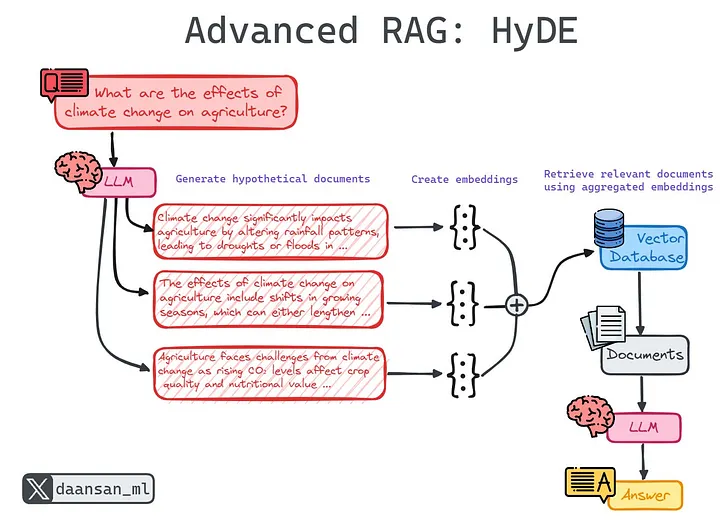
HyDE 基于一个反直觉的洞察:问题与答案在语义空间中并不对齐。
工作流程:
- LLM 先生成一个“假想答案”
- 对假答案向量化
- 用该向量检索真实文档
- 基于真实文档生成最终回答
示例
用户问:“加州那个关于数字隐私的法律。” HyDE 先生成 CCPA 的摘要,再找到真实法条。
优点
- 对模糊、概念性问题检索效果极佳
缺点
- 假答案错误会误导检索
- 对简单问题效率低
8️⃣ Agentic RAG:专家协同
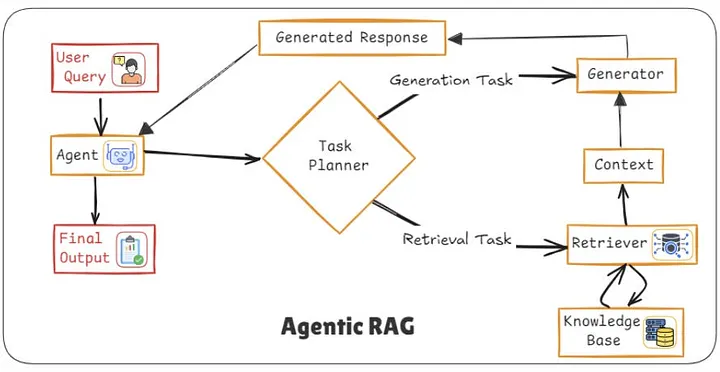
Agentic RAG 将检索视为研究过程,而非查找。
工作流程:
- 分析问题
- 制定计划
- 调用工具(搜索、API、计算器)
- 迭代验证
- 综合生成
示例
“在印度法规下,金融科技应用用 LLM 做贷款审批是否安全?”
Agent 会:
- 识别为监管问题
- 查 RBI 政策
- 检索内部合规文档
- 校验最新法规
- 输出结构化结论
优点
- 处理复杂、模糊、多步问题
- 支持实时数据
缺点
- 延迟与成本高
- 架构复杂
9️⃣ GraphRAG:关系推理器
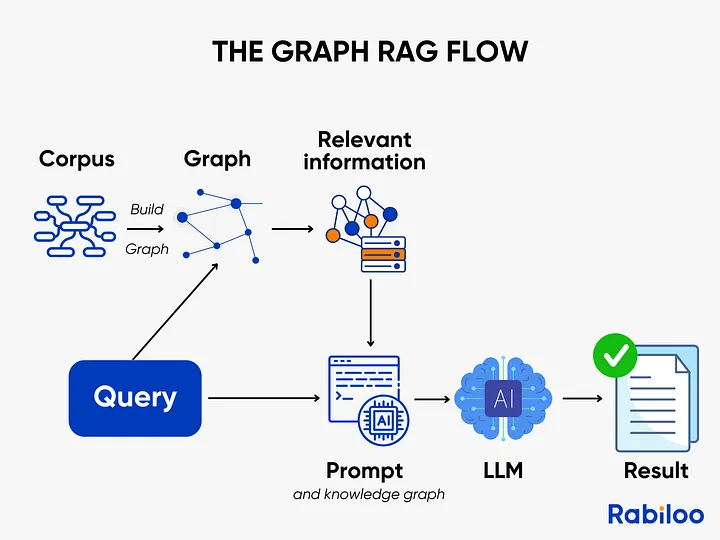
GraphRAG 检索的是实体与关系,而非文本相似度。
它问的是:“哪些实体相关?它们如何相互影响?”
示例
“美联储加息如何影响科技初创公司估值?”
通过关系链推理得出结论,而非文档匹配。
优点
- 擅长因果、多跳推理
- 解释性极强
缺点
- 知识图谱构建成本高
- 不适合开放对话
结论
RAG 不是魔法。 它不能修复糟糕的设计或垃圾数据。
但如果合理实现, 它能把语言模型从**“自信的说谎者”变成可靠的信息系统**。
从简单开始,量化一切,只有在明确需要时才增加复杂度。
如何学习AI大模型?
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 4
4 0
0- 0



 已为社区贡献565条内容
已为社区贡献565条内容

所有评论(0)