YOLOv11改进 - C3k2融合 | C3k2融合LWGA轻量分组注意力(Light-Weight Grouped Attention):四路径并行架构破解通道冗余难题 | AAAI 2026
本文介绍了轻量级骨干网LWGANet及其核心模块LWGA在YOLOv11中的结合。现有用于遥感(RS)视觉质量分析的轻量级神经网络存在空间初始冗余和通道冗余问题,无法应对RS场景挑战。LWGA采用异构分组策略,将通道划分为4个不重叠子集,每个子集对应特定特征尺度,通过专用子模块处理并融合多尺度特征。我们将相关代码加入指定目录,在ultralytics/nn/tasks.py中注册,配置yolo11
前言
本文介绍了轻量级骨干网LWGANet及其核心模块LWGA在YOLOv11中的结合。现有用于遥感(RS)视觉质量分析的轻量级神经网络存在空间初始冗余和通道冗余问题,无法应对RS场景挑战。LWGA采用异构分组策略,将通道划分为4个不重叠子集,每个子集对应特定特征尺度,通过专用子模块处理并融合多尺度特征。我们将相关代码加入指定目录,在ultralytics/nn/tasks.py中注册,配置yolo11 - C3k2_LWGA.yaml文件,最后通过实验脚本和结果验证了方法的有效性。
文章目录: YOLOv11改进大全:卷积层、轻量化、注意力机制、损失函数、Backbone、SPPF、Neck、检测头全方位优化汇总
专栏链接: YOLOv11改进专栏
介绍

摘要
用于遥感(RS) vi质量分析的轻量级神经网络必须克服两个固有的冗余:spa来自巨大、同质背景的初始冗余和通道冗余,其中极端的尺度变化使单个特征空间效率低下。现有的模型(通常为自然图像签名)无法解决RS场景中的这一双重挑战。为了弥补这一差距,我们提出了LWGANet,这是一种轻量级骨干网,专为rs特定的适当连接而设计。LWGANet引入了两个核心创新:一个是Top-KGlobal Feature Interaction (TGFI)模块,通过将计算集中在显著区域来减轻spa初始冗余,另一个是轻量级分组注意(LWGA)模块,通过将通道划分为专门的、特定于规模的路径来解决通道冗余。通过协同重新解决这些核心的低效率,LWGANet在特征表示质量和计算成本之间实现了一个超级的权衡。在四个主要RS任务(场景分类、ori对象检测、语义分割和变化检测)中的12个不同数据集上进行的广泛实验表明,LWGANet在准确性和效率方面始终优于,形成了最先进的轻量级主干。我们的工作建立了一个新的,健壮的基线线,用于有效的RS图像视觉分析。
文章链接
论文地址:论文地址
代码地址:代码地址
基本原理
LWGA(Light-Weight Grouped Attention)是LWGANet的核心模块,核心作用是通过异构分组策略拆分通道特征,用专用子模块适配遥感影像多尺度特性,从而解决通道冗余问题。
核心设计理念
传统轻量模型采用同质分组(如分组卷积、多头注意力),所有通道组执行相同操作,无法适配遥感影像中极端尺度差异(如小车辆与长跑道共存)。LWGA则采用异构分组:
- 将通道划分为4个不重叠的子集,每个子集对应特定特征尺度。
- 为每个子集分配专用计算路径,确保通道资源聚焦于对应尺度特征,避免冗余浪费。
- 最终融合多尺度特征,形成全面且高效的特征表达。
模块结构与工作流程
- 通道拆分:输入特征图X(维度H×W×C)按通道均匀拆分为4个子集X₁~X₄,每个子集维度为H×W×(C/4)。
- 专用子模块处理:4个子集分别通过针对性设计的子注意力模块,捕捉不同尺度特征。
- 特征融合:将4个子模块的输出R₁~R₄沿通道维度拼接,得到最终增强特征图Y(维度H×W×C)。
四大专用子注意力模块
每个子模块聚焦特定尺度特征,兼顾效率与表达能力:
- Gate Point Attention(GPA):捕捉点级细粒度特征,适配小目标(如车辆)、复杂纹理场景。通过1×1卷积扩展-压缩通道维度,生成注意力权重图,增强关键细节特征。
- Regular Local Attention(RLA):基于3×3标准卷积,利用卷积的归纳偏置高效捕捉局部纹理和模式,为模型提供稳定的局部特征基础。
- Sparse Medium-range Attention(SMA):针对不规则形状目标(如桥梁、河流),捕捉中距离上下文信息。结合TGFI模块稀疏采样特征,通过多方向邻域交互生成注意力图,再插值恢复至原始尺寸。
- Sparse Global Attention(SGA):建模长距离依赖,支撑全局场景理解(如城市布局、大范围植被分布)。采用动态策略适配网络阶段:低阶段(1-2阶段)用卷积近似降低计算成本,高阶段(3-4阶段)逐步启用标准自注意力,平衡效率与表达力。
关键优势
- 多尺度精准适配:4个子模块覆盖点级、局部、中距离、全局尺度,无需牺牲任一尺度特征。
- 通道效率最大化:异构分组避免“一刀切”操作,每个通道组仅负责对应尺度任务,减少冗余计算。
- 轻量性设计:所有子模块均采用低复杂度操作(如小核卷积、稀疏采样),确保模块整体计算成本可控。
- 任务通用性:适配场景分类、目标检测、语义分割等多类遥感视觉任务,提供统一的多尺度特征解决方案。
核心代码
class LWGA_Block(nn.Module):
def __init__(self,
dim,
stage,
att_kernel,
mlp_ratio,
drop_path,
act_layer,
norm_layer
):
super().__init__()
self.stage = stage
self.dim_split = dim // 4
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
mlp_hidden_dim = int(dim * mlp_ratio)
mlp_layer: List[nn.Module] = [
nn.Conv2d(dim, mlp_hidden_dim, 1, bias=False),
norm_layer(mlp_hidden_dim),
act_layer(),
nn.Conv2d(mlp_hidden_dim, dim, 1, bias=False)
]
self.mlp = nn.Sequential(*mlp_layer)
self.PA = PA(self.dim_split, norm_layer, act_layer) # PA is point attention
self.LA = LA(self.dim_split, norm_layer, act_layer) # LA is local attention
self.MRA = MRA(self.dim_split, att_kernel, norm_layer) # MRA is medium-range attention
if stage == 2:
self.GA3 = D_GA(self.dim_split, norm_layer) # GA3 is global attention (stage of 3)
elif stage == 3:
self.GA4 = GA(self.dim_split) # GA4 is global attention (stage of 4)
self.norm = norm_layer(self.dim_split)
else:
self.GA12 = GA12(self.dim_split, act_layer) # GA12 is global attention (stages of 1 and 2)
self.norm = norm_layer(self.dim_split)
self.norm1 = norm_layer(dim)
self.drop_path = DropPath(drop_path)
def forward(self, x: Tensor) -> Tensor:
# for training/inference
shortcut = x.clone()
x1, x2, x3, x4 = torch.split(x, [self.dim_split, self.dim_split, self.dim_split, self.dim_split], dim=1)
x1 = x1 + self.PA(x1)
x2 = self.LA(x2)
x3 = self.MRA(x3)
if self.stage == 2:
x4 = x4 + self.GA3(x4)
elif self.stage == 3:
x4 = self.norm(x4 + self.GA4(x4))
else:
x4 = self.norm(x4 + self.GA12(x4))
x_att = torch.cat((x1, x2, x3, x4), 1)
x = shortcut + self.norm1(self.drop_path(self.mlp(x_att)))
return x
YOLO11引入代码
在根目录下的ultralytics/nn/目录,新建一个 C3k2目录,然后新建一个以 C3k2_LWGA为文件名的py文件, 把代码拷贝进去。
# Copyright (c) Microsoft Corporation.
# Licensed under the MIT License.
import torch
import torch.nn as nn
from timm.layers import DropPath
from typing import List
from torch import Tensor
import numpy as np
import torch.nn.functional as F
from ultralytics.nn.modules.conv import Conv
from ultralytics.nn.modules.block import Bottleneck,C3k2,C3k,C2f
__all__ = ['LWGA_Block']
class DRFD(nn.Module):
def __init__(self, dim, norm_layer, act_layer):
super().__init__()
self.dim = dim
self.outdim = dim * 2
self.conv = nn.Conv2d(dim, dim*2, kernel_size=3, stride=1, padding=1, groups=dim)
self.conv_c = nn.Conv2d(dim*2, dim*2, kernel_size=3, stride=2, padding=1, groups=dim*2)
self.act_c = act_layer()
self.norm_c = norm_layer(dim*2)
self.max_m = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.norm_m = norm_layer(dim*2)
self.fusion = nn.Conv2d(dim*4, self.outdim, kernel_size=1, stride=1)
def forward(self, x): # x = [B, C, H, W]
x = self.conv(x) # x = [B, 2C, H, W]
max = self.norm_m(self.max_m(x)) # m = [B, 2C, H/2, W/2]
conv = self.norm_c(self.act_c(self.conv_c(x))) # c = [B, 2C, H/2, W/2]
x = torch.cat([conv, max], dim=1) # x = [B, 2C+2C, H/2, W/2] --> [B, 4C, H/2, W/2]
x = self.fusion(x) # x = [B, 4C, H/2, W/2] --> [B, 2C, H/2, W/2]
return x
class PA(nn.Module):
def __init__(self, dim, norm_layer, act_layer):
super().__init__()
self.p_conv = nn.Sequential(
nn.Conv2d(dim, dim*4, 1, bias=False),
norm_layer(dim*4),
act_layer(),
nn.Conv2d(dim*4, dim, 1, bias=False)
)
self.gate_fn = nn.Sigmoid()
def forward(self, x):
att = self.p_conv(x)
x = x * self.gate_fn(att)
return x
class LA(nn.Module):
def __init__(self, dim, norm_layer, act_layer):
super().__init__()
self.conv = nn.Sequential(
nn.Conv2d(dim, dim, 3, 1, 1, bias=False),
norm_layer(dim),
act_layer()
)
def forward(self, x):
x = self.conv(x)
return x
def get_pad_layer(pad_type):
if(pad_type in ['refl','reflect']):
PadLayer = nn.ReflectionPad2d
elif(pad_type in ['repl','replicate']):
PadLayer = nn.ReplicationPad2d
elif(pad_type=='zero'):
PadLayer = nn.ZeroPad2d
else:
print('Pad type [%s] not recognized'%pad_type)
return PadLayer
class BlurPool(nn.Module):
def __init__(self, channels, pad_type='reflect', filt_size=4, stride=2, pad_off=0):
super(BlurPool, self).__init__()
self.filt_size = filt_size
self.pad_off = pad_off
self.pad_sizes = [int(1.*(filt_size-1)/2), int(np.ceil(1.*(filt_size-1)/2)), int(1.*(filt_size-1)/2), int(np.ceil(1.*(filt_size-1)/2))]
self.pad_sizes = [pad_size+pad_off for pad_size in self.pad_sizes]
self.stride = stride
self.off = int((self.stride-1)/2.)
self.channels = channels
if(self.filt_size==1):
a = np.array([1.,])
elif(self.filt_size==2):
a = np.array([1., 1.])
elif(self.filt_size==3):
a = np.array([1., 2., 1.])
elif(self.filt_size==4):
a = np.array([1., 3., 3., 1.])
elif(self.filt_size==5):
a = np.array([1., 4., 6., 4., 1.])
elif(self.filt_size==6):
a = np.array([1., 5., 10., 10., 5., 1.])
elif(self.filt_size==7):
a = np.array([1., 6., 15., 20., 15., 6., 1.])
filt = torch.Tensor(a[:,None]*a[None,:])
filt = filt/torch.sum(filt)
self.register_buffer('filt', filt[None,None,:,:].repeat((self.channels,1,1,1)))
self.pad = get_pad_layer(pad_type)(self.pad_sizes)
def forward(self, inp):
if(self.filt_size==1):
if(self.pad_off==0):
return inp[:,:,::self.stride,::self.stride]
else:
return self.pad(inp)[:,:,::self.stride,::self.stride]
else:
return F.conv2d(self.pad(inp), self.filt, stride=self.stride, groups=inp.shape[1])
class MRA(nn.Module):
def __init__(self, channel, att_kernel, norm_layer):
super().__init__()
att_padding = att_kernel // 2
self.gate_fn = nn.Sigmoid()
self.channel = channel
self.max_m1 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
self.max_m2 = BlurPool(channel, stride=3)
self.H_att1 = nn.Conv2d(channel, channel, (att_kernel, 3), 1, (att_padding, 1), groups=channel, bias=False)
self.V_att1 = nn.Conv2d(channel, channel, (3, att_kernel), 1, (1, att_padding), groups=channel, bias=False)
self.H_att2 = nn.Conv2d(channel, channel, (att_kernel, 3), 1, (att_padding, 1), groups=channel, bias=False)
self.V_att2 = nn.Conv2d(channel, channel, (3, att_kernel), 1, (1, att_padding), groups=channel, bias=False)
self.norm = norm_layer(channel)
def forward(self, x):
x_tem = self.max_m1(x)
x_tem = self.max_m2(x_tem)
x_h1 = self.H_att1(x_tem)
x_w1 = self.V_att1(x_tem)
x_h2 = self.inv_h_transform(self.H_att2(self.h_transform(x_tem)))
x_w2 = self.inv_v_transform(self.V_att2(self.v_transform(x_tem)))
att = self.norm(x_h1 + x_w1 + x_h2 + x_w2)
out = x[:, :self.channel, :, :] * F.interpolate(self.gate_fn(att),
size=(x.shape[-2], x.shape[-1]),
mode='nearest')
return out
def h_transform(self, x):
shape = x.size()
x = torch.nn.functional.pad(x, (0, shape[-1]))
x = x.reshape(shape[0], shape[1], -1)[..., :-shape[-1]]
x = x.reshape(shape[0], shape[1], shape[2], 2*shape[3]-1)
return x
def inv_h_transform(self, x):
shape = x.size()
x = x.reshape(shape[0], shape[1], -1).contiguous()
x = torch.nn.functional.pad(x, (0, shape[-2]))
x = x.reshape(shape[0], shape[1], shape[-2], 2*shape[-2])
x = x[..., 0: shape[-2]]
return x
def v_transform(self, x):
x = x.permute(0, 1, 3, 2)
shape = x.size()
x = torch.nn.functional.pad(x, (0, shape[-1]))
x = x.reshape(shape[0], shape[1], -1)[..., :-shape[-1]]
x = x.reshape(shape[0], shape[1], shape[2], 2*shape[3]-1)
return x.permute(0, 1, 3, 2)
def inv_v_transform(self, x):
x = x.permute(0, 1, 3, 2)
shape = x.size()
x = x.reshape(shape[0], shape[1], -1)
x = torch.nn.functional.pad(x, (0, shape[-2]))
x = x.reshape(shape[0], shape[1], shape[-2], 2*shape[-2])
x = x[..., 0: shape[-2]]
return x.permute(0, 1, 3, 2)
class GA12(nn.Module):
def __init__(self, dim, act_layer):
super().__init__()
self.downpool = nn.MaxPool2d(kernel_size=2, stride=2, return_indices=True)
self.uppool = nn.MaxUnpool2d((2, 2), 2, padding=0)
self.proj_1 = nn.Conv2d(dim, dim, 1)
self.activation = act_layer()
self.conv0 = nn.Conv2d(dim, dim, 5, padding=2, groups=dim)
self.conv_spatial = nn.Conv2d(dim, dim, 7, stride=1, padding=9, groups=dim, dilation=3)
self.conv1 = nn.Conv2d(dim, dim // 2, 1)
self.conv2 = nn.Conv2d(dim, dim // 2, 1)
self.conv_squeeze = nn.Conv2d(2, 2, 7, padding=3)
self.conv = nn.Conv2d(dim // 2, dim, 1)
self.proj_2 = nn.Conv2d(dim, dim, 1)
def forward(self, x):
x_, idx = self.downpool(x)
x_ = self.proj_1(x_)
x_ = self.activation(x_)
attn1 = self.conv0(x_)
attn2 = self.conv_spatial(attn1)
attn1 = self.conv1(attn1)
attn2 = self.conv2(attn2)
attn = torch.cat([attn1, attn2], dim=1)
avg_attn = torch.mean(attn, dim=1, keepdim=True)
max_attn, _ = torch.max(attn, dim=1, keepdim=True)
agg = torch.cat([avg_attn, max_attn], dim=1)
sig = self.conv_squeeze(agg).sigmoid()
attn = attn1 * sig[:, 0, :, :].unsqueeze(1) + attn2 * sig[:, 1, :, :].unsqueeze(1)
attn = self.conv(attn)
x_ = x_ * attn
x_ = self.proj_2(x_)
x = self.uppool(x_, indices=idx)
return x
class D_GA(nn.Module):
def __init__(self, dim, norm_layer):
super().__init__()
self.norm = norm_layer(dim)
self.attn = GA(dim)
self.downpool = nn.MaxPool2d(kernel_size=2, stride=2, return_indices=True)
self.uppool = nn.MaxUnpool2d((2, 2), 2, padding=0)
def forward(self, x):
x_, idx = self.downpool(x)
x = self.norm(self.attn(x_))
x = self.uppool(x, indices=idx)
return x
class GA(nn.Module):
def __init__(self, dim, head_dim=4, num_heads=None, qkv_bias=False,
attn_drop=0., proj_drop=0., proj_bias=False, **kwargs):
super().__init__()
self.head_dim = head_dim
self.scale = head_dim ** -0.5
self.num_heads = num_heads if num_heads else dim // head_dim
if self.num_heads == 0:
self.num_heads = 1
self.attention_dim = self.num_heads * self.head_dim
self.qkv = nn.Linear(dim, self.attention_dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(self.attention_dim, dim, bias=proj_bias)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
B, C, H, W = x.shape
x = x.permute(0, 2, 3, 1)
N = H * W
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, self.head_dim).permute(2, 0, 3, 1, 4)
q, k, v = qkv.unbind(0) # make torchscript happy (cannot use tensor as tuple)
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, H, W, self.attention_dim)
x = self.proj(x)
x = self.proj_drop(x)
x = x.permute(0, 3, 1, 2)
return x
class LWGA_Block(nn.Module):
def __init__(self,
dim,
stage,
att_kernel=11,
mlp_ratio=2.0,
drop_path=0,
act_layer=nn.SiLU,
norm_layer=nn.BatchNorm2d
):
super().__init__()
self.stage = stage
self.dim_split = dim // 4
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
mlp_hidden_dim = int(dim * mlp_ratio)
mlp_layer: List[nn.Module] = [
nn.Conv2d(dim, mlp_hidden_dim, 1, bias=False),
norm_layer(mlp_hidden_dim),
act_layer(),
nn.Conv2d(mlp_hidden_dim, dim, 1, bias=False)
]
self.mlp = nn.Sequential(*mlp_layer)
self.PA = PA(self.dim_split, norm_layer, act_layer) # PA is point attention
self.LA = LA(self.dim_split, norm_layer, act_layer) # LA is local attention
self.MRA = MRA(self.dim_split, att_kernel, norm_layer) # MRA is medium-range attention
if stage == 2:
self.GA3 = D_GA(self.dim_split, norm_layer) # GA3 is global attention (stage of 3)
elif stage == 3:
self.GA4 = GA(self.dim_split) # GA4 is global attention (stage of 4)
self.norm = norm_layer(self.dim_split)
else:
self.GA12 = GA12(self.dim_split, act_layer) # GA12 is global attention (stages of 1 and 2)
self.norm = norm_layer(self.dim_split)
self.norm1 = norm_layer(dim)
self.drop_path = DropPath(drop_path)
def forward(self, x: Tensor) -> Tensor:
# for training/inference
shortcut = x.clone()
x1, x2, x3, x4 = torch.split(x, [self.dim_split, self.dim_split, self.dim_split, self.dim_split], dim=1)
x1 = x1 + self.PA(x1)
x2 = self.LA(x2)
x3 = self.MRA(x3)
if self.stage == 2:
x4 = x4 + self.GA3(x4)
elif self.stage == 3:
x4 = self.norm(x4 + self.GA4(x4))
else:
x4 = self.norm(x4 + self.GA12(x4))
x_att = torch.cat((x1, x2, x3, x4), 1)
x = shortcut + self.norm1(self.drop_path(self.mlp(x_att)))
return x
def autopad(k, p=None, d=1):
"""Pad to 'same' shape outputs."""
if d > 1:
k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k]
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k]
return p
class Conv(nn.Module):
"""Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)."""
default_act = nn.SiLU()
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
"""Initialize Conv layer with given arguments including activation."""
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
"""Apply convolution, batch normalization and activation to input tensor."""
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
"""Perform transposed convolution of 2D data."""
return self.act(self.conv(x))
class Bottleneck(nn.Module):
"""Standard bottleneck."""
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5):
"""Initializes a standard bottleneck module with optional shortcut connection and configurable parameters."""
super().__init__()
c_ = int(c2 * e)
self.cv1 = Conv(c1, c_, k[0], 1)
self.cv2 = Conv(c_, c2, k[1], 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
"""Applies the YOLO FPN to input data."""
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class C2f(nn.Module):
"""Faster Implementation of CSP Bottleneck with 2 convolutions."""
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):
"""Initializes a CSP bottleneck with 2 convolutions and n Bottleneck blocks for faster processing."""
super().__init__()
self.c = int(c2 * e)
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1)
self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))
def forward(self, x):
"""Forward pass through C2f layer."""
y = list(self.cv1(x).chunk(2, 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
def forward_split(self, x):
"""Forward pass using split() instead of chunk()."""
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
class C3(nn.Module):
"""CSP Bottleneck with 3 convolutions."""
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
"""Initialize the CSP Bottleneck with given channels, number, shortcut, groups, and expansion values."""
super().__init__()
c_ = int(c2 * e)
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1)
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, k=((1, 1), (3, 3)), e=1.0) for _ in range(n)))
def forward(self, x):
"""Forward pass through the CSP bottleneck with 2 convolutions."""
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), 1))
class C3k2(C2f):
"""Faster Implementation of CSP Bottleneck with 2 convolutions."""
def __init__(self, c1, c2, n=1, c3k=False, e=0.5, g=1, shortcut=True):
"""Initializes the C3k2 module, a faster CSP Bottleneck with 2 convolutions and optional C3k blocks."""
super().__init__(c1, c2, n, shortcut, g, e)
self.m = nn.ModuleList(
C3k(self.c, self.c, 2, shortcut, g) if c3k else Bottleneck(self.c, self.c, shortcut, g) for _ in range(n)
)
class C3k(C3):
"""C3k is a CSP bottleneck module with customizable kernel sizes for feature extraction in neural networks."""
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5, k=3):
"""Initializes the C3k module with specified channels, number of layers, and configurations."""
super().__init__(c1, c2, n, shortcut, g, e)
c_ = int(c2 * e)
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, k=(k, k), e=1.0) for _ in range(n)))
class C3k_LWGA(C3k):
def __init__(self, c1, c2, n=1, stage=None, shortcut=False, g=1, e=0.5, k=3):
super().__init__(c1, c2, n, shortcut, g, e, k)
c_ = int(c2 * e) # hidden channels
self.m = nn.Sequential(*(LWGA_Block(c_, stage) for _ in range(n)))
class C3k2_LWGA(C3k2):
def __init__(self, c1, c2, n=1, stage=None, c3k=False, e=0.5, g=1, shortcut=True):
super().__init__(c1, c2, n, c3k, e, g, shortcut)
self.m = nn.ModuleList(C3k_LWGA(self.c, self.c, 2, stage, shortcut, g) if c3k else LWGA_Block(self.c, stage) for _ in range(n))
注册
在ultralytics/nn/tasks.py中进行如下操作:
步骤1:
from ultralytics.nn.C3k2.C3k2_LWGA import C3k2_LWGA
步骤2
修改def parse_model(d, ch, verbose=True):
C3k2_LWGA
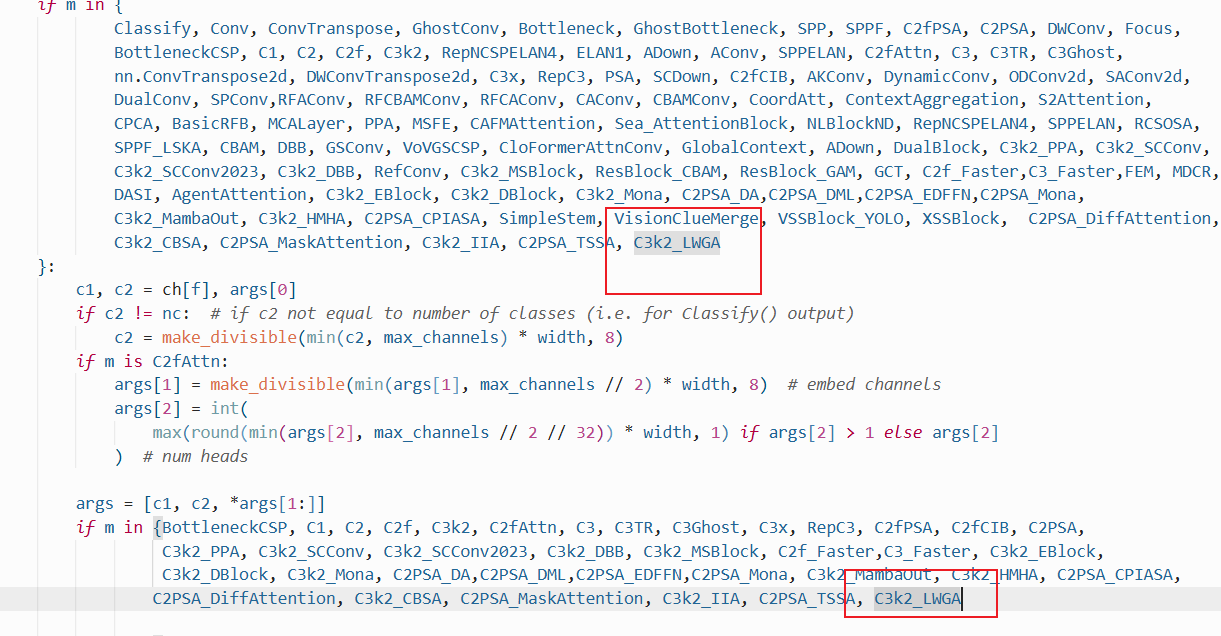
配置yolo11-C3k2_LWGA.yaml
ultralytics/cfg/models/11/yolo11-C3k2_LWGA.yaml
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLO11 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPs
s: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPs
m: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPs
l: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPs
x: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs
# YOLO11n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 2, C3k2_LWGA, [256, False, 0.25]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 2, C3k2_LWGA, [512, False, 0.25]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 2, C3k2_LWGA, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 2, C3k2_LWGA, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 2, C2PSA, [1024]] # 10
# YOLO11n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C3k2_LWGA, [512, False]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C3k2_LWGA, [256, False]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 2, C3k2_LWGA, [512, False]] # 19 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 2, C3k2_LWGA, [1024, True]] # 22 (P5/32-large)
- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)
解决报错:
RuntimeError: The size of tensor a (21) must match the size of tensor b (20) at non-singleton dimension 3\
修改 ultralytics\models\yolo\detect\train.py 的 class DetectionTrainer(BaseTrainer):
把
return build_yolo_dataset(self.args, img_path, batch, self.data, mode=mode, rect=mode == "val", stride=gs)
替换为
return build_yolo_dataset(self.args, img_path, batch, self.data, mode=mode, rect=False, stride=gs)
实验
脚本
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
#
if __name__ == '__main__':
# 修改为自己的配置文件地址
model = YOLO('./ultralytics/cfg/models/11/yolo11-C3k2_LWGA.yaml')
# 修改为自己的数据集地址
model.train(data='./ultralytics/cfg/datasets/coco8.yaml',
cache=False,
imgsz=640,
epochs=10,
single_cls=False, # 是否是单类别检测
batch=8,
close_mosaic=10,
workers=0,
optimizer='SGD',
amp=True,
project='runs/train',
name='yolo11-C3k2_LWGA',
)
结果


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 30
30 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)