RAFT: Recurrent All-Pairs Field Transforms for Optical Flow
本文提出了Recurrent All-Pairs Field Transforms(RAFT), 一个光流估计的深度神经网络. RAFT 提取像素级的特征, 为所有像素建立多尺度 4D 关联信息, 通过查找4D关联信息, 循环迭代的更新光流场. 本文算法在KITTI、Sintel数据集上取得了state-of-the-art的表现. 同时, RAFT在多个数据集上有很强的泛化能力, 并且在训练速度
0. 摘要
本文提出了递归全对场变换 (RAFT),一种新的光流深度网络结构。RAFT提取过像素特征,为所有像素对构建多尺度的四维相关卷,并通过一个对相关卷进行查找的循环单元迭代地更新流场。RAFT实现了最先进的性能。在KITTI上,RAFT的F1-all误差为5.10%,比最佳发布的结果 (6.10%) 减少了16%。在Sintel(最后通过)上,RAFT得到了2.855像素的终点误差,比已发布的最佳结果(4.098像素)减少了30%。此外,RAFT具有较强的跨数据集泛化性,在推理时间、训练速度和参数计数方面都具有较高的效率。
1. 引言
光流是估计视频帧之间每像素运动的任务。这是一个长期存在的尚未解决的愿景问题。最好的系统受到困难的限制,包括快速移动的物体、遮挡、运动模糊和无纹理的表面。
光流传统上被认为是在一对图像[21, 51, 13]之间的密集位移场空间上的一个手工制作的优化问题。一般来说,优化目标定义了鼓励视觉相似图像区域对齐的数据项和先加于运动合理性的正则化项之间的权衡。这种方法已经取得了相当大的成功,但由于难以手工设计一个对各种角落情况具有稳健性的优化目标,进一步的进展似乎具有挑战性。
最近,深度学习已被证明是一种很有前途的替代传统方法。深度学习可以逐步制定优化问题,训练网络直接预测流程。目前的深度学习方法[25, 42, 22, 49, 20]已经取得了可与最佳传统方法相媲美的性能,同时在推理时速度明显更快。进一步研究的一个关键问题是设计有效的性能更好、更容易训练和很好地推广到新场景的架构。
我们介绍了递归全对场变换 (RAFT),一种新的光流深度网络结构。RAFT具有以下优点:
- 最先进的准确性
- 强大的泛化性
- 高效性
RAFT由三个主要组件组成:(1) 特征编码器,提取每个像素的特征向量;(2) 相关层,为所有像素对产生四维相关卷,随后池产生低分辨率卷;(3) 一个基于GPU的循环更新操作运算,从相关卷中检索值,并迭代更新初始化的流场。图1说明了RAFT的设计。
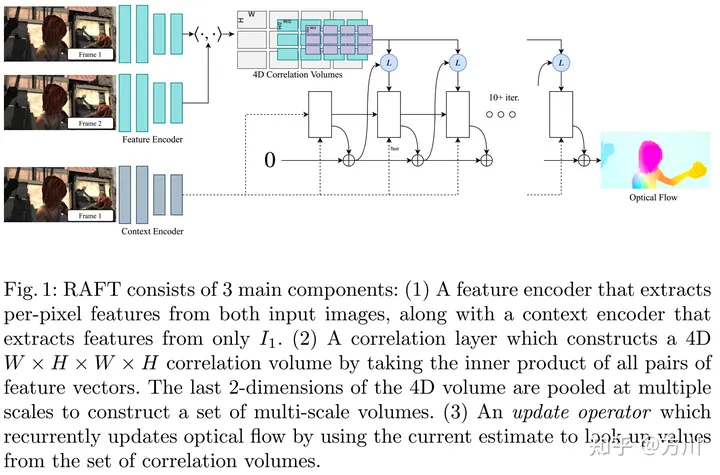
RAFT架构采用了传统的基于优化的方法。该特征编码器提取每个像素的特征。相关层计算像素之间的视觉相似性。该更新操作符模拟了一个迭代优化算法的步骤。但与传统方法不同的是,特征和运动先验不是手工制作的,而是分别由特征编码器和更新运算符学习的。
RAFT的设计从许多现有的作品中汲取灵感,但在本质上是新颖的。首先,RAFT以高分辨率维护和更新单个固定流场。这与之前的工作[42, 49, 22, 23, 50]中流行的从粗到细的设计不同,后者首先以低分辨率估计流量,并在高分辨率下进行上采样和细化。通过在单个高分辨率流场上运行,RAFT克服了粗到细级联的几个限制:从粗分辨率的错误中恢复的差异,错过小型快速移动对象的倾向,以及训练多层级联通常需要的许多训练迭代(通常超过1M)。
其次,RAFT的更新操作符是周期性的和轻量级的。[24,42,49,22,25]最近的许多工作都包括了某种形式的迭代细化,但没有绑定跨迭代[42,49,22]的权重,因此被限制在固定数量的迭代中。据我们所知,IRR[24]是唯一一种反复出现的深度学习方法[24]。它使用FlowNetS[15]或PWC-Net[42]作为其循环单元。当使用FlowNetS时,它受到网络大小(38M参数)的限制,并且只应用5次迭代。当使用PWC-Net时,迭代受到金字塔级别数量的限制。相比之下,我们的更新操作算子只有2.7M的参数,在推理过程中可以应用100+次而不发散。
第三,更新操作符有一个新颖的设计,它由一个卷积GRU组成,可以在4D多尺度相关卷上进行查找;相比之下,之前工作中的细化模块通常只使用普通卷积或相关层。
我们对Sintel[11]和KITTI[18]进行了实验。结果表明,RAFT在两个数据集上都取得了最先进的性能。此外,我们通过广泛的消融研究验证了RAFT的各种设计选择。
2. 相关工作
2.1. 光流作为能量最小化
光流传统上被视为一个能量最小化问题,它在数据项和正则化项之间进行权衡。Horn和Schnuck[21]将光流作为一个使用变分框架的连续优化问题,并能够通过执行梯度步骤来估计一个密集的流场。Black和Anandan[9]通过引入一个鲁棒估计框架来解决过平滑和噪声灵敏度的问题。TV-L1[51]用L1数据项和全变化正则化取代了二次惩罚,这允许运动不连续,并能更好地处理异常值。通过定义更好的匹配成本[45,10]和正则化项[38],已经进行了改进。
这种连续公式保持了光流的单一估计,每次迭代都经过改进。为了保证目标函数的光滑,采用一阶泰勒近似法对数据项进行建模。因此,它们只适用于较小的位移,为了处理大的位移,使用了从粗到细的策略,其中使用图像金字塔来估计低分辨率的大位移,然后细化高分辨率的小位移。但是这种从粗到细的策略可能会错过快速移动的小物体,并且很难从早期的错误中恢复过来。与连续方法一样,我们保持光流的单一估计,每次迭代进行改进。然而,由于我们在高分辨率和低分辨率下为所有对构建相关量,每个局部更新都使用关于小位移和大位移的信息。此外,我们的更新算符没有使用数据项的亚像素泰勒近似,而是学习提出下降方向。
最近,光流也被认为为一个使用全局目标的离散优化问题[35,13,47]。这种方法的一个挑战是搜索空间的巨大大小,因为每个像素都可以合理地与另一帧中的数千个点配对。Menez等人使用特征描述符来修剪搜索空间,并使用消息传递来逼近全局MAP估计。陈等人。[13]表明,利用距离变换,求解整个流场空间上的全局优化问题是易于处理的。DCFlow[47]通过使用神经网络作为特征描述符进行了进一步的改进,并构建了所有特征对的四维代价体积。然后使用半全局匹配 (SGM) 算法[19]对四维成本量进行处理。与DCFlow一样,我们也在学习到的特性上构建了4D成本卷。然而,我们没有使用SGM来处理成本量,而是使用一个神经网络来估计流量。我们的方法是端到端可微的,这意味着特征编码器可以与网络的其余部分一起进行训练,以直接最小化最终流量估计的误差。相比之下,DCFlow要求使用像素之间的嵌入损失进行训练;它不能直接对光流进行训练,因为它们的损失量处理是不可区分的。
2.2. 直接流预测
神经网络经过训练可以直接预测一对帧之间的光流,回避了优化问题完全地。从粗到精的加工已成为一种流行的成分许多最近的作品。相反,我们的方法保持并更新单个高分辨率流场。
2.3. 光流的迭代细化
最近的许多工作都使用迭代细化来改进光流的结果和相关任务。伊尔格等人将迭代细化应用于光流通过串联堆叠多个 FlowNetS 和 FlowNetC 模块。间谍网[39],PWC-Net[42]、LiteFlowNet[22] 和 VCN[49] 使用迭代细化由粗到细的金字塔。这些方法与我们的主要区别是他们在迭代之间不共享权重。
与我们的方法更密切相关的是 IRR[24],它建立在FlownetS和PWC-Net架构,但在细化之间共享权重网络。使用FlowNetS时,受到网络大小(38M参数)的限制,最多只能应用5次迭代。使用PWC-Net时,迭代受到金字塔级别数的限制。相比之下,我们使用了很多更简单的细化模块(270万个参数),可以在推理过程中应用 100 多次迭代而不会发散。我们的方法也与 Devon [31] 有相似之处,即构建不扭曲的成本量和固定分辨率更新。然而,德文郡没有任何经常单位。在大排量方面它也与我们不同。
德文郡使用扩张的成本量来处理大位移,而我们的方法则汇集了相关性多种分辨率下的音量。
我们的方法还与 TrellisNet [5] 和深度均衡模型有联系(DEQ)[6]。网格网在大量层上使用深度绑定权重,DEQ 通过直接求解不动点来模拟无限层。TrellisNet 和 DEQ 是为序列建模任务而设计的,但我们采用使用大量权重绑定单元的核心思想。我们的更新操作符使用修改后的 GRU 块[14],它类似于 中使用的 LSTM 块格子网。我们发现这个结构允许我们的更新操作符更多容易收敛到固定流场。
2.4. 学习优化
视觉中的许多问题都可以表述为一个优化问题。这促使一些工作嵌入优化将问题纳入网络架构中。这些作品通常使用网络来预测优化问题的输入或参数,以及然后通过反向传播梯度来训练网络权重求解器,隐式[4,3]或展开每个步骤[32,43]。然而,这项技术仅限于具有易于定义的目标的问题。
另一种方法是直接从数据中学习迭代更新[1,2]。这些方法的动机是一阶优化器(例如 Primal)对偶混合梯度 (PDHG) [12] 可以表示为迭代序列更新步骤。Adler 等人没有直接使用优化器。[1] 提议构建一个模仿一阶算法更新的网络。该方法已应用于图像去噪等逆问题[26],断层扫描重建[2]和新颖的视图合成[17]。TVNet [16]将TV-L1 算法实现为计算图,这使得训练 TV-L1 参数。然而,TVNet直接基于强度梯度而不是学习的特征,这限制了可实现的精度具有挑战性的数据集,例如 Sintel。
我们的方法可以被视为学习优化:我们的网络使用大量更新块来模拟一阶优化的步骤算法。然而,与之前的工作不同,我们从未明确定义梯度尊重某些优化目标。相反,我们的网络检索特征从相关量来提出下降方向。
3. 方法
RAFT网络由三部分组成:
(1) 特征编码层:逐像素的提取特征;
(2) 特征关联层:为所有像素产生WxHxWxH的4D关联信息,并且使用了汇合层来产生更低分辨率的关联信息;
(3) 循环更新算子:基于GRU的循环更新算子查找4D关联信息,然后迭代的更新光流场,光流场初始值为0。
3.1. 特征提取
RAFT提取的特征分为两种:第一种是匹配特征,左右影像共享同样的权重,提取的特征主要用于匹配;因此,这个网络最后会更倾向于提取保证稳健匹配的特征。第二种是内容特征,仅仅在左影像上提取,主要用于对光流结果进行优化,其实就是一个导向滤波,最后这个网络会更倾向于判断那些区域的光流更可能是一致的。
针对第二个网路,RAFT也表明,其实也可以用匹配特征来进行优化;但是用两个网络的效果更好。
3.2. 计算视觉相似度
上一步得到两幅图像的特征张量,
,correlation volume C的计算方法:
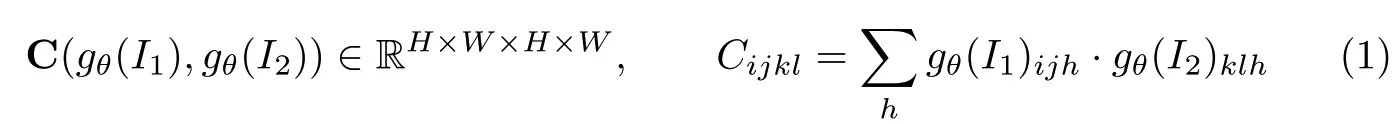
3.2.1. correlation pyramid
这样一个相关信息张量C是非常大的,因此在C的最后两个维度上进行汇合来降低维度大小,产生4个相关信息,每个的维度为
。保持前两个维度不变,这种相关信息张量可以保证同时捕捉到较大和较小的像素位移。
3.2.2. correlation lookup
上一步构建了4 levels correlation volumes,在接下来的光流场估计中需要用到correlation volume,但是并非是这么大的correlation volume全部都用,对于每个像素而言只需要查找出与他相关的correlation region即可。我们在寻找像素的pixel correspondence时可以利用当前的光流场估计
,把图像
上的x映射到图像
上的
。因此可以定义一个搜索域:
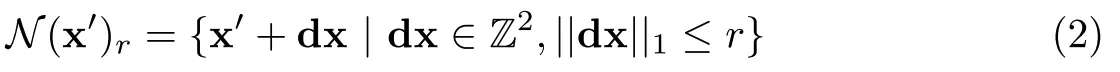
r为二维图像平面上的搜索半径。基于对于每个相关信息张量都查找一个feature map,然后将这四个feature map拼接起来。
3.2.3. Efficient computation for high resolution images
理论上这个4D correlation volume只需要计算一次,在后续的迭代过程中之需要去查找相关的correlation volume即可。但其实可以不用计算这么大的相关信息张量。对于第m层的correlation volume
:
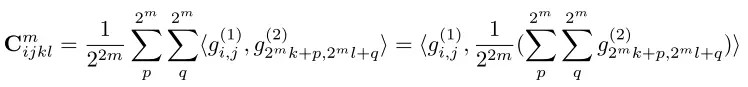
其中,
。这意思是说像素 (i, j) 和 (k, l) 之间的相关信息其实是
的网格上的相关信息的均值,因此
的计算只需要在由
卷积核下采样后的图像上计算就可以了,并且可是在需要时再计算
。
3.3. 迭代更新
更新算子这部分的输入是上一次估计的flow fileds,相关信息张量和循环卷积的隐藏状态,输出更新后的和更新后的隐藏层状态。
初始化:默认将初始光流场置为0
输入:根据当前的光流场估计值在correlation volume中查找correlation feature,索引到的这些correlation feature map又送入两层卷积层;同时我们对
后面也加上两层卷积操作;还有从context 网络输出的feature map;correlation feature map,flow feature map和context feature map拼接起来送入更新算子。
更新:更新算子的核心是卷积GRU模块,是输入的拼接feature map。
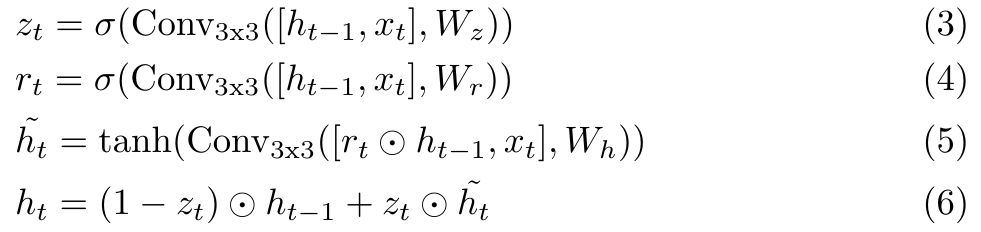
光流估计:GRU输出的隐藏状态经过两层卷积后得到的就是光流场更新,该值为输入图像分辨率的1/8的光流场更新值,因此需要吧光流场上采样后才能与Ground Truth对比。
上采样:上采样后的高分辨率光流场是维度为的张量。
3.4. 监督方法
本文选用预测值和GT之间的累积距离作为loss函数,
为累计因子:

4. 实验结果
本文的网络首先在 FlyChairs 和 FlyThings 数据集上进行预训练,然后在特定的数据上进行优化训练。最终KITTI、Sintel数据集以及高分辨率的DAVIS数据集上取得了sota的结果。

具体的训练过程还是挺耗时的,本文使用了2块2080Ti GPU,首先在FlyThings和FlyingThings3D上各训练100K次,接着在Sintel,KITTI-2015等混合数据上训练了100K次,最后又在KITTI-2015数据集上训练50K次。
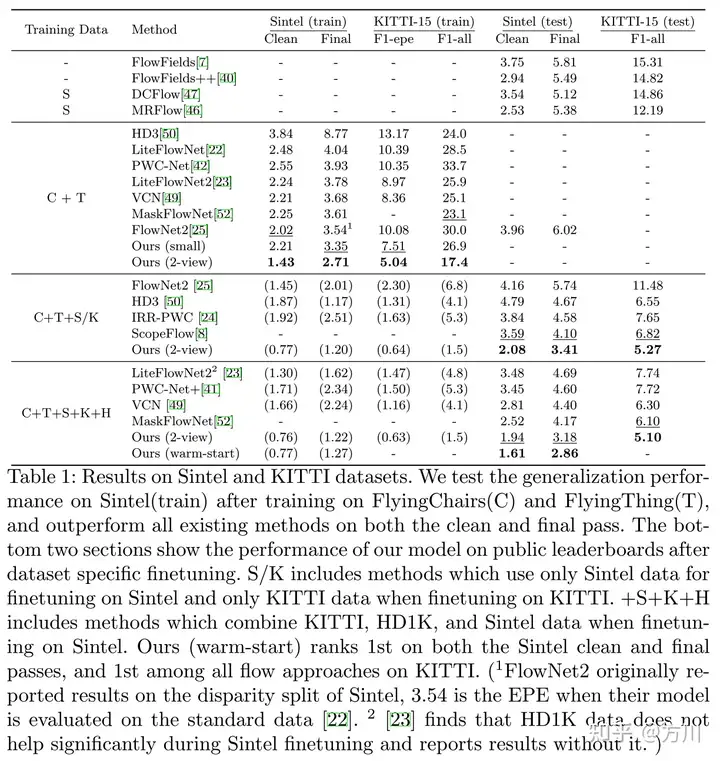
预测结果与其他光流方法的对比:
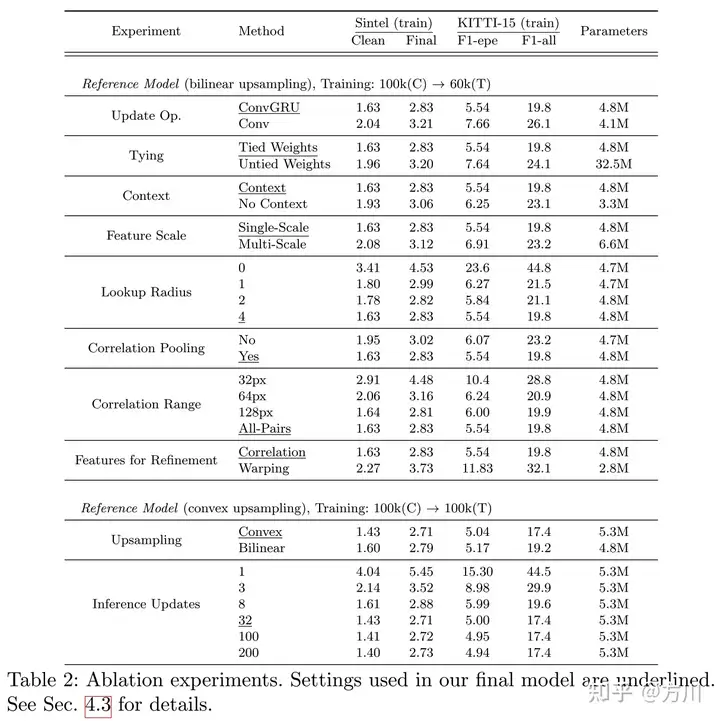
消融实验:
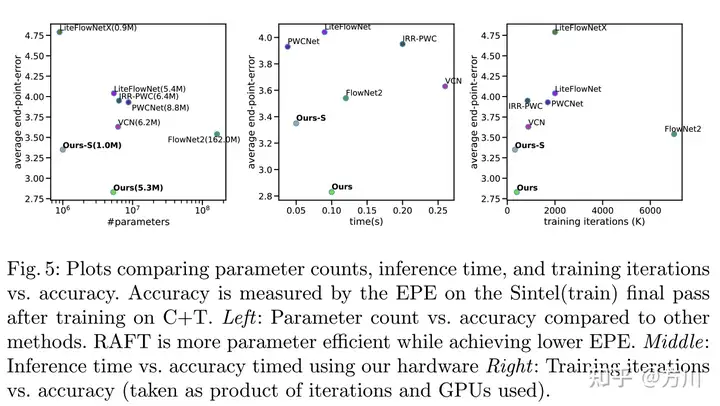
本文网络与其他网络的能效对比:
参考文献
RAFT: Recurrent All-Pairs Field Transforms for Optical Flow

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 30
30 0
0- 0



 已为社区贡献87条内容
已为社区贡献87条内容

所有评论(0)