【Agent】Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models
这篇论文提出的ACE框架通过生成、反射和整理的结构化工作流程,有效地解决了简洁偏差和上下文坍塌问题。ACE在代理和特定领域基准测试中均表现出色,显著提高了模型性能,同时降低了适应延迟和成本。ACE的成功展示了全面、不断发展的上下文在构建可扩展、高效和自改进的LLM系统中的潜力。- 当前主流 prompt / memory / reflection 方法的两个系统性缺陷:- Brevity Bias
·
note
- 这篇论文提出的ACE框架通过生成、反射和整理的结构化工作流程,有效地解决了简洁偏差和上下文坍塌问题。ACE在代理和特定领域基准测试中均表现出色,显著提高了模型性能,同时降低了适应延迟和成本。ACE的成功展示了全面、不断发展的上下文在构建可扩展、高效和自改进的LLM系统中的潜力。
- 当前主流 prompt / memory / reflection 方法的两个系统性缺陷:
- Brevity Bias(“越改越短”偏置):压缩成为通用的废话
- Context Collapse(上下文坍缩):有时压缩过于厉害,准确率比不用 context engineering还低
- ACE框架:Generator → Reflector → Curator
- Generator:正常做任务(推理、写代码、用工具)
- Reflector:站在“老师/复盘者”角度,总结 成功策略 & 失败原因
- Curator:不用 LLM,用规则逻辑把新知识并入 context
- 核心设计:
- 把“反思”和“写 context”彻底解耦;LLM 只负责认知工作,Context 的结构演化权力交给确定性逻辑
- Incremental Delta Updates(增量更新)
- Grow-and-Refine(先长再修):宁可冗余,也不要丢信息
- context 自进化 ≈ RL 效果,但成本更低
- 局限性:强依赖 Reflector 质量
一、研究背景
- 研究问题:这篇文章要解决的问题是如何在不训练模型权重的情况下,通过上下文适应来提高大型语言模型(LLM)的性能。具体来说,现有的上下文适应方法存在简洁偏差和上下文坍塌的问题,前者会导致领域洞察力的丢失,后者则会导致详细信息的丢失。
- 研究难点:该问题的研究难点包括:如何在保持详细知识的同时防止上下文坍塌,如何在不依赖标注监督的情况下进行有效的上下文适应,以及如何在大规模长上下文模型中实现可扩展的自适应。
- 相关工作:该问题的研究相关工作包括Reflexion、TextGrad、GEPA和Dynamic Cheatsheet等方法,这些方法通过自然语言反馈来改进LLM系统,但在简洁偏差和上下文坍塌问题上仍存在不足。
二、Agentic Context Engineering
这篇论文提出了ACE(Agentic Context Engineering)框架,用于解决上下文适应中的简洁偏差和上下文坍塌问题。具体来说:
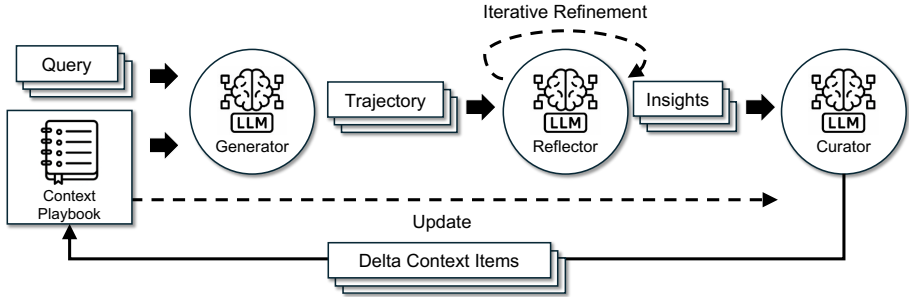
- 生成器(Generator):生成器负责生成推理轨迹,这些轨迹不仅展示了有效的策略,还揭示了常见的陷阱。生成器使用DeepSeek-V3.1模型的非思考模式。
- 反射器(Reflector):反射器从生成的推理轨迹中提取教训,并在多个迭代中对其进行精炼。反射器的目标是分离评估和洞察提取与整理工作,从而提高上下文质量和下游性能。
- 整理器(Curator):整理器将反射器提炼的教训整合成紧凑的增量条目,并通过轻量级、非LLM逻辑将其合并到现有上下文中。增量更新和增长-精炼机制确保了上下文的适应性、可解释性,并避免了单一上下文重写引入的潜在方差。
三、实验部分
- 数据集:实验在两个类别的LLM应用上进行评估:代理基准测试和特定领域基准测试。代理基准测试使用AppWorld数据集,涉及API理解、代码生成和环境交互。特定领域基准测试使用金融分析数据集,包括FiNER和Formula任务。
- 评估指标:对于AppWorld,使用任务目标完成度(TGC)和场景目标完成度(SGC)作为评估指标。对于FiNER和Formula,使用准确率作为评估指标,即预测答案与真实答案完全匹配的比例。
- 基线方法:基线方法包括直接使用默认提示的Base LLM、In-Context Learning(ICL)、MIPROv2和GEPA。所有方法都在官方实现的ReAct框架上构建。
四、实验结论
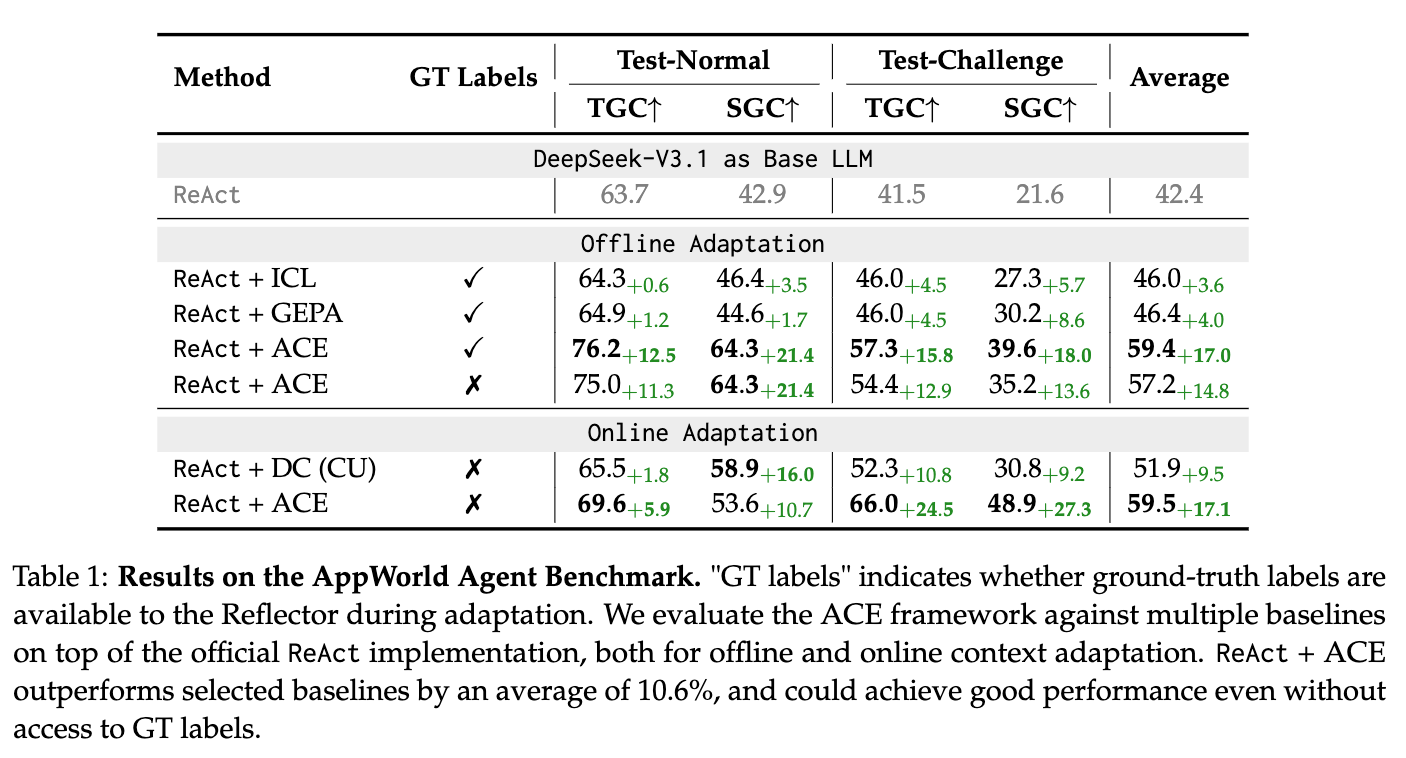
- 代理基准测试:在离线设置中,
ReAct+ACE比ReAct+ICL和ReAct+GEPA分别提高了12.3%和11.9%。在线设置中,ACE比Dynamic Cheatsheet平均提高了7.6%。在没有标注监督的情况下,ReAct+ACE比ReAct基线提高了14.8%。 - 特定领域基准测试:在离线设置中,ACE比ICL、MIPROv2和GEPA分别提高了10.9%。在线设置中,ACE比Dynamic Cheatsheet平均提高了6.2%。
- 成本和时间分析:ACE在减少适应延迟和token美元成本方面表现出色。例如,在AppWorld的离线适应中,ACE的适应延迟减少了82.3%,令牌美元成本减少了75.1%。在FiNER的在线适应中,ACE的适应延迟减少了91.5%,token美元成本减少了83.6%。
注意:上面的ReAct+ACE是没有GT label(即ground truth),比如如果有的GT时,reflector可以看到代码执行错误(错误代码)和正确代码,但没有GT则是reflector只能看到执行过程和其他反馈(比如单元测试、报错信息等),但看不到正确代码。
五、优势和劣势
1、优点与创新
- 全面的上下文适应:ACE(Agentic Context Engineering)框架将上下文视为不断演变的剧本,通过生成、反思和策划的模块化过程积累、精炼和组织策略。
- 防止上下文坍塌:通过结构化的增量更新,ACE保留了详细的领域特定知识,防止了上下文在迭代重写过程中逐渐减少信息的问题。
- 无需标签监督:ACE能够在没有标签监督的情况下有效地进行适应,而是利用自然执行反馈和环境信号,这是自我改进的LLMs和代理的关键成分。
- 显著降低适应延迟和部署成本:ACE在适应过程中需要的重放次数和美元成本显著减少,平均适应延迟降低了86.9%。
- 多任务和多领域的适用性:ACE在代理和任务特定的基准测试中表现出色,不仅在代理任务上提升了10.6%,在金融分析基准上也提升了8.6%。
- 模块化的工作流程:ACE引入了生成器、反射器和策划器三个角色,分别负责生成推理轨迹、提炼具体见解和整合这些见解到结构化上下文更新中。
2、不足与反思
- 对强反射器的依赖:ACE的成功依赖于一个强大的反射器,如果反射器未能从生成的轨迹或结果中提取有意义的见解,构建的上下文可能会变得嘈杂甚至有害。
- 领域特定任务的挑战:在没有模型可以提取有用见解的领域特定任务中,构建的上下文自然会缺乏这些见解。
- 长上下文的成本问题:尽管ACE生成了比GEPA更长的上下文,但这并不意味着线性更高的推理成本或GPU内存使用。然而,现代服务基础设施通过缓存、压缩和卸载等技术优化了长上下文工作负载的成本。
- 在线和持续学习的应用:ACE为在线和持续学习提供了一个灵活且高效的替代方案,但需要进一步研究如何在分布偏移和有限训练数据的情况下应用ACE。
Reference
[1] Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models:https://arxiv.org/abs/2510.04618
[2] Agentic上下文工程登场,无需微调实现模型进化
[3] AppWorld: A Controllable World of Apps and People
for Benchmarking Interactive Coding Agents
[4] https://appworld.dev/

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 16
16 0
0- 0



 已为社区贡献86条内容
已为社区贡献86条内容

所有评论(0)