大模型智能体记忆技术深入研究
MemoryBank 的代表性做法是:把交互历史压缩成 summary,再作为长期记忆注入后续会话。它解决了上下文窗口有限的硬约束:不可能把所有历史原文都塞回 prompt,只能。
把大模型记忆拆成三维坐标与六类原子操作,带你看清智能体如何获得可进化、可检索、可遗忘的长期记忆。

1 记忆三维坐标
1.1 表征:参数化 vs 上下文记忆
✅ 参数化记忆是什么 参数化记忆指写进模型参数里的知识。它的典型形态是:不提供外部资料,模型仍能回答世界常识、领域知识、语言规律:这部分能力来自预训练/微调把知识固化进权重。
它的优点是:调用成本低:推理时不必访问外部存储;泛化强:能把统计规律迁移到新问题;输出更流畅:知识与生成模型天然耦合。
但也有代价:更新难:知识过时或错误时,改权重成本高;可控性弱:很难精确只删掉某条记忆;可追溯性差:回答很难给出明确来源(除非另加机制)。
✅ 上下文记忆是什么
上下文记忆指存在模型外部或输入上下文里的记忆,常见形态包括:对话历史、多轮会话归档、事件记录、日志、文档库、知识库、向量库、KV Cache 管理等。它更像工程系统:写入、索引、检索、拼装进提示词(Prompt)或工具调用结果中。
它的优点是:好更新:写库、改库、删库都比改权重容易;可解释:可以指向具体文档/事件;容量大:可存多会话、多用户、多模态。
代价是:链路复杂:索引、召回、重排、拼装都可能出错;延迟与成本:检索与多次调用会增加时延;一致性问题:新旧信息冲突时要解决信谁。
1.2 结构:非结构化 vs 结构化

✅ 非结构化记忆
-
对话历史(multi-turn / multi-session dialogue)
-
事件文本(events)
-
Web logs、用户偏好、工具调用记录
-
多模态原始信息:图像、音频、视频描述等
-
KV Cache(从缓存管理角度也可视为一种短期非结构化记忆)
它的特点是:写入快、表达自由,但检索依赖好索引与好切分。
✅ 结构化记忆
-
知识图谱(KG)、语义网、schema
-
表格、数据库记录
-
结构化经验(experience)、技能库(skills / tool recipes)
结构化记忆的特点是:查询精确、可执行性强,但构建与维护成本高。很多智能体在能做事这件事上,最终会走向半结构化/结构化的记忆形态:比如把关键实体、时间戳、因果关系、工具参数以字段形式存下来。
1.3 时间:短期、长期与工作记忆
✅ 短期记忆
按时间尺度定义:当前时间窗口内临时保存的信息,用于即时生成与局部推理。常见包含:
-
当前 session 的对话历史(上下文窗口里能看到的)
-
KV Cache(token 级缓存)
-
当前环境状态与历史(比如任务进度、已执行工具、临时变量)
✅ 长期记忆
跨更长交互周期仍然保留的信息。它既可以是:
-
参数化长期记忆(写进模型权重)
-
上下文长期记忆(归档、文档库、知识库、图谱、经验库等)
✅ 工作记忆 ≠ 短期记忆
-
短期记忆更像静态时间窗口内的信息。
-
工作记忆更像工作台:短期记忆 + 被激活的长期记忆 + 主动操作(选择、改写、排序、对齐目标)。
1.4 功能:语义、情景、程序与工作记忆
✅ 语义记忆 世界知识、概念、规则、profile、结构化知识(表/图谱/schema)。它回答是什么/为什么。
✅ 情景记忆 对话历史、事件、空间/时间上下文等个体经历,回答发生过什么。
✅ 程序记忆 技能与流程:做事的方法、工具使用套路、可复用的任务计划(skill library)。回答怎么做。很多能执行任务的智能体,真正的能力差异就在程序记忆的质量与可复用程度。
✅ 工作记忆 用于当前推理与决策的激活态记忆(可看作短期 + 激活长期 + 主动操作),典型系统会维护一个 buffer,并用 FIFO/优先级策略调度(材料里提到 MemGPT 的经典做法之一)。
2 记忆智能体的演进脉络
2.1 从范式到方法
范式先行:把记忆放进智能体框架。在较早的智能体框架工作中,研究者给出一种智能体范式:明确划分 working memory、long-term memory、short-term memory,并给出它们在交互循环里的位置:这一步的意义在于:
-
让记忆从提示词技巧升级为系统组件;
-
明确写入/读取/更新/遗忘的接口位置;
-
为后续方法学工作提供公共问题定义。
2.2 2023:程序记忆
把 skill library 当作程序记忆。在寄生/依附于环境的智能体里,把技能库视为 procedure memory。它带来一个工程上非常值钱的结论:
-
记忆不只是存文本,还要存可执行能力;
-
技能与经验一旦被结构化,检索与复用的收益会指数级上升;
-
智能体的长期成长,往往不是记住更多闲聊细节,而是沉淀更多可复用的动作序列。
2.3 2024:MemoryBank
✅ Summarization:用摘要把对话变成可长期存储的记忆
MemoryBank 的代表性做法是:把交互历史压缩成 summary,再作为长期记忆注入后续会话。它解决了上下文窗口有限的硬约束:不可能把所有历史原文都塞回 prompt,只能选择性保留。
✅ Ebbinghaus:用遗忘曲线管理记忆衰减
基于艾宾浩斯遗忘曲线设计遗忘机制:
-
记忆不是越多越好,冗余与过时会降低检索精度;
-
遗忘提供一种主动清理,减少噪声与风险;
-
遗忘策略还能做成可解释规则(随时间衰减、随使用频次增强)。
2.4 2025:自进化与多模态记忆
✅ 记忆会被重写
Stanford 的 ACE 框架提出自进化记忆:智能体在与外界交互时,不只是追加记录,还会重写既有记忆(更正、抽象、合并、提升为规则)。这把记忆从档案馆变成会自我修订的知识系统。
✅ 多模态记忆:M³-Agent 的方向感
M³-Agent 关注 multimodal memory,把视觉、文本、音频融合成 memory augmented 体系。现实世界里,很多关键记忆本来就不是文字:
-
一张设备铭牌照片
-
一段会议录音
-
一段操作视频
-
一次屏幕截图的 UI 状态
多模态记忆很可能是下一代记忆系统的主航向:记忆条目不再是纯文本 chunk,而是跨模态的统一事件。
3 六类原子操作:编码—演化—适配
把记忆看作一个流动的生命周期,并拆成三个阶段:Encoding(编码)、Evolving(演化)、Adapting(适配),以及六种原子操作。下面按工程视角把它们落到做系统要怎么实现。
3.1 记忆巩固:从短期到持久
本质是把当前时间窗口的交互与经验转换为更稳定的存储形态。它分两条路线:
✅ 参数化巩固(写进权重)
按时间尺度由短到长:
-
Continuous Learning:持续交互中不断吸收经验(但要处理灾难性遗忘与稳定性问题);
-
Post-training:针对特定场景收集数据后做 SFT / RL 等任务适配;
-
Mid-training:面向更大领域(如 code/math)做阶段性训练;
-
Pre-training:最长期、最大规模,把通用世界知识固化进模型。
工程含义:参数化巩固是慢变量,适合大规模、低频更新;否则你会被训练成本拖死。
✅ 上下文巩固(写进外部记忆)
-
Token-level caching:KV Cache 让短期推理更快,但不适合作长期;
-
Context compression:把长对话压缩成摘要/关键事实/要点;
-
Episode archiving(归档):把一次会话或一次任务作为 episode 存入长期库。
3.2 记忆索引:为找得到而生
很多系统只做存和搜,忽略了索引本身就是一等公民。索引要解决的是:大规模记忆下,如何快速定位候选?如何降低召回噪声?如何让检索更稳定、可控?
✅ 两种索引思路:内容向量 vs 元信息
-
关键词/向量索引:抽取 query 的关键 token/关键词,映射到 embedding 向量空间做近邻搜索。
-
元信息索:存时间戳、会话 ID、关键实体、超短摘要、任务类型、置信度等字段;检索时先用元信息过滤,再做向量相似度或 BM25。。
✅ 工程要点:索引不是越多越好
-
粒度过小:召回碎片化,拼装难;
-
过大:相似度被稀释,命中率下降;
-
元信息过多:写入成本高,质量参差反而引噪声。
一个常见的稳健做法是:混合检索(BM25 + Embedding)+ 轻量元信息过滤 + 重排(rerank)。
3.3 记忆更新:让旧记忆跟上现实
更新是智能体长期可靠性的生命线:不更新就会陈旧,乱更新就会漂移。
✅ 参数化更新:Model Editing 用 model editing 定位并修改模型某部分知识,实现对特定 entity/事实的更新。工程上它强调两件事:
-
更新要局部化,避免牵一发动全身;
-
更新要可验证,避免把幻觉写进权重。
✅ 上下文更新:增量摘要、KG editing、Contextual CRUD
-
增量摘要:第一轮生成 summary;第二轮把旧 summary + 新对话再压成新 summary(典型滚动更新)。
-
KG editing:实体增删改查,适合结构化知识。
-
Contextual CRUD:把记忆当数据库表一样管理。
工程上最难的是冲突解决:当旧记忆与新事实矛盾时,要有优先级与证据策略(时间新近性、来源可信度、使用频次、人工确认等)。
3.4 记忆遗忘:清理噪声与风险
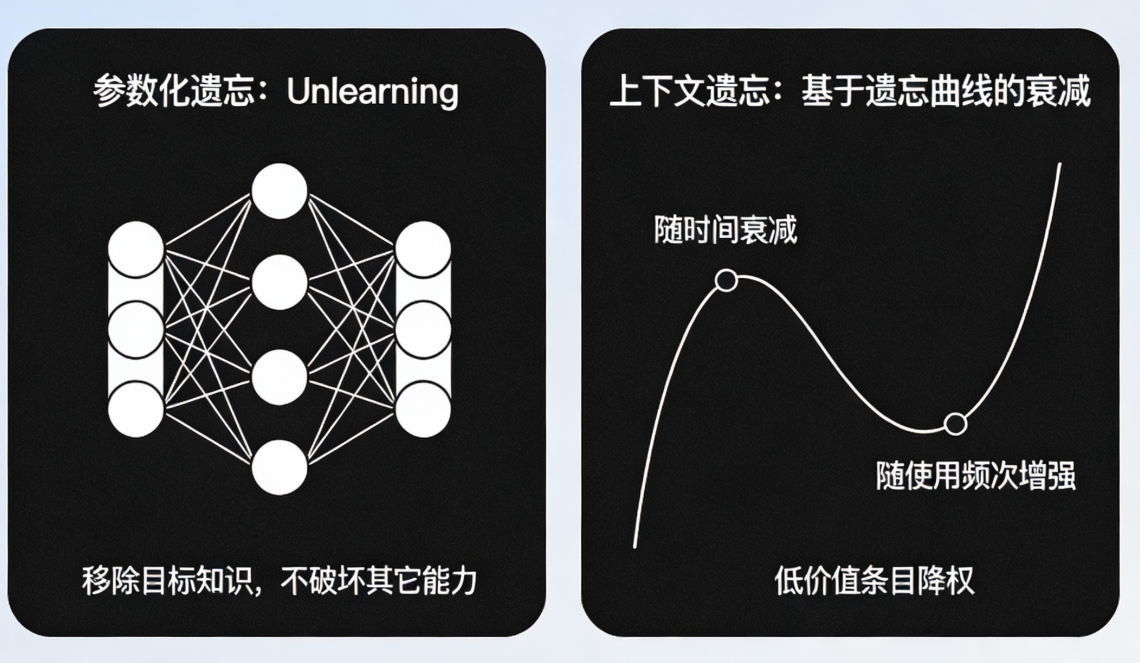
遗忘不是缺陷,是容量管理与安全机制。
✅ 参数化遗忘:Unlearning 当模型权重里固化了有毒/违法/过时信息,或需要满足遗忘权/合规要求,尽量只移除目标知识,不破坏其它能力。
✅ 上下文遗忘:基于遗忘曲线的衰减 用艾宾浩斯遗忘曲线设计记忆衰减:
-
随时间自然衰减;
-
随访问/使用频次增强;
-
对低价值条目逐步降权,直至不再召回。
3.5 记忆检索:把相关信息带回工作台
✅ 定义:响应输入,从记忆中识别并访问相关信息 检索是记忆系统的咽喉。给出两类典型做法:
✅ 参数化侧:Attention / 向量相似度的内在机制 模型内部用注意力分配当前 token 该看哪里,这是一种隐式检索。但它受上下文窗口限制,且不可控。
✅ 上下文侧:BM25、Embedding Retrieval 等显式机制
-
BM25适合关键词精确匹配(术语、ID、代码符号);
-
Embedding适合语义相近召回(同义改写、概念相似);
-
**重排(Rerank)**把粗召回的候选按与当前任务目标的相关性再排序;
-
多跳检索适合跨文档推理(先找实体,再扩展关联)。
3.6 记忆压缩:在有限窗口里保留要点
✅ 定义:保留显著信息、丢弃冗余 在有限上下文窗口里,要把重要的留下,不重要的扔掉。
-
未来任务可能用到什么?
-
哪些事实是稳定的?
-
哪些只是当时的闲聊噪声?
✅ 两条路线:参数化蒸馏 vs 上下文压缩
-
参数化侧:知识蒸馏、模型融合/回放)等,把经验内化。
-
上下文侧:会话摘要、要点抽取、事件模板化、把长历史变成可检索的短条目。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 32
32 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)