AI大模型:python电商销售预测分析可视化系统 机器学习 线性回归预测算法 大数据 计算机毕业设计(建议收藏)
AI大模型:python电商销售预测分析可视化系统 机器学习 线性回归预测算法 大数据 计算机毕业设计(建议收藏)
·
博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
2、大数据毕业设计:2026年选题大全 深度学习 python语言 JAVA语言 hadoop和spark(建议收藏)✅
1、项目介绍
技术栈:
python语言、flask框架、机器学习、线性回归预测算法、Echarts可视化、HTML
2、项目界面
(1)数据中心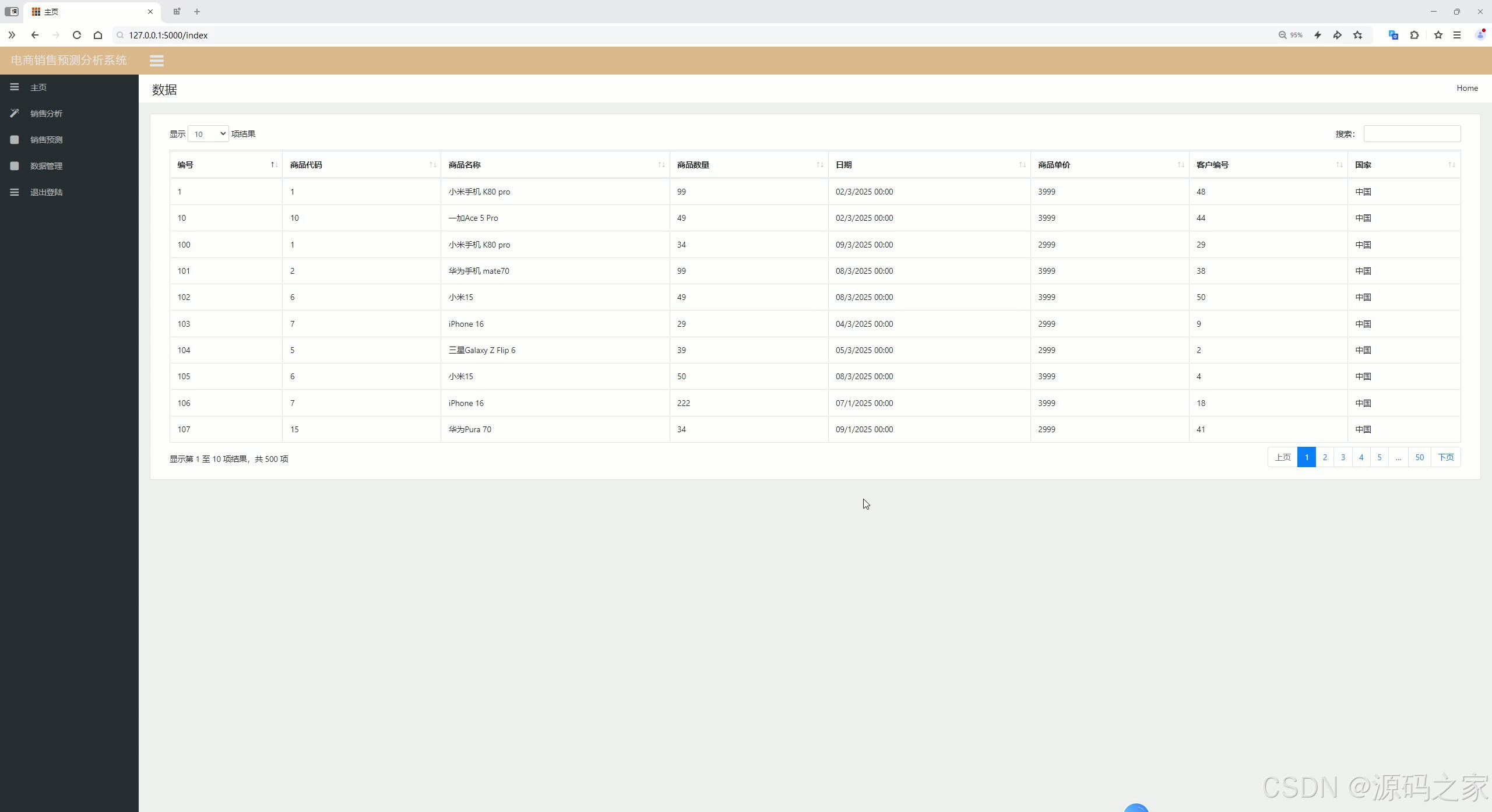
(2)数据分析可视化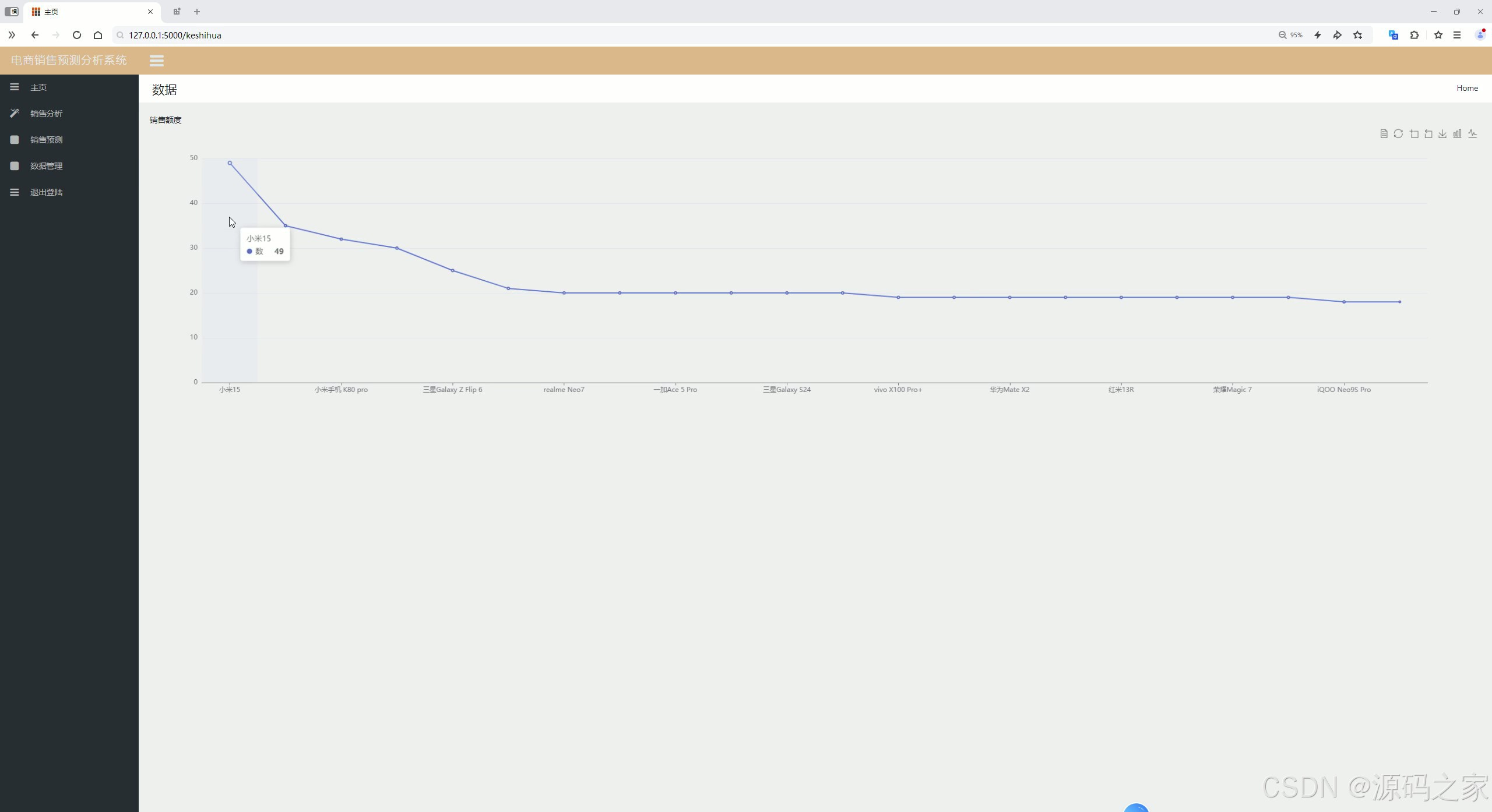
(3)销售预测
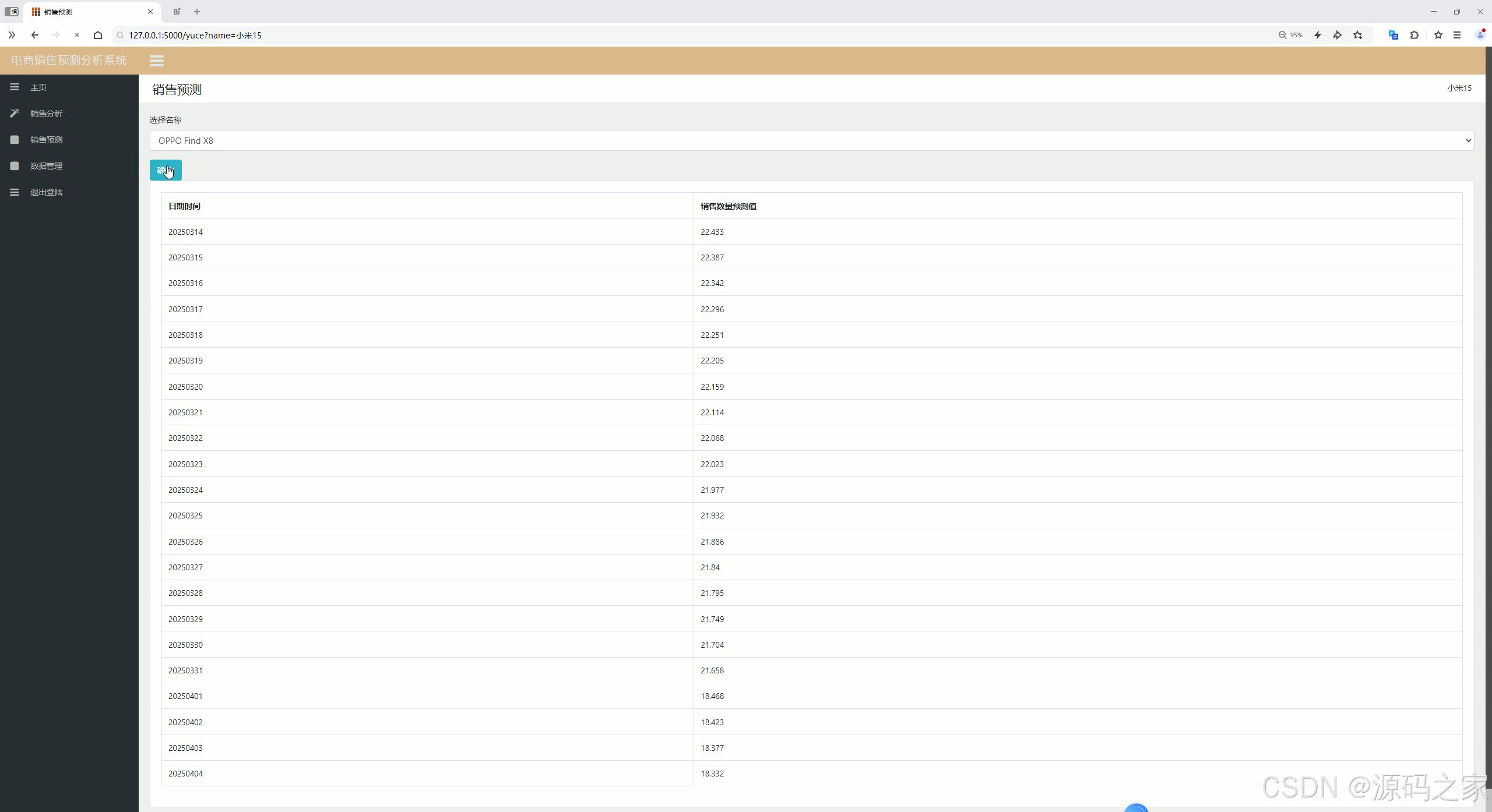
(4)注册登录
(5)后台管理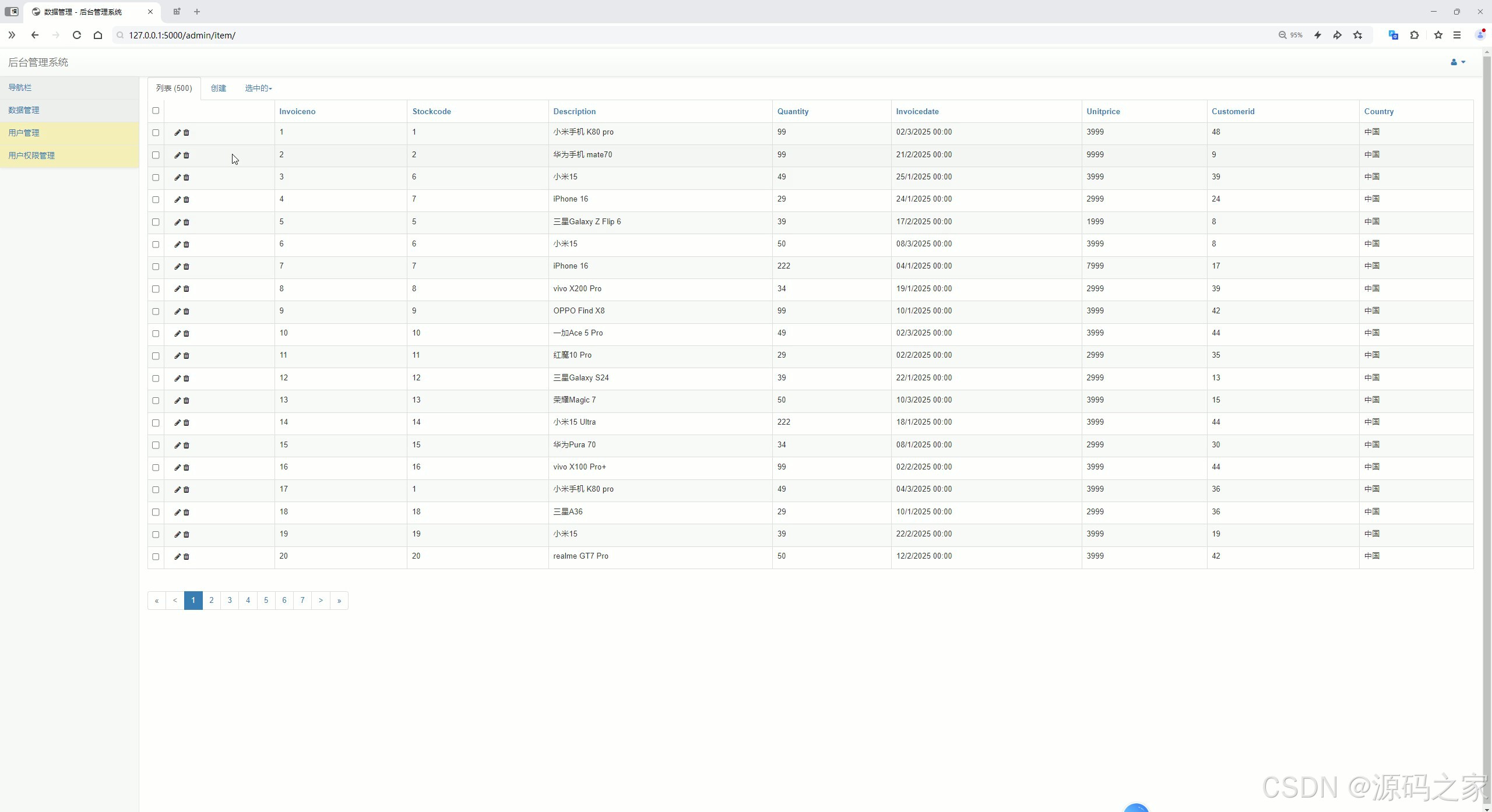
3、项目说明
电商销售预测分析可视化项目介绍
本电商销售预测分析可视化项目,依托 Python 语言、Flask 框架、机器学习线性回归预测算法、Echarts 可视化及 HTML 技术栈构建,为电商企业提供全方位的销售数据处理与决策支持服务。
项目核心界面功能丰富且实用。数据中心作为基础数据枢纽,能集中展示电商平台的核心销售数据,包括订单量、销售额、客户数量等关键指标,数据呈现清晰直观,为后续分析工作奠定坚实基础,方便工作人员快速掌握整体销售概况。
数据分析可视化界面借助 Echarts 强大的可视化能力,将复杂的销售数据转化为各类直观图表,如折线图展示销售额变化趋势、柱状图对比不同品类销售情况、饼图呈现各地区销售占比等。通过多样化图表,工作人员可轻松挖掘数据背后的规律,发现销售中的优势与不足。
销售预测界面是项目的核心亮点,基于机器学习线性回归预测算法,结合历史销售数据,如过去数月的销售额、促销活动影响、季节因素等,构建预测模型。工作人员输入相关参数后,系统能精准预测未来一段时间的销售情况,为库存管理、营销计划制定提供科学依据,助力企业提前做好资源调配。
注册登录界面保障了系统数据的安全性,通过账号密码验证机制,实现用户身份识别与权限管控,不同角色用户拥有不同操作权限,有效防止数据泄露与误操作,确保系统稳定运行。
后台管理界面则为管理人员提供了便捷的系统维护工具,可进行数据录入、更新、删除,用户账号管理、权限分配,以及系统参数配置等操作,保障整个项目系统的顺畅运行与高效管理。
整体而言,该项目打通了电商销售数据从采集、分析到预测、管理的全流程,为电商企业提升销售效率、优化运营策略提供了有力的技术支撑。
4、核心代码
from collections import OrderedDict
import pandas as pd
import models
from sqlalchemy import or_,and_
import datetime
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
import numpy
import traceback
def yuce1(name):
try:
print(name)
sql_command = 'select * from Item '
df = pandas.read_sql(sql_command, models.db.engine)
da = df[df['Description'].map(lambda xx: xx == name)]
datas = df[df['Description'].map(lambda xx: xx == name)].values.tolist()
print(datas[0])
date_day = list(set([int(datetime.datetime.strptime(i[-4].split(' ')[0],'%d/%m/%Y').strftime('%Y%m%d')) for i in datas]))
date_day.sort()
print(date_day)
liuliang = []
for i in date_day:
record_list = da[da['InvoiceDate'].map(
lambda xx:int(datetime.datetime.strptime(xx.split(' ')[0],'%d/%m/%Y').strftime('%Y%m%d')) == i )].values.tolist()
liuliang.append(record_list[-1][-2])
# 数据集
examDict = {
'时间': date_day,
'数据': liuliang
}
print(examDict)
examOrderedDict = OrderedDict(examDict)
examDf = pd.DataFrame(examOrderedDict)
examDf.head()
# exam_x 即为feature
exam_x = examDf.loc[:, '时间']
# exam_y 即为label
exam_y = examDf.loc[:, '数据']
print("-------------正常1-------------")
x_train, x_test, y_train, y_test = train_test_split(exam_x, exam_y, train_size=0.5)
# x_train, x_test, y_train, y_test = train_test_split(exam_x, exam_y, train_size=0.5)
x_train = x_train.values.reshape(-1, 1)
x_test = x_test.values.reshape(-1, 1)
model = LinearRegression()
model.fit(x_train, y_train)
print("-------------正常2-------------")
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=1)
# LinearRegression(copy_X=True, fit_intercept=True, n_jobs=1, normalize=False)
rDf = examDf.corr()
model.score(x_test, y_test)
data1 = datetime.datetime.strptime(str(date_day[-1]), '%Y%m%d')
li1 = []
for i in range(24):
data1 = data1 + datetime.timedelta(days=1)
li1.append([int(data1.strftime('%Y%m%d'))])
li2 = numpy.array(li1)
y_train_pred = model.predict(li2)
li2 = []
for i in range(len(li1)):
dicts = {}
dicts['riqi'] = li1[i][0]
dicts['xisu'] = round(abs(y_train_pred[i]),3)
li2.append(dicts)
return li2[2:]
except:
print(traceback.format_exc())
return []
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看我的【用户名】、【专栏名称】、【顶部选题链接】就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看👇🏻获取联系方式👇🏻



有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 33
33 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)