数据架构设计
本文系统介绍了现代数据架构设计的关键要素和发展趋势。首先阐述了数据架构的定义、演进历程和核心目标,重点分析了分层架构模型(采集层、存储层、计算层、服务层和消费层)。详细解读了湖仓一体、数据网格等前沿架构模式,以及数据建模、ETL/ELT设计等核心技术。文章还探讨了数据治理与安全、性能优化与成本管理等重要议题,提供了技术选型建议和实施策略,并通过电商和金融案例展示实践价值。最后展望了AI增强、实时化
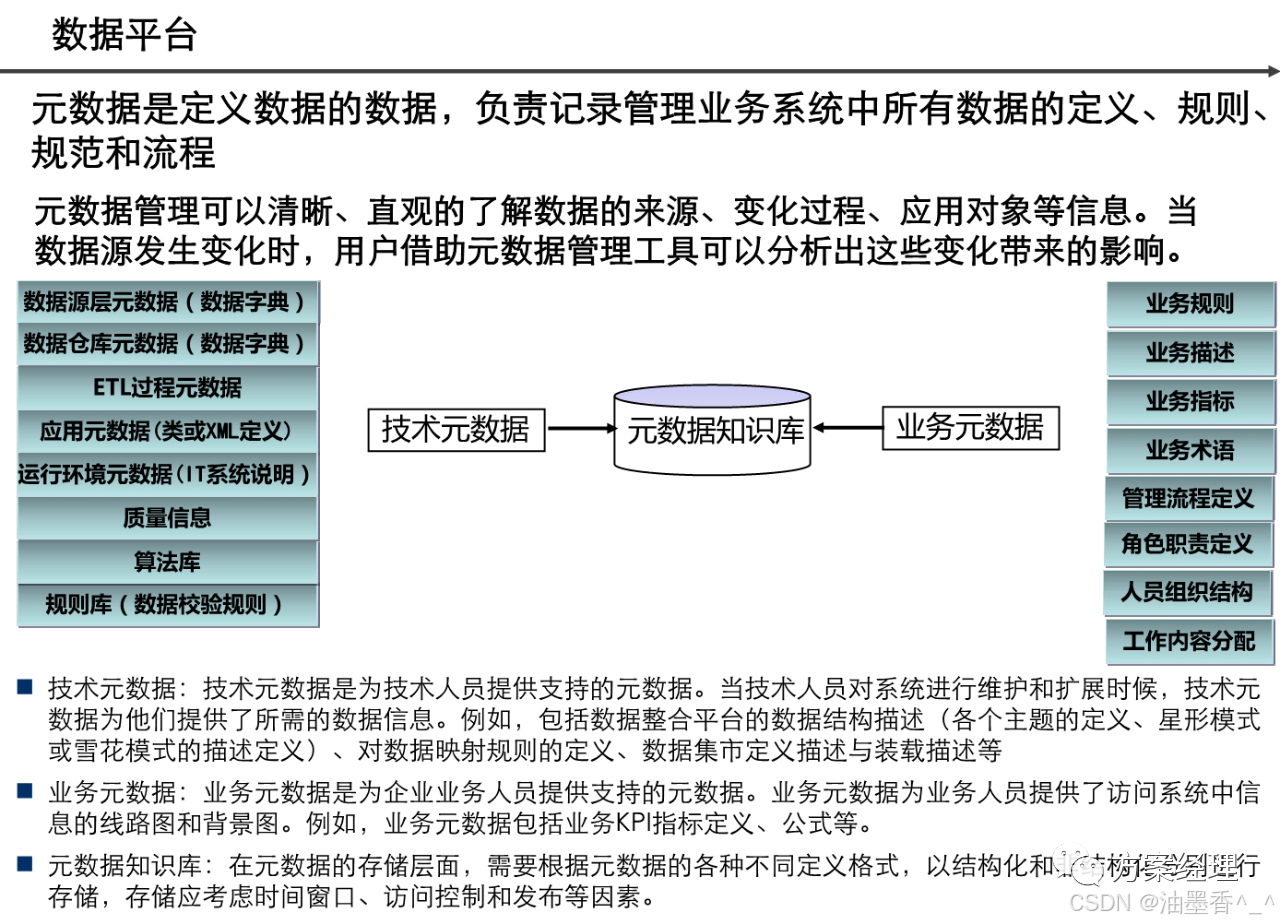 阅读的时候看到一篇非常不错的数据架构设计,分享给大家,做MDM或数据治理的朋友可以研究研究~(干货比较多,但是有的图不清晰。可以支撑大家看逻辑)
阅读的时候看到一篇非常不错的数据架构设计,分享给大家,做MDM或数据治理的朋友可以研究研究~(干货比较多,但是有的图不清晰。可以支撑大家看逻辑)
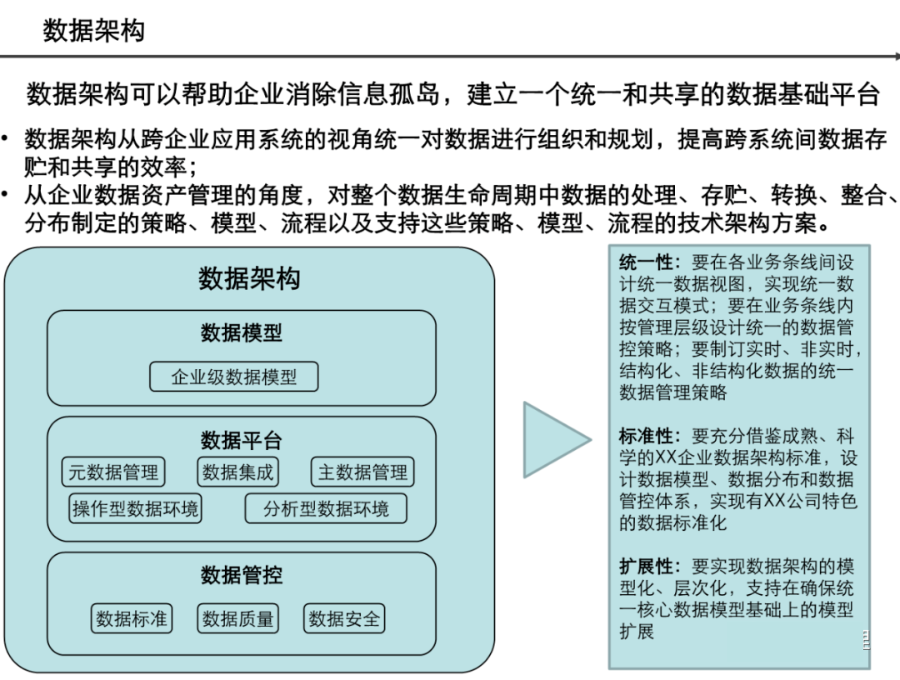
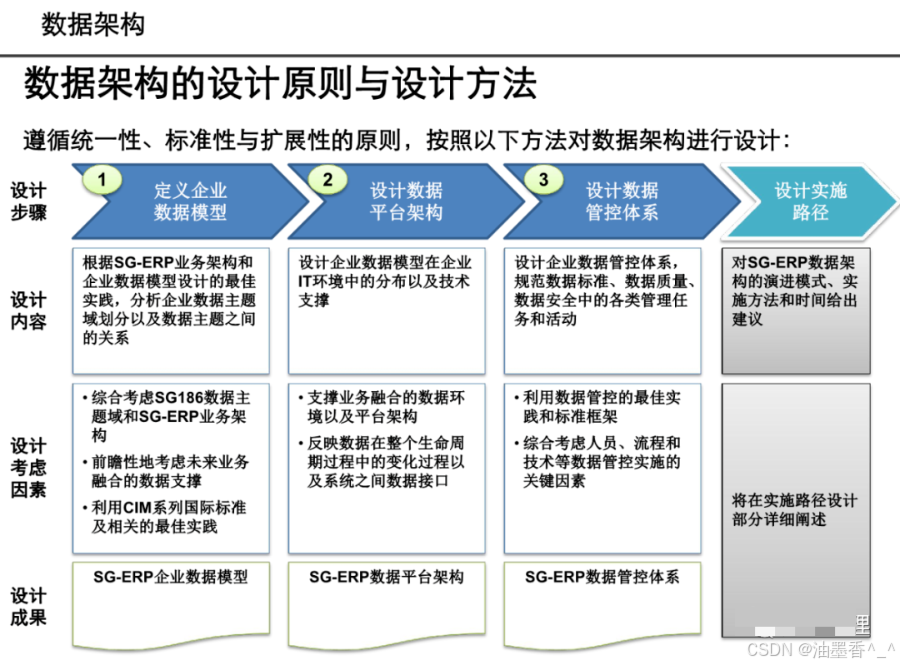
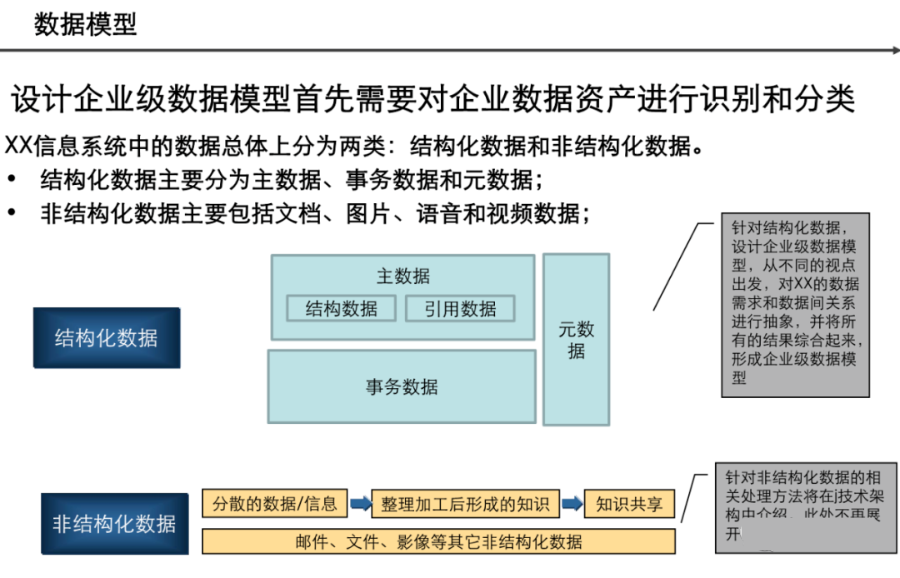
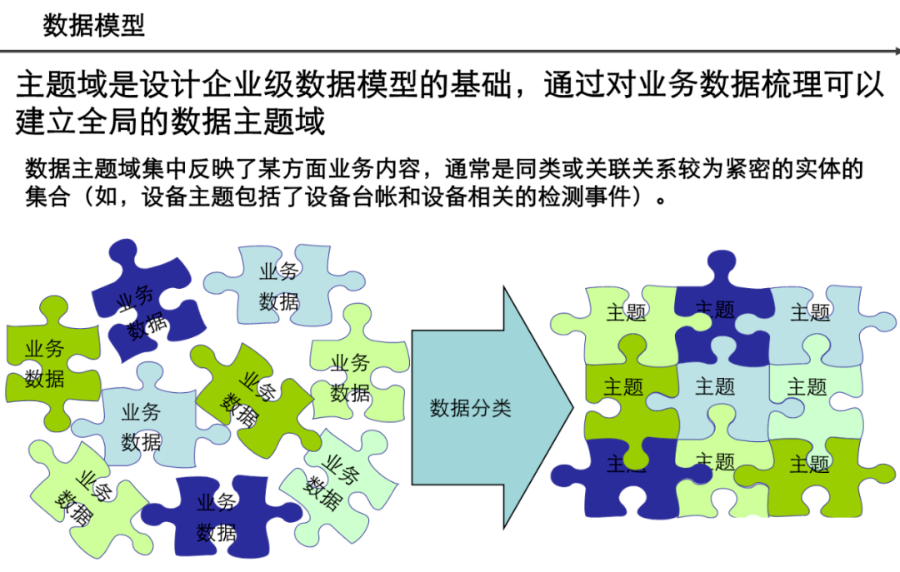
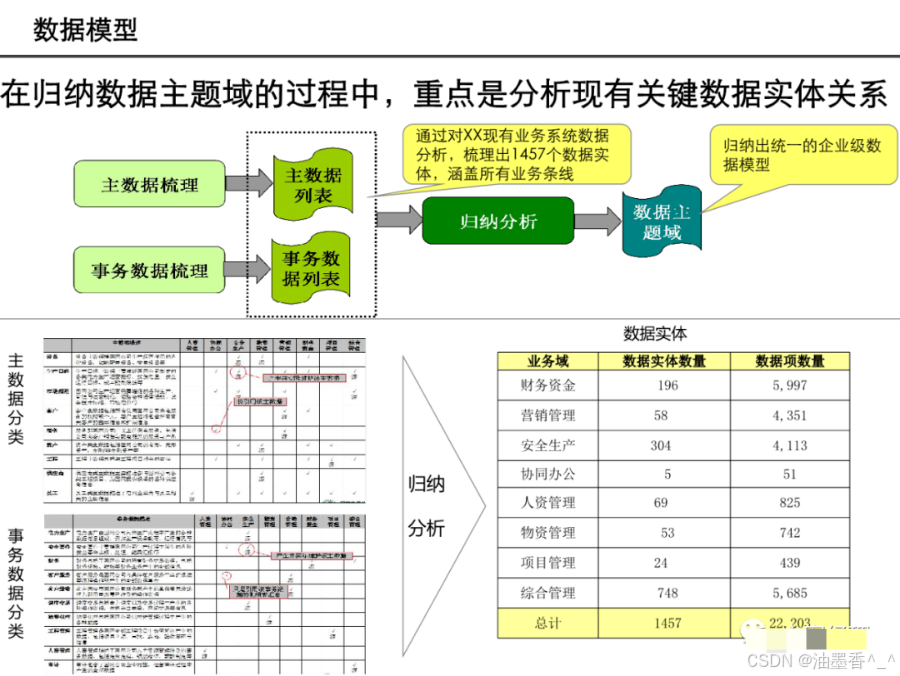
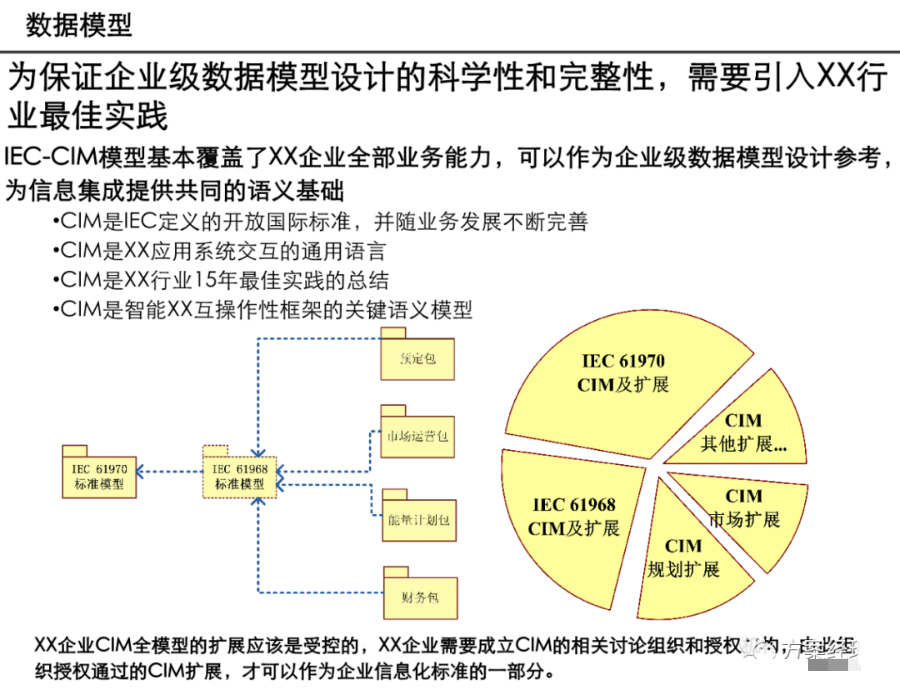
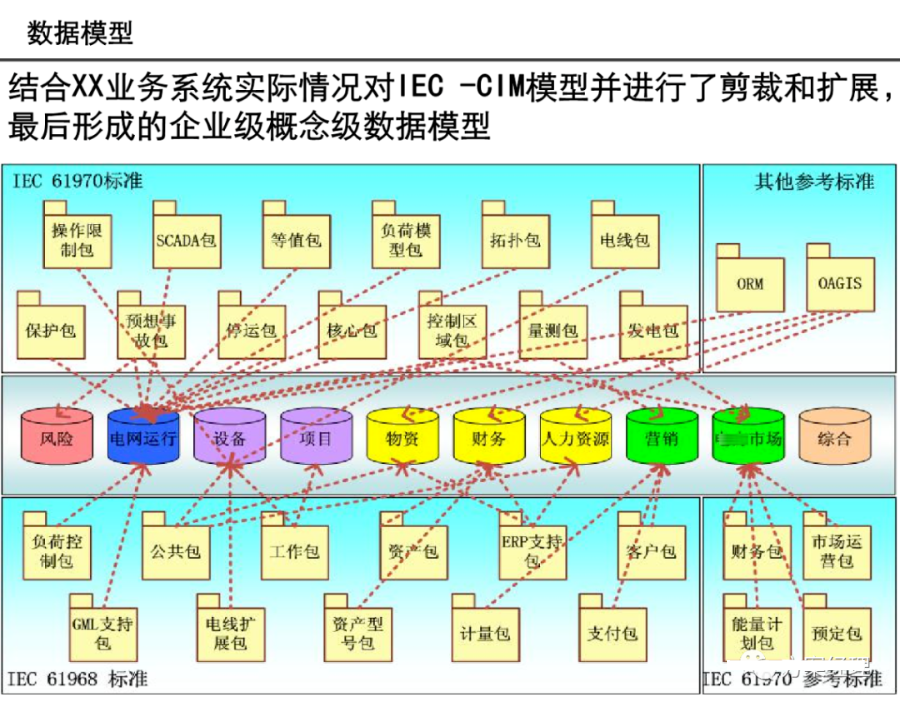
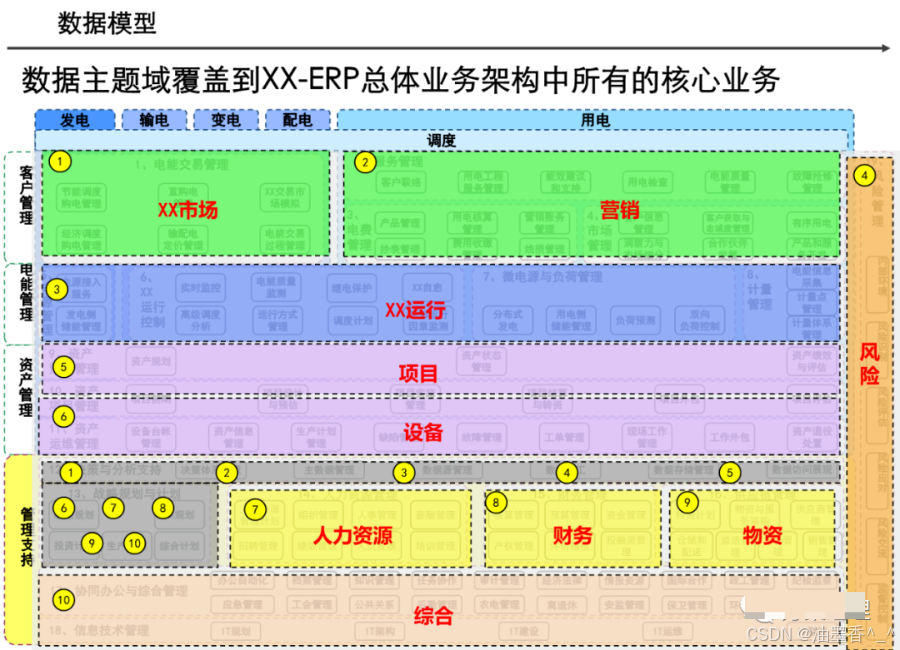
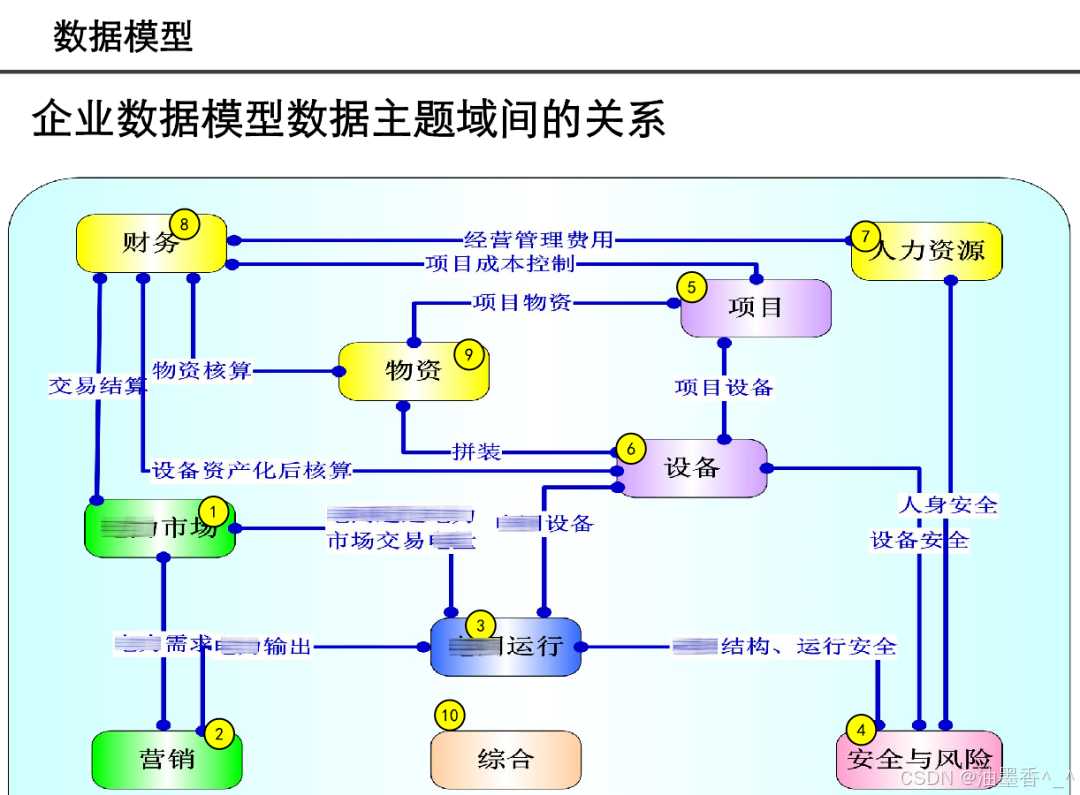
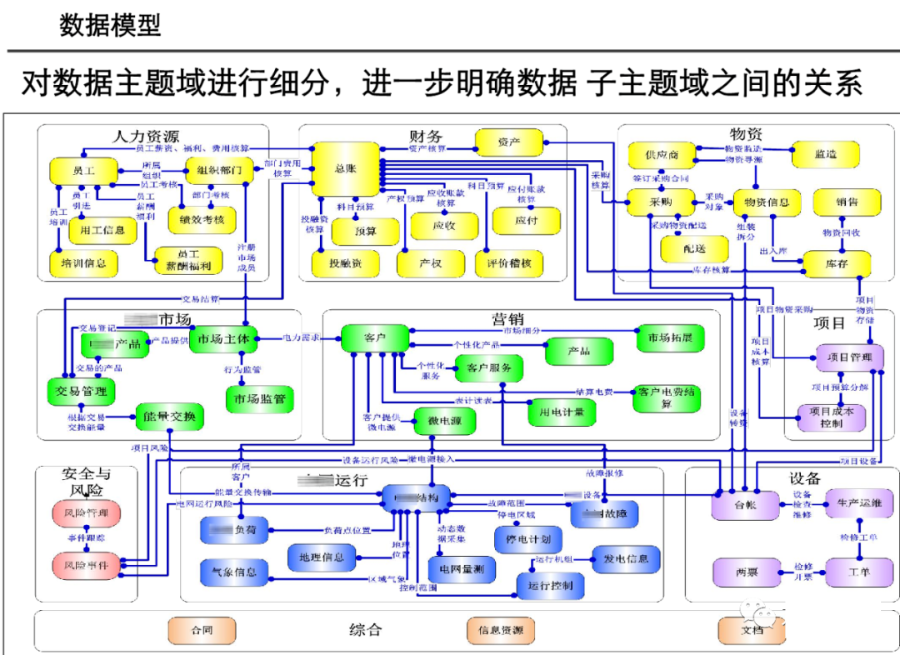
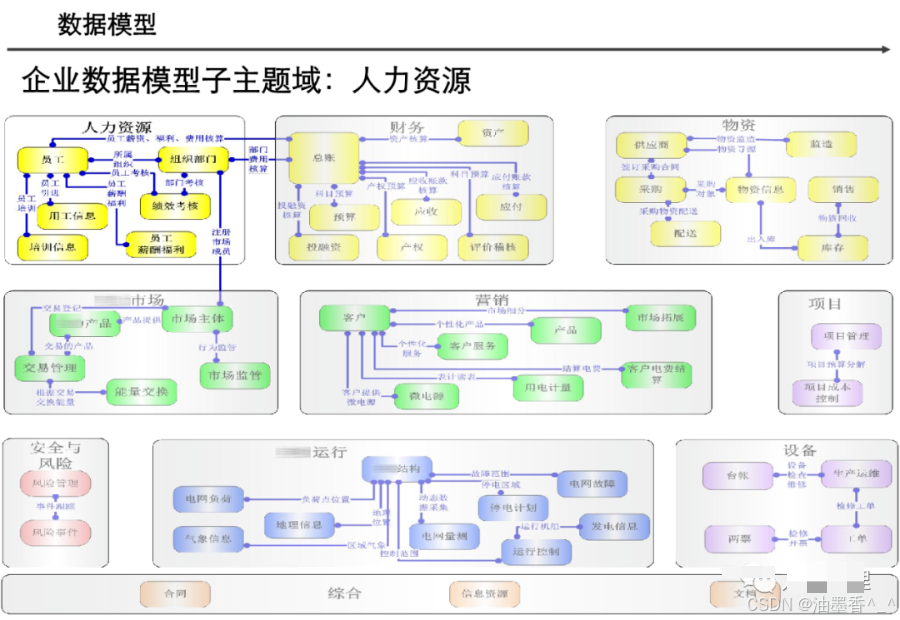
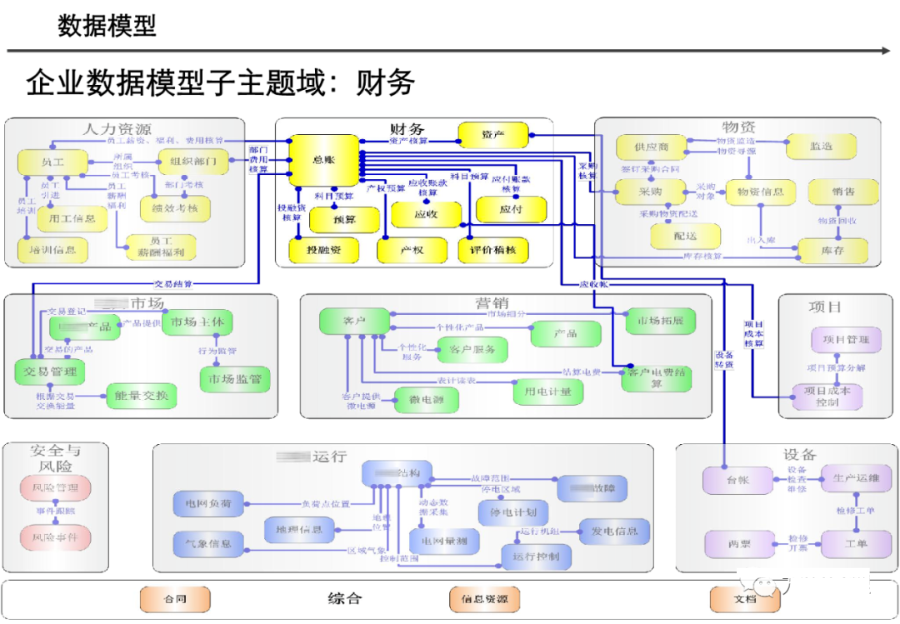
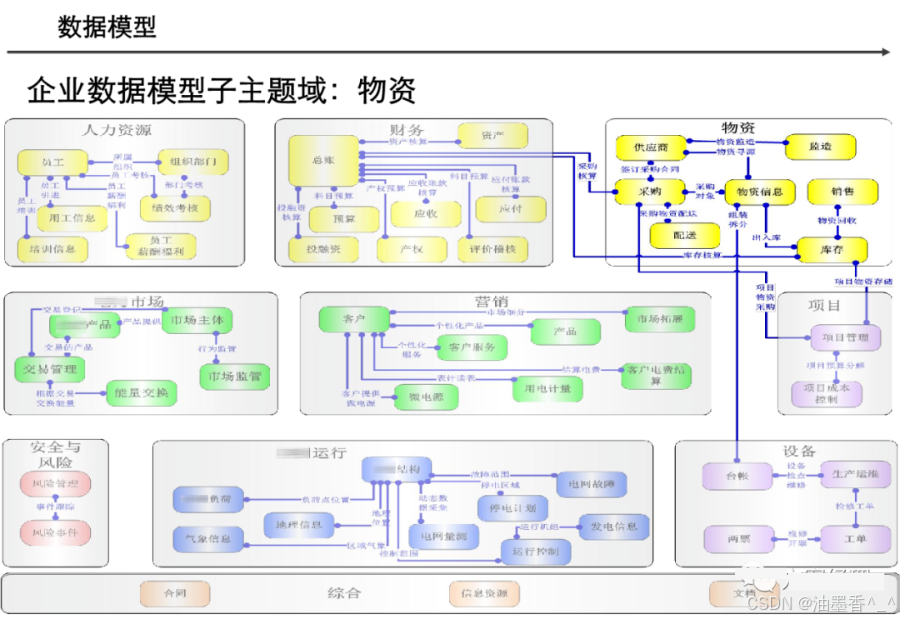
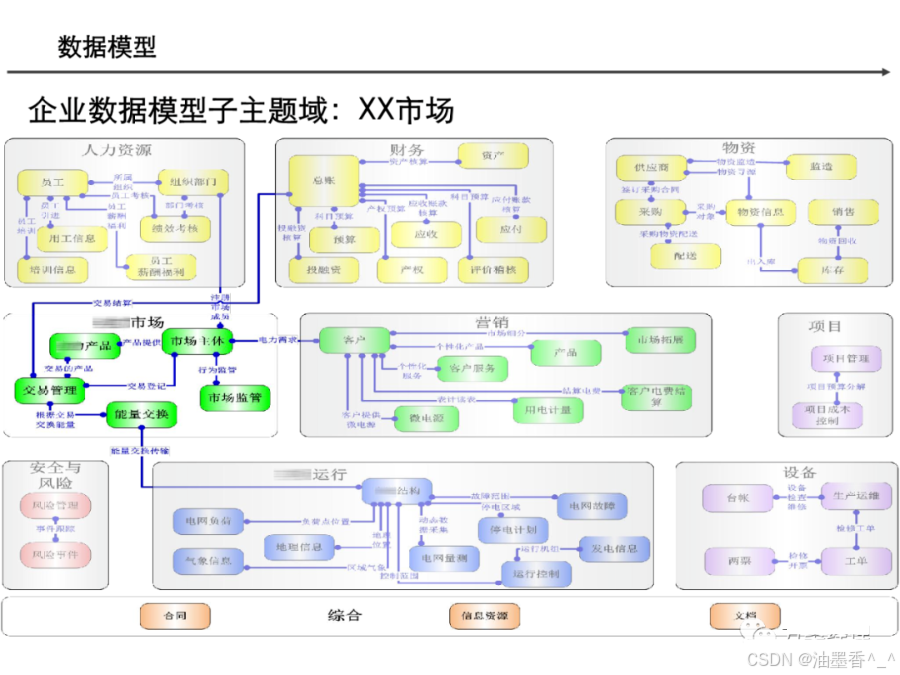
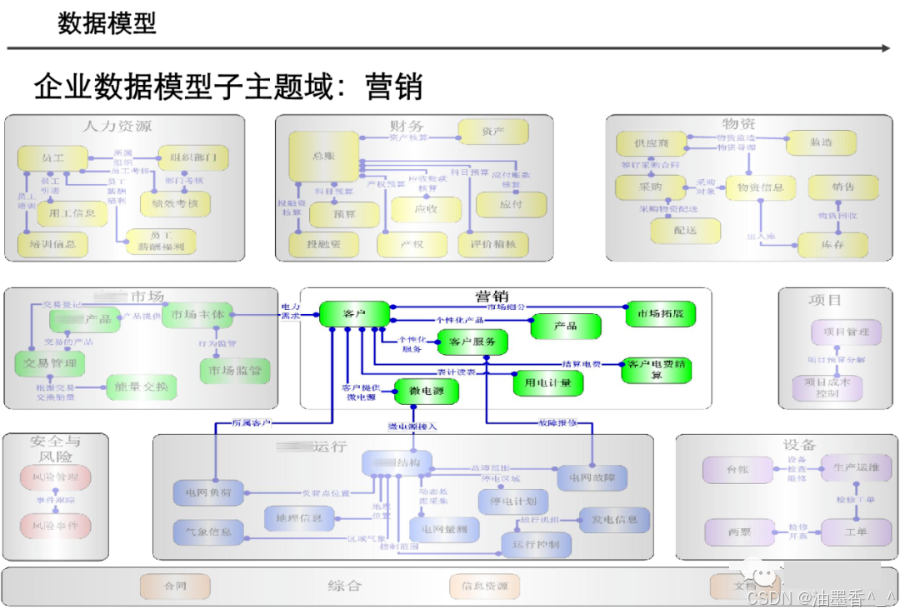
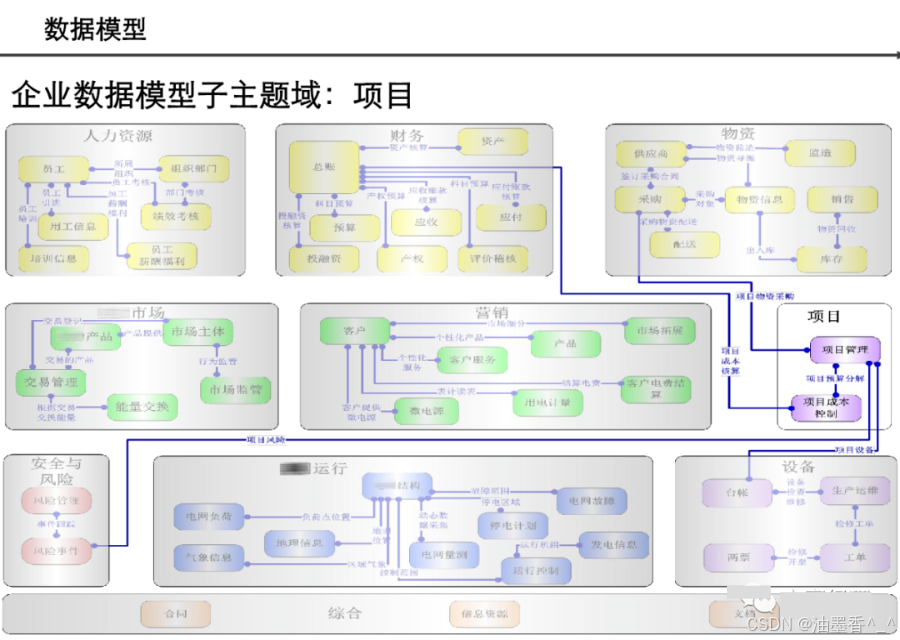
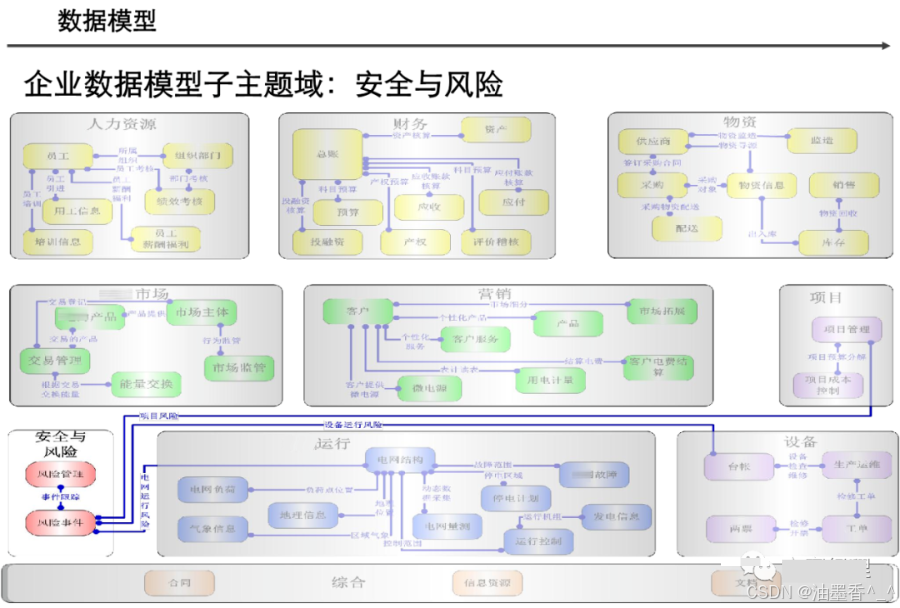
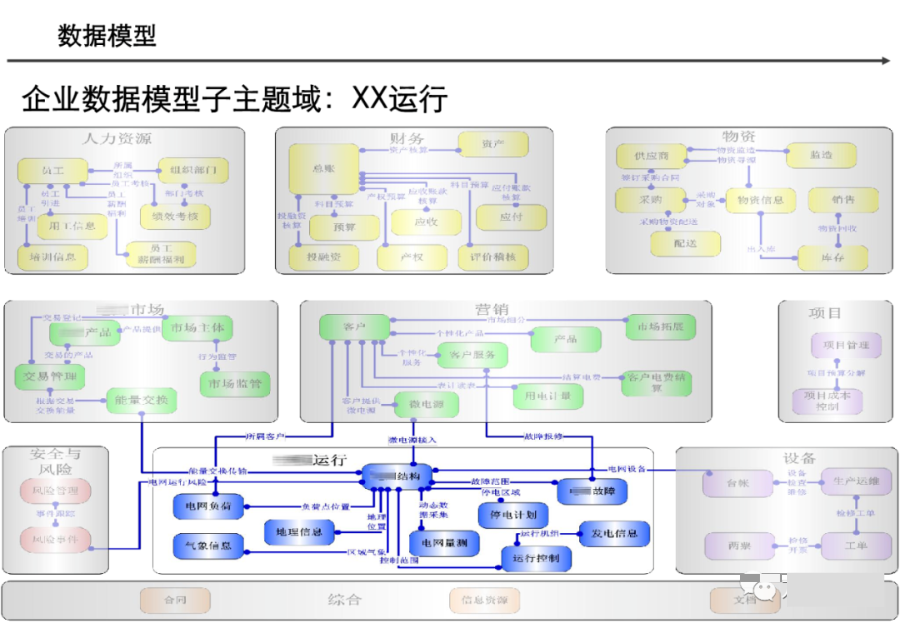
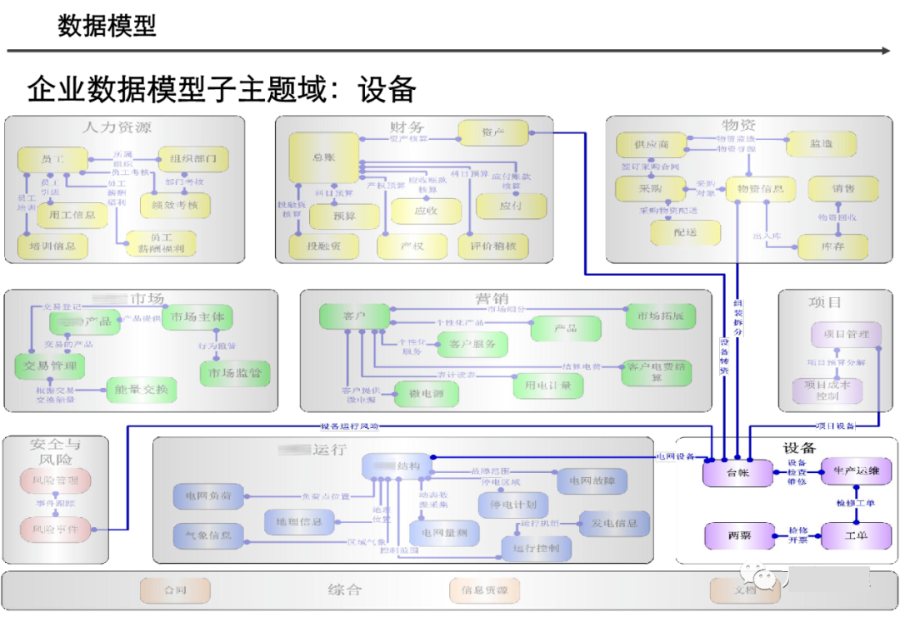
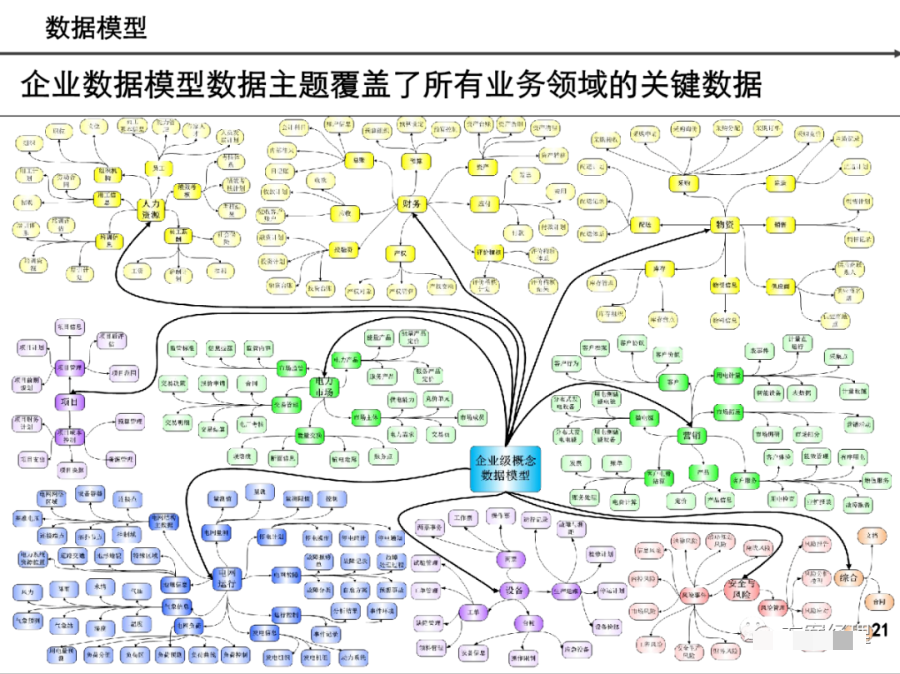
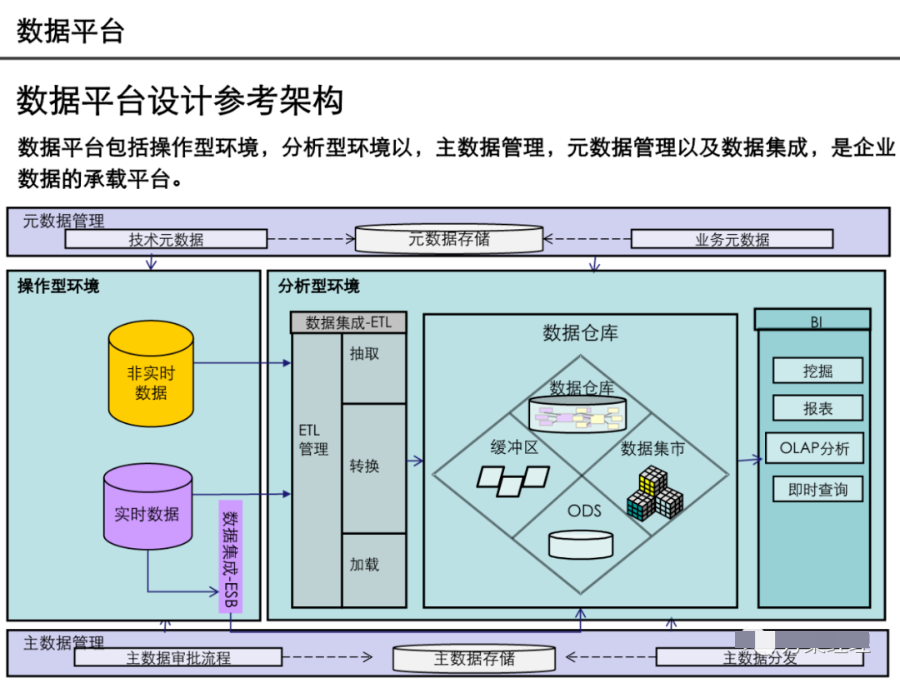
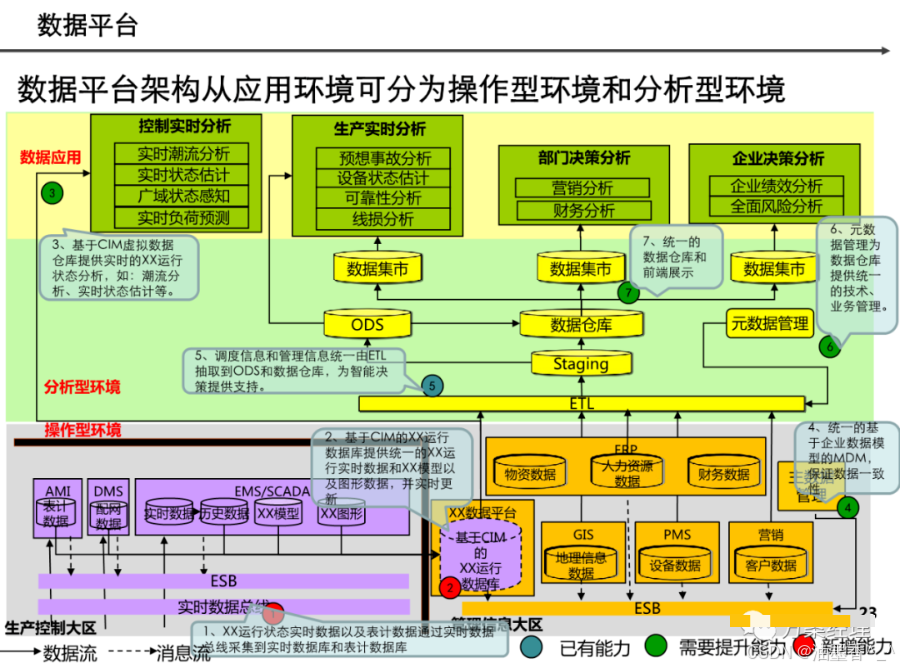
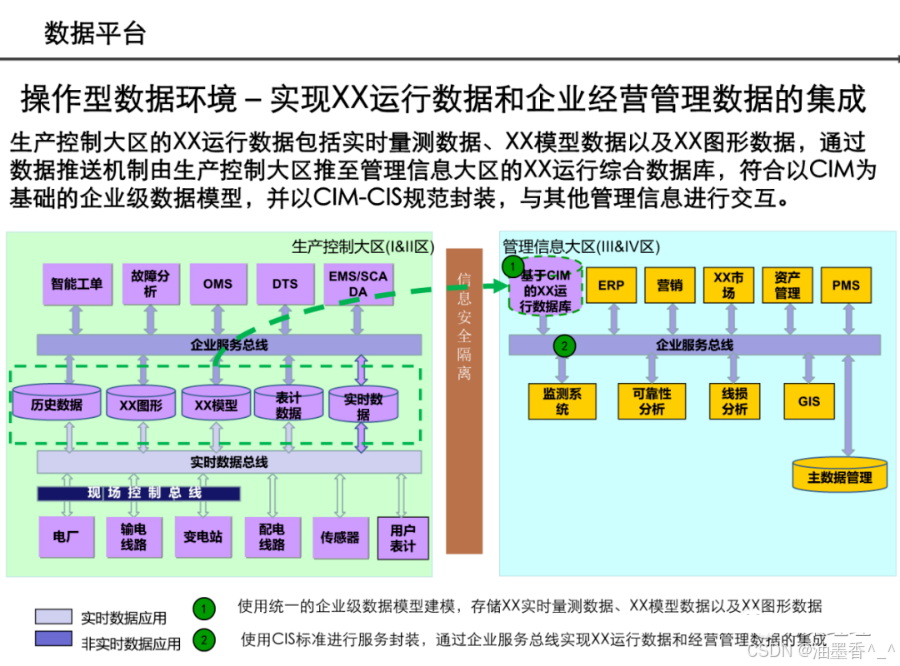
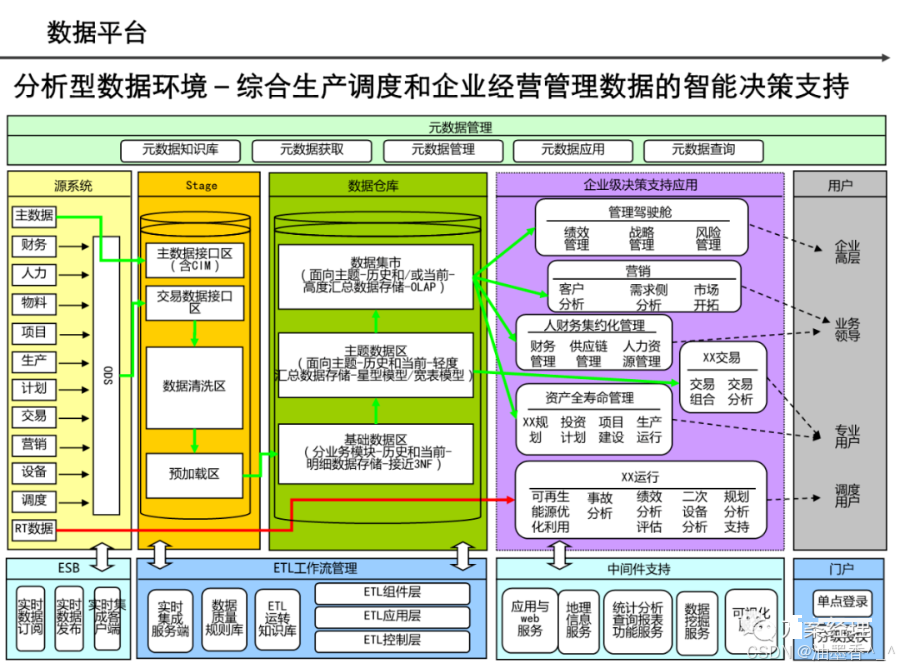
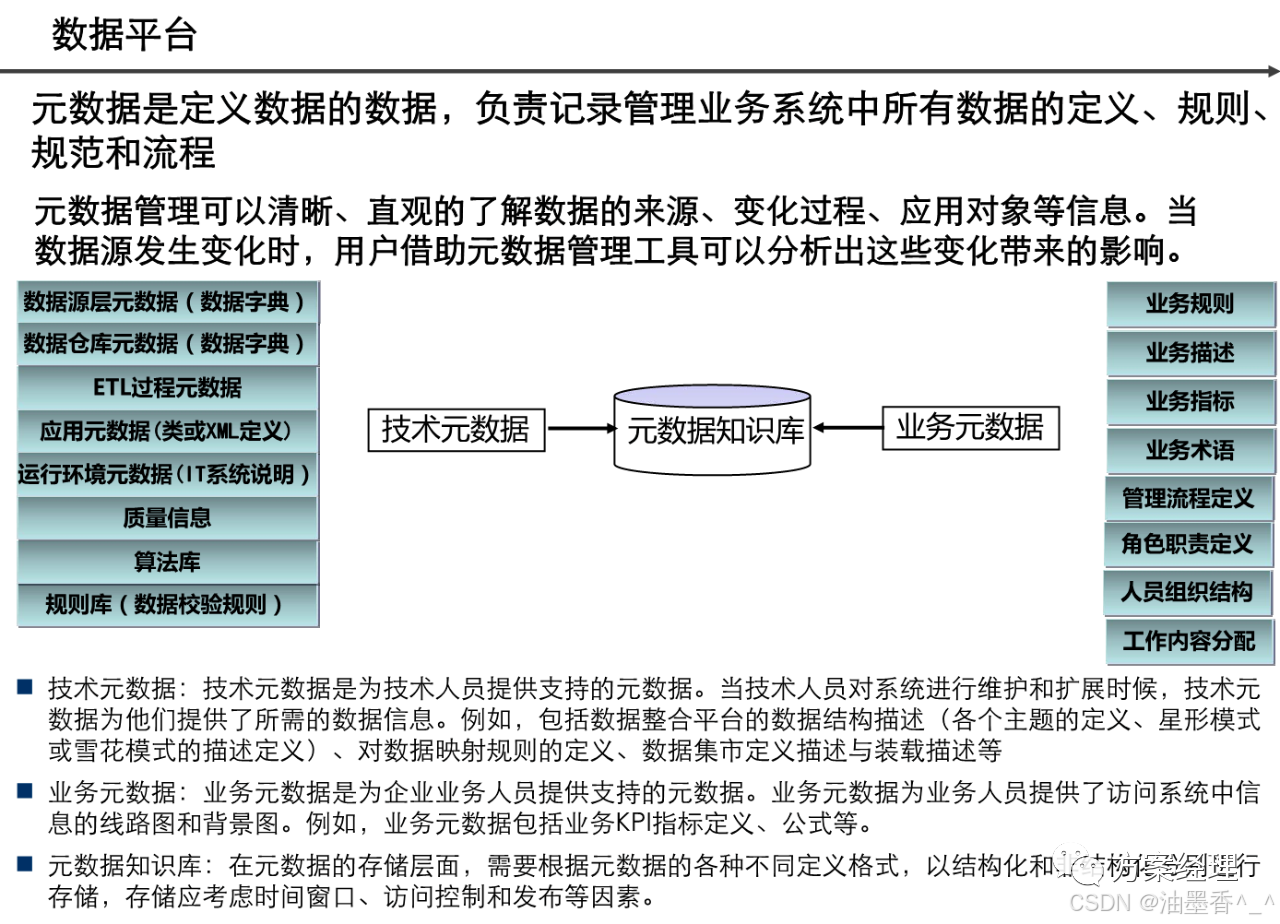
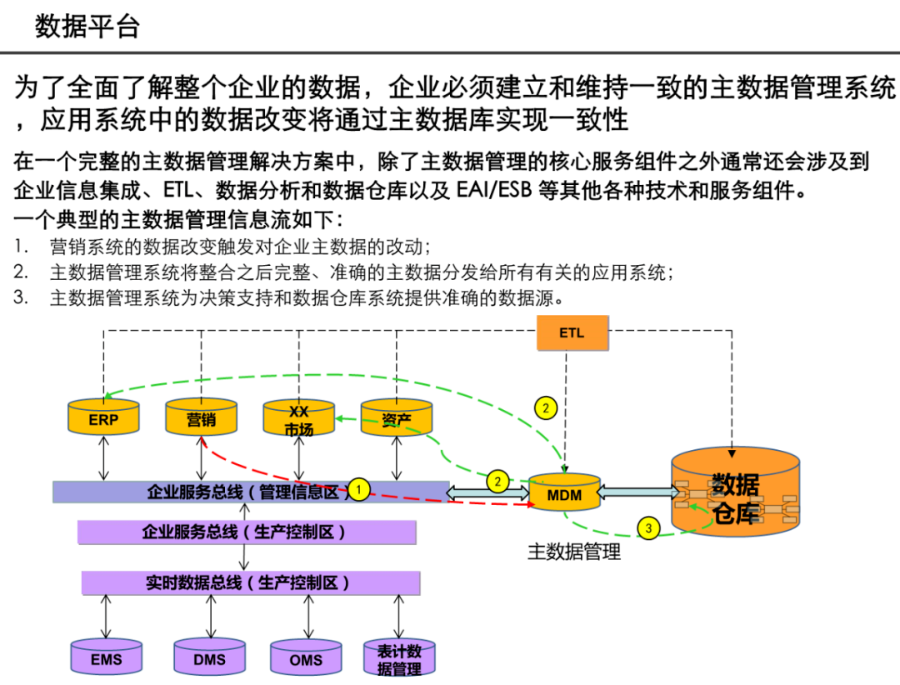
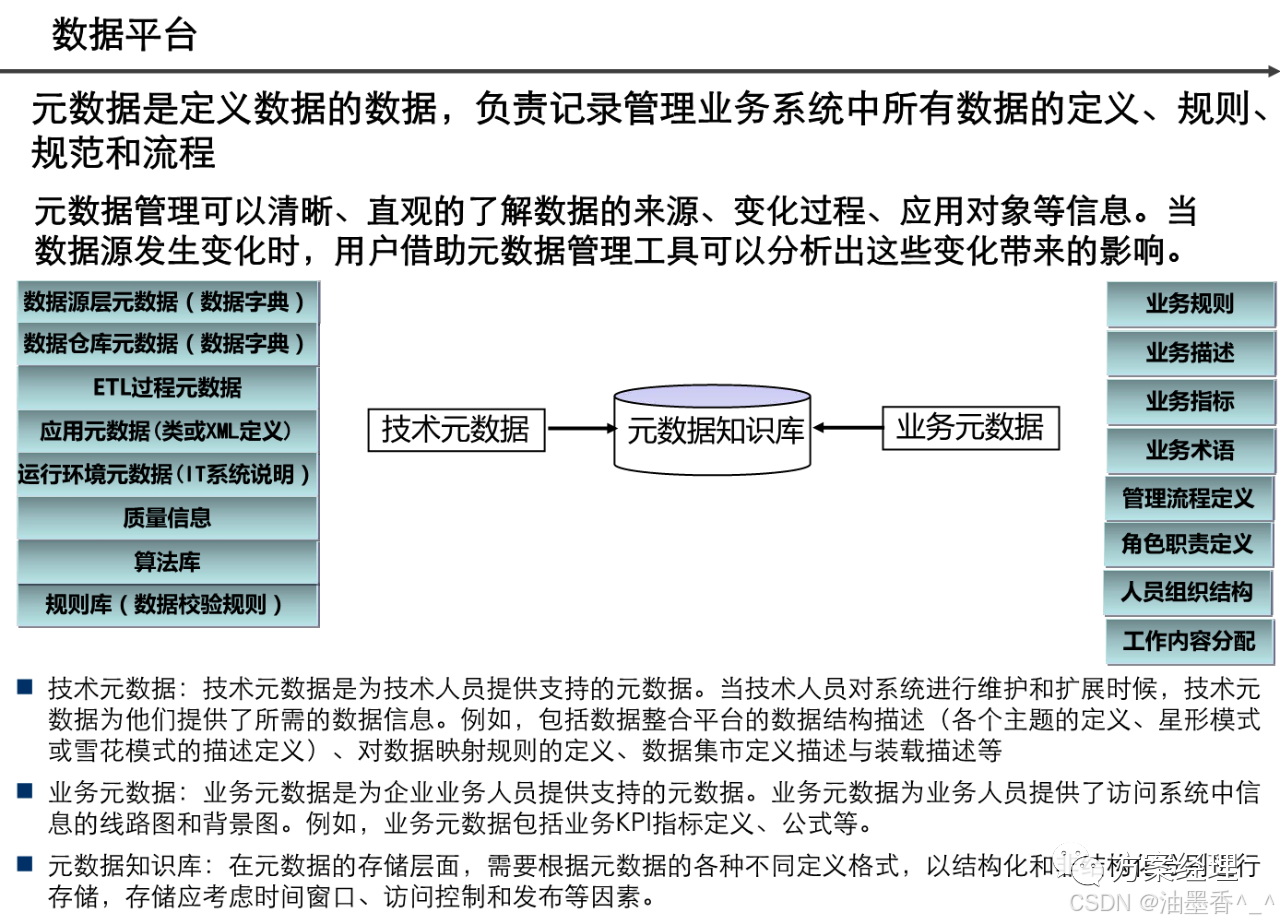

引言:数据架构的时代价值
在数字化浪潮席卷全球的今天,数据已成为组织最核心的战略资产。数据架构设计作为数据治理和管理的基石,直接决定了组织能否高效利用数据、挖掘数据价值并支撑业务创新。一个优秀的数据架构不仅能够解决当前的数据管理问题,更能为未来的数据应用和业务发展奠定坚实基础。本文将全面解析数据架构设计的核心理念、关键组件、设计方法与实践策略,帮助您构建面向未来的数据架构体系。
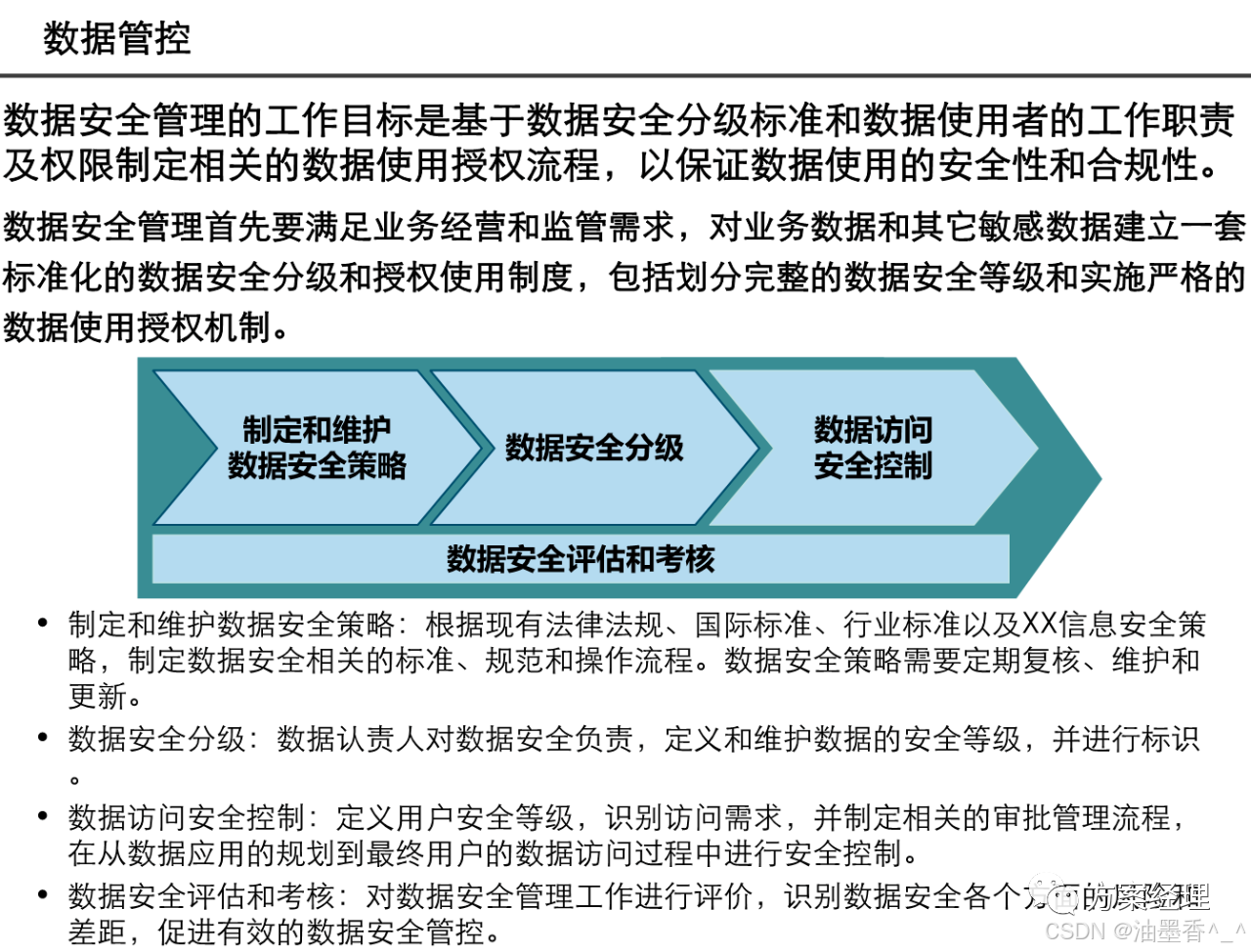
第一章:数据架构设计的核心理念
1.1 数据架构的定义与范畴
数据架构是组织数据资产的蓝图,定义了数据如何被采集、存储、整合、处理和使用的结构性框架。它不仅仅是一套技术规范,更是连接业务战略与数据实现之间的桥梁。完整的数据架构应涵盖:
-
数据模型设计:包括概念模型、逻辑模型和物理模型
-
数据存储策略:针对不同类型数据选择合适的存储方案
-
数据流设计:数据在系统中的流动路径与处理逻辑
-
数据集成机制:不同系统间数据交换与共享的方式
-
数据治理框架:数据质量、安全、标准的管理体系
-
数据服务接口:将数据能力暴露给业务应用的标准方式
1.2 数据架构的演进历程
数据架构经历了多个阶段的演进:
第一阶段:传统数据仓库架构(1990s)
-
基于ETL(抽取-转换-加载)流程
-
集中式存储,星型/雪花型模型
-
面向历史数据分析,批处理为主
第二阶段:大数据平台架构(2010s)
-
引入Hadoop等分布式计算框架
-
支持非结构化数据处理
-
流批一体化处理能力
第三阶段:现代数据架构(2020s+)
-
云原生与混合云部署
-
数据湖仓一体化(Lakehouse)
-
实时数据管道与AI/ML集成
-
数据网格(Data Mesh)等分布式架构
1.3 数据架构的核心目标
设计数据架构时应明确以下目标:
-
业务价值驱动:确保数据架构服务于业务目标
-
数据质量保障:建立数据可信度和一致性
-
可扩展性与弹性:支持业务增长和技术演进
-
安全与合规:满足隐私保护和监管要求
-
成本效益:平衡性能需求与资源投入
-
敏捷性与灵活性:快速响应业务变化
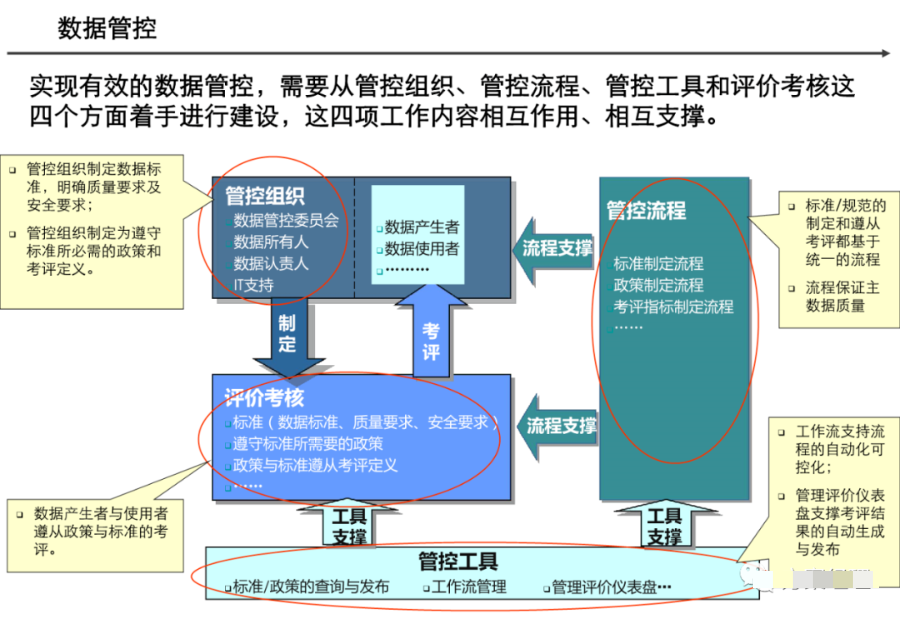
第二章:现代数据架构的分层设计
2.1 经典分层架构模型
现代数据架构通常采用分层设计理念,各层职责清晰分离:
text
┌─────────────────────────────────────┐ │ 数据消费层 │ │ BI工具|数据应用|数据API │ ├─────────────────────────────────────┤ │ 数据服务层 │ │ 数据集市|特征仓库|指标平台 │ ├─────────────────────────────────────┤ │ 数据计算层 │ │ 批处理|流处理|机器学习 │ ├─────────────────────────────────────┤ │ 数据存储层 │ │ 数据湖|数据仓库|NoSQL|图数据库 │ ├─────────────────────────────────────┤ │ 数据采集层 │ │ CDC|日志采集|API集成|物联网 │ └─────────────────────────────────────┘
2.2 详细分层解析
2.2.1 数据采集层
数据采集是数据管道的起点,关注如何高效、可靠地获取数据:
核心采集模式:
-
批量采集:定期从源系统导出数据文件
-
增量采集:通过CDC(变更数据捕获)实时获取变更
-
流式采集:实时捕获事件流和日志数据
-
API采集:通过API接口获取外部数据
技术选型示例:
-
传统ETL工具:Informatica, Talend
-
数据集成平台:Fivetran, Airbyte
-
流式采集:Kafka Connect, Fluentd
-
云服务:AWS DMS, Azure Data Factory
2.2.2 数据存储层
存储层设计需根据数据类型和使用场景选择合适方案:
结构化数据存储:
-
关系型数据库:OLTP场景,强一致性要求
-
分析型数据库:列存储,MPP架构,如Snowflake、Redshift
-
数据仓库:维度建模,支持复杂分析
半结构化/非结构化数据存储:
-
数据湖:原始数据存储,支持多种格式(Parquet、ORC等)
-
NoSQL数据库:文档型(MongoDB)、宽列(Cassandra)、键值(Redis)
-
对象存储:S3、OSS,成本低廉,无限扩展
存储策略设计要点:
-
数据分层存储(热/温/冷/冰)
-
数据生命周期管理
-
存储格式优化(列存 vs 行存)
-
数据压缩与编码策略
2.2.3 数据计算层
计算层负责数据的加工、转换和分析:
批处理计算:
-
Hadoop MapReduce(传统)
-
Spark(现代标准)
-
Flink Batch(统一流批)
流处理计算:
-
实时处理:Flink、Spark Streaming
-
复杂事件处理:Kafka Streams
-
云原生:AWS Kinesis Analytics
交互式查询:
-
Presto/Trino:联邦查询引擎
-
Apache Drill:无模式查询
-
ClickHouse:实时分析
计算架构模式:
-
Lambda架构:流批分离,结果合并
-
Kappa架构:全流式处理
-
湖仓一体架构:统一存储,多种计算引擎
2.2.4 数据服务层
服务层将加工后的数据以标准化方式提供给消费者:
核心服务能力:
-
数据API服务:REST/GraphQL接口
-
数据产品化:特征工程、指标计算
-
数据市场:内部数据目录和发现
-
数据沙箱:数据探索和实验环境
微服务化数据架构:
java
// 示例:数据服务API设计
@DataService
public class CustomerDataService {
@GetMapping("/customers/{id}/360-view")
public Customer360View getCustomer360(@PathVariable String id) {
// 整合来自多个源系统的客户数据
CustomerBasicInfo basicInfo = customerRepo.findById(id);
List<Order> recentOrders = orderService.getRecentOrders(id);
CustomerBehavior behavior = behaviorAnalytics.getBehavior(id);
return new Customer360View(basicInfo, recentOrders, behavior);
}
@PostMapping("/analytics/customer-segments")
public SegmentResult analyzeSegments(@RequestBody SegmentRequest request) {
// 调用ML模型进行客户分群
return mlService.predictSegments(request);
}
}
2.2.5 数据消费层
最终用户与数据的交互界面:
数据可视化:
-
BI工具:Tableau、Power BI、QuickSight
-
自定义仪表板:Superset、Metabase
-
嵌入式分析:在应用中直接集成
数据应用开发:
-
报表系统
-
推荐引擎
-
风险控制系统
-
智能客服系统
数据API消费:
-
微服务调用
-
移动应用集成
-
合作伙伴数据交换
第三章:关键数据架构模式详解
3.1 数据湖仓一体化架构
湖仓一体(Lakehouse)结合了数据湖的灵活性和数据仓库的管理能力:
核心特征:
-
统一存储层:使用开放格式(Delta Lake、Iceberg、Hudi)
-
事务支持:ACID事务保障数据一致性
-
模式演化:支持灵活的模式变更
-
统一治理:数据血缘、质量监控、访问控制
实现方案:
text
┌─────────────────────────────────────────────────┐ │ 统一数据湖仓 │ │ ┌─────────────┐ ┌─────────────┐ │ │ │ 数据仓库层 │ │ 数据湖层 │ │ │ │ · 维度建模 │ │ · 原始数据 │ │ │ │ · 星型模式 │ │ · 多格式存储 │ │ │ │ · 高性能查询│ │ · 数据探索 │ │ │ └─────────────┘ └─────────────┘ │ │ Delta Lake / Iceberg │ └─────────────────────────────────────────────────┘
3.2 数据网格架构
数据网格(Data Mesh)是一种分布式、去中心化的数据架构范式:
四大核心原则:
-
领域数据所有权:业务领域团队负责自己的数据产品
-
数据即产品:将数据视为产品,有明确的SLA和文档
-
自助式数据平台:提供标准化数据基础设施
-
联邦式数据治理:统一策略,分散执行
实施架构:
text
┌─────────────────────────────────────────────────────┐ │ 联邦数据治理委员会 │ ├─────────────────────────────────────────────────────┤ │ ┌──────────┐ ┌──────────┐ ┌──────────┐ │ │ │ 领域A │ │ 领域B │ │ 领域C │ │ │ │ 数据产品 │ │ 数据产品 │ │ 数据产品 │ │ │ └──────────┘ └──────────┘ └──────────┘ │ ├─────────────────────────────────────────────────────┤ │ 自助式数据平台(数据网格基础设施) │ │ 数据发现│数据管道│数据质量│数据安全│监控告警 │ └─────────────────────────────────────────────────────┘
技术实现要点:
-
数据产品API化(gRPC/GraphQL)
-
数据合约(Data Contracts)定义接口规范
-
数据产品目录(Data Catalog)实现可发现性
-
跨域数据血缘追踪
3.3 实时数据架构
满足低延迟数据分析需求的架构模式:
典型架构组件:
text
┌─────────────────────────────────────────────────┐
│ 数据源层 │
│ DB│日志│IoT│应用事件 │
└─────────────────┬───────────────────────────────┘
│ CDC / 日志采集
↓
┌─────────────────────────────────────────────────┐
│ 消息队列层 │
│ Kafka / Pulsar / Kinesis │
└─────────────────┬───────────────────────────────┘
│ 流处理
↓
┌─────────────────────────────────────────────────┐
│ 流计算层 │
│ Flink / Spark Streaming / ksqlDB │
└─────────────────┬───────────────────────────────┘
│ 实时存储
↓
┌─────────────────────────────────────────────────┐
│ 实时存储层 │
│ 时序数据库│KV存储│OLAP数据库 │
└─────────────────────────────────────────────────┘
实时应用场景:
-
实时监控与告警
-
实时推荐系统
-
欺诈检测
-
IoT数据处理
第四章:数据建模与设计
4.1 多层次数据建模
4.1.1 概念数据模型(CDM)
-
识别关键业务实体和关系
-
与技术实现无关
-
用于业务沟通和需求分析
-
工具:ER图、UML类图
4.1.2 逻辑数据模型(LDM)
-
详细定义实体、属性和关系
-
规范化设计(通常到3NF)
-
数据类型和约束定义
-
示例:客户实体定义
sql
-- 逻辑模型示例
ENTITY Customer {
customer_id: UUID (PK)
customer_name: VARCHAR(100) NOT NULL
email: VARCHAR(255) UNIQUE
registration_date: DATE NOT NULL
status: ENUM('active', 'inactive', 'suspended')
RELATIONSHIPS:
Places Order (1:N)
Has Address (1:N)
}
4.1.3 物理数据模型(PDM)
-
针对特定数据库系统的实现
-
考虑性能优化(索引、分区)
-
存储引擎特性利用
sql
-- 物理模型示例
CREATE TABLE customers (
customer_id UUID DEFAULT gen_random_uuid() PRIMARY KEY,
customer_name VARCHAR(100) NOT NULL,
email VARCHAR(255) UNIQUE NOT NULL,
registration_date DATE NOT NULL DEFAULT CURRENT_DATE,
status VARCHAR(20) NOT NULL DEFAULT 'active',
created_at TIMESTAMP NOT NULL DEFAULT NOW(),
updated_at TIMESTAMP NOT NULL DEFAULT NOW(),
-- 索引设计
INDEX idx_customer_email (email),
INDEX idx_customer_status (status),
-- 分区策略
PARTITION BY HASH(customer_id)
) WITH (
-- 存储参数
orientation = column,
compression = lz4
);
4.2 维度建模详解
4.2.1 星型模式
sql
-- 事实表
CREATE TABLE sales_fact (
sale_id BIGINT PRIMARY KEY,
date_id INT NOT NULL, -- 外键到时间维度
product_id INT NOT NULL, -- 外键到产品维度
customer_id INT NOT NULL, -- 外键到客户维度
store_id INT NOT NULL, -- 外键到门店维度
quantity INT NOT NULL,
amount DECIMAL(10,2) NOT NULL,
discount DECIMAL(5,2),
net_amount DECIMAL(10,2)
);
-- 维度表
CREATE TABLE dim_date (
date_id INT PRIMARY KEY,
full_date DATE NOT NULL,
year INT NOT NULL,
quarter INT NOT NULL,
month INT NOT NULL,
week INT NOT NULL,
day_of_week INT NOT NULL,
is_weekend BOOLEAN NOT NULL,
is_holiday BOOLEAN NOT NULL
);
-- 缓慢变化维(SCD)设计
CREATE TABLE dim_customer (
customer_key INT PRIMARY KEY,
customer_id INT NOT NULL,
customer_name VARCHAR(100) NOT NULL,
email VARCHAR(255),
customer_segment VARCHAR(50),
start_date DATE NOT NULL,
end_date DATE,
is_current BOOLEAN DEFAULT TRUE,
version INT DEFAULT 1
);
4.2.2 数据仓库总线架构
-
一致性维度:跨业务过程的标准化维度
-
一致性事实:统一的事实定义和计算逻辑
-
企业数据总线矩阵:连接业务过程与维度
4.3 现代数据建模趋势
4.3.1 数据产品建模
-
面向领域的数据产品设计
-
API优先的数据建模
-
数据契约(Data Contracts)定义接口
4.3.2 机器学习特征工程
-
特征存储(Feature Store)设计
-
离线特征与在线特征一致性
-
特征版本管理和回溯
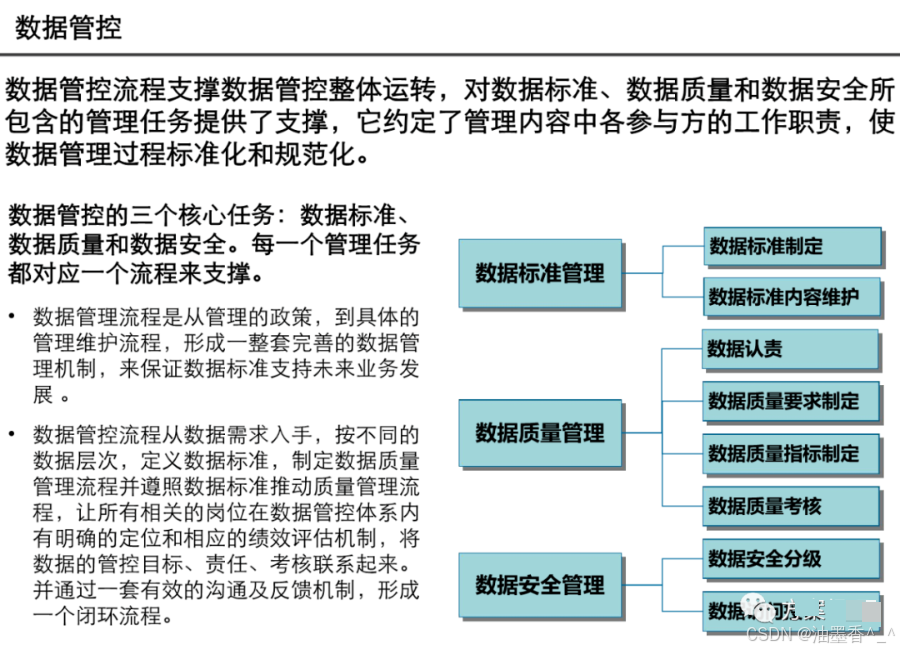
第五章:数据集成与ETL/ELT设计
5.1 数据集成模式
5.1.1 ETL vs ELT
text
ETL模式: ELT模式: 源系统 → 转换 → 目标仓库 源系统 → 目标仓库 → 转换 优点:目标库负载小 优点:灵活性高,利用目标库计算能力 缺点:转换逻辑固定 缺点:目标库负载大 适合:传统数据仓库 适合:现代云数据平台
5.1.2 实时数据集成
-
Change Data Capture(CDC)
-
基于日志的变更捕获
-
双写模式(应用层双写)
5.2 现代数据管道设计
5.2.1 声明式数据管道
yaml
# 示例:使用dbt的声明式转换
version: 2
models:
- name: customer_orders
description: "客户订单聚合视图"
config:
materialized: view
cluster_by: customer_id
columns:
- name: customer_id
tests:
- not_null
- unique
- name: total_orders
description: "总订单数"
- name: total_amount
description: "总消费金额"
sql: |
SELECT
customer_id,
COUNT(*) as total_orders,
SUM(net_amount) as total_amount,
MAX(order_date) as last_order_date
FROM {{ ref('stg_orders') }}
GROUP BY customer_id
5.2.2 数据管道编排
-
工作流调度:Airflow、Dagster、Prefect
-
任务依赖管理
-
故障恢复与重试机制
-
监控与告警
5.3 数据质量框架
5.3.1 数据质量维度
-
准确性:数据正确反映现实的程度
-
完整性:数据无缺失的程度
-
一致性:数据在不同系统间的一致程度
-
及时性:数据更新的及时程度
-
有效性:数据符合定义格式和范围的程度
-
唯一性:无重复记录的程度
5.3.2 数据质量检查框架
python
# 数据质量检查示例
class DataQualityFramework:
def __init__(self, data_source):
self.data_source = data_source
self.checks = []
def add_check(self, check_name, check_func, severity='error'):
self.checks.append({
'name': check_name,
'func': check_func,
'severity': severity
})
def run_checks(self):
results = []
for check in self.checks:
try:
passed = check['func'](self.data_source)
results.append({
'check': check['name'],
'status': 'PASS' if passed else 'FAIL',
'severity': check['severity']
})
except Exception as e:
results.append({
'check': check['name'],
'status': 'ERROR',
'error': str(e),
'severity': check['severity']
})
return results
# 定义检查规则
dq_framework = DataQualityFramework('customer_table')
dq_framework.add_check(
'非空检查',
lambda df: df['customer_id'].notnull().all(),
'error'
)
dq_framework.add_check(
'唯一性检查',
lambda df: df['customer_id'].is_unique,
'warning'
)
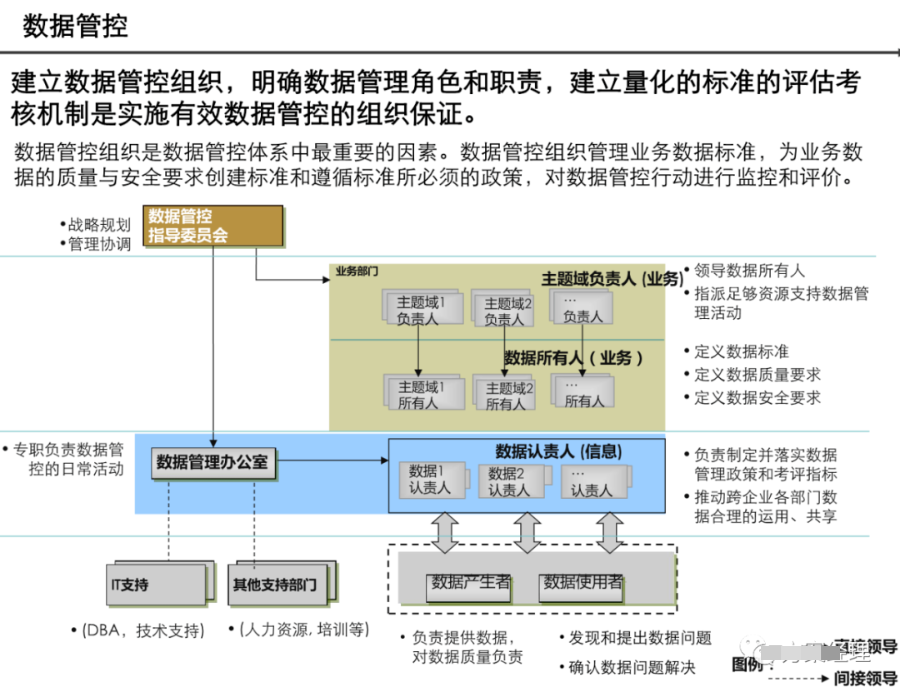
第六章:数据治理与安全
6.1 数据治理框架
6.1.1 数据治理组织
-
数据治理委员会
-
数据所有者(Data Owner)
-
数据管家(Data Steward)
-
数据工程师团队
6.1.2 数据治理流程
-
数据识别与分类
-
元数据管理
-
数据血缘分析
-
数据质量监控
-
主数据管理
-
数据生命周期管理
6.2 数据安全架构
6.2.1 安全防护层次
text
应用层安全
↓
API网关安全
↓
数据访问层安全
↓
数据存储层安全
↓
基础设施安全
6.2.2 数据加密策略
-
传输加密:TLS/SSL
-
静态加密:数据库级、文件级加密
-
字段级加密:敏感数据单独加密
-
同态加密:计算时无需解密
6.2.3 数据脱敏与匿名化
sql
-- 动态数据脱敏示例
CREATE VIEW masked_customers AS
SELECT
customer_id,
-- 部分隐藏邮箱
CONCAT(
SUBSTRING(email, 1, 3),
'****',
SUBSTRING(email, LOCATE('@', email))
) as masked_email,
-- 隐藏手机号中间四位
CONCAT(
SUBSTRING(phone, 1, 3),
'****',
SUBSTRING(phone, 8)
) as masked_phone,
-- 其他非敏感字段
registration_date,
status
FROM customers;
6.3 隐私合规设计
6.3.1 GDPR/CCPA合规要求
-
数据主体权利:访问、更正、删除
-
数据保护影响评估(DPIA)
-
数据跨境传输机制
-
数据泄露通知流程
6.3.2 数据可追溯性设计
-
数据血缘追踪
-
数据变更审计
-
数据使用日志
-
同意管理记录
第七章:性能优化与成本管理
7.1 数据架构性能优化
7.1.1 查询性能优化
-
查询重写与优化
-
物化视图
-
查询缓存策略
-
数据分区与分桶
7.1.2 数据处理性能优化
-
并行处理设计
-
内存优化配置
-
数据本地性优化
-
压缩算法选择
7.2 成本优化策略
7.2.1 存储成本优化
-
数据生命周期管理
-
存储分层(热、温、冷、冰)
-
数据压缩与编码
-
重复数据删除
7.2.2 计算成本优化
-
自动伸缩策略
-
批处理窗口优化
-
计算引擎选择
-
资源调度优化
7.2.3 成本监控与优化框架
python
class DataCostOptimizer:
def __init__(self, cloud_provider='aws'):
self.cloud_provider = cloud_provider
self.cost_metrics = {}
def analyze_storage_cost(self, storage_path):
"""分析存储成本"""
# 识别存储类型(热、温、冷)
# 分析访问模式
# 推荐优化策略
pass
def optimize_query_cost(self, query_history):
"""基于查询历史优化成本"""
# 识别昂贵查询
# 推荐索引或物化视图
# 查询重写建议
pass
def implement_optimizations(self, recommendations):
"""执行成本优化建议"""
for rec in recommendations:
if rec['type'] == 'storage_tiering':
self.move_to_cheaper_storage(rec['data'])
elif rec['type'] == 'query_optimization':
self.create_materialized_view(rec['query'])
第八章:技术选型与实施策略
8.1 技术栈选型指南
8.1.1 开源 vs 商业解决方案
text
开源方案优势: 商业方案优势: - 无许可费用 - 企业级支持 - 社区活跃 - 集成解决方案 - 可定制化 - 易用性高 - 避免厂商锁定 - 安全合规认证
8.1.2 云原生 vs 本地部署
text
云原生优势: 本地部署优势: - 弹性伸缩 - 数据主权控制 - 按需付费 - 长期成本可控 - 免运维基础设施 - 低延迟要求 - 丰富的托管服务 - 特定合规要求
8.2 参考技术架构
8.2.1 中小型企业数据架构
text
数据源 → Fivetran/Airbyte → Snowflake/BigQuery → dbt →
→ 数据目录(Amundsen) → BI工具(Tableau/Metabase)
8.2.2 大型企业数据架构
text
┌─────────────────────────────────────────────────────────┐
│ 数据治理平台 │
│ Collibra / Alation / DataHub │
└─────────────────────────────────────────────────────────┘
│
┌─────────────────────────────────────────────────────────┐
│ 数据集成层 │
│ Airflow + dbt + Spark (Delta Lake) │
└─────────────────────────────────────────────────────────┘
│
┌─────────────────────────────────────────────────────────┐
│ 数据存储层 │
│ 数据湖(S3/ADLS) + 数据仓库(Snowflake) + NoSQL │
└─────────────────────────────────────────────────────────┘
│
┌─────────────────────────────────────────────────────────┐
│ 数据服务层 │
│ 数据API + 特征存储(Feast) + 实时计算(Flink) │
└─────────────────────────────────────────────────────────┘
8.3 实施路线图
8.3.1 阶段化实施策略
第一阶段:基础建设(1-3个月)
-
数据采集管道搭建
-
核心数据仓库建设
-
基础数据治理建立
第二阶段:能力扩展(4-9个月)
-
数据湖建设
-
实时数据处理能力
-
数据产品化
第三阶段:成熟运营(10-18个月)
-
数据网格架构演进
-
AI/ML能力集成
-
数据市场建设
8.3.2 成功关键因素
-
业务驱动:从业务价值最高的用例开始
-
迭代演进:小步快跑,持续改进
-
组织适配:建立跨职能数据团队
-
文化培养:建设数据驱动文化
第九章:案例分析与最佳实践
9.1 电商平台数据架构案例
9.1.1 业务挑战
-
海量用户行为数据
-
实时推荐需求
-
多维度业务分析
-
数据孤岛严重
9.1.2 架构设计
text
┌─────────────────────────────────────────────────┐
│ 数据源:订单DB|用户日志|点击流|外部数据 │
└────────────────┬────────────────────────────────┘
│
┌────────────┴────────────┐
│ 实时层 │ 批量层
│ Kafka + Flink │ Airflow + Spark
└────────────┬────────────┘
│
┌────────────┴────────────┐
│ 统一数据湖仓 │
│ Delta Lake on S3 │
└────────────┬────────────┘
│
┌────────────┴────────────┐
│ 数据服务层 │
│ 特征存储|指标平台|API │
└────────────┬────────────┘
│
┌────────────┴────────────┐
│ 数据应用层 │
│ 实时推荐|用户画像|BI │
└─────────────────────────┘
9.1.3 成效与价值
-
推荐转化率提升15%
-
数据分析时效从T+1到实时
-
数据开发效率提升50%
-
存储成本降低40%
9.2 金融行业数据架构案例
9.2.1 合规性要求
-
强数据一致性要求
-
严格的安全与审计
-
监管报表需求
-
实时风控需求
9.2.2 架构特点
-
混合云部署(敏感数据本地化)
-
多活数据中心设计
-
完整的审计追溯链
-
实时风险计算引擎
第十章:未来趋势与演进方向
10.1 技术发展趋势
10.1.1 AI增强的数据管理
-
自动化数据质量管理
-
智能数据发现与分类
-
自然语言查询接口
-
自动化ETL管道生成
10.1.2 实时数据架构普及
-
流批一体化成为标配
-
事件驱动架构扩展
-
实时特征工程标准化
10.1.3 数据编织(Data Fabric)
-
自动化数据集成
-
主动元数据管理
-
语义知识图谱
-
增强的数据发现
10.2 架构演进建议
10.2.1 向数据网格演进
-
从集中式到分布式治理
-
建立数据产品思维
-
建设自助数据平台
10.2.2 增强数据可观测性
-
全面监控数据流水线
-
数据SLA定义与监控
-
自动化根因分析
10.2.3 建立数据经济
-
内部数据价值计量
-
数据产品市场化
-
数据质量与价值关联
结论
数据架构设计是一项复杂而系统的工程,需要平衡技术先进性、业务需求、成本效益和长期演进。优秀的数据架构不是一次性建成的,而是随着组织发展持续演进的过程。关键在于:
-
以终为始:始终围绕业务价值设计架构
-
保持灵活:选择开放、可扩展的技术栈
-
治理先行:建立坚实的数据治理基础
-
持续演进:适应技术和业务的变化
未来的数据架构将更加智能化、实时化和民主化。数据不再是IT部门的专属资产,而是整个组织的创新引擎。构建面向未来的数据架构,就是为组织在数字化时代的竞争优势奠定基础。
无论您是刚开始数据架构旅程,还是正在重构现有架构,希望本文提供的框架、模式和最佳实践能够为您提供有价值的参考。数据架构的终极目标,是让数据在组织内自由、安全、高效地流动,真正成为驱动业务增长和创新的核心动力。
附录:关键术语表
-
CDC:变更数据捕获
-
ETL/ELT:提取-转换-加载/提取-加载-转换
-
OLTP:在线事务处理
-
OLAP:在线分析处理
-
MPP:大规模并行处理
-
ACID:原子性、一致性、隔离性、持久性
-
SLAL:服务水平协议
-
Data Mesh:数据网格
-
Data Fabric:数据编织
-
Lakehouse:湖仓一体
-
Feature Store:特征存储
-
Data Contract:数据契约
-
Data Product:数据产品
-
Data Catalog:数据目录

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 22
22 0
0- 0



 已为社区贡献60条内容
已为社区贡献60条内容

所有评论(0)