论文阅读:AIED 2025 Dyslexia and AI: Do Language Models Align with Dyslexic Style Guide Criteria?
本研究是一项概念验证研究,聚焦阅读障碍友好文本标准与语言模型(LMs)的适配性,首次提出量化标准的DysText指标,基于英国阅读障碍协会的《阅读障碍风格指南》评估了Gemma、Phi4和GPT4-turbo三款模型。研究发现,这些模型仅能识别33项标准中的约13项,虽能显著提升文本的阅读障碍友好性(Phi4的DysText平均总分最高达3.24,满分11分),但存在推荐额外非标准标准、生成文本出
总目录 大模型相关研究:https://blog.csdn.net/WhiffeYF/article/details/142132328
https://link.springer.com/chapter/10.1007/978-3-031-98414-3_3
论文集下载:https://download.csdn.net/download/WhiffeYF/92543315
https://www.doubao.com/chat/35222653891057666
英文论文:https://download.csdn.net/download/WhiffeYF/92544327
论文翻译:https://blog.csdn.net/WhiffeYF/article/details/156708960
速览
1. 一段话总结
本研究是一项概念验证研究,聚焦阅读障碍友好文本标准与语言模型(LMs)的适配性,首次提出量化标准的DysText指标,基于英国阅读障碍协会的《阅读障碍风格指南》评估了Gemma、Phi4和GPT4-turbo三款模型。研究发现,这些模型仅能识别33项标准中的约13项,虽能显著提升文本的阅读障碍友好性(Phi4的DysText平均总分最高达3.24,满分11分),但存在推荐额外非标准标准、生成文本出现拼写错误、内容偏离主题等问题,不能盲目信任其输出,需进一步验证,且传统可读性指标LIX无法全面捕捉阅读障碍友好特征,结构化提示(如仅提供文本相关标准)能有效提升模型表现。
2. 思维导图(mindmap)

## 研究背景
- 阅读障碍现状:全球约10%-20%人口受影响,75%特殊教育需求学生有阅读困难
- 现有问题:缺乏量化阅读障碍友好文本的指标,LMs在该领域应用有限
- 核心依据:英国阅读障碍协会《阅读障碍风格指南》(33项标准)
## 研究目标与问题
- 目标:评估LMs对阅读障碍友好标准的识别与应用能力,提出量化指标
- 关键问题(RQ)
- RQ1:LMs能否有效识别《阅读障碍风格指南》标准?
- RQ2:LMs能否依据该指南生成友好文本?
- RQ3:提供指南标准后,LMs表现是否提升?
## 研究方法
- 数据收集:50章历史教材(西非高中证书考试教材+OpenStax《美国历史》)
- 评估模型:Gemma(7B参数)、Phi4(14B参数)、GPT4-turbo(千亿级参数)
- 提示工程:4类识别类提示、2类无指南生成提示、2类含指南生成提示
- 分析方法:描述性统计(均值/标准差等)、配对统计检验(p<0.05)、DysText指标(范围[-10,11])
## 核心发现
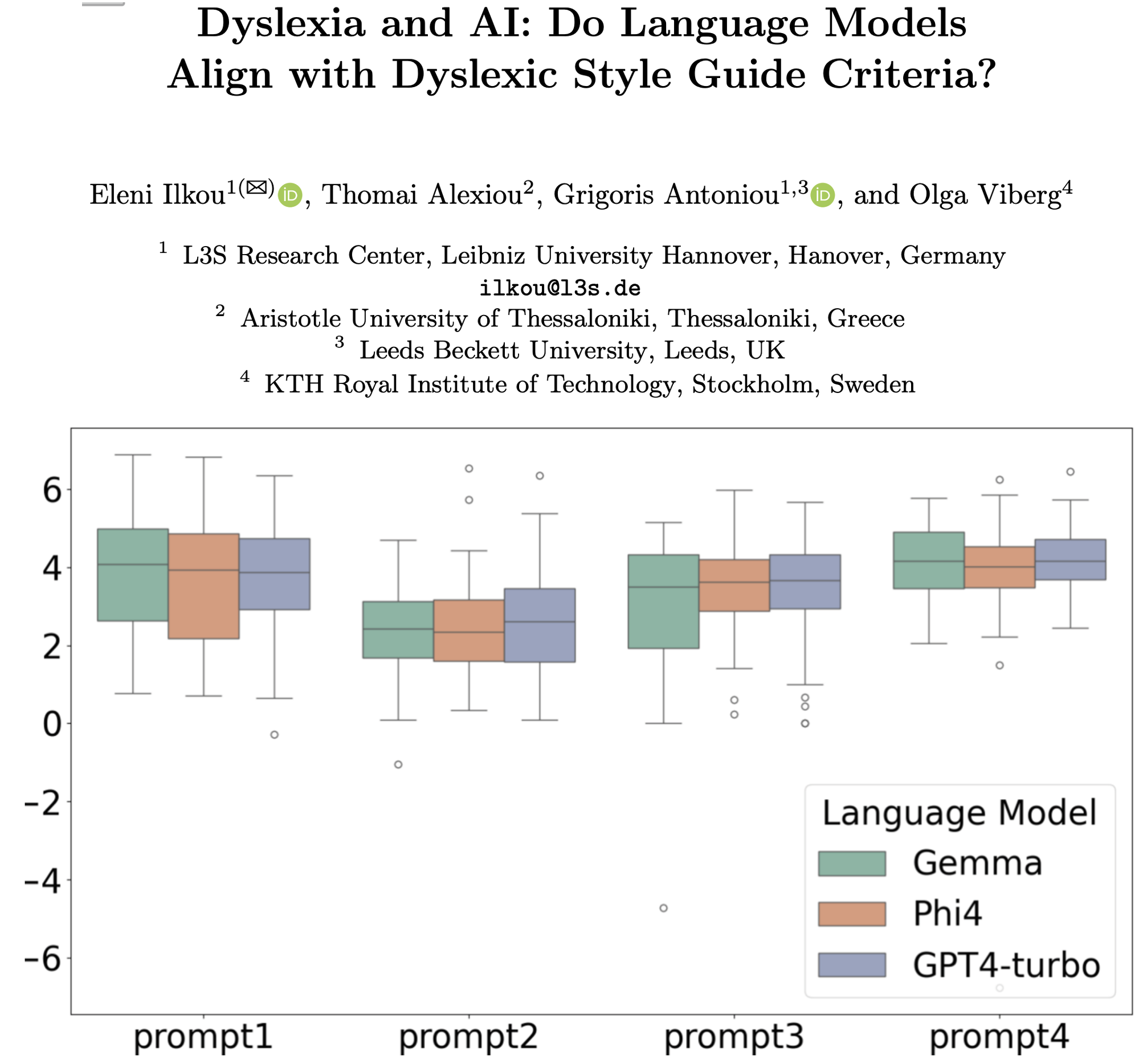
- 标准识别:模型仅识别约13项标准(占比39%),Phi4总分最高13.88
- 文本生成:三款模型DysText平均总分分别为2.88(Gemma)、3.24(Phi4)、2.22(GPT4-turbo),均有提升但远未达满分
- 模型局限:存在拼写错误、内容偏离、推荐非标准标准等问题,需验证
- 提示效果:结构化提示(文本相关标准)提升显著,Phi4实现100%视觉/内容/总分提升
- 指标对比:LIX指标无法全面反映阅读障碍友好特征
## 研究结论与展望
- 结论:LMs有提升潜力但需验证,DysText指标更具针对性
- 局限:仅支持英文文本、存在伦理法律风险、术语检测依赖专家验证
- 未来方向:构建基准数据集、扩展DysText指标至全标准、多语言适配
3. 详细总结
一、研究背景与意义
- 阅读障碍现状:全球约10%-20% 的人口患有阅读障碍,在特殊教育需求学生中,约75% 面临阅读困难,辅助技术对提升阅读障碍友好文本的可读性至关重要,但自然语言处理工具和语言模型(LMs)在该领域的应用仍有限。
- 现有痛点:
- 缺乏统一的阅读障碍友好文本黄金标准,现有指南(如联合国“易读性”标准、W3C-WAI)无强制要求;
- 无量化阅读障碍友好文本的专用指标,传统指标(LIX可读性指数、BLEU、BERTScore)仅能捕捉少数特征,无法匹配专业指南标准。
- 研究依据:采用英国阅读障碍协会(British Dyslexia Association)的《阅读障碍风格指南》,该指南包含33项具体标准,分为可通过JSON计算(C类,17项)和不可计算(O类,16项)两类。
二、研究目标与关键问题
| 研究目标 | 核心关键问题(RQ) |
|---|---|
| 1. 量化阅读障碍友好文本指南; 2. 评估LMs对该指南标准的识别能力; 3. 测试LMs生成友好文本的水平; 4. 验证提供指南标准后LMs的表现提升 |
RQ1:LMs能否有效识别《阅读障碍风格指南》的标准? RQ2:LMs依据该指南生成友好文本的效果如何? RQ3:提供指南标准后,LMs生成友好文本的表现是否改善? |
三、研究方法
- 数据收集:
- 来源:2本开源历史教材(西非高中证书考试教材+OpenStax《美国历史》);
- 规模:50章文本,排除短段落、注释和超链接,手动整理为JSON格式,保留换行特征。
- 评估模型:选择3款不同规模和架构的LMs,具体参数如下:
| 模型名称 | 开发者 | 参数规模 | 核心特征 |
|----------|--------|----------|----------|
| Gemma | Google | 7B | 基于Transformer解码器,英语预训练,适合本地部署 |
| Phi4 | Microsoft | 14B | 解码器架构,混合有机/合成数据预训练,STEM表现优异 |
| GPT4-turbo | OpenAI | 千亿级 | 稀疏注意力+混合专家架构,上下文窗口128k tokens | - 提示设计:
- 识别类提示(4条):如“使文本适合阅读障碍者的标准有哪些?”;
- 生成类提示(4条):2条无指南(如“将以下文本改为阅读障碍友好型”)、2条含指南(完整指南/仅JSON可计算标准)。
- 分析工具与指标:
- 描述性统计:最小值(Min.)、中位数(Mdn.)、最大值(Max.)、平均值(Av.)、标准差(SD);
- 统计检验:Shapiro-Wilk正态性检验、配对t检验(正态分布)、Wilcoxon符号秩检验(非正态分布),显著性水平p<0.05;
- 专用指标:DysText(首次提出),量化17项可计算标准,得分范围[-10,11],0-1分表示提升友好性,-1-0分表示阻碍友好性。
四、核心研究结果
-
LMs对标准的识别能力(RQ1答案):
- 整体表现:三款模型均仅识别不到一半标准(33项中约13项),Phi4总分最高(13.88),Gemma10.13,GPT4-turbo13.00;
- 常见遗漏:字体大小/样式、短句使用、简单语言等关键标准;
- 额外推荐:均推荐非指南标准(如OpenDyslexic字体、音频支持),部分存在风险(如过度鼓励可能造成羞辱感)。
-
LMs生成友好文本的效果(RQ2答案):
- DysText得分:Phi4平均总分3.24(最高),Gemma2.88,GPT4-turbo2.22(满分11分);
- 文本特征变化(对比原始文本):
指标 原始文本平均 Gemma生成平均 Phi4生成平均 GPT4-turbo生成平均 句子数(No. Sentences) 24.74 17.24 21.37 15.18 单词数(No. Words) 538.84 280.46 330.56 356.11 段落数(含标题/项目符号) 4.82 7.22 15.35 11.80 LIX可读性得分 49.68 43.81 48.79 60.84 - 质量问题:存在拼写错误(如Gemma将“the”改为“da”)、标题表述不当(如“[主题]-更易读”有居高临下感)、内容偏离(GPT4-turbo在殖民相关主题中出现无意义重复)。
-
提供指南后LMs的表现提升(RQ3答案):
- 整体提升:所有提示下模型表现均有统计显著提升(p<0.05);
- 最佳提示:仅提供JSON可计算标准的提示(提示4)效果最优,Phi4实现100%视觉/内容/总分提升,Gemma96%视觉提升、100%内容/总分提升,GPT4-turbo100%视觉提升、98%内容/总分提升;
- 模型差异:Gemma因上下文窗口较小(8192 tokens),在精简提示下表现更优。
-
指标对比:传统LIX指标与DysText相关性低,如Phi4的LIX仅从49.68小幅降至48.79,但DysText总分最高,说明LIX无法捕捉阅读障碍友好文本的核心特征(如项目符号、段落间距等)。
五、研究结论与展望
- 核心结论:
- LMs对阅读障碍友好标准的知识有限,但能显著提升文本友好性;
- 生成文本存在质量风险,不能盲目信任,需人工验证;
- DysText指标比传统LIX更适合评估阅读障碍友好文本;
- 结构化提示(如精简的文本相关标准)能有效优化模型表现。
- 研究局限:仅支持英文文本、存在伦理法律风险(如GPT4-turbo在敏感历史主题上的偏差)、术语检测依赖专家验证。
- 未来方向:构建原始文本与阅读障碍友好文本的基准数据集、扩展DysText至全部33项标准、实现多语言适配、分析模型在各标准上的优劣表现。
4. 关键问题
问题1:研究提出的DysText指标有何创新之处?其核心特征是什么?
答案:创新之处在于它是首个量化阅读障碍友好文本标准的指标,填补了现有评估工具无法匹配专业指南的空白。核心特征:① 基于英国阅读障碍协会《阅读障碍风格指南》,聚焦17项可通过JSON计算的标准;② 得分范围为[-10,11],0-1分表示符合标准(提升友好性),-1-0分表示违反标准(阻碍友好性);③ 同时涵盖文本视觉特征(如段落间距、项目符号)和内容特征(如短句、主动语态),比传统LIX指标更全面捕捉阅读障碍友好属性。
问题2:三款评估模型(Gemma、Phi4、GPT4-turbo)在生成阅读障碍友好文本方面的表现差异如何?
答案:表现差异主要体现在DysText得分、文本特征和质量上,具体对比如下:
| 模型 | DysText平均总分 | 核心优势 | 主要不足 |
|---|---|---|---|
| Phi4 | 3.24(最高) | 100%文本提升率,常提供术语表/摘要 | LIX指标改善不明显(49.68→48.79) |
| Gemma | 2.88 | 文本最简洁,内容得分最高 | 存在拼写错误(如“Diplomcy”) |
| GPT4-turbo | 2.22(最低) | 上下文窗口最大(128k tokens) | 内容易偏离主题、敏感主题出现无意义重复 |
问题3:如何有效提升语言模型生成阅读障碍友好文本的性能?研究给出了哪些关键建议?
答案:关键提升策略及建议如下:① 采用结构化提示:优先提供仅与文本相关的可计算标准(如DysText对应的17项C类标准),避免完整指南的信息过载,该方式使Phi4实现100%提升,Gemma和GPT4-turbo提升率超96%;② 避免盲目信任模型输出:需通过人工验证解决拼写错误、内容偏离、表述不当等问题;③ 选择适配场景的模型:小规模模型(如Gemma)适合本地部署(学校/个人电脑),大规模模型(如GPT4-turbo)需控制上下文长度避免信息丢失;④ 采用专用评估指标:用DysText替代传统LIX指标,全面评估文本的阅读障碍友好特征。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 21
21 0
0- 0



 已为社区贡献78条内容
已为社区贡献78条内容

所有评论(0)