LangChain 全面解析:构建强大大语言模型应用的利器
在当今人工智能飞速发展的时代,大语言模型(LLMs)如 GPT - 4、Claude 等凭借其强大的自然语言处理能力,在各个领域崭露头角。然而,要将这些强大的模型应用到实际业务场景中,仅仅依靠模型本身往往是不够的。这时候,LangChain 应运而生。LangChain 是一个开源的 Python 框架,它旨在简化大语言模型应用的开发过程,为开发者提供了一套工具、组件和接口,能够轻松地将大语言模型
大家好,我是玖日大大,前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。
https://www.captainbed.cn/jr![]() https://www.captainbed.cn/jr
https://www.captainbed.cn/jr
一、LangChain 概述
1.1 什么是 LangChain
在当今人工智能飞速发展的时代,大语言模型(LLMs)如 GPT - 4、Claude 等凭借其强大的自然语言处理能力,在各个领域崭露头角。然而,要将这些强大的模型应用到实际业务场景中,仅仅依靠模型本身往往是不够的。这时候,LangChain 应运而生。
LangChain 是一个开源的 Python 框架,它旨在简化大语言模型应用的开发过程,为开发者提供了一套工具、组件和接口,能够轻松地将大语言模型与其他数据源、应用程序和服务进行集成,从而构建出更加强大、灵活且实用的 AI 应用。简单来说,LangChain 就像是一个 “桥梁”,连接了孤立的大语言模型和丰富的外部资源,让大语言模型能够更好地理解现实世界的复杂问题,并给出更准确、更有价值的答案。
1.2 LangChain 的核心价值
LangChain 的核心价值主要体现在以下几个方面:
首先,模块化与可扩展性。LangChain 将大语言模型应用的各个环节拆分成独立的模块,如文档加载、文本分割、向量存储、提示词工程、链和代理等。每个模块都具有良好的封装性和可替换性,开发者可以根据自己的需求选择合适的模块进行组合,也可以自定义模块来满足特定的业务场景。这种模块化的设计使得 LangChain 具有极高的可扩展性,能够适应不同规模、不同领域的应用开发需求。
其次,集成能力。LangChain 支持与多种主流的大语言模型(如 OpenAI 的 GPT 系列、Anthropic 的 Claude、Google 的 PaLM 等)进行集成,同时还能够连接各种外部数据源(如 PDF 文档、Excel 表格、数据库、API 接口等)和应用服务(如搜索引擎、邮件系统、任务管理工具等)。通过这种强大的集成能力,开发者可以让大语言模型获取更多的信息,从而提升应用的智能化水平和实用性。
再者,简化开发流程。传统的大语言模型应用开发往往需要开发者处理大量复杂的技术细节,如模型调用、数据处理、流程控制等。而 LangChain 通过提供简洁易用的 API 和丰富的预置组件,大大简化了这些开发流程。开发者可以专注于业务逻辑的设计,而无需过多关注底层技术实现,从而提高开发效率,降低开发成本。
最后,支持复杂应用场景。随着 AI 技术的不断发展,越来越多的应用场景需要大语言模型具备更强的综合能力,如多轮对话、知识问答、任务规划、数据分析等。LangChain 通过其强大的链(Chains)和代理(Agents)功能,能够支持这些复杂的应用场景。例如,通过链可以将多个简单的操作组合成一个复杂的流程,实现多步推理;通过代理可以让大语言模型根据具体情况自主选择工具和执行步骤,实现更灵活的任务处理。
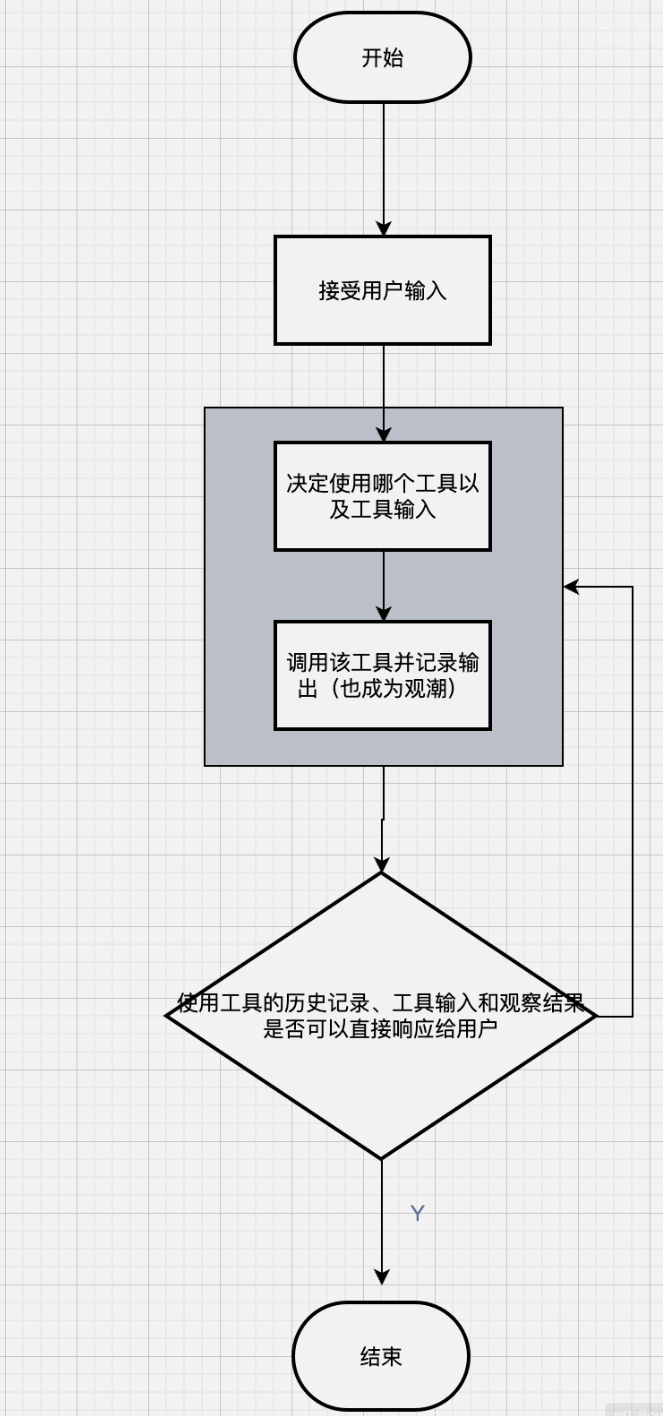
二、LangChain 核心组件
2.1 文档加载器(Document Loaders)
在很多大语言模型应用中,需要处理各种类型的文档数据,如 PDF、Word、TXT、Excel、HTML 等。文档加载器的作用就是将这些不同格式的文档数据加载到 LangChain 中,并将其转换为统一的文档对象(Document)格式,以便后续的处理和分析。
LangChain 提供了丰富的文档加载器,支持多种常见的文档格式和数据源。以下是一些常用的文档加载器及其使用示例:
2.1.1 PDF 文档加载器(PyPDFLoader)
PyPDFLoader 是 LangChain 中用于加载 PDF 文档的加载器,它基于 PyPDF 库实现。使用 PyPDFLoader 可以轻松地将 PDF 文档中的文本内容提取出来,并转换为 Document 对象列表。
from langchain.document_loaders import PyPDFLoader
# 初始化PDF加载器,指定PDF文件路径
loader = PyPDFLoader("example.pdf")
# 加载PDF文档,返回Document对象列表
documents = loader.load()
# 打印文档数量
print(f"加载的文档数量:{len(documents)}")
# 打印第一个文档的内容(前500个字符)
if documents:
print("第一个文档的内容:")
print(documents[0].page_content[:500])在上述代码中,首先导入了 PyPDFLoader 类,然后通过指定 PDF 文件的路径初始化了一个加载器对象。接着调用 load () 方法加载 PDF 文档,得到一个 Document 对象列表。每个 Document 对象包含了 PDF 文档中某一页的文本内容(page_content)和一些元数据(如页码、文件路径等)。
2.1.2 TXT 文档加载器(TextLoader)
TextLoader 用于加载 TXT 格式的文档,它可以直接读取 TXT 文件中的文本内容,并转换为 Document 对象。
from langchain.document_loaders import TextLoader
# 初始化TXT加载器,指定TXT文件路径
loader = TextLoader("example.txt", encoding="utf-8")
# 加载TXT文档,返回Document对象
document = loader.load()
# 打印文档内容
print("TXT文档的内容:")
print(document[0].page_content)这里需要注意指定正确的文件编码(如 utf - 8),以避免出现乱码问题。
2.1.3 网页内容加载器(WebBaseLoader)
WebBaseLoader 可以加载网页上的内容,它通过请求网页 URL,提取网页中的文本内容,并转换为 Document 对象。
from langchain.document_loaders import TextLoader
# 初始化TXT加载器,指定TXT文件路径
loader = TextLoader("example.txt", encoding="utf-8")
# 加载TXT文档,返回Document对象
document = loader.load()
# 打印文档内容
print("TXT文档的内容:")
print(document[0].page_content)WebBaseLoader 会自动处理网页的 HTML 结构,提取其中的主要文本内容,去除 HTML 标签和无关信息。
除了上述介绍的几种文档加载器外,LangChain 还提供了很多其他类型的加载器,如 ExcelLoader(加载 Excel 文档)、Docx2txtLoader(加载 Word 文档)、DatabaseLoader(加载数据库数据)等。开发者可以根据实际需求选择合适的文档加载器。
2.2 文本分割器(Text Splitters)
加载文档后,得到的文档对象可能包含大量的文本内容,直接将其输入到大语言模型中可能会超出模型的上下文窗口限制,同时也会增加模型的处理成本和时间。因此,需要使用文本分割器将长文本分割成多个较短的文本片段,以便更好地进行后续处理。
LangChain 提供了多种文本分割器,每种分割器都有其独特的分割策略和适用场景。以下是一些常用的文本分割器:
2.2.1 字符文本分割器(CharacterTextSplitter)
CharacterTextSplitter 是一种基于字符数量的文本分割器,它按照指定的字符数量将文本分割成多个片段。这种分割器简单直观,适用于大多数文本类型。
from langchain.text_splitter import CharacterTextSplitter
# 初始化字符文本分割器,设置每个片段的最大字符数和重叠字符数
text_splitter = CharacterTextSplitter(
chunk_size=1000, # 每个片段的最大字符数
chunk_overlap=200, # 相邻片段的重叠字符数,用于保持上下文连贯性
length_function=len, # 计算文本长度的函数
is_separator_regex=False, # 是否将分隔符视为正则表达式
)
# 假设我们有一个长文本
long_text = """LangChain是一个非常强大的大语言模型应用开发框架,它提供了丰富的组件和工具,能够帮助开发者轻松地构建各种复杂的AI应用。无论是文档问答、多轮对话,还是任务规划、数据分析,LangChain都能够提供有力的支持。
在使用LangChain进行开发时,首先需要了解其核心组件,如文档加载器、文本分割器、向量存储、提示词工程、链和代理等。每个组件都有其特定的功能和用途,只有掌握了这些组件的使用方法,才能更好地利用LangChain进行应用开发。
此外,LangChain还支持与多种主流的大语言模型进行集成,如OpenAI的GPT系列、Anthropic的Claude等。开发者可以根据自己的需求选择合适的模型,并通过LangChain提供的API进行调用和管理。
总之,LangChain为大语言模型应用开发提供了一站式的解决方案,大大降低了开发难度,提高了开发效率,是广大AI开发者不可或缺的工具。"""
# 对长文本进行分割,返回分割后的文本片段列表
texts = text_splitter.split_text(long_text)
# 打印分割后的片段数量和每个片段的内容
print(f"分割后的片段数量:{len(texts)}")
for i, text in enumerate(texts, 1):
print(f"\n片段{i}:")
print(text)
print(f"片段{i}的字符数:{len(text)}")在上述代码中,chunk_size 参数指定了每个文本片段的最大字符数,chunk_overlap 参数指定了相邻片段之间的重叠字符数。设置适当的重叠字符数可以帮助保持文本的上下文连贯性,避免因分割导致的语义断裂。
2.2.2 递归字符文本分割器(RecursiveCharacterTextSplitter)
RecursiveCharacterTextSplitter 是 CharacterTextSplitter 的改进版本,它采用递归的方式进行文本分割。首先尝试使用指定的分隔符(如段落符、句子符、空格等)进行分割,如果分割后的片段仍然超过最大字符数,则继续递归分割,直到满足要求。这种分割器能够更好地保持文本的语义结构,适用于结构化较强的文本,如文章、报告等。
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 初始化递归字符文本分割器,设置分隔符列表、最大字符数和重叠字符数
text_splitter = RecursiveCharacterTextSplitter(
separators=["\n\n", "\n", ". ", " ", ""], # 分割符列表,优先级从高到低
chunk_size=500,
chunk_overlap=100,
length_function=len,
)
# 对上述长文本进行分割
texts = text_splitter.split_text(long_text)
# 打印分割结果
print(f"分割后的片段数量:{len(texts)}")
for i, text in enumerate(texts, 1):
print(f"\n片段{i}:")
print(text)
print(f"片段{i}的字符数:{len(text)}")RecursiveCharacterTextSplitter 会按照分隔符列表的优先级依次尝试分割文本。例如,首先尝试用两个换行符(段落分隔符)分割,如果某个段落的长度超过 chunk_size,则用一个换行符(句子分隔符)分割,以此类推。这种分割方式能够最大程度地保持文本的自然语义结构,提高后续处理的效果。
2.2.3 标记文本分割器(TokenTextSplitter)
TokenTextSplitter 是一种基于标记(Token)数量的文本分割器,它按照指定的标记数量将文本分割成多个片段。由于大语言模型通常是按照标记数量来计算上下文窗口大小的,因此使用 TokenTextSplitter 可以更准确地控制输入到模型中的文本长度,避免超出模型的上下文限制。
from langchain.text_splitter import TokenTextSplitter
# 初始化标记文本分割器,设置每个片段的最大标记数和重叠标记数
text_splitter = TokenTextSplitter(
chunk_size=200, # 每个片段的最大标记数
chunk_overlap=50, # 相邻片段的重叠标记数
)
# 对上述长文本进行分割
texts = text_splitter.split_text(long_text)
# 打印分割结果
print(f"分割后的片段数量:{len(texts)}")
for i, text in enumerate(texts, 1):
print(f"\n片段{i}:")
print(text)需要注意的是,不同的大语言模型使用的标记化方式可能不同,因此在使用 TokenTextSplitter 时,需要确保所使用的标记化方法与目标模型一致,以获得准确的标记数量计算结果。LangChain 默认使用的是 OpenAI 的标记化方法,如果需要使用其他模型的标记化方法,可以通过自定义 length_function 参数来实现。
2.3 向量存储(Vector Stores)
将文本分割成片段后,为了能够快速地进行文本检索和相似性匹配,需要将这些文本片段转换为向量表示,并存储到向量数据库中。向量存储的主要作用就是高效地存储和管理文本向量,同时提供快速的相似性搜索功能,以便在需要时能够快速找到与查询文本最相似的文本片段。
LangChain 支持多种主流的向量数据库,如 Chroma、FAISS、Pinecone、Weaviate 等。这些向量数据库各有特点,适用于不同的应用场景和规模。以下以 Chroma 和 FAISS 为例,介绍向量存储的使用方法。
2.3.1 Chroma 向量存储
Chroma 是一个轻量级、开源的向量数据库,它具有简单易用、部署方便、性能高效等特点,非常适合用于开发和测试环境。
首先,需要安装 Chroma 库:
pip install chromadb然后,使用 LangChain 将文本片段转换为向量并存储到 Chroma 中:
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.text_splitter import CharacterTextSplitter
from langchain.document_loaders import TextLoader
# 1. 加载文档
loader = TextLoader("example.txt", encoding="utf-8")
documents = loader.load()
# 2. 分割文本
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
# 3. 初始化嵌入模型(用于将文本转换为向量)
embeddings = OpenAIEmbeddings(openai_api_key="your-openai-api-key")
# 4. 初始化Chroma向量存储,并将文本片段转换为向量存储起来
db = Chroma.from_documents(
texts, # 要存储的文本片段(Document对象列表)
embeddings, # 嵌入模型
persist_directory="./chroma_db" # 向量存储的持久化目录
)
# 持久化向量存储(将向量数据保存到磁盘,以便后续使用)
db.persist()
# 5. 进行相似性搜索
query = "LangChain的核心组件有哪些?"
docs = db.similarity_search(query, k=3) # k表示返回最相似的前k个文本片段
# 打印搜索结果
print(f"与查询'{query}'最相似的{len(docs)}个文本片段:")
for i, doc in enumerate(docs, 1):
print(f"\n结果{i}:")
print(f"内容:{doc.page_content}")
print(f"元数据:{doc.metadata}")在上述代码中,首先通过 TextLoader 加载 TXT 文档,然后使用 CharacterTextSplitter 将文档分割成文本片段。接着,使用 OpenAIEmbeddings 作为嵌入模型,将文本片段转换为向量。最后,通过 Chroma.from_documents () 方法将向量存储到 Chroma 中,并可以通过 similarity_search () 方法进行相似性搜索,返回与查询文本最相似的前 k 个文本片段。
2.3.2 FAISS 向量存储
FAISS(Facebook AI Similarity Search)是 Facebook 开发的一个高效的向量相似性搜索库,它支持多种向量相似性搜索算法,具有较高的搜索性能和灵活性,适用于大规模向量数据的存储和搜索。
首先,需要安装 FAISS 库:
pip install faiss-cpu # CPU版本
# 或者
pip install faiss-gpu # GPU版本(需要CUDA支持)然后,使用 LangChain 将文本片段转换为向量并存储到 FAISS 中:
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.text_splitter import CharacterTextSplitter
from langchain.document_loaders import TextLoader
# 1. 加载文档
loader = TextLoader("example.txt", encoding="utf-8")
documents = loader.load()
# 2. 分割文本
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
# 3. 初始化嵌入模型
embeddings = OpenAIEmbeddings(openai_api_key="your-openai-api-key")
# 4. 初始化FAISS向量存储,并将文本片段转换为向量存储起来
db = FAISS.from_documents(texts, embeddings)
# 保存FAISS向量存储到磁盘
db.save_local("faiss_db")
# 从磁盘加载FAISS向量存储
# db = FAISS.load_local("faiss_db", embeddings)
# 5. </doubaocanvas>
有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 62
62 0
0- 0



 已为社区贡献32条内容
已为社区贡献32条内容

所有评论(0)