Langchain(十二)LangGraph 实战入门:用流程图思维构建 LLM 工作流
摘要: LangChain团队于2025年10月发布LangChain 1.0和LangGraph 1.0,标志着AI智能体开发框架进入成熟阶段。LangGraph作为核心组件,通过“节点-连线-状态”的可视化流程解决传统大语言模型应用的线性调用局限,支持多步骤任务、分支决策和状态持久化。本文以“推荐作家+生成风格化笑话”为例,详细讲解LangGraph的核心概念与开发流程,包括State(状态管
2025年10月,LangChain团队正式发布了LangChain 1.0和LangGraph 1.0版本,这标志着AI智能体开发框架进入了一个全新的成熟阶段。作为目前最受欢迎的智能体开发框架之一,这两个项目每月下载量已突破9000万次,被Uber、摩根大通、贝莱德、思科等众多企业采用。
LangGraph非常适合创建多代理工作流,因为它允许将两个或更多代理连接成一个图。每个代理都是一个独立的行动者,代理之间的连接由边缘表示。每个连接边缘都可以有一个控制条件,指导信息从一个代理流向另一个代理。每个代理都有一个状态,可以在每次流动过程中用信息更新。
在大语言模型应用开发中,单一的 “提问 - 回答” 模式难以满足复杂任务需求(如多步骤推理、分支决策、状态持久化)。LangGraph 作为 LangChain 生态的核心组件,将复杂任务拆解为 “节点(Node)- 连线(Edge)- 状态(State)” 的可视化流程,让开发者可以像画流程图一样构建可执行、可回溯、可扩展的 LLM 应用。本文将以 “推荐作家 + 生成风格化笑话” 为例,从零讲解 LangGraph 的核心概念与实战开发。
一、LangGraph 核心价值与核心概念
1. 为什么选择 LangGraph?
传统 LLM 应用多为线性调用,无法处理:
- 多步骤任务(如 “先查数据→再分析→最后生成报告”);
- 分支决策(如 “根据用户输入选择调用搜索工具或计算器”);
- 状态持久化(如多轮对话中保留中间结果)。
LangGraph 的核心优势:
- 可视化流程:用 “节点 + 连线” 定义任务流程,逻辑直观;
- 状态管理:统一管理流程中各节点的输入 / 输出数据;
- 持久化与回溯:支持任务状态保存,可中断、可恢复、可追溯;
- 灵活扩展:轻松添加分支、循环、条件判断等复杂逻辑。
2. LangGraph 三大核心概念
| 概念 | 作用 | 类比 |
|---|---|---|
| State(状态) | 流程中传递的所有数据的载体,是节点间数据交互的唯一通道 | 流程图中在各步骤间传递的 “表单 / 数据单” |
| Node(节点) | 处理数据的最小单元,每个节点对应一个具体的任务(如调用 LLM、调用工具) | 流程图中的 “处理框” |
| Edge(边 / 连线) | 定义节点间的执行顺序(如从 A 节点到 B 节点),支持条件分支 | 流程图中的 “箭头连线” |
二、环境准备
1. 安装依赖
pip install langchain langchain-openai langgraph python-dotenv pydantic typing-extensions
2. 配置环境变量(.env 文件)
env
# 阿里云通义千问API密钥(灵积平台获取)
DASHSCOPE_API_KEY=your_dashscope_api_key
三、完整实战代码(含详细注释)
import os
import uuid
from dotenv import load_dotenv
from typing import TypedDict
from langchain.agents import create_agent
from langchain_openai import ChatOpenAI
from pydantic import SecretStr
# LangGraph核心组件
from langgraph.checkpoint.memory import InMemorySaver # 内存级状态持久化
from langgraph.constants import START, END # 流程起始/结束标识
from langgraph.graph import StateGraph # 状态图构建器
from typing_extensions import NotRequired # 可选字段标识
# 1. 加载环境变量并初始化LLM
load_dotenv()
llm = ChatOpenAI(
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1", # 通义千问兼容接口
model="qwen-plus", # 通义千问增强版
api_key=SecretStr(os.environ["DASHSCOPE_API_KEY"]), # 安全存储API密钥
)
# 2. 定义State(流程状态):统一管理节点间传递的数据
class State(TypedDict):
# NotRequired表示该字段非必需(初始状态可无,由节点生成)
author: NotRequired[str] # 存储推荐的作家名称
joke: NotRequired[str] # 存储生成的风格化笑话
# 3. 定义Node(节点):每个节点对应一个具体任务
# 节点1:推荐一位受欢迎的作家
def author_node(state: State) -> State:
# 接收State(当前流程数据),返回更新后的State
prompt = "帮我推荐一位受人们欢迎的作家。只需要给出作家的名字即可。"
# 调用LLM生成结果
author_response = llm.invoke(prompt)
# 更新State:添加author字段
return {"author": author_response.content}
# 节点2:根据作家风格生成100字以内的笑话
def joke_node(state: State) -> State:
# 从State中获取上一节点生成的author字段
author_name = state["author"]
prompt = f"用作家: {author_name} 的风格,写一个100字以内的笑话"
# 调用LLM生成风格化笑话
joke_response = llm.invoke(prompt)
# 更新State:添加joke字段
return {"joke": joke_response.content}
# 4. 构建StateGraph(状态图):定义流程逻辑
# 初始化图,指定State类型为我们自定义的State类
builder = StateGraph(State)
# 步骤1:添加节点到图中(参数:节点名称,节点函数)
builder.add_node("author_node", author_node) # 作家推荐节点
builder.add_node("joke_node", joke_node) # 笑话生成节点
# 步骤2:定义Edge(连线):指定节点执行顺序
builder.add_edge(START, "author_node") # 起始→作家推荐节点
builder.add_edge("author_node", "joke_node") # 作家推荐节点→笑话生成节点
builder.add_edge("joke_node", END) # 笑话生成节点→结束
# 5. 配置状态持久化:用InMemorySaver保存流程状态(内存级,重启后丢失)
checkpointer = InMemorySaver()
# 6. 编译图:生成可执行的LangGraph应用
graph = builder.compile(checkpointer=checkpointer)
# 7. 执行图:触发流程运行
# 配置项:指定thread_id(唯一标识流程实例,用于状态回溯)
config = {
"configurable": {
"thread_id": uuid.uuid4(), # 生成唯一ID
}
}
# 调用graph.invoke()启动流程,初始State为空字典
final_state = graph.invoke({}, config)
# 输出最终状态(包含author和joke字段)
print("=== LangGraph执行结果 ===")
print(f"推荐作家:{final_state['author']}")
print(f"风格化笑话:{final_state['joke']}")
四、核心代码深度解析
1. State(状态)定义:数据传递的核心
class State(TypedDict):
author: NotRequired[str]
joke: NotRequired[str]
- TypedDict:Python 的类型注解工具,用于定义结构化的字典类型,让 State 的字段类型更清晰;
- NotRequired:标记字段为可选,
author由author_node生成,joke由joke_node生成,初始状态无需包含这些字段; - 核心原则:State 是节点间数据交互的唯一载体,节点只能读取 State 中的数据,或返回新的 State 更新数据。
2. Node(节点)开发:任务处理的最小单元
每个节点函数需遵循固定规则:
def 节点函数名(state: State) -> State:
# 1. 读取State中的数据(如state["author"])
# 2. 执行具体任务(调用LLM/工具/计算)
# 3. 返回更新后的State(字典形式)
- 输入:必须接收
state参数(当前流程的全部状态); - 输出:必须返回
State类型的字典(更新流程状态); - 无副作用:节点函数应只处理数据并返回新 State,避免直接修改外部变量(保证流程可追溯)。
3. StateGraph 构建:定义流程逻辑
# 初始化图
builder = StateGraph(State)
# 添加节点
builder.add_node("author_node", author_node)
builder.add_node("joke_node", joke_node)
# 定义连线
builder.add_edge(START, "author_node")
builder.add_edge("author_node", "joke_node")
builder.add_edge("joke_node", END)
- START/END:LangGraph 内置的流程起始 / 结束标识,无需自定义;
- add_node:第一个参数是节点的 “名称”(需唯一),第二个参数是节点函数;
- add_edge:定义节点执行顺序,格式为
add_edge(起始节点, 目标节点)。
4. 状态持久化与流程执行
# 初始化内存级状态存储器
checkpointer = InMemorySaver()
# 编译图(绑定持久化器)
graph = builder.compile(checkpointer=checkpointer)
# 配置流程实例ID
config = {"configurable": {"thread_id": uuid.uuid4()}}
# 执行流程
final_state = graph.invoke({}, config)
- checkpointer:状态持久化器,
InMemorySaver是最简单的实现(仅内存存储),生产环境可使用PostgresSaver(数据库存储); - thread_id:唯一标识一个流程实例,即使流程中断,也可通过该 ID 恢复状态;
- graph.invoke():触发流程执行,第一个参数是初始 State(本例为空字典),第二个参数是配置项。
五、执行效果示例
输出结果:
=== LangGraph执行结果 ===
推荐作家:鲁迅
风格化笑话:孔乙己踱进酒馆,掌柜斜眼:"还欠十九文钱呢!"孔乙己摸出茴香豆:"茴字有四种写法,这豆也有四种吃法,抵了罢。"掌柜撇嘴:"穷酸样!"孔乙己仰头:"窃豆不算偷,读书人,能算偷么?"众酒客哄笑,豆粒滚了一地。
流程执行逻辑:
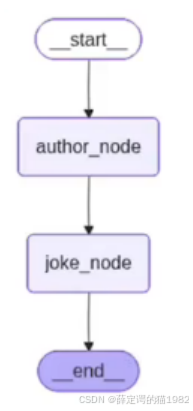

flowchart LR
START --> author_node[推荐作家]
author_node --> joke_node[生成风格化笑话]
joke_node --> END
- 流程从
START开始,调用author_node生成作家名称(如 “鲁迅”),更新 State; author_node执行完成后,通过 Edge 触发joke_node,读取 State 中的作家名称生成笑话;joke_node执行完成后,流程到END结束,返回最终 State(包含作家和笑话)。
六、LangGraph 进阶扩展
1. 条件分支(核心进阶功能)
在实际场景中,常需要根据节点结果选择不同流程(如 “若作家是小说类则生成搞笑故事,若为散文类则生成温馨笑话”):
# 定义条件判断函数
def decide_joke_style(state: State) -> str:
author = state["author"]
# 假设定义小说类作家列表
novel_authors = ["鲁迅", "金庸", "莫言"]
if author in novel_authors:
return "novel_joke_node" # 小说风格笑话节点
else:
return "prose_joke_node" # 散文风格笑话节点
# 添加分支节点
builder.add_node("novel_joke_node", novel_joke_node)
builder.add_node("prose_joke_node", prose_joke_node)
# 替换原有连线,添加条件分支
builder.add_conditional_edges(
"author_node", # 起始节点
decide_joke_style, # 条件判断函数
{
"novel_joke_node": "novel_joke_node", # 判断结果→目标节点
"prose_joke_node": "prose_joke_node"
}
)
# 分支节点最终都指向END
builder.add_edge("novel_joke_node", END)
builder.add_edge("prose_joke_node", END)
2. 循环逻辑
支持流程循环(如 “若笑话生成不满意,重新生成”):
def check_joke(state: State) -> str:
# 简单判断:若笑话长度<50字,重新生成
if len(state["joke"]) < 50:
return "joke_node" # 回到笑话生成节点
else:
return END # 结束流程
# 替换原有连线,添加循环判断
builder.add_conditional_edges("joke_node", check_joke, {"joke_node": "joke_node", END: END})
3. 生产环境优化
- 持久化替换:将
InMemorySaver替换为PostgresSaver或RedisSaver,实现状态持久化; - 日志监控:添加节点执行日志,监控每个节点的耗时和异常;
- 并发控制:通过
thread_id实现多用户流程隔离,避免状态混淆。
七、LangGraph vs 传统线性调用
| 维度 | 传统线性调用 | LangGraph |
|---|---|---|
| 逻辑复杂度 | 仅支持线性流程 | 支持分支、循环、条件判断 |
| 状态管理 | 需手动维护变量 | 内置 State 统一管理 |
| 可回溯性 | 无,执行后无法恢复 | 支持 checkpointer,可回溯任意步骤 |
| 扩展性 | 新增步骤需修改整体代码 | 新增节点 / 连线即可,无需修改原有逻辑 |
总结
- LangGraph 的核心是 “State(状态)+ Node(节点)+ Edge(连线)”,用流程图思维构建 LLM 应用,逻辑直观且可扩展;
- State 是节点间数据传递的唯一载体,需通过 TypedDict 定义结构化字段,保证数据类型清晰;
- 每个 Node 函数遵循 “接收 State→处理任务→返回新 State” 的规则,是任务处理的最小单元;
- LangGraph 支持条件分支、循环等复杂逻辑,远超传统线性调用,是构建复杂 LLM 应用的首选框架。
通过本文的实战案例,你已掌握 LangGraph 的基础开发流程,后续可基于此扩展更复杂的应用(如智能客服流程、数据分析工作流、多工具调用 Agent 等)。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 22
22 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)