一文讲清:什么是多模态?多模态任务与多模态模型如何界定?
《多模态AI的界定标准与核心挑战》 摘要: 本文系统梳理了多模态AI的核心概念与判定标准。严格定义多模态需满足三个条件:1)输入/输出涉及≥2种模态;2)不同模态信息在推理中实质融合;3)融合对任务性能有实质贡献。文章区分了多模态任务(理解/检索/生成/交互)、模型(双塔/编解码/多模态LLM/统一生成)与系统的本质差异,指出多模态模型需在内部表示空间实现联合建模。同时揭示了多模态AI面临的四大核
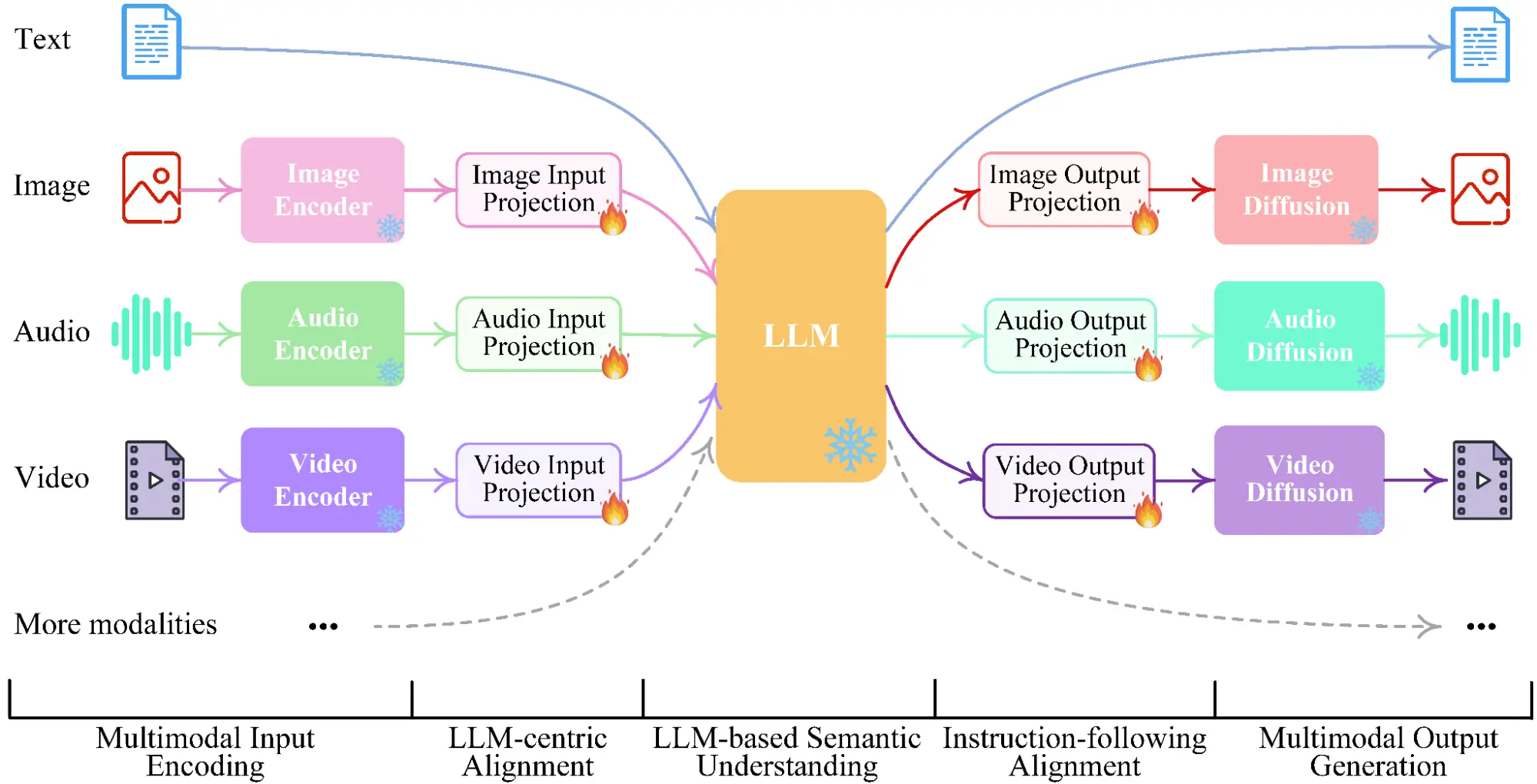
你可能听过“多模态大模型”“多模态任务”“跨模态检索”“图文理解”……但概念经常被混用:
有人把“输入有图片”就叫多模态
有人把“能输出图像”才叫多模态
还有人把“多模态训练方式(CLIP)”和“多模态推理能力(GPT-4V)”混为一谈
这篇文章给出一个清晰的界定标准:从“信息来源(modalities)”出发,区分任务、模型、训练目标与系统能力。
1. 什么是“模态(Modality)”?
模态 = 信息的表现形式 / 通道(channel)。
在 AI 场景里,模态通常指数据的类型与承载形式,例如:
-
语言:文本、token、语音转写
-
视觉:图片、视频、帧序列
-
音频:语音、环境声、音乐
-
结构化数据:表格、知识图谱、数据库 schema
-
时序信号:传感器、IMU、雷达、EEG
-
3D:点云、深度图、mesh
-
交互行为:点击、轨迹、操作序列
关键点:
模态的本质不是“文件格式”,而是信息生成机制不同、统计特性不同、建模方式不同。
2. 什么是“多模态(Multimodal)”?——最严格的界定
严格定义
多模态 = 至少两种模态的信息在一个任务中被共同使用(jointly used)。
“共同使用”意味着:不是简单拼接或旁路,而是对同一目标做协同贡献。
三个必要条件(你可以把它当判定准则)
一个系统/任务/模型想被称为“多模态”,至少满足:
-
输入或输出涉及 ≥2 种模态
-
不同模态的信息在推理过程中发生融合或对齐
-
融合/对齐对任务性能有实质贡献
3. 什么样的是“多模态任务”?——从任务目标而非数据形式判断
多模态任务的定义
多模态任务 = 任务的输入/输出需要跨越不同模态才能完成。
关键是“需要”。
如果把一张图删掉、或把音频静音后任务仍能做得一样好,那这个任务可能不是“本质多模态”。
3.1 多模态任务的典型类型(最常用分类)
A) 多模态理解(Multimodal Understanding)
输入多模态,输出单模态(通常是文本/标签)
-
视觉问答 VQA(图 + 问题 → 答案)
-
图文推理(图 + 文 → 结论)
-
视频理解(视频 + 问题 → 描述)
-
医疗影像 + 病历 → 诊断建议
核心能力:融合、推理、结构化理解
B) 跨模态检索 / 匹配(Cross-modal Retrieval & Matching)
输入一模态,检索另一模态
-
文本检索图片(text → image retrieval)
-
图片检索商品文本描述(image → text)
-
视频-文本检索
-
多模态 ReID(图像 + 属性描述 → 人员检索)
核心能力:对齐到同一个语义空间(alignment)
C) 多模态生成(Multimodal Generation)
输入一模态/多模态,输出另一模态
-
文生图(text → image)
-
图生文(image → caption)
-
文生视频 / 图生视频
-
语音克隆(voice prompt → speech)
-
机器人动作生成(instruction + vision → action sequence)
核心能力:跨模态映射与可控生成
D) 多模态交互与规划(Multimodal Agent / Embodied AI)
多模态输入,输出动作/决策,长期交互
-
机器人:视觉 + 语言指令 → 操作动作
-
UI Agent:屏幕截图 + 文本 → 点击/输入操作
-
自动驾驶:摄像头 + 雷达 + 地图 → 控制决策
核心能力:感知-推理-规划-行动(Perception → Reasoning → Action)
3.2 常见误区:不是“用了图片”就一定是多模态任务
例子 1:把图片当作附件,但模型只看文字做分类
-
输入:图 + 文
-
实际:只用文
这是“多模态数据”,不一定是“多模态任务”。
判断方法:
如果去掉视觉输入性能不变,或模型 attention 基本不落在视觉 token 上,那么任务不是本质多模态。
4. 什么样的是“多模态模型”?——从“建模与能力”两个维度界定
这里是很多人最容易混乱的地方:
多模态模型 ≠ 多模态系统
多模态训练 ≠ 多模态推理能力
多模态模型的基本定义(模型层面)
多模态模型 = 能够对两种及以上模态进行联合建模(joint modeling)的模型。
这包括:
-
处理多模态输入(图 + 文)
-
输出多模态结果(文 + 图)
-
在中间空间中对齐语义(CLIP/ALIGN)
-
将多模态信息融合成统一表征(Flamingo / LLaVA / GPT-4V 等)
4.1 多模态模型的四种典型范式(从结构上看)
范式 1:双塔(Two-tower / Dual Encoder)
代表:CLIP、ALIGN
-
图像 encoder + 文本 encoder
-
学到共享语义空间
-
最适合:检索、匹配
优点:高效、可索引
缺点:推理能力弱、不擅长复杂问答
范式 2:编码器-解码器(Encoder-Decoder)
代表:BLIP、Flan-T5 + Vision Encoder
-
多模态 encoder → 文本 decoder 输出
-
最适合:caption、VQA、OCR理解
优点:生成能力强
缺点:对话/长上下文支持弱(传统结构)
范式 3:多模态 LLM(Vision/Audio Encoder + LLM)
代表:LLaVA、Qwen-VL、GPT-4V、Gemini 等
-
视觉 encoder → 投影到 LLM token space
-
LLM 负责推理与生成
优点:推理强、对话强、可扩展工具调用
缺点:视觉细粒度、空间推理仍可能不稳
范式 4:统一生成模型(Diffusion + LLM / Transformer-based generative)
代表:Imagen、Stable Diffusion、Sora 等(更偏生成)
-
可从文本生成图片/视频
-
或在统一 token 空间生成多模态内容
优点:强生成
缺点:对结构化推理依赖外部模块
4.2 重要区分:多模态模型 vs 多模态系统
很多产品宣传会混淆。
-
多模态系统:多个单模态模型串联(OCR → LLM → TTS)
-
多模态模型:单一模型内部联合建模多个模态(端到端融合)
系统也能很强,但不等价。
判断是否是“多模态模型”的简单规则:
如果模态之间的交互发生在模型内部表示空间中(embedding / attention),则更像多模态模型;
如果模态转换依赖外部工具与串联流程,更像多模态系统。
5. 如何判断“模型真的学会多模态”?
除了看 demo,我们可以用一些更严谨的标准。
5.1 对齐能力(Alignment)
-
图文是否能映射到同一语义空间?
-
支持文本检索图片 / 图片检索文本?
5.2 融合能力(Fusion)
-
多模态信息是否共同决定输出?
-
有无“忽略模态”的塌缩(collapse)?
5.3 组合泛化(Compositionality)
-
能否理解未见组合?例如:
“穿红衣服的蓝色机器人”
这对多模态理解非常关键
5.4 跨模态推理(Cross-modal Reasoning)
-
计数、空间关系、因果、时间顺序(视频)
-
OCR + 推理(发票、图表)
6. 多模态到底难在哪?——本质挑战
6.1 模态间“语义鸿沟”
图片像素 ≠ 文本语义
需要学习映射与对齐。
6.2 信息密度差异
一张图含信息远超过一句话。
如何让 LLM 用有限 token 表达视觉内容?
6.3 时序与空间结构
视频与3D难在结构:
-
空间一致性
-
时间一致性
-
可追踪性(tracking)
-
多视角融合
6.4 数据与标注成本
高质量多模态对齐数据昂贵。
很多模型效果取决于数据配方而非结构创新。
7. 一个“可操作”的结论:如何在工作中界定多模态?
判断一个任务是否多模态:看“信息依赖”
-
是否必须使用多个模态才能完成?
-
去掉某个模态性能是否显著下降?
判断一个模型是否多模态:看“内部联合建模”
-
是否在同一 token/embedding 空间融合?
-
是否可以端到端处理多模态输入?
-
是否存在跨模态 attention?
判断一个系统是否多模态:看“能力维度”
-
是否支持对齐(检索)
-
是否支持融合(理解)
-
是否支持跨模态生成
-
是否支持交互/行动(agent)
结语:
-
多模态(Multimodal):多个模态的信息共同参与任务目标。
-
多模态任务:完成任务必须跨模态理解/对齐/生成。
-
多模态模型:在模型内部联合建模并融合 ≥2 种模态,而不仅是串联工具。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 18
18 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)