对话 John Schulman:如果带着 2025 的记忆回到十年前,OpenAI 能多快造出 ChatGPT?
【摘要】OpenAI联合创始人John Schulman在访谈中指出,若以当前认知重返2015年,无需GPT-4级算力即可快速开发ChatGPT,关键在于"后训练"技术(如SFT和RLHF)和高质量数据工程。其新创公司Thinking Machines推出的Tinker项目,旨在通过标准化"原语"将AI训练流程模块化,终结当前低效的"炼金术&quo
在 AI 领域,John Schulman 是一个无法绕过的名字。作为 OpenAI 的联合创始人,他曾一手主导了 ChatGPT 的强化学习架构。

最近,在一次深度访谈中,John 被问到一个极具启发性的问题:如果让初创时期的 OpenAI 团队带着今天的认知回到 2015 年,你们能用多快的速度造出 ChatGPT?
本文将结合 John Schulman 的最新创业项目 Thinking Machines,深度拆解这场对话中关于“后训练、 “原语”、“自进化”的核心内涵。
这不仅是一场技术回顾,更是对未来 3-5 年 AI 商业竞争壁垒的预判。

多快能造出现在 ChatGPT?认知差才是真正的算力
John 被问到的第一个问题是:如果回到 2015 年,你们能多快造出 ChatGPT?
他的回答出人意料:并不需要 GPT-4 这种规模的算力,甚至不需要 GPT-3 的全量算力。
1. 被低估的“后训练”力量
在 2015-2020 年间,整个行业的重心都在“预训练”上,即不断喂数据、堆参数。
但 John 指出,今天我们已经意识到,“后训练”阶段(包括 SFT 监督微调和 RLHF 强化学习)对模型表现出的“智能感”起到了决定性作用。
认知的错位:过去我们认为,模型必须要足够“大”才能理解指令。
当下的洞察:通过极高质量、精心构造的微调数据集,即便是一个参数量适中的模型,其表现也能在特定任务上超越巨大的原始模型。
如果你拥有今天的“数据配方”,在 2015 年那个算力匮乏的时代,你可以通过更聪明的微调手段,让 GPT-2 级别的模型展现出类似对话代理的能力。
2. 从大力出奇迹到精细化炼金
上面的认知差反映在商业上就是:先发优势并不完全在于你拥有多少块 H100,而在于你是否掌握了让模型高效对齐的特定数据工程方法。


Thinking Machines 的野心:终结 AI 开发的炼金术时代
John 离开 OpenAI 创立了 Thinking Machines,并推出了名为 Tinker 的项目。这背后是他对当前 AI 工业界生产模式的深度反思。
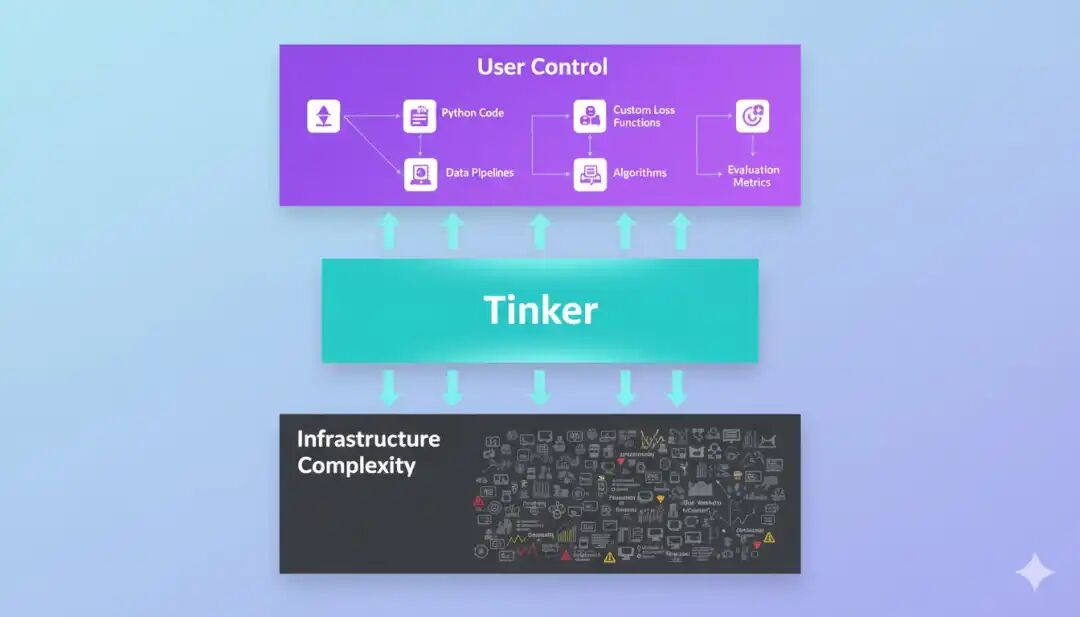
1. 现状:低效且不透明的黑盒训练
目前的 AI 模型训练过程极其类似于中世纪的炼金术:
-
开发者编写冗长的脚本,将各种数据混杂在一起;
-
按下运行键,烧掉几十万美金;
-
等待结果,如果效果不好,由于训练过程的不可解释性,很难精准定位是哪一步出了问题。
2. Tinker 的逻辑:引入低级原语
John 在访谈中多次提到一个词:原语。
在计算机科学中,原语是最基础的运算指令。John 认为,目前的模型训练缺乏这种标准化、可拆解的基础构件。
Tinker 的目标是将复杂的训练流程拆解为一系列透明的、可操纵的原语。包括:
-
工程化转型:开发者不再是祈祷奇迹发生的炼金术师,而是精密仪器的工程师。你可以像调试软件代码一样,精细地调整训练过程中每一个权重的更新逻辑、每一批次数据的分布。
-
全栈式赋能:Tinker 的目标是让非顶级 ML 专家也能根据业务场景,通过组合这些高效的原语,快速构建出高性能的垂直领域模型。
这意味着 AI 的门槛正在从算法研究下移到工程效率。
正如我之前写过的 Reevo,成功的项目往往不是靠模型更聪明,而是靠工程化的交付更标准、更快速。

未来一年的关键词:多模态与自进化的闭环
当谈到未来一年的趋势时,John 给出了非常具体的指引。
1. 强化学习的下半场:从人教到自悟
目前的 RLHF 极度依赖人类的标注。但人类标注有三个致命伤:贵、慢、且人类的认知水平限制了 AI 的上限。
John 预测,未来的突破点在于深度自监督强化学习。
-
AI 将学会自我对弈和自我评估
-
在没有人类实时干预的情况下,模型通过在大规模模拟环境中的探索,发现更高效的逻辑路径
-
这就像 AlphaZero 摆脱人类棋谱一样,未来的通用模型将摆脱人类数据的天花板
2. 真正的多模态:不只是文字的翻译件
目前所谓的多模态(图像进、文字出)在 John 看来仍然是浅层的。下一代的 AI 将具备真正的感官融合能力:
-
它能直接在多模态的原生空间里进行推理
-
它对物理世界的理解将通过视频和传感器数据得到质的提升。

给 2025 年 AI 创业者的三条认知红利
基于 John 的访谈,结合我之前对全球爆款 AI 应用(如 HubX, Talkie 等等)的分析,总结出以下三点实战建议:
1. 规模化的重心转移
缩放定律并没有失效,但其重点正从参数规模转向推理规模和数据精炼规模。
如果你在 2025 年还在盲目追求训练更大的模型,而忽视了如何在推理端通过更复杂的搜索和思维链来提升表现,你将失去核心竞争力。
2. 关注低摩擦的工程工具
John 创立 Thinking Machines 本身就说明了一个趋势:赋能开发者、降低模型调优摩擦的“铲子”公司,其商业价值可能比单纯做模型的公司更稳固。
开发者应该关注那些能让你快速实验、精准反馈的工具,而不是把资源浪费在低效的盲目训练上。
3. 小而美的垂直闭环依然是现金流之王
在访谈中,John 提到即使是 GPT-3 级别的算力,如果加上极致的后训练,也能达到惊人的效果。
这再次验证了我们多次提到的:深入垂直场景,用高质量的私有数据去做极细颗粒度的微调,其投资回报率远高于去卷通用模型。
以上,祝你今天开心。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 17
17 0
0- 0



 已为社区贡献49条内容
已为社区贡献49条内容

所有评论(0)