AI大模型:python舆情分析系统 情感分析 CNN算法 LSTM算法 卷积神经网络网络 可视化 Django框架 Echarts可视化 毕业设计✅
AI大模型:python舆情分析系统 情感分析 CNN算法 LSTM算法 卷积神经网络网络 可视化 Django框架 Echarts可视化 毕业设计✅
·
博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2025年计算机专业毕业设计选题汇总(建议收藏)✅
1、项目介绍
技术栈:python语言、Django框架、Echarts可视化、html
深度学习算法:CNN算法、LSTM算法、对比2种算法的差别
python舆情分析系统 情感分析 CNN算法 LSTM算法 卷积神经网络网络 可视化 毕业设计
2、项目界面
(1)CNN算法 LSTM算法算法比较、可视化分析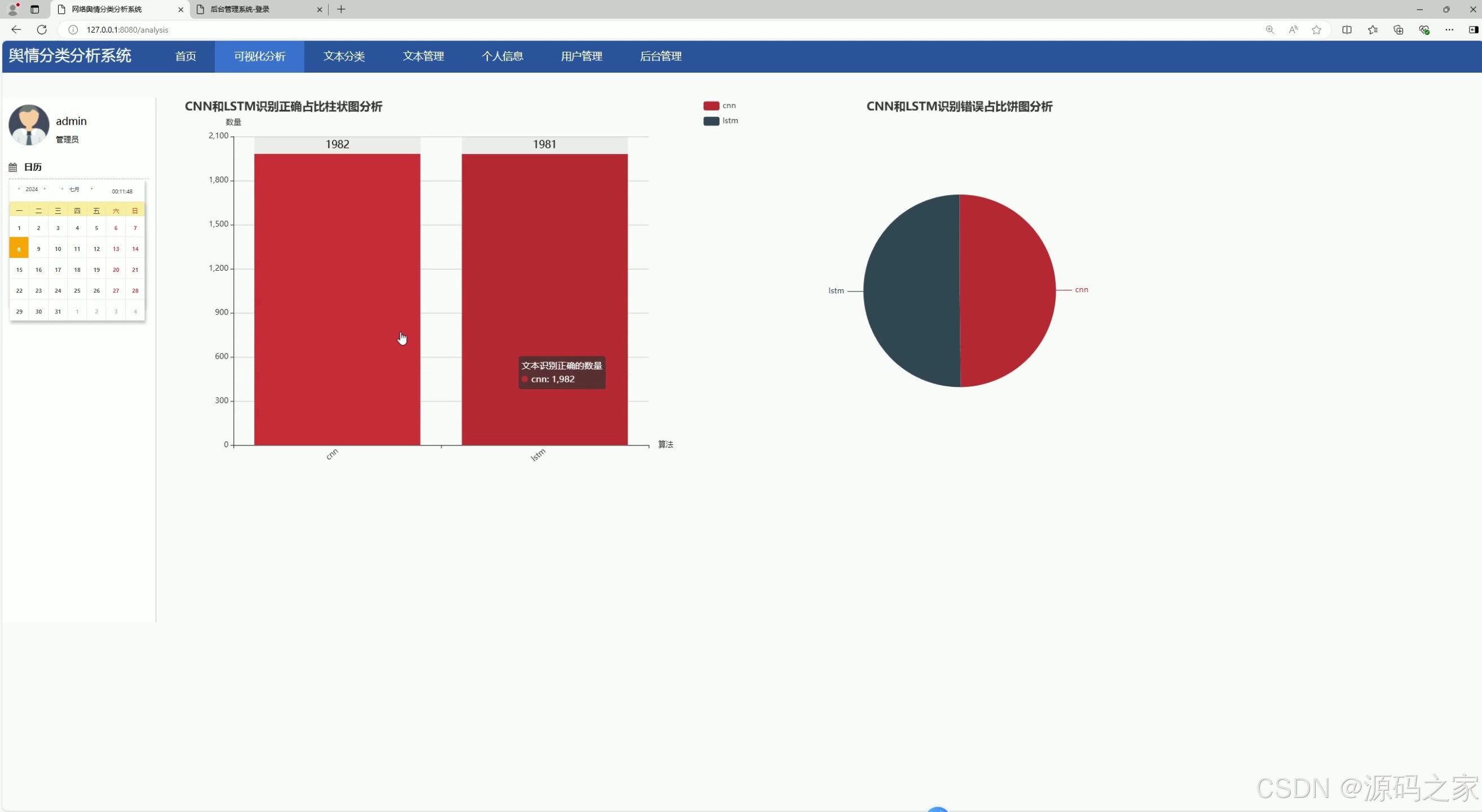
(2)CNN算法 LSTM算法算法比较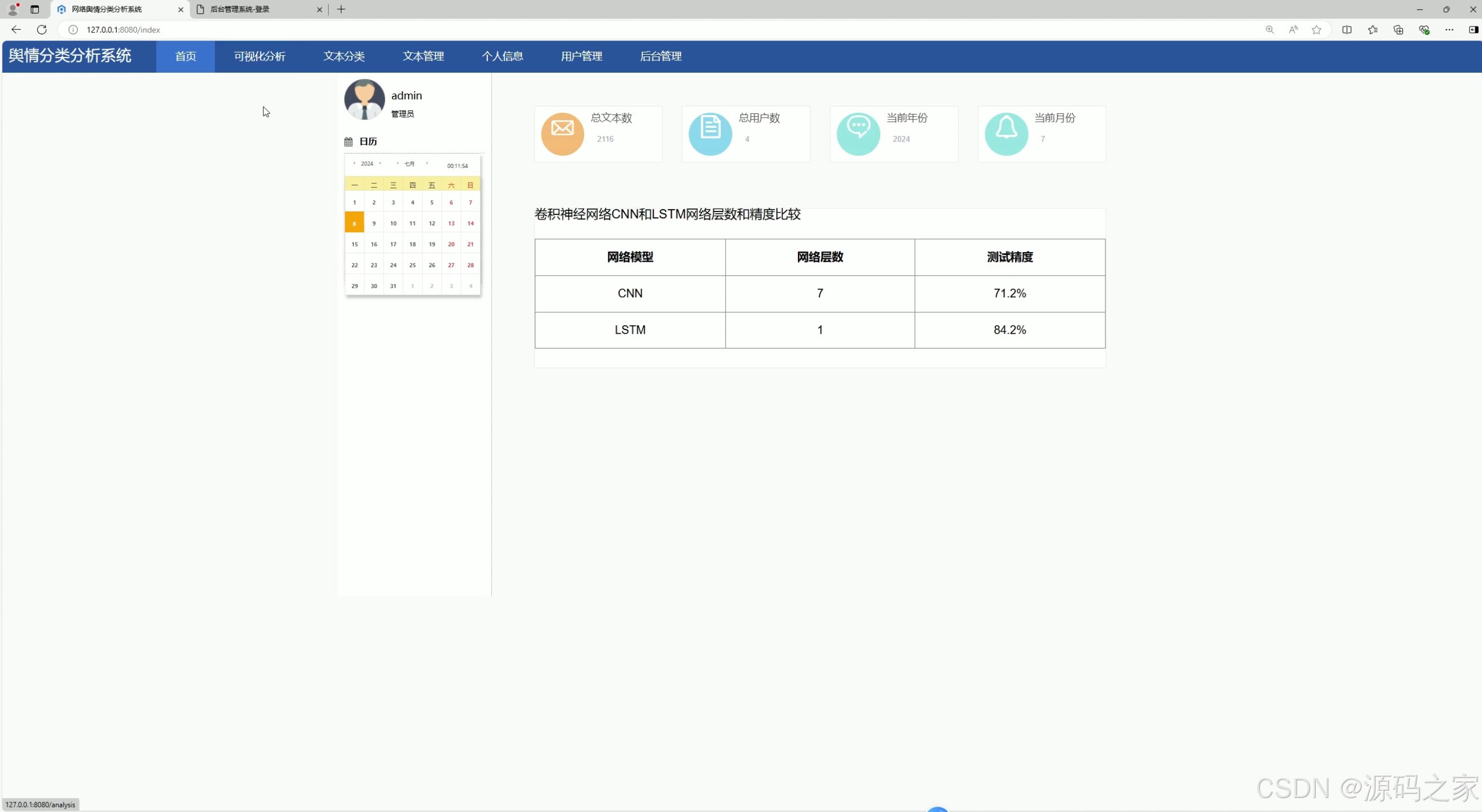
(3)文本管理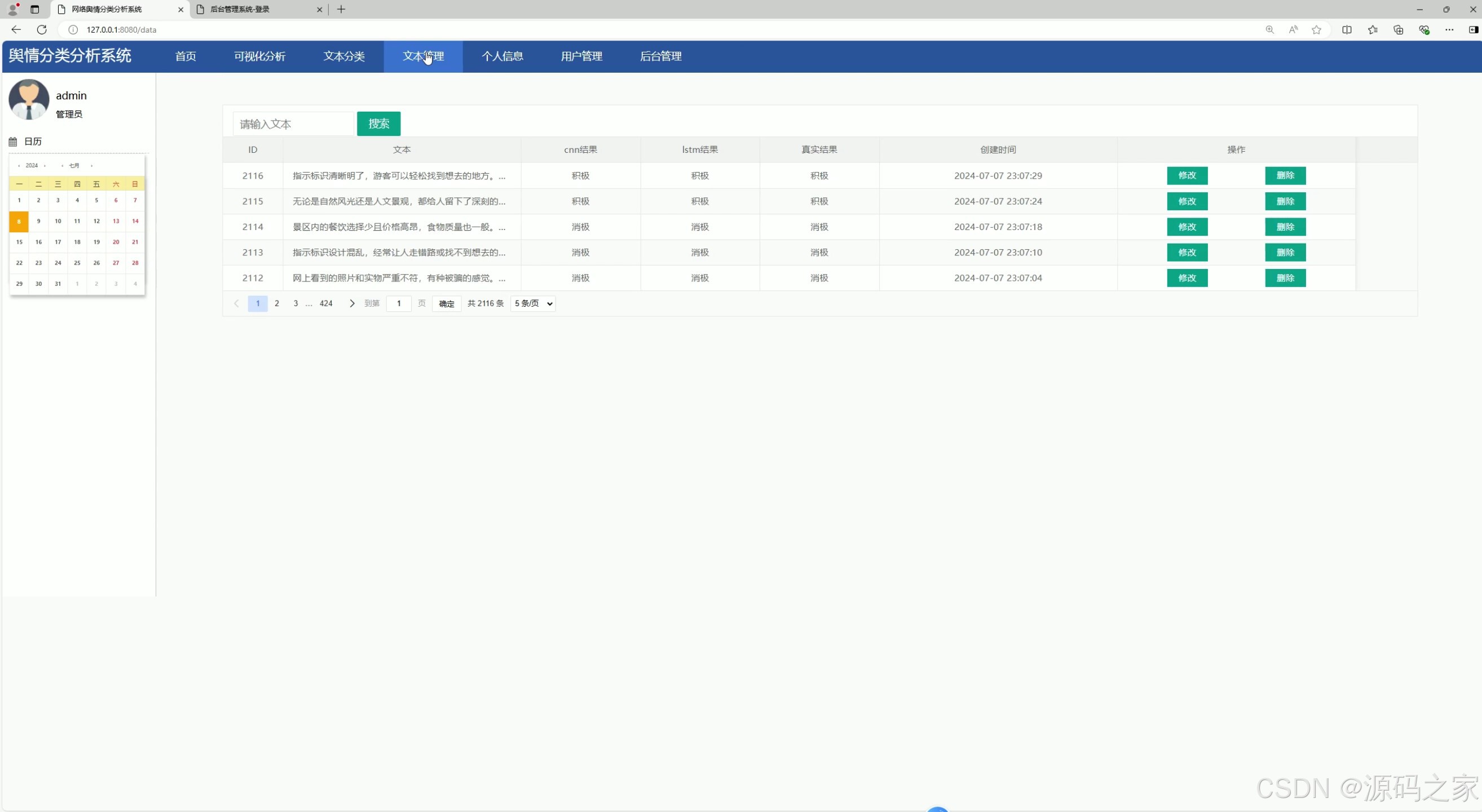
(4)文本分类,显示2种分类结果
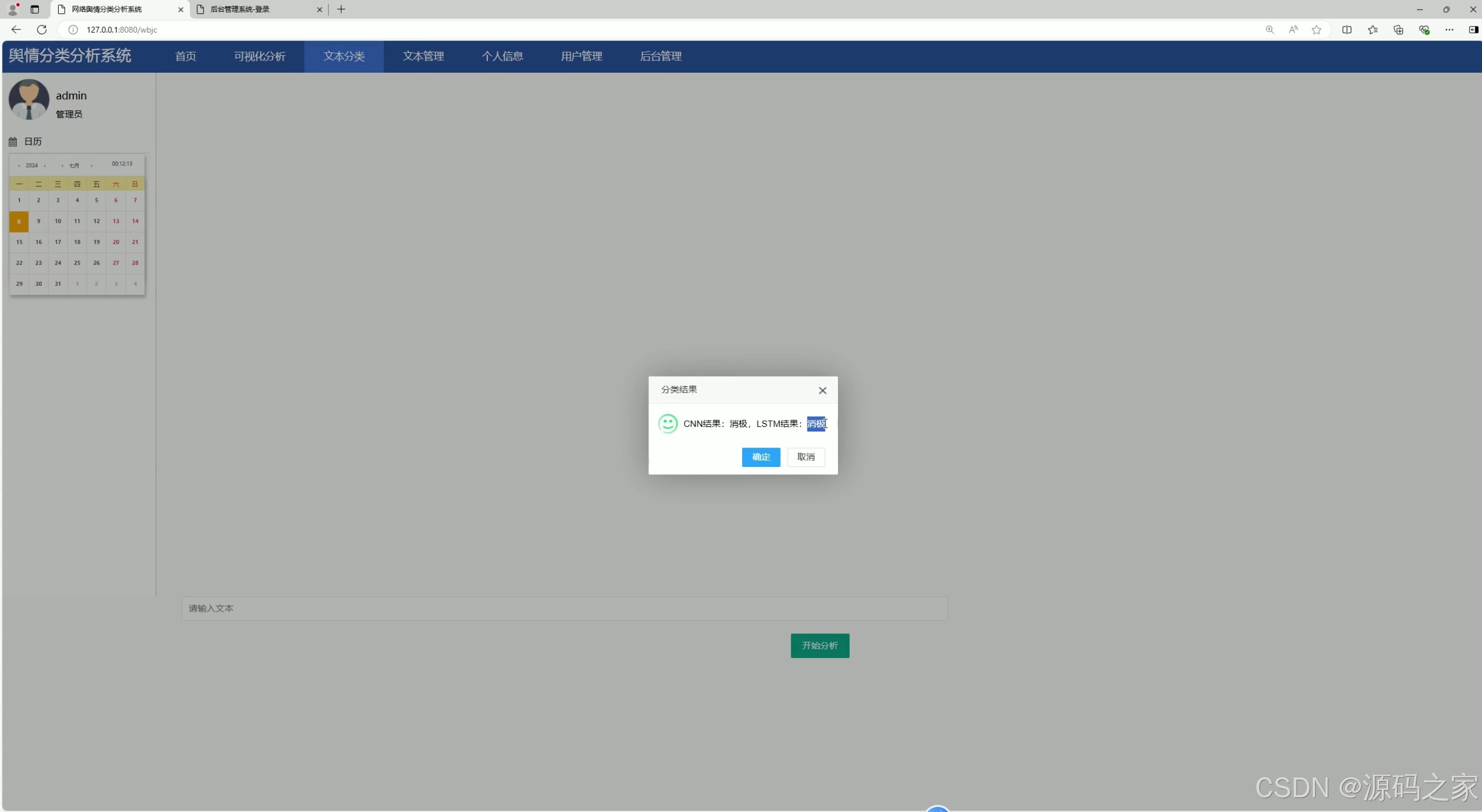
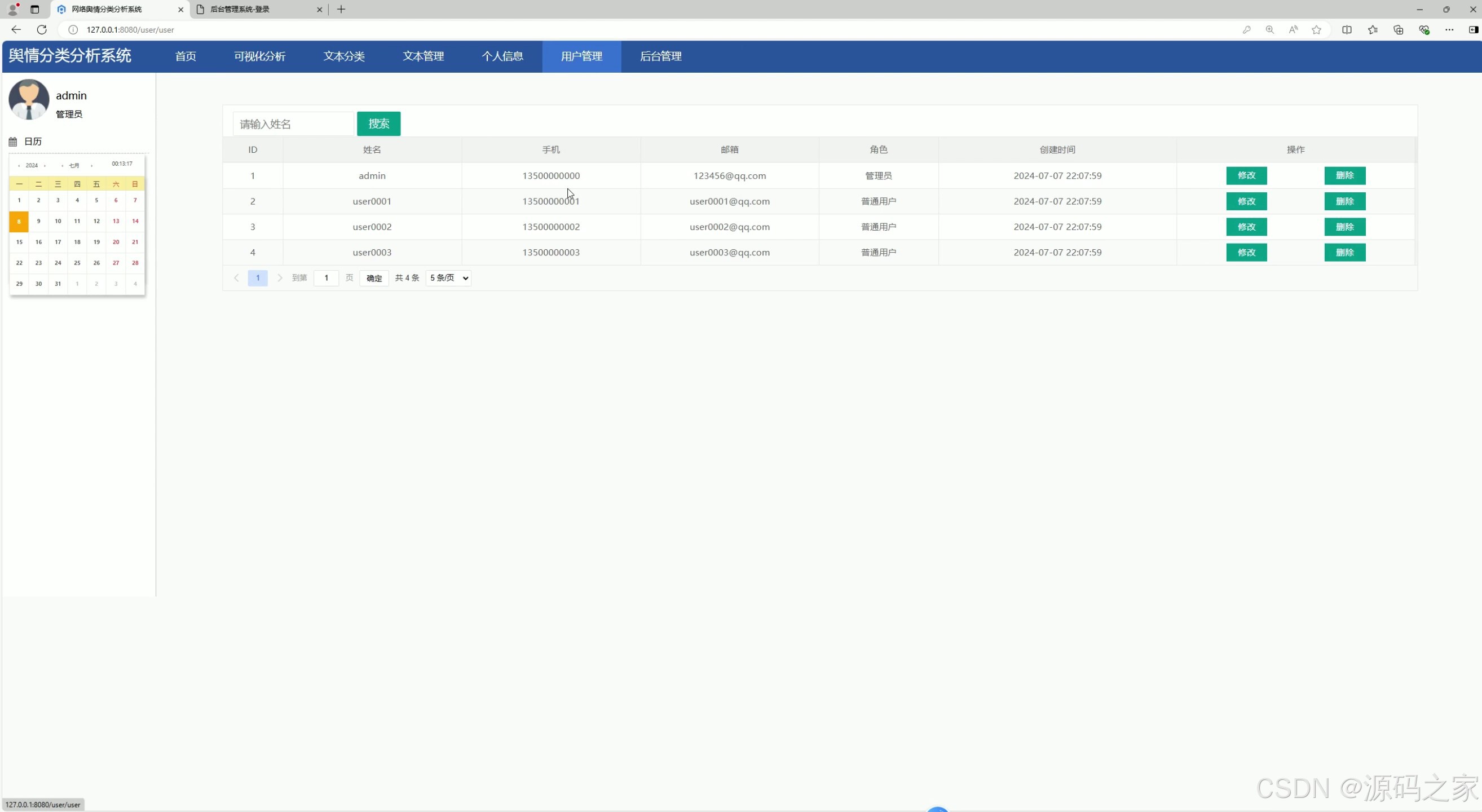
(5)用户管理
(6)后台管理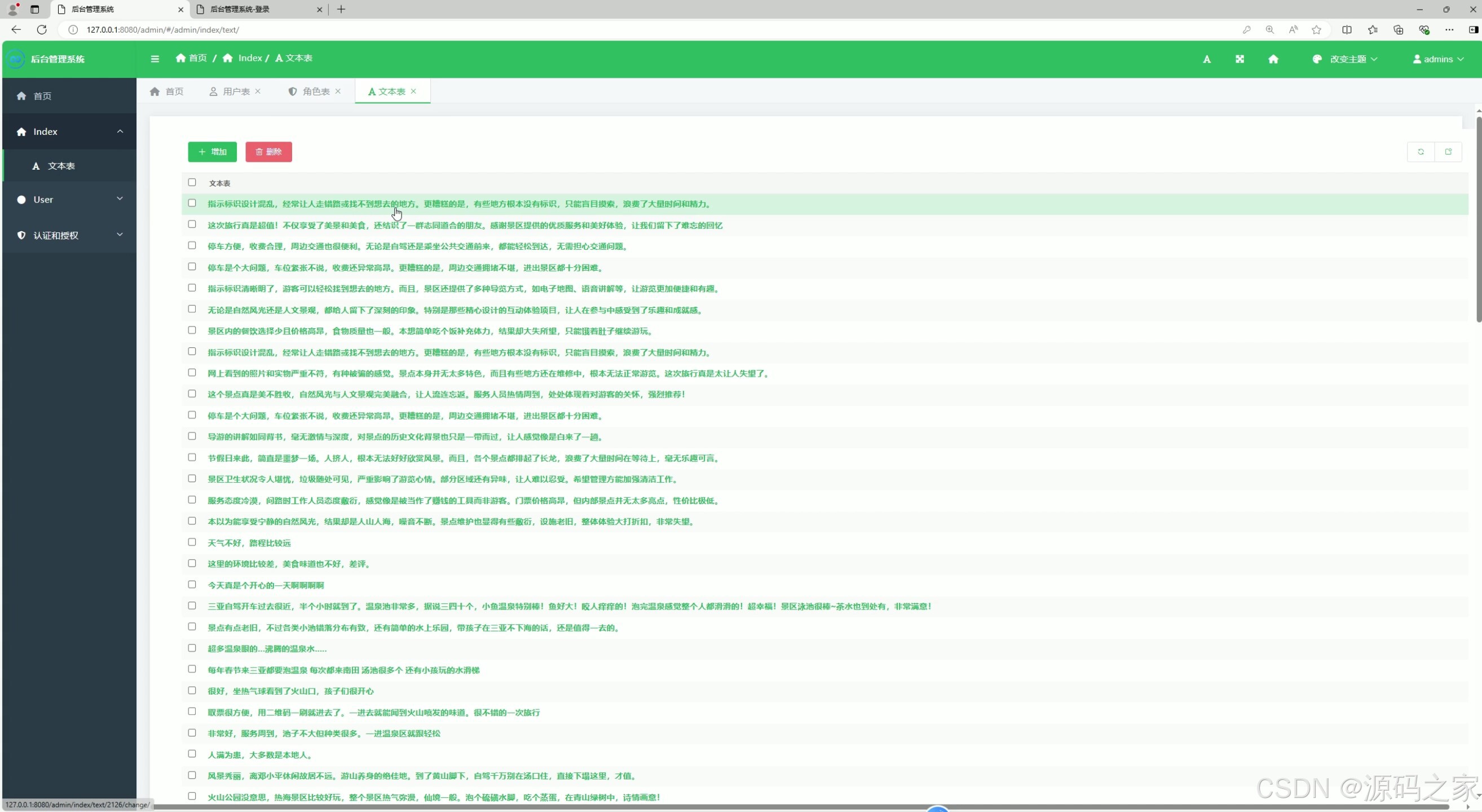
(7)登录
3、项目说明
摘 要:进入二十一世纪以来,计算机技术蓬勃发展,人们的生活发生了许多变化。比如说信息的传播和言论的发表变得越来越快了,当代的网民朋友可以通过网络平台快速的了解当今社会的新闻及动态,除此之外还可以利用各个平台的评论功能发表自己的意见或看法。由此可见,计算机技术对人们生活的改变不仅仅包含衣食住行等方面,它在各种领域都对现代生活作出了贡献。
虽然现在网络很发达,网民们可以通过各种各样的网络平台(比如新浪微博)就一些现象发声,不过作为一名网民,要发表积极且正能量的评论或者微博,对自己的国家或城市要热爱不可以诋毁,网络也会尊重网民们的言论自由,但对一些造谣生事的网民也会有监控。在计算机技术快速发展之前,人们如果想对网络上特定的发言或评论进行查找是非常麻烦的,人们需要查看所有特定用户的微博然后一条一条进行翻看,但这种查找方式首先效率很低,因为一个人的精力是有限的,人们要查看每个用户的微博,而微博的刷新是很快的,可能几分钟的间隔就会产生新的评论或转发。其次此种方式的时效性比较差,微博或微博中的评论信息无法快速及时的刷新。
本系统使用Python语言和MySQL数据库开发,为社会的网络管理部门提供了言论分析、言论管理、用户管理等多种功能,让用户不需要再繁琐的查看每个人的微博帐号就可以进行以自己城市或地区为关键词的言论分析和管理,在保障了网民们的隐私权和言论自由权的同时,可以最大效率地查看和本地有关的舆情或负面评论。
关键词:舆情分析;计算机;Python;数据库
5.1 首页展示
用户在输入正确的系统域名后,即可顺利访问本舆情分析系统。需要注意的是,在完成用户注册之前,访客仅能浏览系统公告、站内新闻等公开信息,无法使用系统的核心功能。本系统首页采用清晰的上中下结构设计,头部区域为导航栏,集中展示系统各主要功能模块的入口;中间部分布局分为左右两侧,左侧清晰呈现当前登录用户的基本信息,同时实时显示当前的日期和天气状况,为用户提供便捷的生活信息参考;右侧则以数据统计的形式,直观展示系统内的总发言数、总用户数等关键运营数据,让用户对系统规模有整体了解。
5.2 登录注册
对于未进行注册的用户,系统会限制其使用所有核心功能。只有用户按照要求填写注册表单,经过系统的一系列严格验证(包括信息完整性、格式正确性等检查),成功注册并拥有属于自己的账号后,才能通过登录操作获取系统的全部功能使用权限,进而体验文本分析、数据管理等专业功能。
5.3 文本分析
用户成功登录系统首页后,通过点击上方导航栏中的“文本分析”选项,即可进入该功能模块。在文本分析界面中,用户不仅可以查阅系统内所有文本的历史输入记录,方便进行数据回溯与对比,还能在专门的文本输入框中录入新的文本信息,提交后系统将运用CNN、LSTM等深度学习算法对文本进行情感分析等处理,具体的操作流程和分析结果会在界面中清晰呈现。
5.4 文本管理
文本管理功能作为本舆情分析系统的核心功能之一,承担着重要的数据管理职责。用户在文本分析过程中输入的各类关键词,以及系统通过算法处理后得出的最终分析结果,都能通过文本管理功能进行全面的查看、整理和管理。用户可以在此模块对文本数据进行筛选、排序、导出等操作,具体的功能界面将按照直观易用的原则进行设计。
5.5 个人信息查看
在系统首页上方的导航栏中,设有“个人信息”的超链接按钮,用户点击该按钮后,将跳转至个人信息页面。在这个界面中,用户能够清晰查看到当前登录账户的详细信息,包括账户ID、姓名、联系方式、注册时间以及最后登录时间等内容,方便用户了解和管理自己的账户状态。具体的界面布局将以简洁明了的方式展示这些信息。
5.6 对比分析模块
本系统的数据分析功能基于CNN(卷积神经网络)和LSTM两种深度学习算法实现。在对比分析模块中,用户可以通过系统生成的柱状图、饼图等可视化图表,直观地对比两种算法在情感分析等任务中的表现差异,包括分析准确率、处理效率等关键指标。用户通过该模块能够清晰了解不同算法的优劣,具体的操作界面将提供图表切换、数据筛选等功能,提升分析体验。
5.7 注册用户管理模块
管理员登录系统后台后,可通过注册用户管理模块对平台所有用户的信息进行全面查看与管理。在此模块中,管理员能够查阅用户的账号、加密存储的密码以及其他基本个人信息,还可以根据实际需求为不同用户设置相应的操作权限。当用户不具备相关权限时,将无法进行言论管理等特定操作。此外,若用户存在违反网站规定的行为,管理员有权对该用户账号进行删除处理。
注册用户管理模块包含两大核心功能:其一为用户创建功能,管理员在输入用户姓名、密码、手机号等必要信息并验证通过后,即可完成新用户的添加操作;其二为用户信息维护功能,新添加的用户信息会在数据列表中展示,管理员可通过列表上方的搜索栏,输入用户姓名快速查询指定用户的数据信息。当用户信息发生变更(如更换手机号)时,管理员可点击列表最右侧的“修改”按钮,对用户数据进行及时更新。该模块的操作界面将采用表格形式清晰展示用户信息,并配备便捷的操作按钮。
4、核心代码
import sys
import json
import logging
import functools
import numpy as np
import tensorflow as tf
from pathlib import Path
DATA_DIR = '../../data/hotel_comment'
# Logging
Path('results').mkdir(exist_ok=True)
tf.logging.set_verbosity(logging.INFO)
handlers = [
logging.FileHandler('results/main.log'),
logging.StreamHandler(sys.stdout)
]
logging.getLogger('tensorflow').handlers = handlers
# Input function
def parse_fn(line_words, line_tag):
# Encode in Bytes for TF
words = [w.encode() for w in line_words.strip().split()]
tag = line_tag.strip().encode()
return (words, len(words)), tag
def generator_fn(words, tags):
with Path(words).open('r', encoding='utf-8') as f_words, Path(tags).open('r', encoding='utf-8') as f_tags:
for line_words, line_tag in zip(f_words, f_tags):
yield parse_fn(line_words, line_tag)
def input_fn(words_path, tags_path, params=None, shuffle_and_repeat=False):
params = params if params is not None else {}
shapes = (([None], ()), ()) # shape of every sample
types = ((tf.string, tf.int32), tf.string)
defaults = (('<pad>', 0), '')
dataset = tf.data.Dataset.from_generator(
functools.partial(generator_fn, words_path, tags_path),
output_shapes=shapes, output_types=types)
if shuffle_and_repeat:
dataset = dataset.shuffle(params['buffer']).repeat(params['epochs'])
dataset = (dataset
.padded_batch(params.get('batch_size', 20), shapes, defaults)
.prefetch(1))
return dataset
def model_fn(features, labels, mode, params):
if isinstance(features, dict):
features = features['words'], features['nwords']
# Read vocabs and inputs
dropout = params['dropout']
words, nwords = features
training = (mode == tf.estimator.ModeKeys.TRAIN)
vocab_words = tf.contrib.lookup.index_table_from_file(
params['words'], num_oov_buckets=params['num_oov_buckets'])
with Path(params['tags']).open(encoding='utf-8') as f:
indices = [idx for idx, tag in enumerate(f)]
num_tags = len(indices)
# Word Embeddings
word_ids = vocab_words.lookup(words)
w2v = np.load(params['w2v'])['embeddings']
w2v_var = np.vstack([w2v, [[0.] * params['dim']]])
w2v_var = tf.Variable(w2v_var, dtype=tf.float32, trainable=False)
embeddings = tf.nn.embedding_lookup(w2v_var, word_ids)
embeddings = tf.layers.dropout(embeddings, rate=dropout, training=training)
# LSTM
t = tf.transpose(embeddings, perm=[1, 0, 2])
lstm_cell_fw = tf.contrib.rnn.LSTMBlockFusedCell(params['lstm_size'])
lstm_cell_bw = tf.contrib.rnn.LSTMBlockFusedCell(params['lstm_size'])
lstm_cell_bw = tf.contrib.rnn.TimeReversedFusedRNN(lstm_cell_bw)
_, (cf, hf) = lstm_cell_fw(t, dtype=tf.float32, sequence_length=nwords)
_, (cb, hb) = lstm_cell_bw(t, dtype=tf.float32, sequence_length=nwords)
output = tf.concat([hf, hb], axis=-1)
output = tf.layers.dropout(output, rate=dropout, training=training)
# FC
logits = tf.layers.dense(output, num_tags)
pred_ids = tf.argmax(input=logits, axis=1)
if mode == tf.estimator.ModeKeys.PREDICT:
reversed_tags = tf.contrib.lookup.index_to_string_table_from_file(params['tags'])
pred_labels = reversed_tags.lookup(tf.argmax(input=logits, axis=1))
predictions = {
'classes_id': pred_ids,
'labels': pred_labels
}
return tf.estimator.EstimatorSpec(mode, predictions=predictions)
else:
# LOSS
tags_table = tf.contrib.lookup.index_table_from_file(params['tags'])
tags = tags_table.lookup(labels)
loss = tf.losses.sparse_softmax_cross_entropy(labels=tags, logits=logits)
# Metrics
metrics = {
'acc': tf.metrics.accuracy(tags, pred_ids),
'precision': tf.metrics.precision(tags, pred_ids),
'recall': tf.metrics.recall(tags, pred_ids)
}
for metric_name, op in metrics.items():
tf.summary.scalar(metric_name, op[1])
if mode == tf.estimator.ModeKeys.TRAIN:
train_op = tf.train.AdamOptimizer().minimize(
loss, global_step=tf.train.get_or_create_global_step())
return tf.estimator.EstimatorSpec(mode, loss=loss, train_op=train_op)
elif mode == tf.estimator.ModeKeys.EVAL:
return tf.estimator.EstimatorSpec(
mode, loss=loss, eval_metric_ops=metrics)
if __name__ == '__main__':
params = {
'dim': 300,
'lstm_size': 32,
'dropout': 0.5,
'num_oov_buckets': 1,
'epochs': 25,
'batch_size': 20,
'buffer': 3500,
'words': str(Path(DATA_DIR, 'vocab.words.txt')),
'tags': str(Path(DATA_DIR, 'vocab.labels.txt')),
'w2v': str(Path(DATA_DIR, 'w2v.npz'))
}
with Path('results/params.json').open('w', encoding='utf-8') as f:
json.dump(params, f, indent=4, sort_keys=True)
def fwords(name):
return str(Path(DATA_DIR, '{}.words.txt'.format(name)))
def ftags(name):
return str(Path(DATA_DIR, '{}.labels.txt'.format(name)))
train_inpf = functools.partial(input_fn, fwords('train'), ftags('train'),
params, shuffle_and_repeat=True)
eval_inpf = functools.partial(input_fn, fwords('eval'), ftags('eval'))
cfg = tf.estimator.RunConfig(save_checkpoints_secs=60)
estimator = tf.estimator.Estimator(model_fn, 'results/model', cfg, params)
Path(estimator.eval_dir()).mkdir(parents=True, exist_ok=True)
train_spec = tf.estimator.TrainSpec(input_fn=train_inpf)
eval_spec = tf.estimator.EvalSpec(input_fn=eval_inpf, throttle_secs=60)
tf.estimator.train_and_evaluate(estimator, train_spec, eval_spec)
# Write predictions to file
def write_predictions(name):
Path('results/score').mkdir(parents=True, exist_ok=True)
with Path('results/score/{}.preds.txt'.format(name)).open('wb', encoding='utf-8') as f:
test_inpf = functools.partial(input_fn, fwords(name), ftags(name))
golds_gen = generator_fn(fwords(name), ftags(name))
preds_gen = estimator.predict(test_inpf)
for golds, preds in zip(golds_gen, preds_gen):
((words, _), tag) = golds
f.write(b' '.join([tag, preds['labels'], ''.join(words)]) + b'\n')
for name in ['train', 'eval']:
write_predictions(name)
5、项目获取
(绿色聊天软件)yuanmazhiwu 或 biyesheji0005

🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看我的【用户名】、【专栏名称】、【顶部选题链接】就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看👇🏻获取联系方式👇🏻

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 19
19 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)