多智能体协同算法的智能电网分布式调度【附代码】
✨ 本团队擅长数据搜集与处理、建模仿真、程序设计、仿真代码、论文写作与指导,毕业论文、期刊论文经验交流。✅ 专业定制毕设、代码✅ 成品或定制,查看文章底部微信二维码。
(1)分布式模式搜索算法求解非凸负荷分配问题
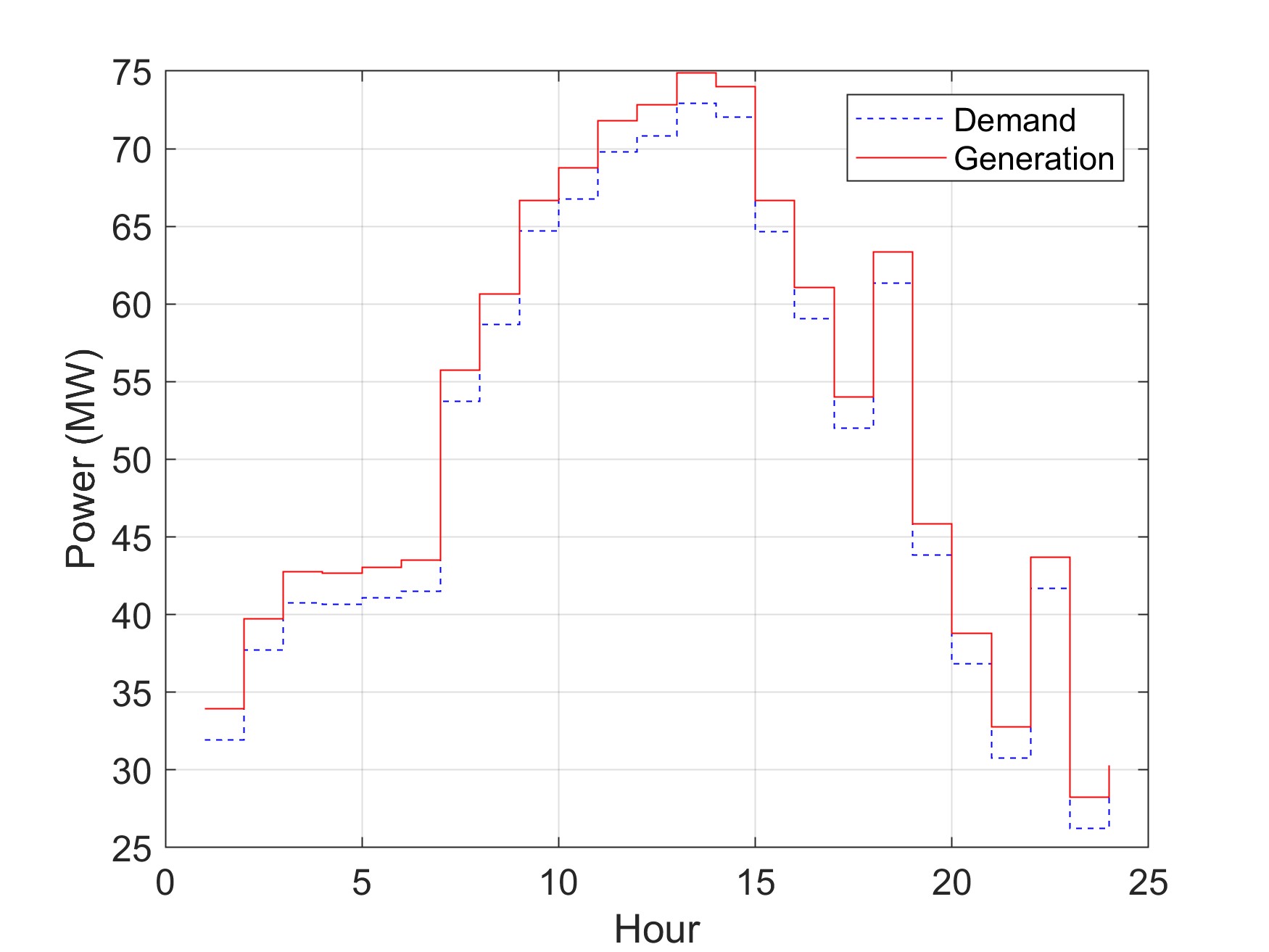
智能电网中的负荷分配问题旨在将总负荷需求合理分配给各发电机组,使得系统总发电成本最小化的同时满足各种运行约束。传统的负荷分配方法通常假设发电机组的成本函数为光滑凸函数,然而实际的发电成本曲线往往呈现非凸特性,如阀点效应会导致成本函数出现不可微点,某些机组的启停成本也会引入离散跳跃。此外,由于发电机组老化、环境变化等因素,精确的成本函数模型往往难以获取,传统的基于梯度的优化方法在这些情况下将面临严重困难。本研究针对成本函数非凸且模型不精确的情况,将负荷分配问题建模为无导数优化问题,并设计了一种基于多智能体协同的分布式模式搜索算法进行求解。
分布式调度架构是实现智能电网灵活高效运行的关键技术路线,与集中式调度相比,分布式调度具有通信开销小、隐私保护好、可扩展性强等优势。本研究构建了一个由多个智能体组成的调度系统,每个智能体对应一台发电机组,负责收集本地信息并执行局部决策。智能体之间通过通信网络交换必要的协调信息,共同完成全局优化任务。为了使算法能够自适应地识别网络拓扑结构,本研究还设计了一种分布式拓扑发现算法,各智能体通过有限次信息交互即可获取与自身直接相连的邻居节点列表,进而构建局部通信图。
模式搜索算法是一类不需要目标函数梯度信息的直接搜索方法,通过在当前解的邻域内按照特定模式进行试探性搜索来寻找下降方向。本研究在模式搜索算法的基础上进行分布式化改造,利用通信网络的拉普拉斯矩阵构造正张成矩阵作为搜索方向集。正张成矩阵的性质保证了搜索方向集能够覆盖整个解空间,从而确保算法的全局收敛性。在算法迭代过程中,每个智能体首先计算本地的搜索方向,然后与邻居节点交换中间变量以实现信息融合,最后根据综合信息更新本地决策变量。这种分布式计算架构使得算法的计算负担均匀分散到各智能体,避免了集中式计算的通信瓶颈和单点故障风险。
收敛性分析是验证算法有效性的重要理论基础,本研究基于李雅普诺夫稳定性理论证明了所提分布式模式搜索算法的收敛性。通过构造适当的李雅普诺夫函数,证明了在满足一定条件下,所有智能体的决策变量将收敛到全局最优解的邻域内,且邻域半径与网格细化参数成正比。仿真实验在多个标准测试系统上验证了算法的有效性,结果表明所提算法能够在非凸成本函数和模型不确定条件下获得满意的负荷分配方案。
(2)分布式强化学习算法求解机组组合与负荷分配联合调度问题
机组组合问题关注的是在给定的调度周期内决定各发电机组的启停状态,使得在满足负荷需求和各种约束的前提下总运行成本最小。机组组合问题与负荷分配问题相互耦合,启停状态的改变会影响可调机组集合进而影响负荷分配结果,而负荷分配的经济性又会反过来影响机组组合决策。本研究将机组组合和负荷分配整合为统一的调度优化框架,并采用分布式强化学习算法进行求解,以应对成本函数非凸和模型不精确带来的挑战。
强化学习是一种通过与环境交互来学习最优策略的机器学习方法,特别适合处理模型未知或难以精确建模的序贯决策问题。本研究首先将调度问题形式化为马尔可夫决策过程,状态空间包括当前时段的负荷需求和各机组的运行状态,动作空间包括各机组的启停决策和出力设定值,奖励函数定义为负的运行成本。在离散化假设下,将连续的出力空间划分为有限个离散等级,从而将原问题转化为有限状态和动作的马尔可夫决策过程。基于Q学习框架,本研究设计了集中式强化学习调度算法,通过不断与电网环境交互更新动作值函数,最终学习到近似最优的调度策略。
为了消除集中式算法对全局信息的依赖,本研究进一步发展了分布式强化学习调度算法。核心思想是将全局动作值函数分解为多个局部动作值函数的组合,每个局部函数仅依赖于本地智能体及其邻居的状态和动作。这种分解结构使得各智能体只需与邻居进行局部信息交换即可完成学习和决策,无需中央协调者的参与。在学习过程中,各智能体采用协同探索策略平衡全局探索和局部利用,通过共享探索经验加速学习收敛。此外,本研究还建立了局部动作值函数的更新规则,证明了在适当的学习率递减条件下,分布式学习过程几乎必然收敛到全局最优策略。
强化学习方法的一个重要优势在于能够利用历史数据和在线交互不断改进调度策略。即使初始的成本函数模型存在较大误差,算法也能通过持续学习逐步修正策略,适应真实的系统特性。仿真实验在含有非凸成本函数和阀点效应的测试系统上验证了算法性能,结果表明分布式强化学习算法能够在不依赖精确模型的情况下学习到高质量的调度策略,且学习效率随着智能体数量的增加保持稳定。
(3)基于交替方向乘子法的多微电网协同最优潮流调度
随着分布式发电和微电网技术的快速发展,现代电力系统呈现出多微电网互联的新格局。各微电网作为相对独立的供用电单元,既可以自主运行也可以通过公共耦合点与外部电网进行能量交换。多微电网的协同调度需要在尊重各微电网自主权的前提下实现整体效益最大化,这对调度算法的分布式特性提出了更高要求。本研究建立了耦合微电网的协同最优潮流模型,并基于交替方向乘子法设计了完全分布式的协同调度算法。
在单个微电网层面,本研究建立了包含分布式发电、储能系统、可调负荷和需求响应等多种资源的详细运行模型。分布式发电模型涵盖光伏发电和风力发电的出力特性及其不确定性描述,储能系统模型考虑充放电效率、容量约束和循环寿命影响,需求响应模型描述了可削减负荷和可转移负荷的响应特性。优化目标综合考虑发电成本、购电成本、碳排放成本以及用户舒适度损失,形成多目标优化框架。约束条件包括功率平衡约束、节点电压约束、支路潮流约束以及设备运行约束等。
在多微电网层面,各微电网通过公共耦合点相连,耦合变量包括交换功率和边界节点电压。本研究将全局优化问题在微电网边界处进行分解,形成若干个仅涉及局部变量的子问题,子问题之间通过耦合约束的拉格朗日乘子进行协调。交替方向乘子法的迭代过程分为两个交替进行的阶段:在第一阶段,各微电网并行求解各自的局部优化子问题,更新本地决策变量;在第二阶段,相邻微电网交换边界变量信息,更新对偶变量以实现耦合约束的协调。这种分解协调结构使得算法在微电网层面实现完全分布式,每个微电网只需与物理相邻的微电网进行通信,无需中央协调者和全局通信。
import numpy as np
from scipy.optimize import minimize
class DistributedAgent:
def __init__(self, agent_id, neighbors, cost_func, capacity):
self.id = agent_id
self.neighbors = neighbors
self.cost_func = cost_func
self.capacity = capacity
self.power = 0.0
self.dual_var = 0.0
def local_cost(self, power):
if power < 0 or power > self.capacity:
return 1e10
return self.cost_func(power)
def update_power(self, price, rho=0.1):
def augmented_cost(p):
return self.local_cost(p[0]) + price * p[0]
result = minimize(augmented_cost, [self.power], bounds=[(0, self.capacity)])
self.power = result.x[0]
return self.power
def distributed_pattern_search(agents, total_demand, max_iter=100, tol=1e-4):
n_agents = len(agents)
step_size = 10.0
price = 0.0
for iteration in range(max_iter):
powers = np.array([agent.update_power(price) for agent in agents])
total_power = np.sum(powers)
mismatch = total_power - total_demand
if abs(mismatch) < tol:
break
price += 0.01 * mismatch
step_size *= 0.95
return powers, price
class MicrogridAgent:
def __init__(self, mg_id, n_gens, n_loads, neighbors):
self.id = mg_id
self.n_gens = n_gens
self.n_loads = n_loads
self.neighbors = neighbors
self.gen_power = np.zeros(n_gens)
self.load_power = np.zeros(n_loads)
self.exchange_power = 0.0
self.dual_exchange = {n: 0.0 for n in neighbors}
def local_optimization(self, exchange_targets, rho=1.0):
def objective(x):
gen_p = x[:self.n_gens]
load_p = x[self.n_gens:self.n_gens+self.n_loads]
exchange = x[-1]
gen_cost = np.sum(0.01 * gen_p ** 2 + 2.0 * gen_p)
load_utility = np.sum(5.0 * load_p - 0.02 * load_p ** 2)
penalty = 0.0
for n, target in exchange_targets.items():
penalty += rho / 2 * (exchange - target) ** 2
penalty += self.dual_exchange[n] * (exchange - target)
return gen_cost - load_utility + penalty
x0 = np.concatenate([self.gen_power, self.load_power, [self.exchange_power]])
bounds = [(0, 100)] * self.n_gens + [(0, 50)] * self.n_loads + [(-100, 100)]
result = minimize(objective, x0, bounds=bounds, method='SLSQP')
self.gen_power = result.x[:self.n_gens]
self.load_power = result.x[self.n_gens:self.n_gens+self.n_loads]
self.exchange_power = result.x[-1]
return result.fun
def update_dual(self, neighbor_exchanges, rho=1.0):
for n in self.neighbors:
self.dual_exchange[n] += rho * (self.exchange_power - neighbor_exchanges.get(n, 0))
def admm_microgrid_coordination(microgrids, max_iter=50, rho=1.0, tol=1e-3):
for iteration in range(max_iter):
exchange_targets = {}
for mg in microgrids:
for n in mg.neighbors:
partner = next((m for m in microgrids if m.id == n), None)
if partner:
exchange_targets[(mg.id, n)] = -partner.exchange_power
for mg in microgrids:
targets = {n: exchange_targets.get((mg.id, n), 0) for n in mg.neighbors}
mg.local_optimization(targets, rho)
neighbor_exchanges = {}
for mg in microgrids:
for n in mg.neighbors:
partner = next((m for m in microgrids if m.id == n), None)
if partner:
neighbor_exchanges[n] = -partner.exchange_power
mg.update_dual(neighbor_exchanges, rho)
max_residual = 0
for mg in microgrids:
for n in mg.neighbors:
partner = next((m for m in microgrids if m.id == n), None)
if partner:
residual = abs(mg.exchange_power + partner.exchange_power)
max_residual = max(max_residual, residual)
if max_residual < tol:
break
return [(mg.id, mg.gen_power, mg.exchange_power) for mg in microgrids]
class QLearningAgent:
def __init__(self, n_states, n_actions, alpha=0.1, gamma=0.95, epsilon=0.1):
self.q_table = np.zeros((n_states, n_actions))
self.alpha = alpha
self.gamma = gamma
self.epsilon = epsilon
def choose_action(self, state):
if np.random.rand() < self.epsilon:
return np.random.randint(self.q_table.shape[1])
return np.argmax(self.q_table[state])
def update(self, state, action, reward, next_state):
best_next = np.max(self.q_table[next_state])
td_target = reward + self.gamma * best_next
self.q_table[state, action] += self.alpha * (td_target - self.q_table[state, action])
def distributed_rl_dispatch(n_units, n_states, n_actions, episodes=500):
agents = [QLearningAgent(n_states, n_actions) for _ in range(n_units)]
for episode in range(episodes):
states = [np.random.randint(n_states) for _ in range(n_units)]
for t in range(24):
actions = [agent.choose_action(states[i]) for i, agent in enumerate(agents)]
total_power = sum(actions) * 10
demand = 50 + 30 * np.sin(2 * np.pi * t / 24)
mismatch_penalty = abs(total_power - demand)
for i, agent in enumerate(agents):
cost = 0.01 * (actions[i] * 10) ** 2 + 2 * actions[i] * 10
reward = -cost - mismatch_penalty / n_units
next_state = np.random.randint(n_states)
agent.update(states[i], actions[i], reward, next_state)
states[i] = next_state
for agent in agents:
agent.epsilon = max(0.01, agent.epsilon * 0.99)
return agents
if __name__ == "__main__":
cost_functions = [lambda p, a=a: a * p ** 2 + 10 * p for a in [0.01, 0.02, 0.015, 0.025]]
capacities = [100, 80, 120, 90]
agents = [DistributedAgent(i, [(i-1)%4, (i+1)%4], cost_functions[i], capacities[i])
for i in range(4)]
powers, price = distributed_pattern_search(agents, 250)
print(f"Load allocation: {powers}")
print(f"Marginal price: {price:.4f}")
microgrids = [MicrogridAgent(0, 3, 2, [1]), MicrogridAgent(1, 2, 3, [0, 2]),
MicrogridAgent(2, 3, 2, [1])]
results = admm_microgrid_coordination(microgrids)
for mg_id, gen_p, exch in results:
print(f"Microgrid {mg_id}: Generation={gen_p}, Exchange={exch:.2f}")
rl_agents = distributed_rl_dispatch(4, 10, 10, episodes=200)
print("RL training completed")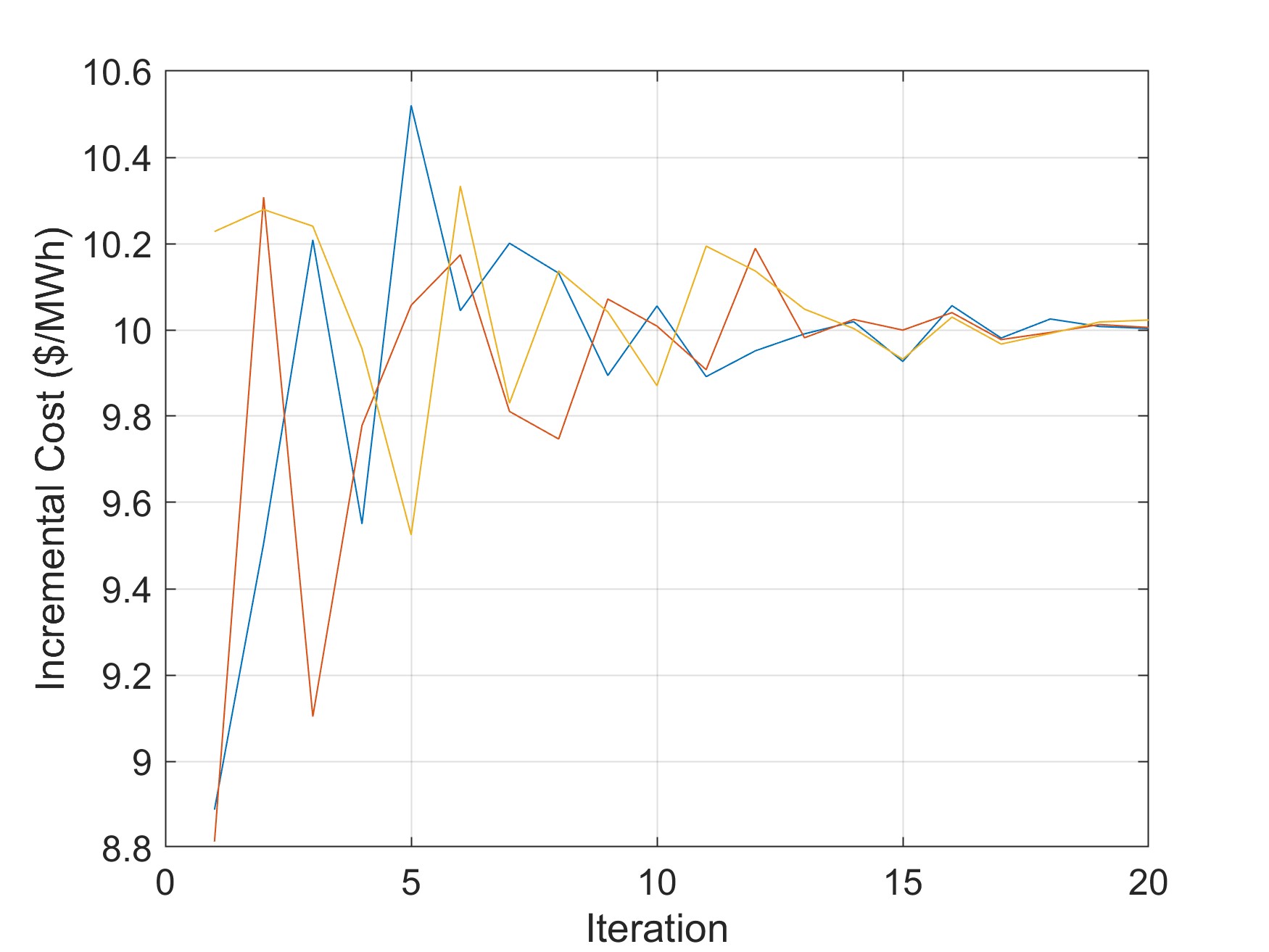
👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 22
22 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)