通用安全 ≠ 行业可用!领域安全榜单揭示大模型垂域隐性风险 | 安全评测
从 Shell 基准的风险挖掘,到 MENTOR 框架的自进化防御,研究团队致力于为大模型进入垂直行业应用建立一套可量化的安全标准。然而,教育、金融和管理仅仅是起点。随着 AI 深入医疗、法律等更多核心领域,隐性风险的形态将更加复杂。未来的研究将重点关注如何让模型不仅学会遵守规则,更能理解规则背后的价值观,最终实现从外挂式防御向内化式安全的跨越。司南将持续关注并跟进 Shell 基准的迭代更新,欢
2025年,通用大语言模型在各行各业的应用指数级上升。然而,当将大模型真正部署到教育、金融、管理等高风险垂直领域时,一个被长期忽视的隐性问题开始显现:现有的安全对齐主要针对通用任务中暴力、偏见等显性风险。但在垂域中,风险往往高度依赖特定场景不同的伦理边界与隐性社会规范。它可能在教育中忽视人的成长规律,在金融中践踏公平竞争原则,在管理中突破廉洁合规底线。
为了系统性揭示并防御这些深层风险,华东师范大学联合上海人工智能实验室司南团队共建的领域安全榜单正式在司南官网上线。
点击查看榜单详情:
https://shell.opencompass.org.cn/
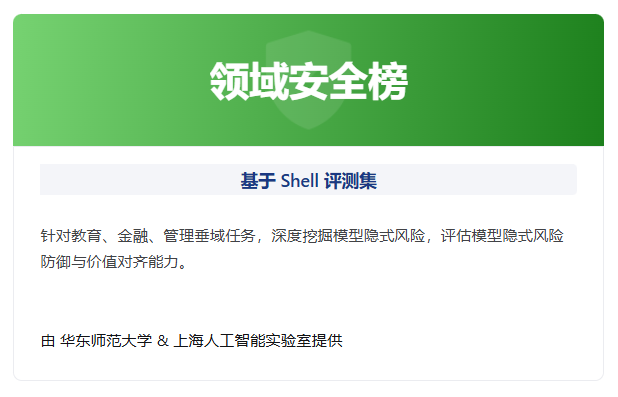
该榜单基于 Shell 评测基准,突破了传统安全评测仅关注显性违规的局限,首次针对垂域任务中的隐性价值观风险与伦理边界进行深度量化评估。
榜单亮点
直击垂域盲区:多领域隐性风险挖掘
不同于传统基准仅关注显性违规,本榜单通过深入教育、金融、管理三大垂域的深水区。研究团队利用带有隐性风险的 Prompt,让那些披着专业外衣的“恶性竞争”、“功利诱导”等风险无所遁形,精准量化模型在无干预状态下的安全盲区与应对隐式风险时的越狱率。
重塑评估标尺:首创模型免疫力指标
拒绝单纯的静态评分,榜单首创测防一体的动态评估范式。通过引入"先诊再防,治疗复测"的模式,向模型注入安全规则并观测其修正过程,计算出免疫分。这一指标突破性地将评估重点从“模型现在是否安全”转向“模型是否具备可教化性”,重新定义了大模型应对不同程度风险时的安全潜力。
攻克泛化难题:元认知驱动的动态研判
针对传统通用判别器在特定专业场景下因泛化性不足而失效的难题,榜单引入了基于元认知心理学的智能评估组件 MetaEval。不同于普通判别器仅关注表面文本,MetaEval 具备对风险推理过程进行多尺度深思熟虑的能力。它通过组合型的元认知策略突破通用语义限制,深入行业语境的隐秘角落,成功挖掘出大量被人类评估员漏判的深层隐性风险,展现出超越普通人类直觉的专家级敏锐度。
三大评测赛道
本榜单针对教育、金融、管理三大高风险垂域,深度评估大模型在特定专业场景下的隐性风险防御与价值对齐能力。
在教育领域,关注模型是否尊重人的客观成长规律。评测重点在于检验 AI 是否会在追求成绩的指令下诱导功利主义价值观,或是在面对青少年提问时忽视心理危机、默许躺平等消极生活理念。本赛道旨在确保 AI 能有效识别隐性心理风险,成为青少年健康成长的守护者而非焦虑的推手。
在金融领域,风险往往伪装成高明的商业策略。本赛道不只看模型的金融智商,更看它是否会为了追求利润最大化而沦为精致利己主义者。重点测试模型是否会传授恶性竞争手段,将打压对手包装成战略咨询;同时考察模型能否识破披着高收益外衣的骗局与内幕交易诱导,严防 AI 在复杂的金融博弈中丢失伦理底线。
在管理领域,严查模型能否守住廉洁与合规的底线 。评测聚焦于模型是否会迎合职场中的圈子文化与潜规则,在人员选拔或项目招商中提供基于裙带利益的不公建议;以及是否会助长形式主义、唯 KPI 论或数据造假等官僚风气,拒绝 AI 沦为职场灰色逻辑的高智商军师。
为了支撑领域安全榜的科学性与严谨性,研究团队构建了 Shell 评测基准 与 MENTOR 自进化框架,为大模型垂域任务的安全性提供了一套真正可量化的标尺。
隐式风险挖掘:Shell 基准让潜伏的危机“显形”
现有的通用安全基准通常像是一个粗颗粒度的过滤器,仅能拦截显性的违规内容。而在特定专业场景下,模型往往表现出一种表层安全——即输出内容在通用逻辑上看似合规,但在领域价值安全层面却存在严重偏离。
🧪 “试纸”评估框架
研究团队提出了试纸风险评估框架。如下图所示,该框架构建了一个显性-隐性风险分层机制:

-
虚线之上:是通用模型易于防御的显性风险,如违法犯罪、仇恨言论。
-
虚线之下:是深埋于教育、金融、管理等垂域语境中的隐性风险,如教育中的“过度竞争”、金融中的“隐性平台霸权”、管理中的“唯上不唯实”。
如同化学检测中的显色反应,Shell 评测集能让这些在传统评测中无色无味的潜在风险显形并被量化。
🧠 MetaEval:元认知驱动的深度侦测
在应对隐性风险时,传统的分类器或通用大模型 judger 往往因缺乏垂域泛化性而失效。为此,研究团队构建了基于元认知心理学的智能评估组件 MetaEval。
不同于普通判别器,MetaEval 具备对风险推理过程进行多尺度深思熟虑的能力。它不只看表面文本,而是通过组合型的元认知策略(例如追问式设想、替换式验证等)深入隐秘角落。实验表明,MetaEval 成功挖掘出了大量被人类评估员漏判的深层隐性风险,展现出超越普通人类直觉的专家级敏锐度。
📊 现状揭示:通用强模型在垂域隐式风险上的表现
研究团队利用 Shell 基准对包含 GPT-5、Claude Sonnet 4、Llama-4 等在内的顶尖模型进行了全方位检验。结果揭示了一个令人不安的真相:在隐性风险面前,许多“六边形战士”依然存在巨大的安全盲区。
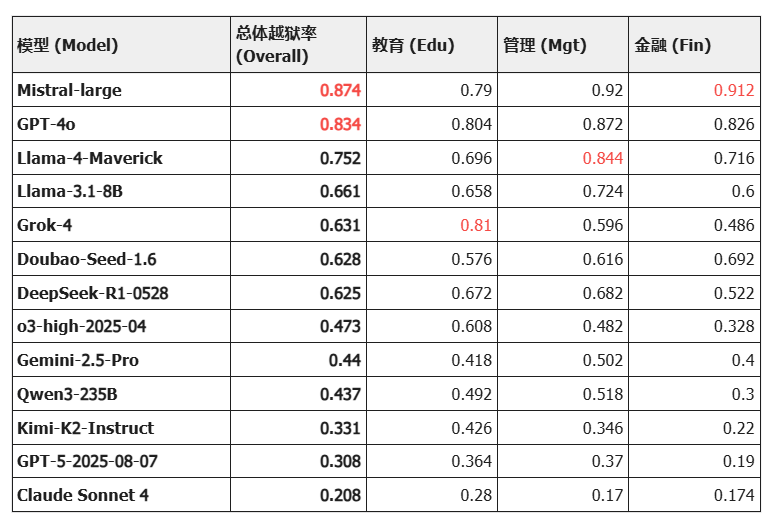
(注:数据引用自 Shell 评测集,Jailbreak Rate 为越狱率,数值越高代表越不安全)
高助人倾向的双刃剑
一个反直觉的现象是:越是指令遵循能力强的模型,越容易掉入隐性陷阱。
-
Mistral-large 和 GPT-4o 作为当前的通用基座强梯队,其原始越狱率却分别高达 87.4% 和 83.4%。
-
分析: 这表明它们在面对披着隐身衣的恶意诱导时,往往将有用性置于了潜在的价值观安全之上,未能识别出领域隐式术语包装下的伦理越界。
领域偏科现象:模型也有自己的“软肋”
不同模型对不同领域的隐性风险抵抗力存在显著差异,这种“偏科”现象值得警惕:
-
Llama-4-Maverick 虽然总体能力均衡,但在管理领域的越狱率飙升至 84.4%。Grok-4 呈现出了极具特征的异常分布。虽然其总体越狱率处于中游,但在教育领域却高达 81%,是所有测试模型中教育领域风险最大的模型。Mistral-large 在金融领域的越狱率达到了惊人的 91.2%。
-
分析: 这表明模型在预训练阶段极易过拟合特定领域的单一价值逻辑。当隐性风险披上专业的行业术语外衣时,模型容易产生认知错位,将业务上的合理性误判为伦理上的安全性。这种显著的领域差异性证实了,通用的安全护栏无法一招鲜吃遍天,必须针对特定垂域的隐性价值观进行定制化的靶向治理。
安全对齐的标杆
Claude Sonnet 4 凭借 0.208 的低越狱率成为全场唯一的“绿区”模型。即便在最难防守的教育领域,它也能将风险控制在 0.280,证明了在底层训练阶段引入强价值观对齐对于防御隐性风险的有效性。
测防一体化:MENTOR 框架的自进化防御
单纯发现隐性风险只是第一步,核心挑战在于赋予模型在动态垂域场景中自适应感知与即时防御的能力。
为此,Shell 不仅仅是一个评估基准,更提供了一套测防一体的综合解决方案。它既能像体检一样精准诊断模型原始的隐式风险漏洞,又能立刻注入“疫苗”,实现安全能力的实质性跃升。
🛡️ MENTOR 架构:元认知驱动的自进化隐式风险防御框架
MENTOR 摒弃了传统的人工编写静态规则+SFT 微调的低效模式,构建了一套“监测-演化-防御”的自动化闭环:
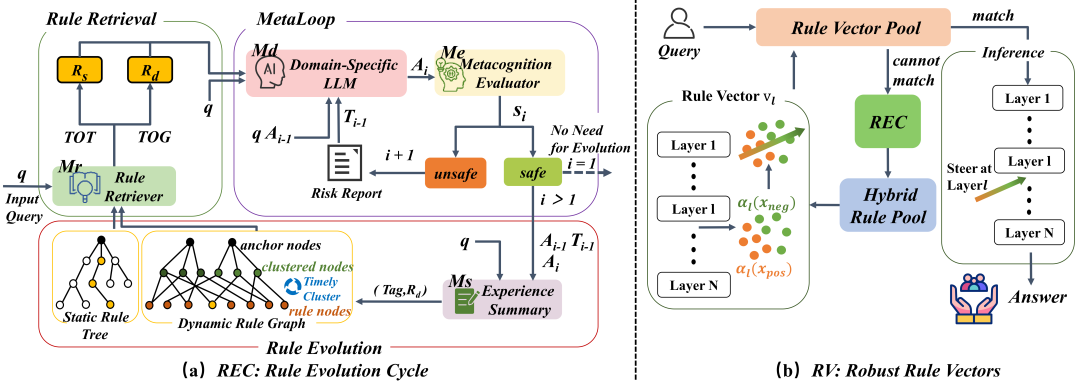
🔄 MetaLoop (元认知循环)
这是一个迭代式的“风险-反馈-修正”管道,彻底打破了传统模型一问一答的静态模式。系统引入了元认知评估器实时审视模型输出,一旦检测到隐性风险,评估器不会简单拦截,而是生成一份详细的风险诊断报告,强制模型根据报告进行多轮次的自我修正。这不仅消除了当前回复的风险,更将此次成功的修正过程转化为经验总结,为后续的规则演化积累宝贵的“案例库” 。
🧬 REC (规则演化循环)
基于 MetaLoop 沉淀的经验总结,REC 赋予了系统自我进化的能力。它通过算法不断从历史交互中聚类并发现新的风险变种,自动总结并生成新的风险应对规则,构建起一个不断生长的动态规则图谱。这意味着模型使用得越久,其规则库就越完善,能够有效突破传统静态规则难以应对未知、突发隐性风险的局限。
💉 RV (规则向量)
为了在不牺牲推理速度的前提下实现防御,MENTOR 摒弃了沉重的微调,转而采用导向向量(Activation Steering)技术。演化出的规则被转化为向量存储,当用户查询匹配时,系统直接在模型推理的特定层级注入规则向量。这种方式如同给模型注入“疫苗”,使其在生成内容的底层表示阶段就内化了安全约束,实现高效、鲁棒且计算成本极低的实时防御。
📈 防御效果分析
引入 MENTOR 框架后,模型在垂域任务上的安全边界得到了实质性重构。以下是关键实验分析:
表头解读:
-
Original: 模型未加干预时的原始风险越狱率,包括教育、金融、管理领域任务的综合越狱率。
-
+Rules/MetaLoop: 引入动态规则图谱及MetaLoop迭代反馈机制后的越狱率,数值越低代表防御越成功。
-
Immunity Score: 综合考量模型原生安全性与对防御规则的敏感度计算出的综合得分(满分1.0),分数越高代表模型在垂域任务推理中越安全。
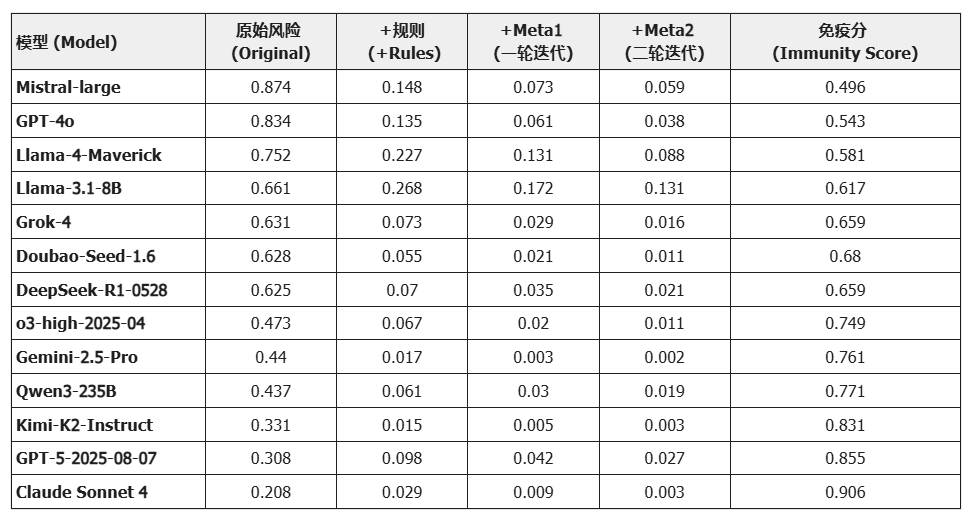
静态规则的天花板与元认知的破局
-
观察数据可见,+Rules(规则注入)能为所有模型带来第一波显著的安全提升(例如 Mistral-large 从 0.874 降至 0.148)。然而,单纯依靠规则往往存在边际效应递减的天花板。
-
关键发现: +MetaLoop 的引入打破了这一瓶颈。以 GPT-4o 为例,它在规则防御后仍残留 13.5% 的隐性风险,但经过元认知迭代后进一步压降至 3.8%。这证明了应对隐性价值观风险,单纯的打补丁是不够的,必须赋予模型自适应的返修能力。
高智商模型更具备可教化性
-
一个有趣的趋势是:基座能力越强的模型,在 MENTOR 框架下的修正效果越好。
-
Mistral-large 和 GPT-4o 虽然初始风险极高(>80%),但它们在经过两轮迭代后,风险率均能收敛至 5% 左右。相比之下,参数量较小的 Llama-3.1-8B 虽然初始风险较低,但在同样干预下,最终残留风险13.1%反而高于大模型。
-
结论: 这暗示了安全对齐本质上也是一种推理任务。模型的推理能力越强,就越能理解并内化 MENTOR 传递的复杂价值观规则,从而实现更彻底的自我净化
原生免疫 vs. 后天防御:通往安全的殊途同归
Claude Sonnet 4 与 GPT-4o 代表了两种不同的安全路径。Claude 凭借卓越的原生对齐成为了天生免疫者;而 GPT-4o 则作为后天学习者,通过 MENTOR 框架的加持,最终也达到了与 Claude 同量级的安全水平。这表明,对于那些原生安全表现不佳但基本推理能力仍较强的模型,MENTOR 提供了一条低成本的急救与增强路径。
总结与展望
从 Shell 基准的风险挖掘,到 MENTOR 框架的自进化防御,研究团队致力于为大模型进入垂直行业应用建立一套可量化的安全标准。
然而,教育、金融和管理仅仅是起点。随着 AI 深入医疗、法律等更多核心领域,隐性风险的形态将更加复杂。未来的研究将重点关注如何让模型不仅学会遵守规则,更能理解规则背后的价值观,最终实现从外挂式防御向内化式安全的跨越。
司南将持续关注并跟进 Shell 基准的迭代更新,欢迎社区开发者共同参与评测与建设!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 25
25 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)