基于AI大模型 python小说数据分析可视化系统 协同过滤推荐算法 可视化大屏 Django框架 Echarts可视化 (建议收藏)
基于AI大模型 python小说数据分析可视化系统 协同过滤推荐算法 可视化大屏 Django框架 Echarts可视化 (建议收藏)
·
博主介绍:✌全网粉丝50W+,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久,累计开发项目作品上万套。凭借丰富的经验与专业实力,已帮助成千上万的学生顺利毕业,选择我们,就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅
2、大数据、计算机专业选题(Python/Java/大数据/深度学习/机器学习)(建议收藏)✅
1、项目介绍
该基于Python与Django的小说数据分析、可视化与推荐系统,功能丰富且实用,涵盖多个关键模块:
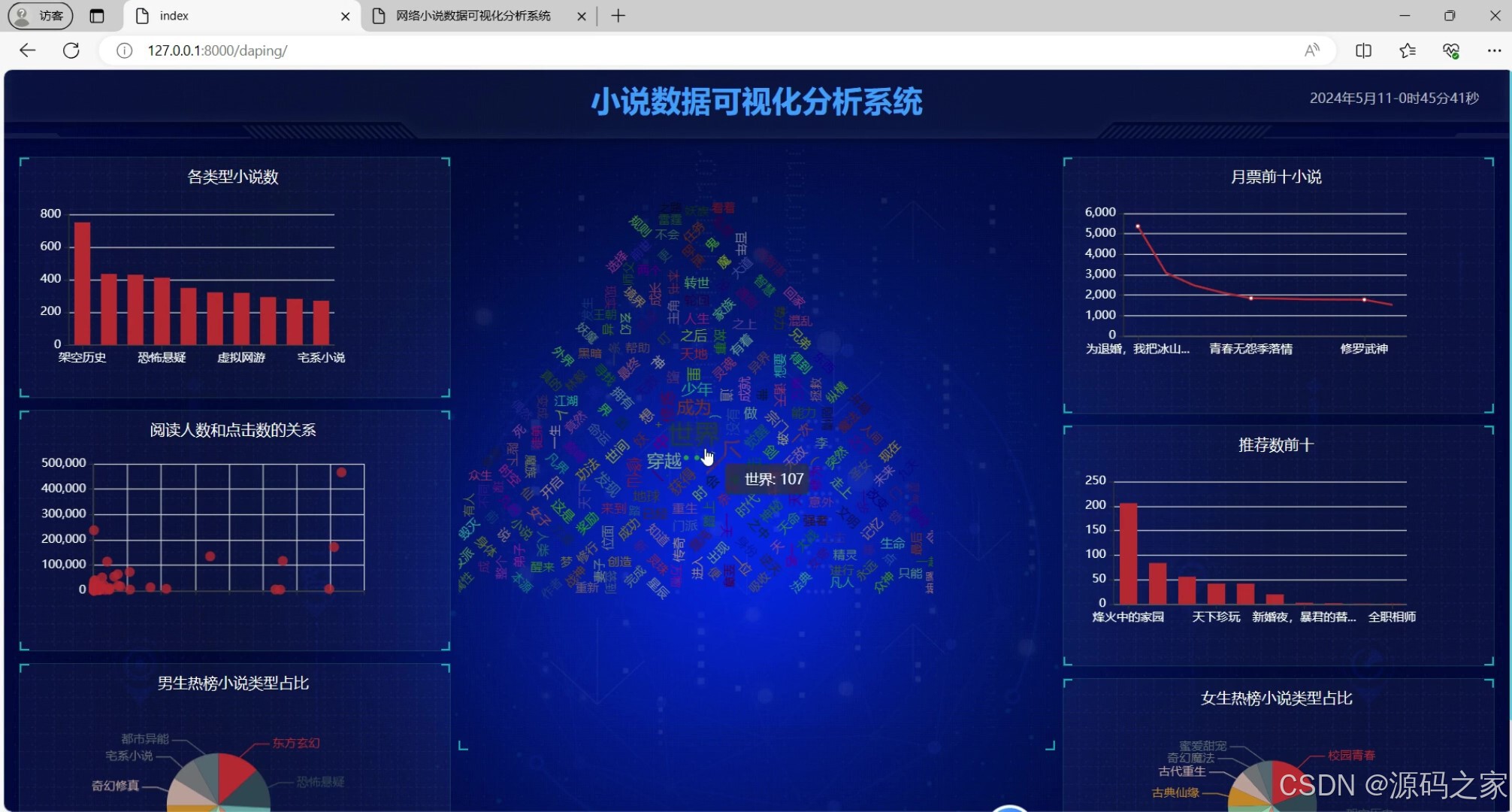
数据分析可视化大屏:集中呈现阅读趋势、用户活跃度等分析结果,借助Echarts、HTML和CSS,以折线图等多种图表直观展示数据。
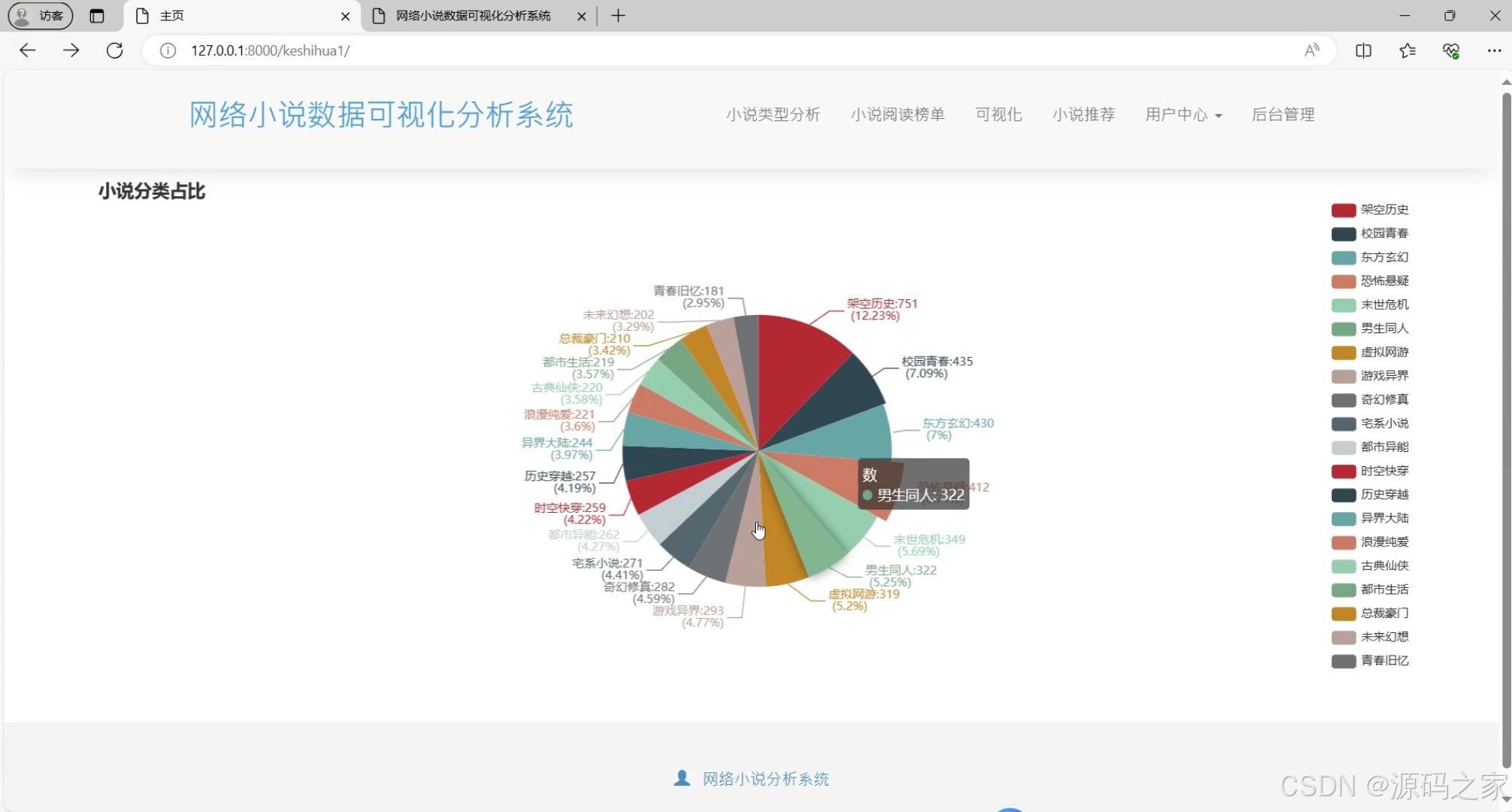
分类占比分析:通过Echarts绘制饼图或环形图,展示不同小说分类占比,Django提供数据,助用户了解阅读偏好。
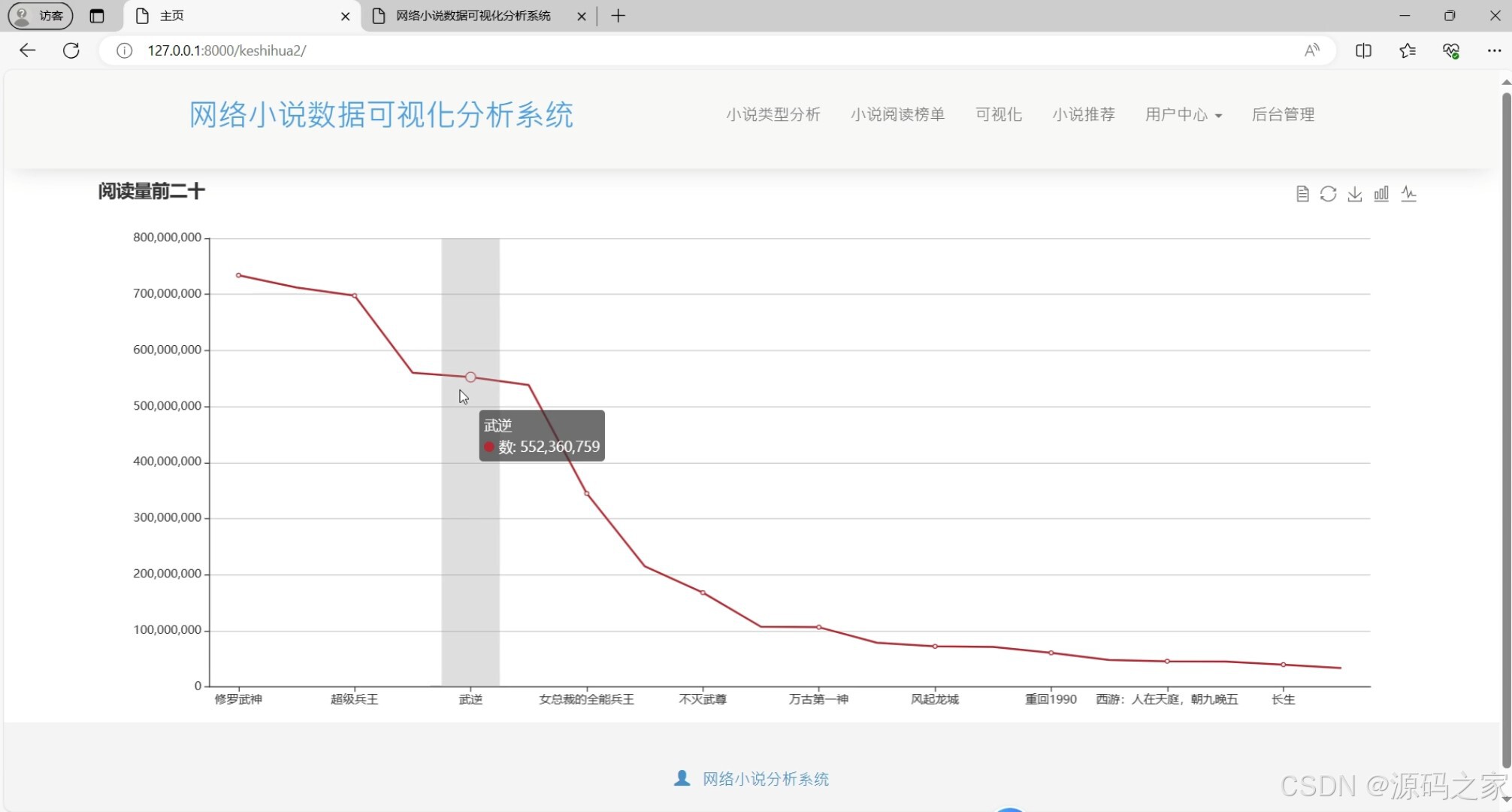
阅读量前20分析:Django对小说阅读量排序并筛选前20名,Echarts绘制条形图,清晰呈现热门小说。
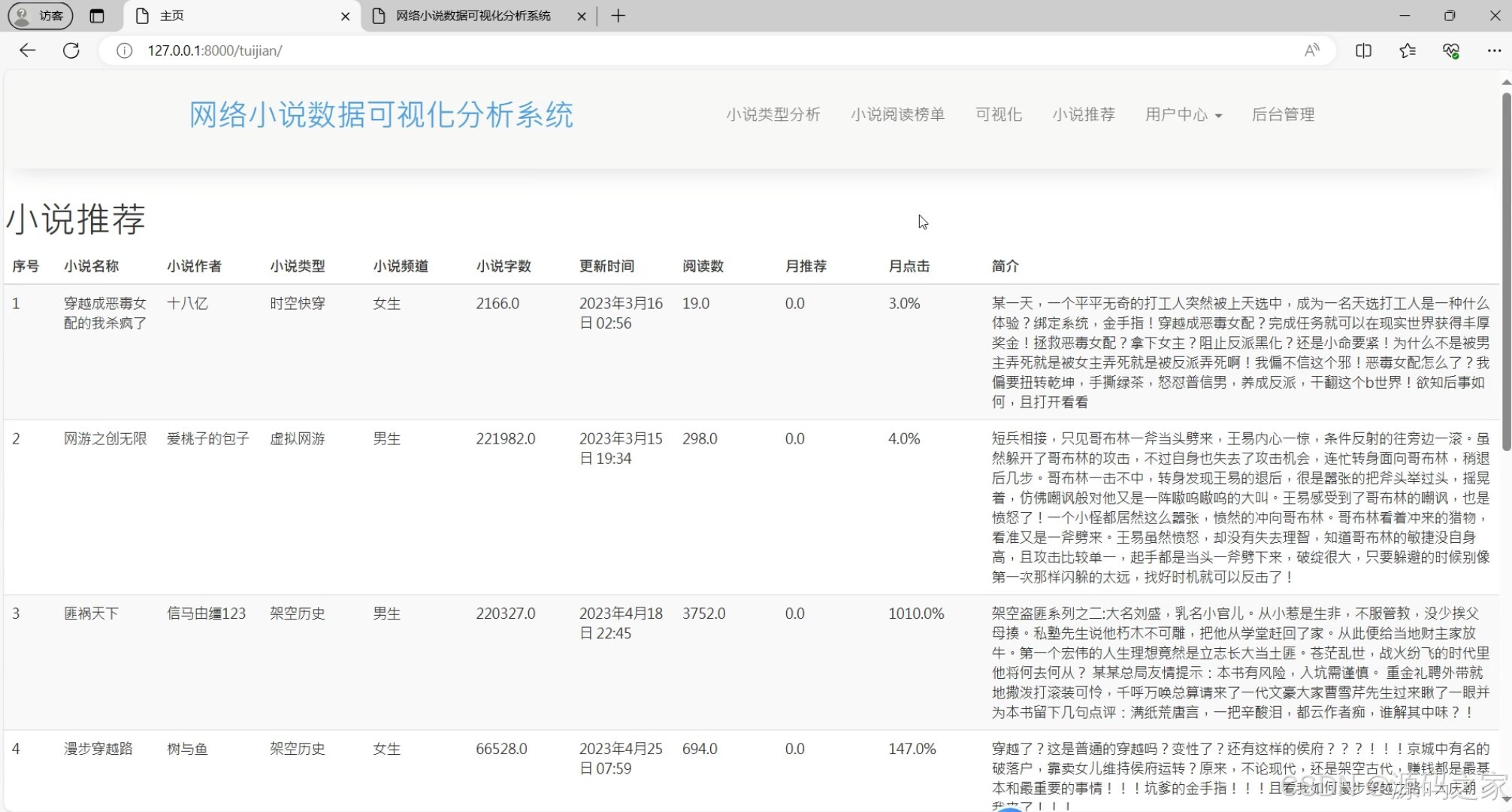
小说推荐:运用协同过滤推荐算法,Django后端实现逻辑,根据用户阅读历史推荐相似或感兴趣的小说。
用户中心:依托Django用户认证系统,结合HTML和CSS设计界面,用户可管理个人信息、查看阅读历史与收藏夹。
注册登录:利用Django内置认证系统,保障用户身份安全与数据私密,实现注册、登录、密码重置等功能。
后台数据管理:采用Django admin后台或自定义系统,为管理员提供数据增删改查功能,方便管理小说、用户及查看日志。
技术栈:
Python语言、Django框架、协同过滤推荐算法、数据分析、Echarts可视化、大屏、HTML
2、项目界面
(1)小说数据分析可视化大屏
(2)小说分类占比分析
(3)阅读量前20分析
(4)小说推荐
(5)用户中心
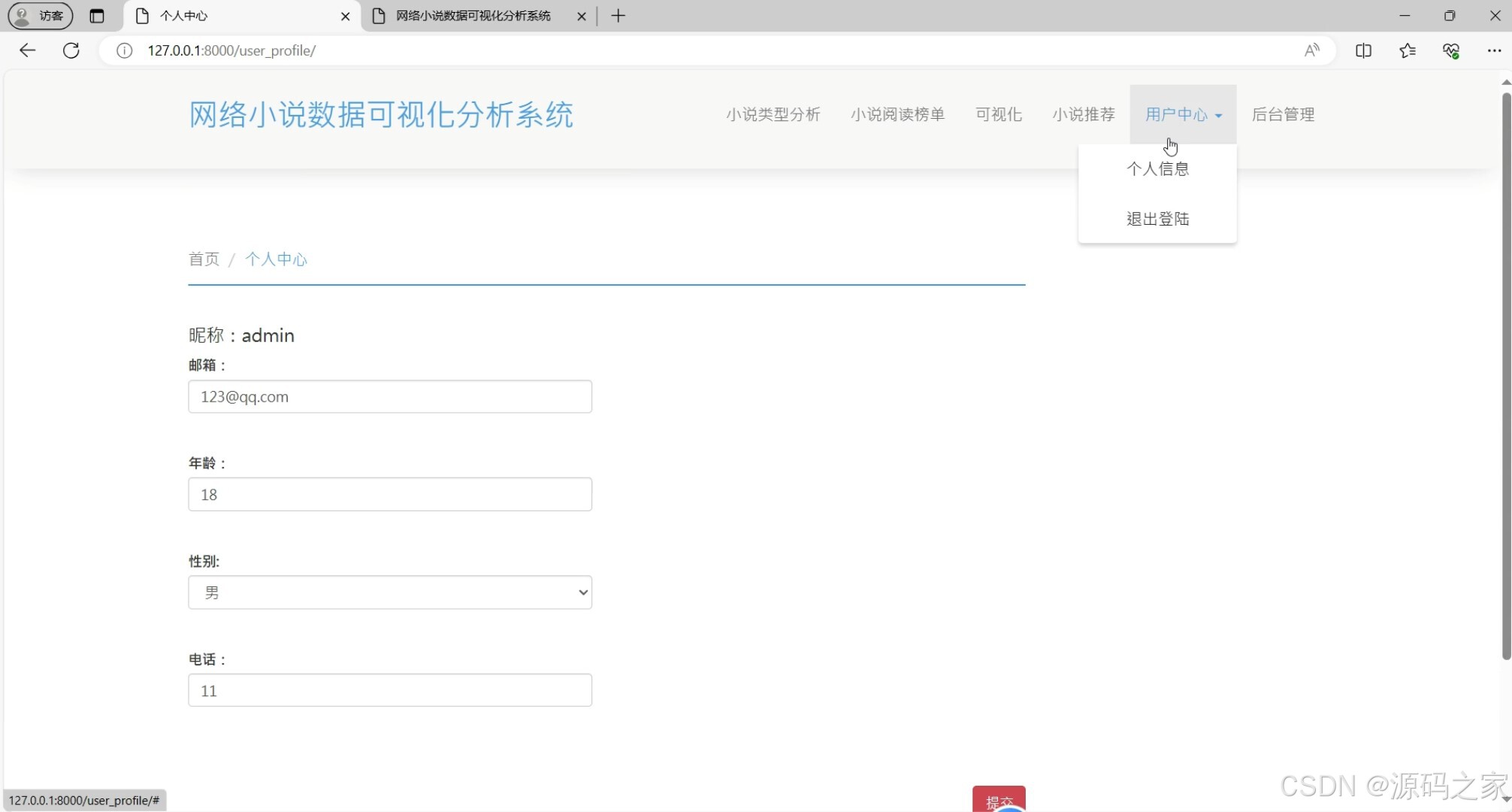
(6)注册登录
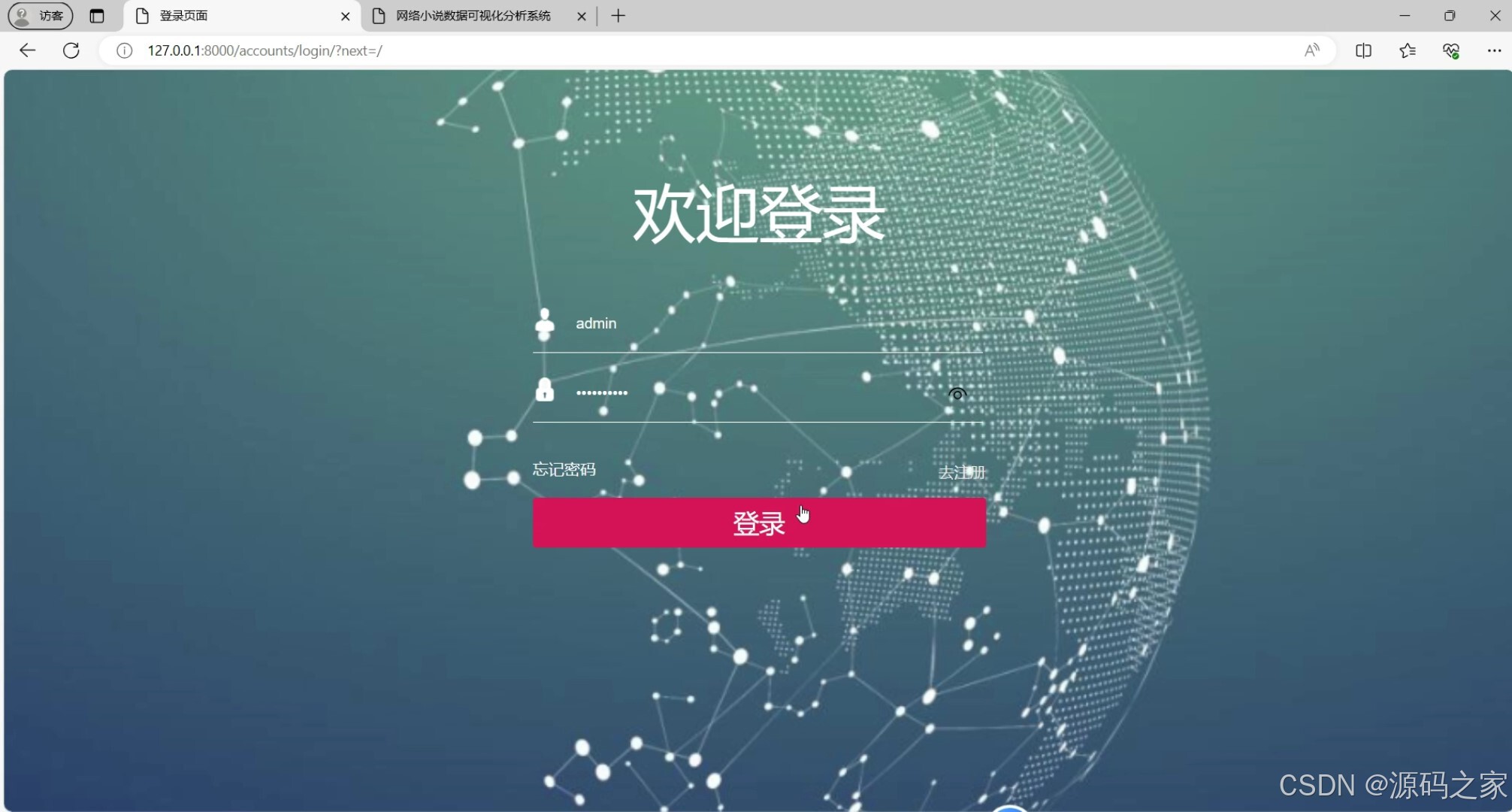
(7)后台数据管理
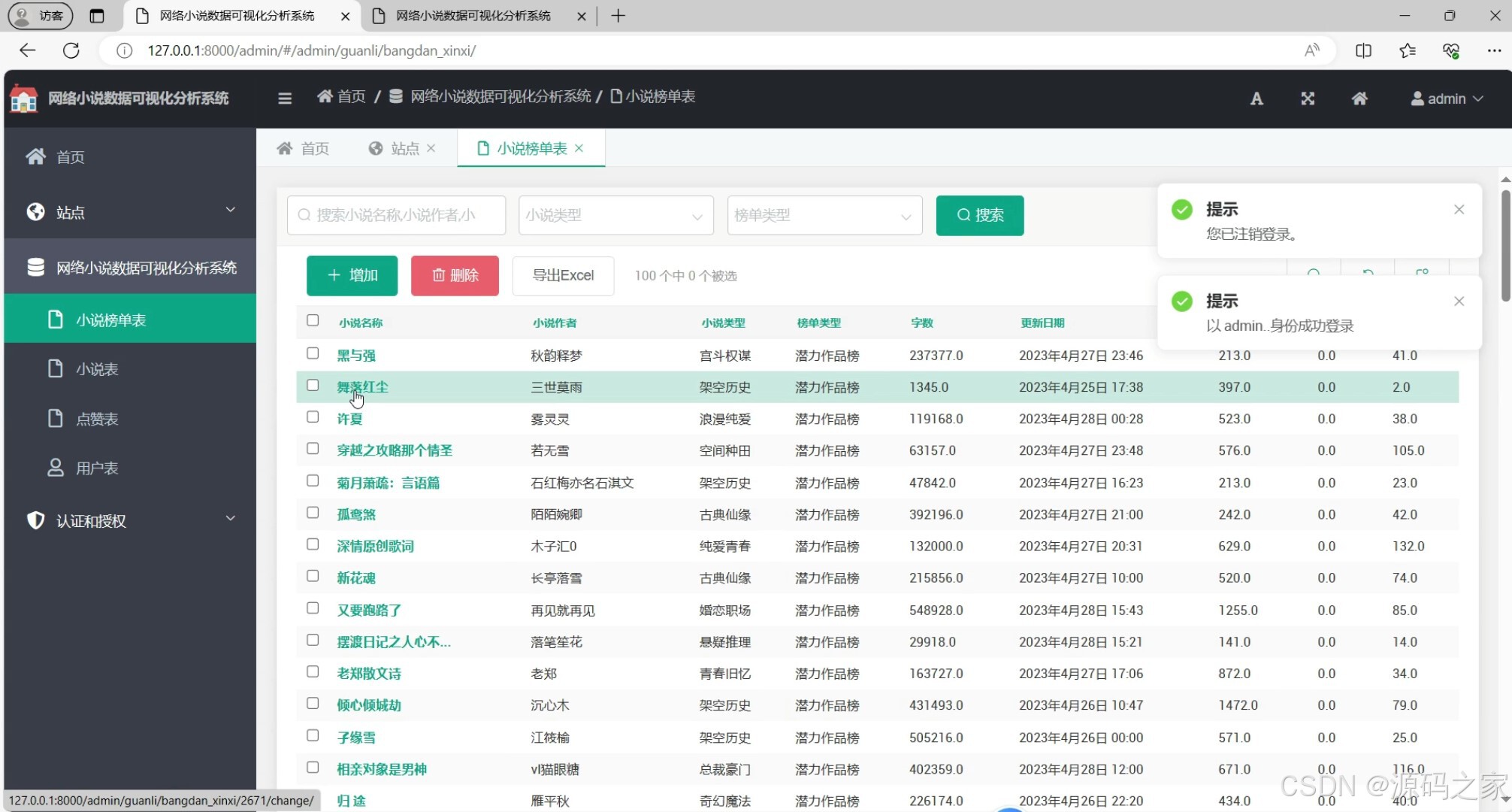
3、项目说明
该基于Python与Django的小说数据分析、可视化与推荐系统,功能丰富且实用,涵盖多个关键模块:
数据分析可视化大屏:集中呈现阅读趋势、用户活跃度等分析结果,借助Echarts、HTML和CSS,以折线图等多种图表直观展示数据。
分类占比分析:通过Echarts绘制饼图或环形图,展示不同小说分类占比,Django提供数据,助用户了解阅读偏好。
阅读量前20分析:Django对小说阅读量排序并筛选前20名,Echarts绘制条形图,清晰呈现热门小说。
小说推荐:运用协同过滤推荐算法,Django后端实现逻辑,根据用户阅读历史推荐相似或感兴趣的小说。
用户中心:依托Django用户认证系统,结合HTML和CSS设计界面,用户可管理个人信息、查看阅读历史与收藏夹。
注册登录:利用Django内置认证系统,保障用户身份安全与数据私密,实现注册、登录、密码重置等功能。
后台数据管理:采用Django admin后台或自定义系统,为管理员提供数据增删改查功能,方便管理小说、用户及查看日志。
这个项目是一个基于Python语言和Django框架构建的小说数据分析、可视化与推荐系统。以下是对各个功能模块的详细介绍:
- 小说数据分析可视化大屏模块
功能:提供一个大屏界面,集中展示小说的各种数据分析结果,如阅读趋势、用户活跃度、小说分类分布等。
技术栈:使用Echarts进行数据可视化,HTML和CSS进行界面布局。
实现:通过Django后端传递数据给前端,前端使用Echarts绘制各种图表,如折线图、柱状图、饼图等,以直观的方式展示数据分析结果。 - 小说分类占比分析模块
功能:展示不同小说分类在整体中的占比,帮助了解用户的阅读偏好。
技术栈:Echarts用于绘制饼图或环形图,Django提供数据支持。
实现:后端统计各类小说的数量或阅读量,将比例数据传递给前端,前端使用Echarts绘制分类占比图。 - 阅读量前20分析模块
功能:展示阅读量排名前20的小说,帮助用户了解热门小说。
技术栈:Echarts用于绘制条形图,Django提供排序和筛选后的数据。
实现:后端对小说阅读量进行排序,取前20名,将相关数据传递给前端,前端使用Echarts绘制条形图。 - 小说推荐模块
功能:根据用户的阅读历史和偏好,推荐相似或可能感兴趣的小说。
技术栈:协同过滤推荐算法,Django后端实现推荐逻辑。
实现:后端使用协同过滤算法(如用户-用户协同过滤或物品-物品协同过滤)计算小说之间的相似性,根据用户的阅读历史推荐相似小说。 - 用户中心模块
功能:提供用户个人信息管理、阅读历史查看、收藏夹管理等功能。
技术栈:Django用户认证系统,HTML和CSS进行界面设计。
实现:用户登录后,可以查看和编辑个人信息,查看阅读历史和收藏的小说,管理自己的账户。 - 注册登录模块
功能:提供用户注册和登录功能,确保用户身份的安全性和数据的私密性。
技术栈:Django用户认证系统。
实现:使用Django内置的用户认证系统,实现用户注册、登录、密码重置等功能。用户注册后,可以登录系统访问个性化功能。 - 后台数据管理模块
功能:为管理员提供后台管理界面,用于管理小说数据、用户信息、系统设置等。
技术栈:Django admin后台或自定义后台管理系统。
实现:利用Django的admin后台或自定义后台管理界面,提供数据的增删改查功能。管理员可以管理小说信息、用户账户、查看系统日志等。
系统整体流程
数据采集与存储:小说数据可能通过爬虫或其他方式采集,并存储在数据库中。
数据分析与可视化:对小说数据进行统计分析,使用Echarts在大屏和各个分析模块中展示结果。
小说推荐:根据用户行为数据,使用协同过滤算法推荐小说。
用户管理:用户通过注册登录系统,访问个性化功能和用户中心。
后台管理:管理员通过后台管理界面管理系统数据和用户。
4、核心代码
#!/usr/bin/python
# -*- coding: UTF-8 -*-
from math import sqrt
import operator
#1.构建用户-->物品的倒排
def loadData(files):
data ={};
for line in files:
user,score,item=line.split(",");
data.setdefault(user,{});
data[user][item]=score;
return data
#2.计算
# 2.1 构造物品-->物品的共现矩阵
# 2.2 计算物品与物品的相似矩阵
def similarity(data):
# 2.1 构造物品:物品的共现矩阵
N={};#喜欢物品i的总人数
C={};#喜欢物品i也喜欢物品j的人数
for user,item in data.items():
for i,score in item.items():
N.setdefault(i,0);
N[i]+=1;
C.setdefault(i,{});
for j,scores in item.items():
if j not in i:
C[i].setdefault(j,0);
C[i][j]+=1;
#2.2 计算物品与物品的相似矩阵
W={};
for i,item in C.items():
W.setdefault(i,{});
for j,item2 in item.items():
W[i].setdefault(j,0);
W[i][j]=C[i][j]/sqrt(N[i]*N[j]);
return W
#3.根据用户的历史记录,给用户推荐物品
def recommandList(data,W,user,k=3,N=10):
rank={};
for i,score in data[user].items():#获得用户user历史记录,如A用户的历史记录为{'a': '1', 'b': '1', 'd': '1'}
for j,w in sorted(W[i].items(),key=operator.itemgetter(1),reverse=True)[0:k]:#获得与物品i相似的k个物品
if j not in data[user].keys():#该相似的物品不在用户user的记录里
rank.setdefault(j,0);
rank[j]+=float(score) * w;
return sorted(rank.items(),key=operator.itemgetter(1),reverse=True)[0:N];
if __name__=='__main__':
#用户,兴趣度,物品
uid_score_bid = ['A,1,a', 'A,1,b', 'A,1,d', 'B,1,b', 'B,1,c', 'B,1,e']
data=loadData(uid_score_bid);#获得数据
W=similarity(data);#计算物品相似矩阵
a = recommandList(data,W,'A',5,10);#推荐
print(a)
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目编程以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
5、源码获取方式

🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 17
17 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)