大模型全量指令微调——Full Parameter SFT
本文介绍了预训练好自己的大语言模型后如何微调,激发模型的对话能力,并讨论了如何调用trl库进行预训练。
🚀 欢迎来到《大语言模型》系列,博客文章将围绕现代大模型框架和技术展开讨论。基于Hugging Face的transformers库,该系列代码的实现尽在GitHub仓库项目🔗Milli-Chat中集成,感谢大家的支持!
文章导航
模型完成预训练之后,当用户输入一段提示词时,模型只会根据用户的输入续写这一段话,并不会回答问题。因此需要对模型使用指令微调,让它学会回答问题或者与用户对话。这个核心的过程就是SFT(Supervised Fine-Tuning,有监督微调)。现在基本上都用指令微调来完成SFT。
1 Chat Template
预训练是让模型会续写,这个句子后面该接续什么话。SFT的目标是让模型遵循指令,回答问题。因此需要给纯文本加上结构,这种结构就是BERT的那种[BOS]、[UNK]之类的特殊标记,用于区分不同的句子。
一般来说,指令微调提供的是json或jsonl文件。最简单最经典的微调数据集格式就是Alpaca格式,这种格式适用于和模型的单轮对话:
{
"instruction": "早上好",
"input": "", // 可选,作为上下文
"output": "早上好,有什么可以帮助您的吗?"
}
拿到这样的数据集之后,需要将其构造成一个结构化的文本,给模型去训练。这个时候就需要用到模型自定义的特殊token,来对这些内容进行分隔。假定分词器的sos_token为<|im_start|>,eos_token为<|im_end|>,这里用最简单的方式将数据集组织成结构化文本:
<|im_start|>user
早上好
<|im_end|>
<|im_start|>assistant
早上好,有什么可以帮助您的吗?<|im_end|>
如果模型追求的质量不高的话,instruction和input属性可以放一起,构造这样的提示词模板就已经足够了。接着只需要给模型训练这样的模板格式,比如:
<|im_start|>user\n早上好\n<|im_end|>\n<|im_start|>assistant\n早上好,有什么可以帮助您的吗?<|im_end|>
模型越大,追求更高的输出质量,那么结构就可能更加复杂。本质上预训练和指令微调的过程并没有太大的区别,训练的目的就是让大模型识别这种输出格式,依然完成句子续写的任务,让模型读取到<|im_start|>user\n XXXXXXX \n<|im_end|>\n<|im_start|>assistant内容之后,根据user的内容完成续写,直到输出<|im_end|>才停止输出。
因此训练完成之后,想让模型激发对话的能力,就得将用户提示词包装起来,在代码中可以这样实现
prompt_str = f"{self.tokenizer.bos_token}user\n{prompt_content}\n{self.tokenizer.eos_token}\n{self.tokenizer.bos_token}assistant\n"
但是想要模型开箱就能用,即不希望用户手动包装提示词,可以修改分词器相关文件。你可以在Hugging Face网站上下载任意一个大模型的分词器配置文件tokenizer_config.json,在文件的末尾有一个chat_template属性,这个就是该大模型给文本加上的结构。这种结构采用的是Jinja2模板语法,Hugging Face的transformers库使用tokenizer.apply_chat_template来自动处理<|im_start|>这些标签。以上面的prompt封装格式为例,添加如下属性
{
"chat_template": "{% for message in messages %}{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}{% endfor %}{% if add_generation_prompt %}{{ '<|im_start|>assistant\n' }}{% endif %}"
}
接着在推理的时候,就不需要手动封装格式了,直接如下操作就能够自动封装:
messages = [
{"role": "user", "content": "你好,请介绍一下你自己。"}
]
# apply_chat_template会自动生成:<|im_start|>user\n XXXX <|im_end|>\n<|im_start|>assistant\n
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
2 Completions only
也叫Instruction Masking,指令掩码。
在预训练中,分词器将一个序列转化为token id序列后,做一个shifted right操作,得到label序列。
对于微调而言,我们给模型输入的是question+answer,那么训练过程中就会计算整段序列的loss,这意味着模型不仅在学习如何回答,还在学习如何提问。这不仅浪费算力,还可能让模型在推理时变得啰嗦,可能会再把问题复述一遍。因此训练好以后的模型只需要输出answer部分即可,它不需要关注question部分,即只包含用户输入的部分,比如上一节中所举的例子中的这一部分:
<|im_start|>user\n早上好\n<|im_end|>\n<|im_start|>assistant\n
后面紧跟着的answer才是模型需要学习的内容,因为模型只需要识别回答模式,并根据前面的内容作出回答即可。
在计算梯度的时候,把question部分给遮住。在PyTorch中,只需要将question部分的token id替换为-100,在计算梯度的过程中就会自动忽略这些位置上的token,即不参与loss的计算。
⭐ 在PyTorch的
CrossEntropyLoss中,默认ignore_index=-100。任何label为-100的位置,都不会产生loss,梯度也不会回传。
因此构造掩码遮蔽序列的question部分即可。下图直观展现了数据的处理操作,一个方块表示一个token id,灰色token方块表示user或者assistant的内容。
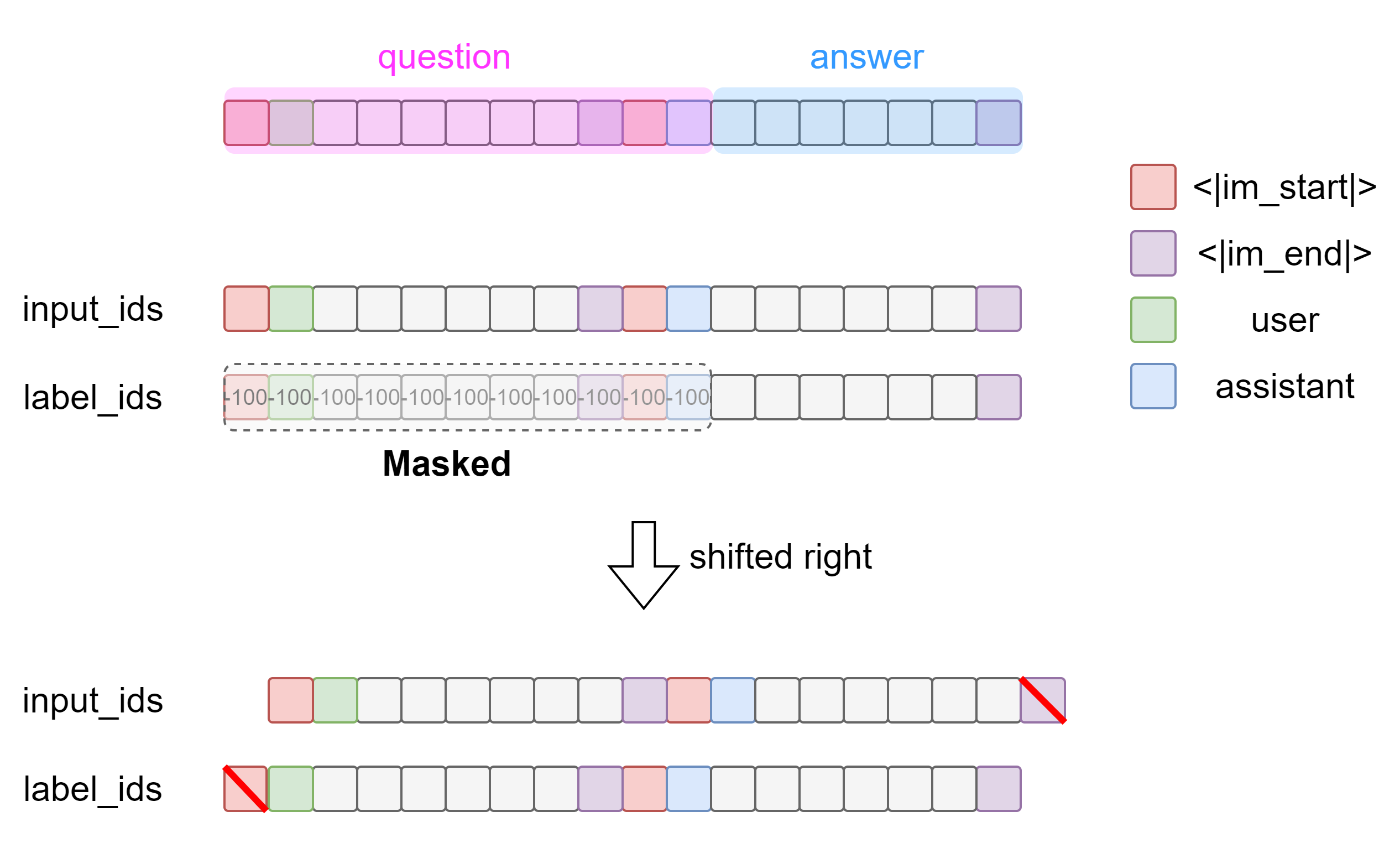
后面的右移操作通常在自定义的XXXForCaulsalLM中的forward函数里实现,Dataset只需要负责构造完整的序列。
def forward(self, input_ids, labels=None, **kwargs):
hidden_states = self.model(input_ids)
logits = self.lm_head(hidden_states)
if labels is not None:
shift_logits = logits[..., :-1, :].contiguous()
shift_labels = labels[..., 1:].contiguous()
pass
根据图示中的操作,可以构造数据集:
class SFTDataset(Dataset):
def __init__(self, file_path: str, tokenizer: AutoTokenizer, max_len: int = 1024, format_map: dict = None):
'''
Args:
format_map: 字典 {"instruction": "instruction", "input": "input", "output": "output"}
'''
self.tokenizer = tokenizer
self.max_len = max_len
self.data = []
if format_map is None:
self.format_map = {"instruction": "instruction", "input": "input", "output": "output"}
else:
self.format_map = format_map
print(f"📂 加载指令微调数据集 {file_path}")
with open(file_path, 'r', encoding='utf-8') as f:
for line in f:
if not line.strip(): continue
try:
item = json.loads(line)
self.data.append(item)
except json.JSONDecodeError:
continue
print(f"✅ 加载了 {len(self.data)} 条样本")
def __len__(self):
return len(self.data)
def __getitem__(self, index):
item = self.data[index]
instruction = item.get(self.format_map["instruction"], "")
input_text = item.get(self.format_map["input"], "")
output_text = item.get(self.format_map["output"], "")
if input_text:
prompt_content = f"{instruction}\n{input_text}"
else:
prompt_content = instruction
# 如果tokenizer_config文件有chat_template属性 则使用apply_chat_template来构造
prompt_str = f"{self.tokenizer.bos_token}user\n{prompt_content}\n"
+ f"{self.tokenizer.eos_token}\n{self.tokenizer.bos_token}assistant\n"
answer_str = f"{output_text}{self.tokenizer.eos_token}"
prompt_ids = self.tokenizer.encode(prompt_str, add_special_tokens=False)
answer_ids = self.tokenizer.encode(answer_str, add_special_tokens=False)
# 这里超出最大长度限制直接暴力截断
if len(prompt_ids) >= self.max_len - 1:
prompt_ids = prompt_ids[:self.max_len // 2]
max_answer_len = self.max_len - len(prompt_ids)
if len(answer_ids) > max_answer_len:
answer_ids = answer_ids[:max_answer_len]
input_ids = prompt_ids + answer_ids
# -100 是pytorch中忽略loss的标志
labels = [-100] * len(prompt_ids) + answer_ids
# 填充为最大长度序列
pad_len = self.max_len - len(input_ids)
if pad_len > 0:
input_ids = input_ids + [self.tokenizer.pad_token_id] * pad_len
labels = labels + [-100] * pad_len
return {
"input_ids": torch.tensor(input_ids, dtype=torch.long),
"labels": torch.tensor(labels, dtype=torch.long)
}
上述代码是基于Alpaca格式的jsonl数据集的数据处理方式,作为参考,处理方式不是唯一的。
注意上述代码需要优化,应改为Dynamic Padding:Dataset只做tokenization和masking,返回非定长的list。Padding交给DataCollator在每个Batch级别动态进行。
这里使用transformers库中的DataCollatorForSeq2Seq数据类来处理,并传给torch.utils.data.DataLoader的collate_fn属性。该类能够将一个batch中的序列填充到和一个batch中的最长序列一样长,而不需要所有的序列都填充至max_len长度,从而加快训练的速度。优化后的代码:
from transformers import DataCollatorForSeq2Seq
class OptimizedSFTDataset(Dataset):
def __init__(self, file_path: str, tokenizer: AutoTokenizer, max_len: int = 1024, format_map: dict = None):
self.tokenizer = tokenizer
self.max_len = max_len
self.data = []
self.format_map = format_map or {"instruction": "instruction", "input": "input", "output": "output"}
print(f"📂 加载微调数据 {file_path}")
with open(file_path, 'r', encoding='utf-8') as f:
for line in f:
if not line.strip(): continue
try:
self.data.append(json.loads(line))
except json.JSONDecodeError:
continue
print(f"✅ 加载 {len(self.data)} 条样本.")
def __len__(self):
return len(self.data)
def __getitem__(self, index):
item = self.data[index]
instruction = item.get(self.format_map["instruction"], "")
input_text = item.get(self.format_map["input"], "")
output_text = item.get(self.format_map["output"], "")
if input_text:
user_content = f"{instruction}\n{input_text}"
else:
user_content = instruction
messages = [
{"role": "user", "content": user_content},
{"role": "assistant", "content": output_text}
]
full_text_ids = self.tokenizer.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=False,
truncation=True,
max_length=self.max_len
)
prompt_ids = self.tokenizer.apply_chat_template(
[messages[0]],
tokenize=True,
add_generation_prompt=True
)
input_ids = torch.tensor(full_text_ids, dtype=torch.long)
labels = input_ids.clone()
# 防止prompt比full_text还要长的情况
prompt_len = len(prompt_ids)
mask_len = min(prompt_len, len(labels))
labels[:mask_len] = -100
return {
"input_ids": input_ids,
"labels": labels,
# attention_mask由DataCollator自动生成,这里不需要手动写
}
def sft_train():
train_dataset = OptimizedSFTDataset(data_path, tokenizer, max_len=1024)
data_collator = DataCollatorForSeq2Seq(
tokenizer=tokenizer,
padding=True,
pad_to_multiple_of=8 # 对齐显存
)
dataloader = DataLoader(train_dataset, batch_size=4, shuffle=True, collate_fn=data_collator)
pass
得到input_ids和labels之后,除了训练的超参数以外,其它的过程就和预训练的时候一模一样了!微调时候的learning_rate要比预训练的时候小,因为该阶段的任务并不是注入新的知识,而是让模型学习聊天模板。一般来说,预训练的学习率设置为3e-4,那么微调的学习率可以设置为5e-5。
请注意,Completions only并不是必须的操作,这样操作只是为了加快微调速度。
3 Catastrophic Forgetting
遗忘灾难:当拿大量的医学数据微调大模型,它医学变强了,但可能不会写代码了,或者英文通用对话能力变差了。也就是预训练的知识库被“覆盖”掉了一部分,学了前面忘了后面。这就是为什么微调的学习率要比预训练的学习率低。除此之外,还有一些缓解遗忘的办法:
- 数据回放replay:在微调数据中掺杂一些通用预训练的数据,比如占10%~20%;
- 训练轮次epoch少一些,不要过拟合了。
暂时就只想到这么多…
4 🤗工具库trl的使用
如果需要多卡分布式训练,可以使用HF提供的trl(Transformer Reinforcement Learning)库,底层都已经帮你封装好了。
NEFTune技巧
Noisy Embeddings for Fine Tuning,这是一种正则化的手段,论文《NEFTUNE: NOISY EMBEDDINGS IMPROVE INSTRUCTION FINETUNING》。即微调的过程中,向模型的Embedding层注入随机噪声,比如Normal Noise。这样做的目的是防止过拟合,因为微调的epochs一般会大于1,模型很容易背答案。让输入变模糊一点,模型依然能够根据上文推断而正确输出,能增强模型的泛化能力,就像计算机视觉里面那样的操作。这是一种较新的trick,已经集成在HF的trl库中。
具体操作如下:模型的Embedding层(nn.Embedding)参数矩阵为 X \boldsymbol X X,那么
X n o i s y = X + ϵ ⋅ E , \boldsymbol X_{noisy}=\boldsymbol X+\epsilon\cdot \boldsymbol \Epsilon, Xnoisy=X+ϵ⋅E,
其中 E ∼ U ( − ϵ , ϵ ) \boldsymbol \Epsilon\sim U(-\epsilon,\epsilon) E∼U(−ϵ,ϵ),即服从 − ϵ ∼ ϵ -\epsilon\sim \epsilon −ϵ∼ϵ均匀分布的噪声,和 X \boldsymbol X X的形状一样, ϵ \epsilon ϵ是缩放因子:
ϵ = α S ⋅ d m o d e l , \epsilon=\frac{\alpha}{\sqrt{S\cdot d_{model}}}, ϵ=S⋅dmodelα,
其中 α \alpha α是超参数,通常取 5 , 10 , 15 5,10,15 5,10,15。
将噪声挂载到model的Embedding上去,手动实现
def activate_neftune(model, noise_alpha=5.0):
def neftune_forward_hook(module, args, output):
"""
output: Embedding层的输出
"""
if module.training:
# HF的trl实现中,缩放因子没有乘batch
dims = torch.tensor(output.size(1) * output.size(2), device=output.device)
mag_norm = noise_alpha / torch.sqrt(dims)
noise = torch.zeros_like(output).uniform_(-mag_norm, mag_norm)
# detach()确保噪声本身不参与梯度更新,只影响后续层的梯度
return output + noise.detach()
return output
# 大多数HF模型可以通过get_input_embeddings()获取
embeddings = model.get_input_embeddings()
# 注册hook,把hook句柄存下来,如果需要移除可以用handle.remove()
embeddings.register_forward_hook(neftune_forward_hook)
return model
当然也可以使用model.base_model.model.model.embed_tokens(input_ids)获取Embedding层输出,将噪声加上去,只不过需要在训练循环中每次取一个batch都需要这样操作。
👎 实际上用了这个方法不一定会有效果。
使用SFTTrainer微调
trl库的深坑:
- HF的SFTTrainer强依赖于它自己定义的datasets库,所以不要使用
torch.utils.data中的Dataset,得使用datasets.Dataset.from_list构造数据集,否则配置不兼容。 - 🐞DataCollatorForCompletionOnlyLM问题:这个数据类已经在0.20.0版本后被移除了,应该使用SFTConfig中的completion_only_loss参数来配置是否计算指令部分的loss。如果现在(时间点2026.1.7)问AI,它死活不会承认这个错误。
- 如果要使用继承
PreTainedModel的自定义模型,需要先注册。比如在继承了PretrainedConfig的模型配置类TinyLLMConfig中,属性设置model_type = 'tinyllm',那么就可以将“tinyllm”这个名字使用AutoConfig注册,生命周期随脚本程序的完成而结束。这是显式告诉transformers库:当看到model_type=‘tinyllm’ 时,请使用我的TinyLLMConfig和TinyLLMForCausalLM类。
from transformers import AutoConfig, AutoModelForCausalLM
# 自定义的模型
from model.configuration_tinyllm import TinyLLMConfig
from model.model_tinyllm import TinyLLMForCausalLM
try:
AutoConfig.register("tinyllm", TinyLLMConfig)
AutoModelForCausalLM.register(TinyLLMConfig, TinyLLMForCausalLM)
print("✅ 自定义模型tinyllm注册成功!")
except ValueError:
print("❗ 模型可能已注册,跳过。")
这里就不展示调用库函数训练的代码了,因为更新速度太快了,可能因为版本的不一致导致代码不通用的问题。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 12
12 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)