GitHub前沿----视觉大爆发!从4D生成(NitroGen)到智能分层(Qwen),再到AI操控UI(A2UI) [特殊字符]
摘要:AI生成技术正从静态内容迈向深度交互时代。NitroGen突破4D生成瓶颈,实现高保真动态资产创建;Qwen-Image-Layered创新生成可编辑分层图像,解放设计师生产力;A2UI开创GUI智能操作,让AI像人类一样操作手机界面。这三个开源项目分别解决了3D/4D生成质量、图像可编辑性和界面智能操作三大难题,标志着AI视觉技术正从"观看"向"行动"
摘要:AI 仅仅生成一张 JPG 图片的时代已经过去。2026 年的开源界正在向更深度的“控制力”进军。本文深度解读三个硬核项目:让视频生成迈向4D的 NitroGen,能生成可编辑 PSD 图层的 Qwen-Image-Layered,以及不仅能看还能帮你点击屏幕的 GUI 智能体 A2UI。
🚀 前言:从“生成”到“操控”
在 Stable Diffusion 和 Midjourney 卷完画质之后,开发者们开始思考三个更难的问题:
-
怎么生成高质量的动态 3D/4D 内容?
-
生成的图片能不能自动分层,方便设计师修改?
-
AI 能不能像人一样看着屏幕操作手机?
今天的三个主角,正是为了回答这三个问题而生。
1. NitroGen: 重新定义 4D 内容生成 🌪️
项目地址:http://github.com/MineDojo/NitroGen
NitroGen 是近期备受关注的生成式模型,它致力于解决 3D/4D 生成中的质量与一致性问题。
-
核心痛点:以往的 Text-to-3D 生成速度慢,且纹理往往模糊不清;视频生成虽然火热,但缺乏三维空间的一致性。
-
黑科技:NitroGen 采用了一种新颖的生成范式(通常基于高斯泼溅 3DGS 或改进的扩散模型),能够直接从文本提示生成具有高保真纹理和动态效果的 4D 资产。
-
应用场景:
-
游戏开发:快速生成游戏内的动态道具。
-
VR/AR:低成本构建沉浸式环境。
-

💡 评价:NitroGen 代表了生成式 AI 从“平面”向“立体空间”迈进的重要一步,对于元宇宙开发者来说是必看项目。
2. Qwen-Image-Layered: 设计师的救星 🖌️
项目地址:http://github.com/QwenLM/Qwen-Image-Layered
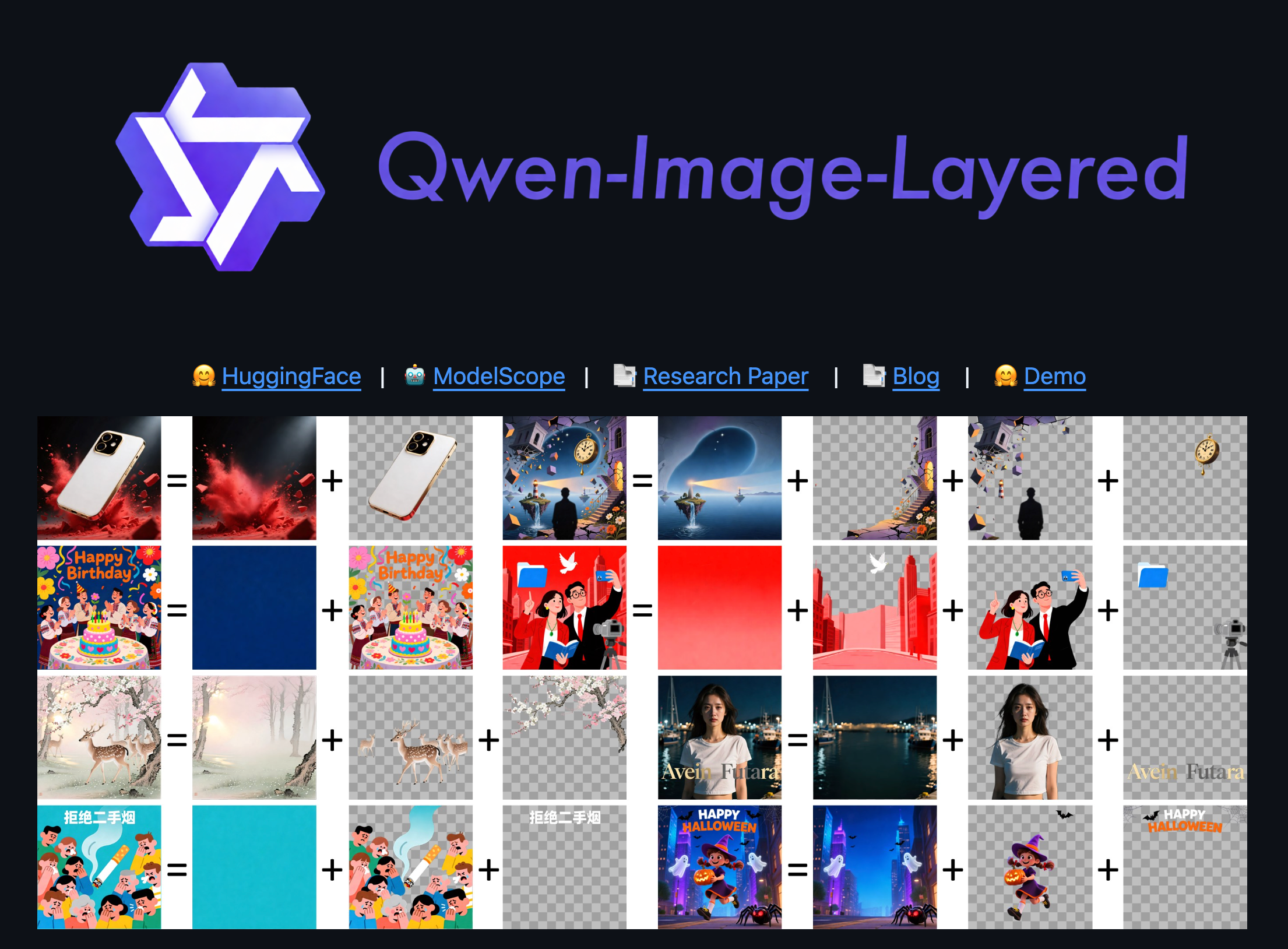


如果你用过 SD 生成图片,就知道最大的痛点是——它是一张“死图”。你想改背景?想移动人物?必须去抠图。
Qwen-Image-Layered 基于强大的 Qwen 多模态能力,做了一件伟大的事:生成带图层的图像。
-
原理:利用大模型对图像元素的理解能力,在生成过程中自动识别前景、背景、文字和装饰元素,并将其输出为分层结构。
-
实战价值:
-
它可以直接输出类似 PSD 的逻辑结构。
-
你可以单独替换背景,而不影响前景人物的光影。
-
-
部署简述: 基于 HuggingFace Transformers 库,加载 Qwen-VL 相关微调模型即可体验。
3. A2UI: AI Agent to UI (让 AI 替你玩手机) 📱
项目地址:http://github.com/google/A2UI

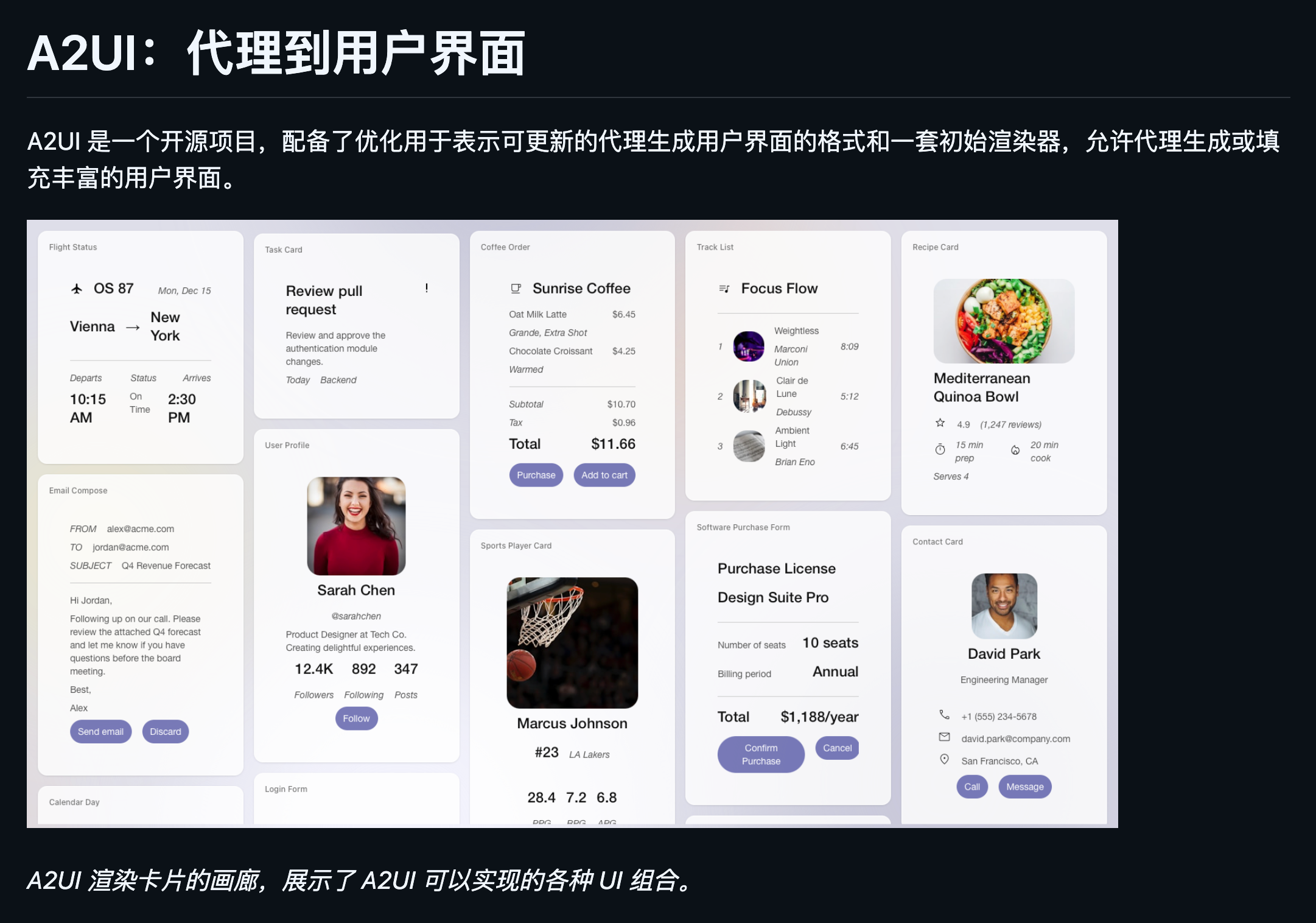

如果说前两个是生成内容,A2UI 就是在操作世界。这是一个多模态 Agent 框架,专注于理解 GUI(图形用户界面)并执行操作。
-
它能做什么?
-
给定一个指令:“帮我给妈妈发微信说晚上不回家吃饭”。
-
A2UI 会识别手机屏幕上的微信图标 -> 点击 -> 找到妈妈 -> 输入文字 -> 发送。
-
-
核心技术:
-
屏幕解析:OCR + 视觉检测,识别按钮和输入框。
-
动作规划:将人类指令拆解为 Click, Scroll, Type 等原子操作。
-
-
意义:它是未来“AI 手机”的雏形。有了 A2UI,RPA(自动化流程)将不再需要写死脚本,而是基于视觉的智能操作。
🎯 总结
-
想做 3D/VR 内容?关注 NitroGen。
-
做设计工具或可编辑生成?研究 Qwen-Image-Layered。
-
想开发手机自动化助手?A2UI 是最佳参考。
视觉 AI 正在从“观看”走向“行动”,这三个项目就是最好的证明。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 6
6 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)