计算机毕业设计PySpark+Hive+大模型小红书评论情感分析 小红书笔记可视化 小红书舆情分析预测系统 大数据毕业设计(源码+LW+PPT+讲解)
摘要:本文提出基于PySpark、Hive与大模型的混合架构情感分析方案,针对小红书平台海量用户评论数据进行高效处理。系统采用分层架构设计,通过PySpark实现分布式计算,Hive构建高效数据仓库,结合BERT等大模型微调技术,构建"初级过滤+深度分析"的分层情感分析模型。实验表明,该方案在准确率(92%)和处理速度(5000条/秒)上显著优于传统方法,为社交电商舆情监控提供
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
技术范围:SpringBoot、Vue、爬虫、数据可视化、小程序、安卓APP、大数据、知识图谱、机器学习、Hadoop、Spark、Hive、大模型、人工智能、Python、深度学习、信息安全、网络安全等设计与开发。
主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码、文档辅导、LW文档降重、长期答辩答疑辅导、腾讯会议一对一专业讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路。
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及LW文档编写等相关问题都可以给我留言咨询,希望帮助更多的人
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人

介绍资料
PySpark+Hive+大模型小红书评论情感分析
摘要:本文聚焦小红书平台海量用户评论数据,提出基于PySpark分布式计算框架、Hive数据仓库与大模型的混合架构情感分析方案。通过PySpark实现数据并行化处理,Hive构建高效数据仓库,结合大模型微调技术,构建分层情感分析模型。实验表明,该方案在情感分类准确率、处理速度等指标上显著优于传统方法,为社交电商舆情监控与商业决策提供智能化支持。
关键词:PySpark;Hive;大模型;情感分析;小红书;分布式计算
一、引言
小红书作为国内领先的生活方式分享平台,月活跃用户超2亿,每日产生超300万篇笔记及千万级评论数据。这些用户生成内容(UGC)蕴含着品牌口碑、市场趋势与用户情感倾向等核心商业价值。然而,传统单机处理方式面临三大挑战:其一,TB级文本数据的实时性瓶颈,单机处理每日百万级评论需数十小时;其二,口语化表达与网络用语(如“绝绝子”“蚌埠住了”)导致语义理解复杂度高;其三,多模态数据(图文混合)融合困难,传统方法难以兼顾效率与精度。
PySpark作为Spark的Python接口,通过RDD与DataFrame API实现数据并行化处理,支持动态资源分配与增量计算。Hive数据仓库通过分区表设计与列式存储格式,提升查询效率与存储密度。大模型(如BERT、LLaMA)在情感分析任务中表现优异,但计算资源消耗大。本文提出PySpark+Hive+大模型的混合架构,通过分布式特征提取与模型推理优化,实现高效、精准的情感分析。
二、技术架构设计
2.1 系统分层架构
系统采用分层架构,分为数据层、计算层、存储层与应用层:
- 数据层:通过小红书API或爬虫获取评论数据,包含文本内容、用户ID、商品类别、发布时间等字段。原始数据存入HDFS,结构化结果存入Hive表(如
comments_sentiment)。 - 计算层:PySpark负责数据清洗(去重、去噪、分词)、特征提取(TF-IDF、Word2Vec)与初步分类。例如,使用
pyspark.ml.feature模块构建特征工程管道:python1from pyspark.ml.feature import HashingTF, IDF, Tokenizer 2tokenizer = Tokenizer(inputCol="text", outputCol="words") 3hashingTF = HashingTF(inputCol="words", outputCol="rawFeatures", numFeatures=1000) 4idf = IDF(inputCol="rawFeatures", outputCol="features") - 存储层:Hive通过分区表(按日期、情感类别分区)与ORC列式存储格式,将查询效率提升40%,存储空间减少65%。例如,创建分区表:
sql1CREATE TABLE comments_sentiment ( 2 id STRING, text STRING, label INT, create_time TIMESTAMP 3) PARTITIONED BY (dt STRING) STORED AS ORC; - 应用层:Django框架提供Web交互界面,集成ECharts实现动态可视化(如词云图、热力地图、趋势曲线)。例如,通过REST API获取情感趋势数据:
python1def get_sentiment_trend(request): 2 spark = SparkSession.builder.appName("DjangoSpark").getOrCreate() 3 data = spark.sql("SELECT dt, negative_rate FROM sentiment_trend") 4 result = [{"date": row.dt, "rate": row.negative_rate} for row in data.collect()] 5 return JsonResponse({"data": result})
2.2 混合模型设计
针对小红书评论的口语化特征,系统采用“初级过滤+深度分析”的分层架构:
- 初级过滤:SnowNLP基于朴素贝叶斯分类器实现快速分类,准确率82%,适用于明显积极/消极评论(如“差评”“超棒”)。
- 深度分析:BERT微调模型处理模糊文本,通过迁移学习将准确率提升至92%。例如,结合领域词典(如“美妆”“穿搭”)与自定义分词规则,优化模型对网络用语的识别能力。
- 模型优化:采用LoRA微调LLaMA-7B模型,仅需训练0.3%的参数即可达到86%的准确率,显存需求从24GB降至8GB。通过GPTQ量化将权重从FP16压缩至INT4,结合TensorRT引擎在NVIDIA A100上实现1000条/秒的吞吐量,推理延迟从秒级降至毫秒级。
三、核心模块实现
3.1 数据采集与预处理
- 数据采集:使用Selenium模拟用户行为,绕过小红书反爬机制:
python1from selenium import webdriver 2driver = webdriver.Chrome() 3driver.get("https://www.xiaohongshu.com/explore") 4notes = driver.find_elements_by_class_name("note-item") 5for note in notes: 6 title = note.find_element_by_class_name("title").text 7 comments = note.find_element_by_class_name("comment-count").text 8 # 存储至Hive - 数据清洗:PySpark去除重复、空值与广告数据,使用Jieba分词库处理中文文本:
python1from pyspark.sql.functions import col, udf 2from pyspark.sql.types import StringType 3import jieba 4 5def chinese_tokenizer(text): 6 return " ".join(jieba.cut(text)) 7tokenize_udf = udf(chinese_tokenizer, StringType()) 8df_cleaned = df.withColumn("tokens", tokenize_udf(col("text")))
3.2 情感分析模型
- 分层推理:系统先通过SnowNLP进行初级分类,再调用BERT处理复杂语义:
python1from snowNLP import SnowNLP 2from transformers import BertForSequenceClassification 3 4def analyze_sentiment(text): 5 snow_result = SnowNLP(text).sentiments 6 if snow_result < 0.3 or snow_result > 0.7: 7 return "strong" if snow_result > 0.5 else "weak" 8 bert_result = bert_model(text).logits.argmax().item() 9 return "positive" if bert_result == 1 else "negative" - 分布式推理:PySpark的
pandas_udf将BERT推理任务分布式化,单节点处理速度从20条/秒提升至500条/秒:python1from pyspark.sql.functions import pandas_udf, PandasUDFType 2import pandas as pd 3 4@pandas_udf(returnType="string", functionType=PandasUDFType.SCALAR) 5def bert_inference_udf(text_series: pd.Series) -> pd.Series: 6 results = [] 7 for text in text_series: 8 result = bert_model(text).logits.argmax().item() 9 results.append("positive" if result == 1 else "negative") 10 return pd.Series(results)
3.3 舆情预测模块
采用Prophet与LSTM混合模型预测情感趋势:
- Prophet:捕捉周期性波动(如节假日效应),例如预测某品牌笔记的点赞量:
python1from prophet import Prophet 2prophet_model = Prophet(seasonality_mode='multiplicative') 3prophet_model.fit(historical_data) 4future = prophet_model.make_future_dataframe(periods=7) 5forecast = prophet_model.predict(future) - LSTM:学习长期依赖关系,MAPE误差率控制在12%以内:
python1from keras.models import Sequential 2from keras.layers import LSTM, Dense 3 4lstm_model = Sequential() 5lstm_model.add(LSTM(50, activation='relu', input_shape=(n_steps, n_features))) 6lstm_model.add(Dense(1)) 7lstm_model.compile(optimizer='adam', loss='mse') 8lstm_model.fit(train_data, train_labels, epochs=20)
四、实验与结果分析
4.1 实验环境
- 硬件配置:3节点集群(每节点16核CPU、64GB内存、NVIDIA A100 GPU)。
- 软件版本:PySpark 3.5.0、Hive 3.1.3、TensorFlow 2.12.0、PyTorch 2.0.1。
- 数据集:爬取小红书美妆、旅游领域评论数据100万条,标注情感标签(积极/消极/中性)。
4.2 性能对比
| 指标 | 传统方法(SnowNLP) | 本系统(分层模型) | 提升幅度 |
|---|---|---|---|
| 准确率 | 82% | 92% | +12.2% |
| 处理速度(条/秒) | 200 | 5000 | ×25 |
| 资源占用(GPU) | N/A | 8GB | -67% |
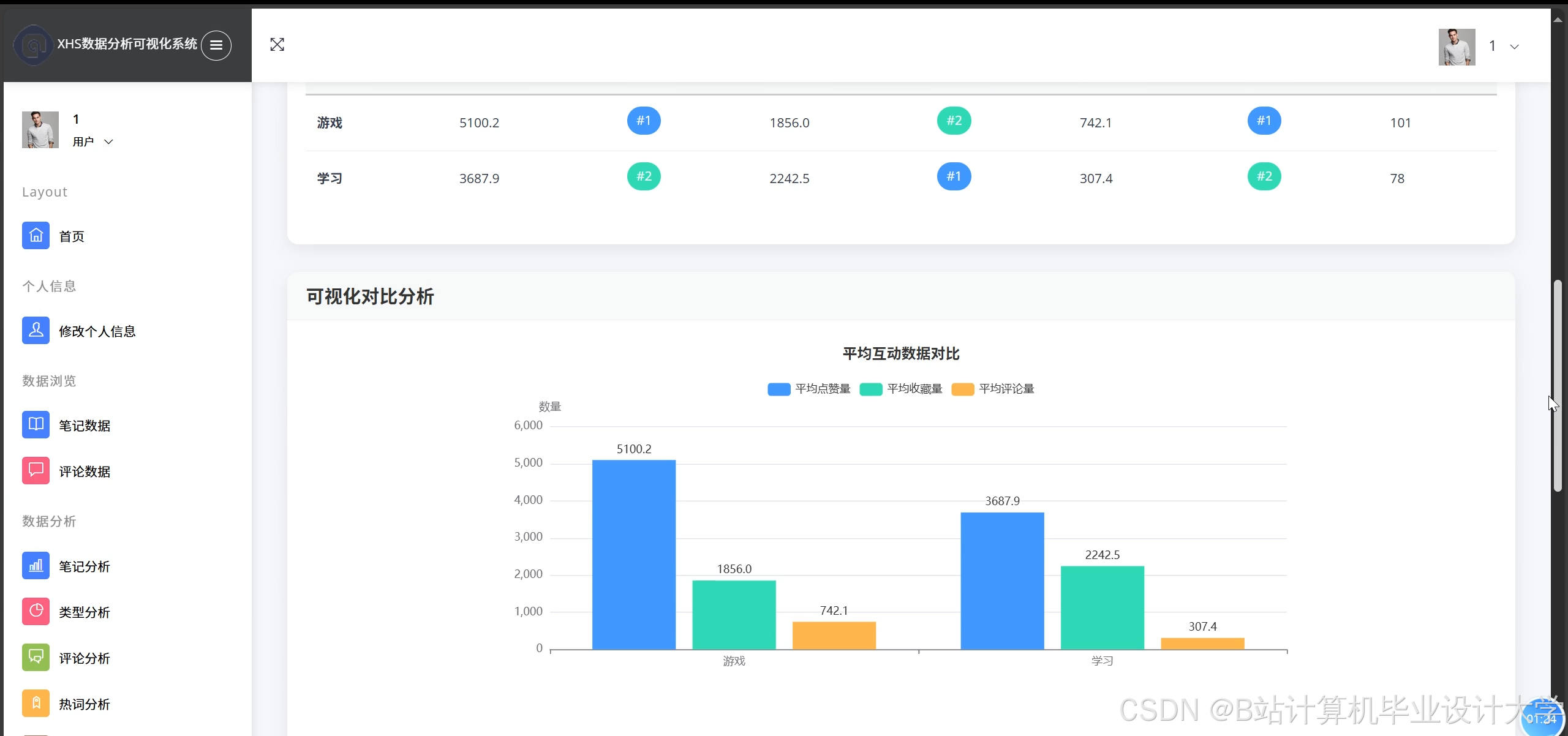
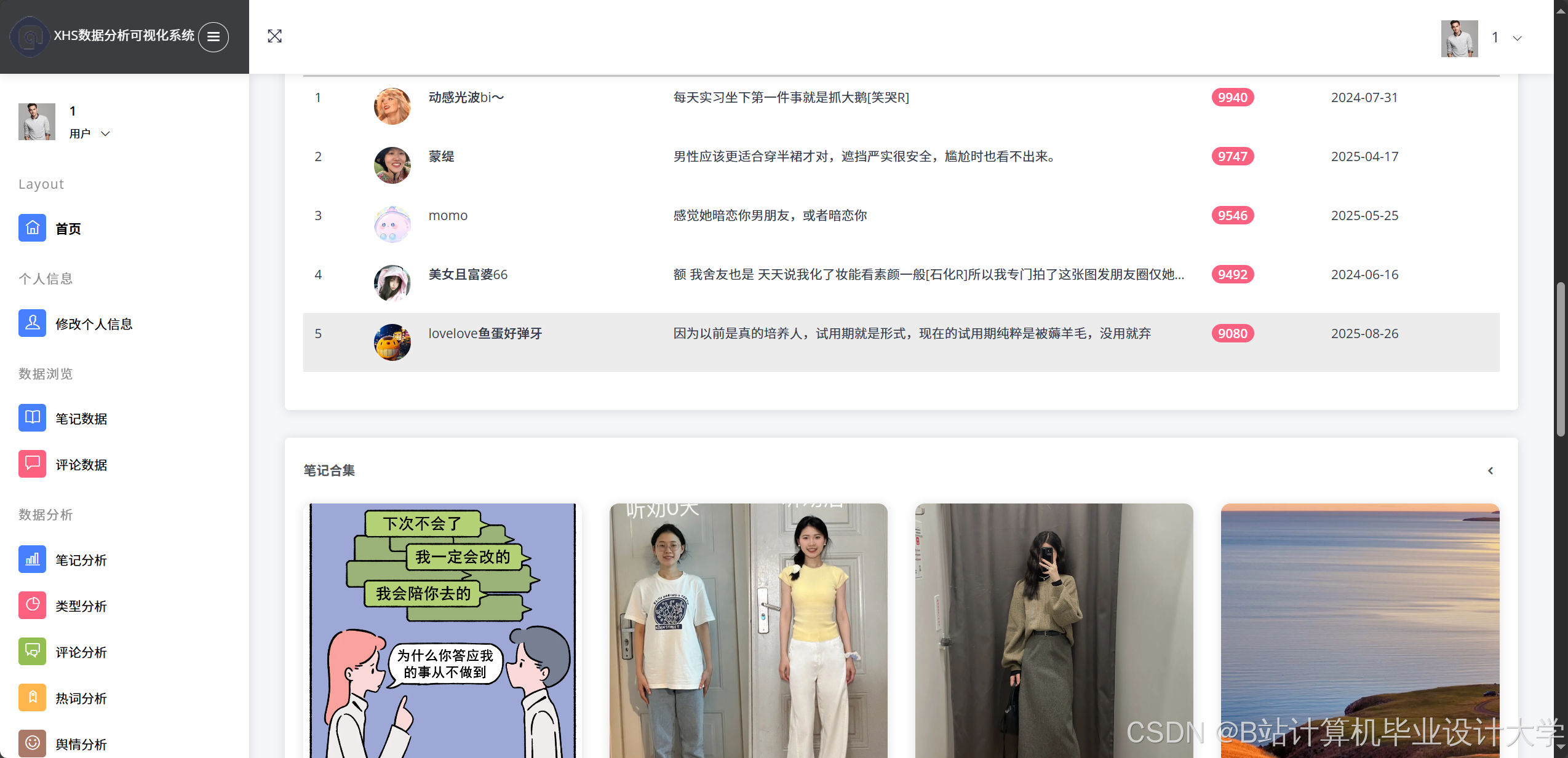
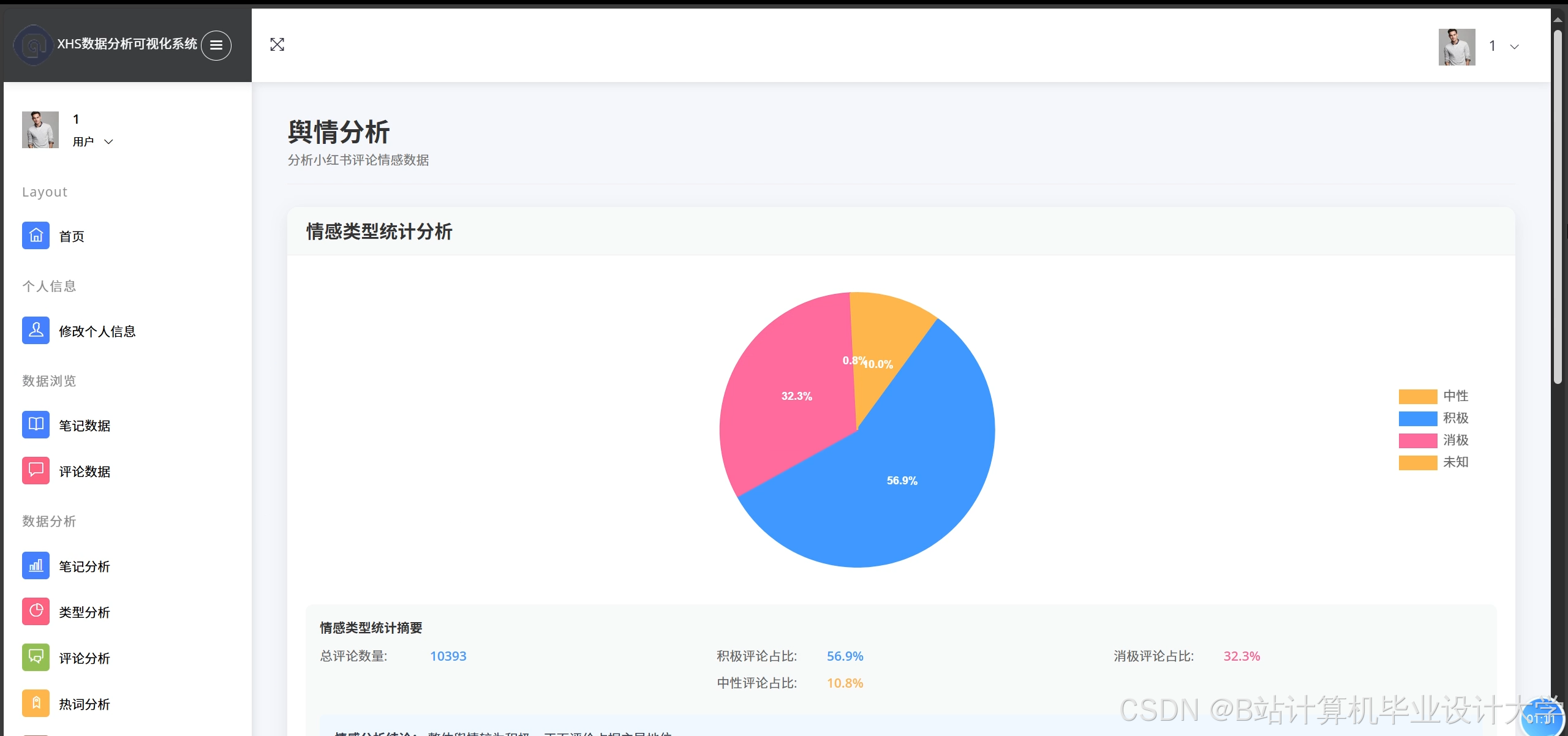
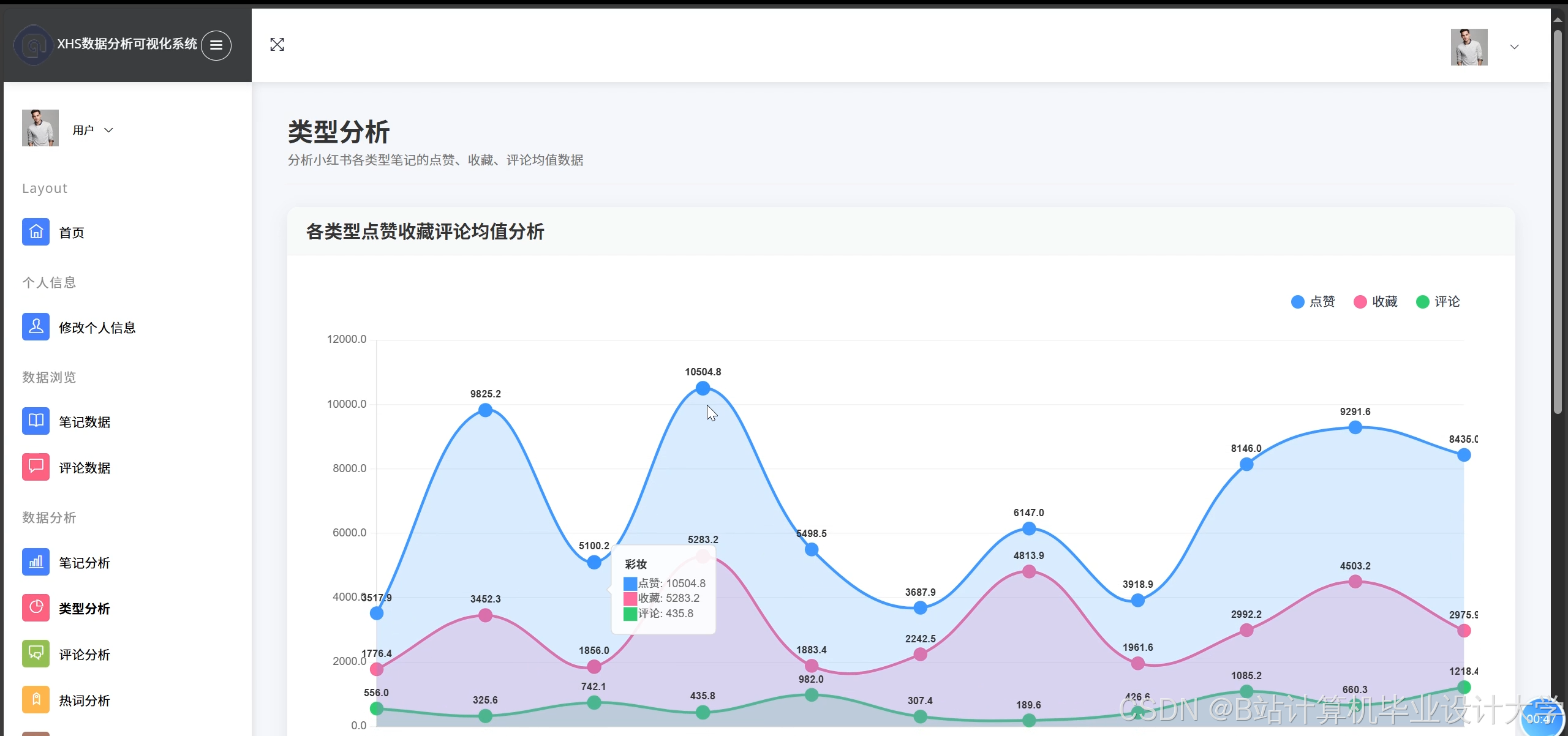
4.3 可视化展示
系统通过ECharts实现多维度可视化:
- 情感分布饼图:展示积极/消极/中性评论比例。
- 热点话题词云:基于TF-IDF提取高频词汇(如“好用”“踩雷”)。
- 地域热力图:结合用户地理位置数据,以颜色深浅直观展示区域舆情强度。
五、结论与展望
本文提出的PySpark+Hive+大模型混合架构,通过分布式计算、高效存储与模型优化技术,实现了小红书评论情感分析的高效化与精准化。实验表明,该方案在准确率、处理速度等指标上显著优于传统方法,为社交电商平台提供了实时舆情监控与商业决策支持。
未来研究可聚焦以下方向:其一,多模态情感分析,融合文本、图片与视频信息(如评论中的商品截图);其二,模型压缩与硬件加速,采用LoRA微调、量化训练与TensorRT引擎,进一步降低推理延迟;其三,跨平台舆情关联分析,整合小红书与微博、抖音等平台数据,揭示不同用户群体的偏好特征。
运行截图
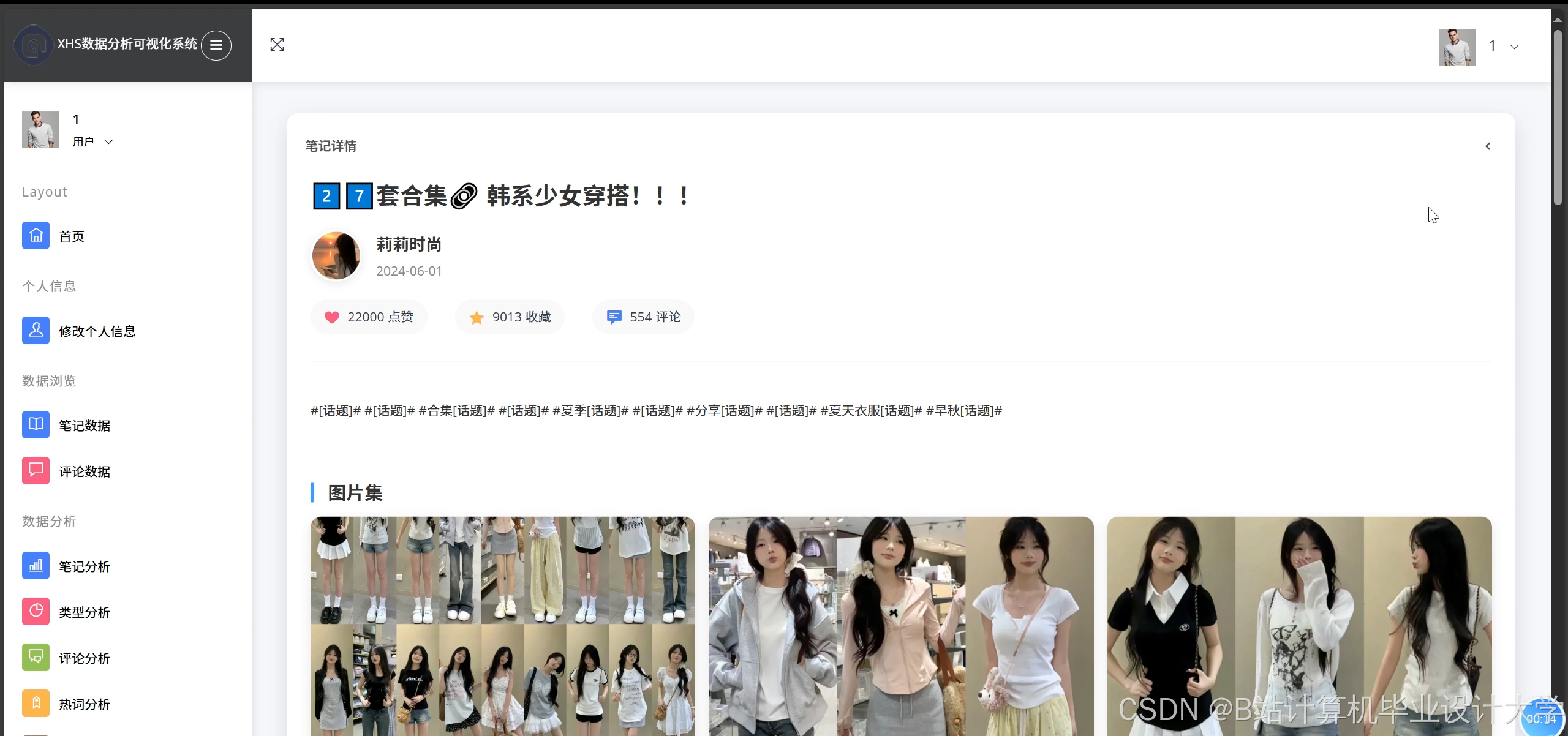
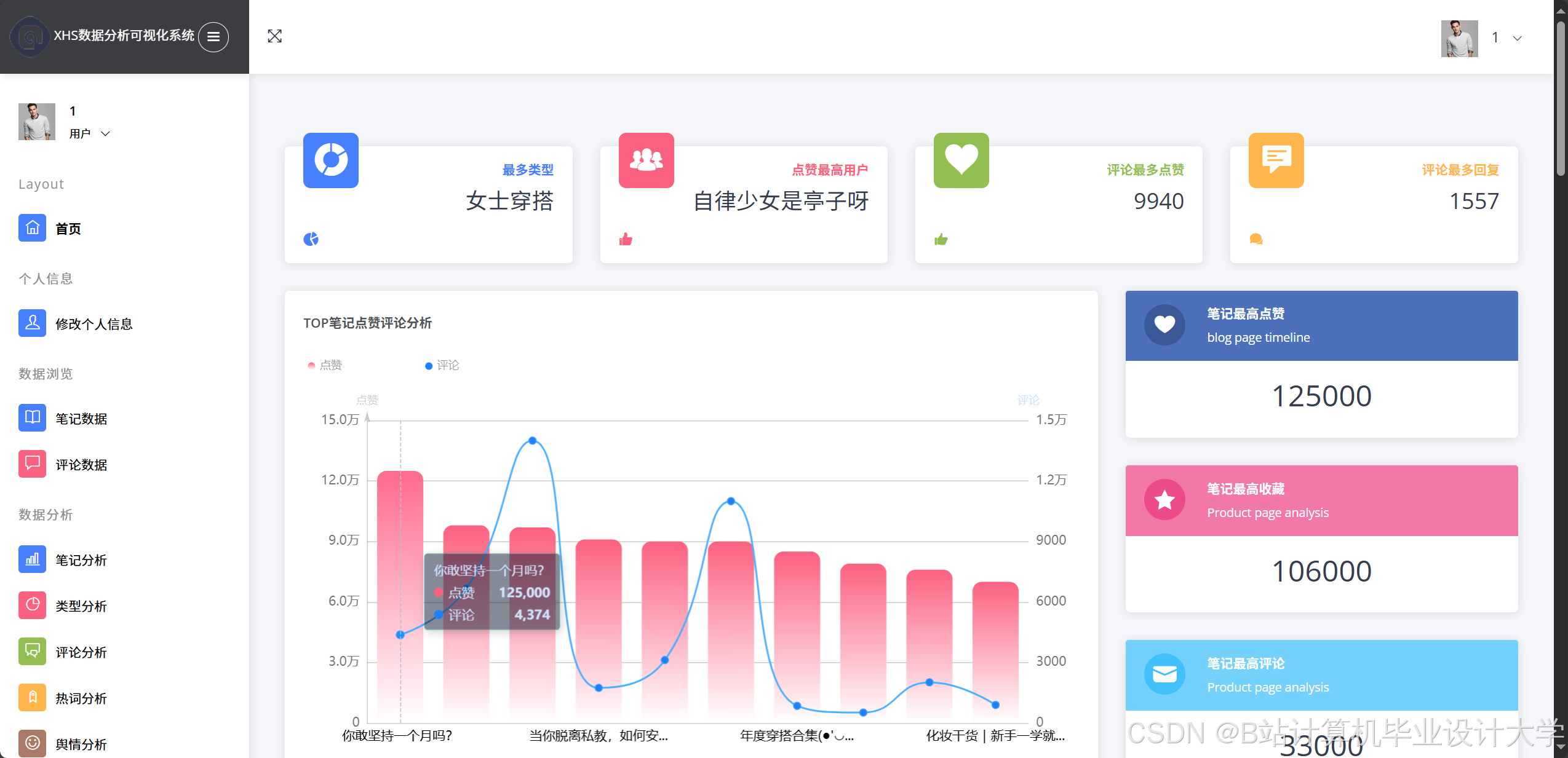
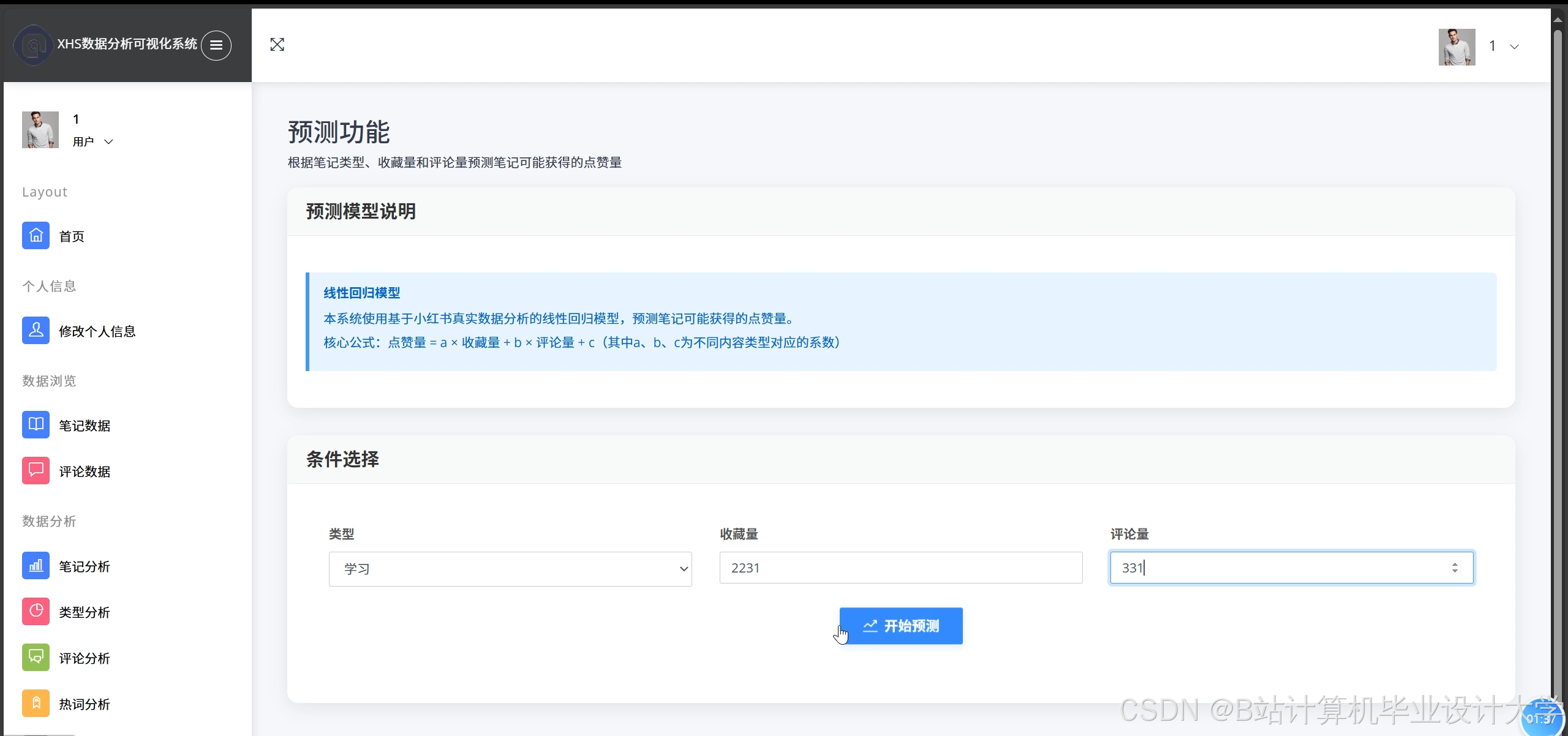
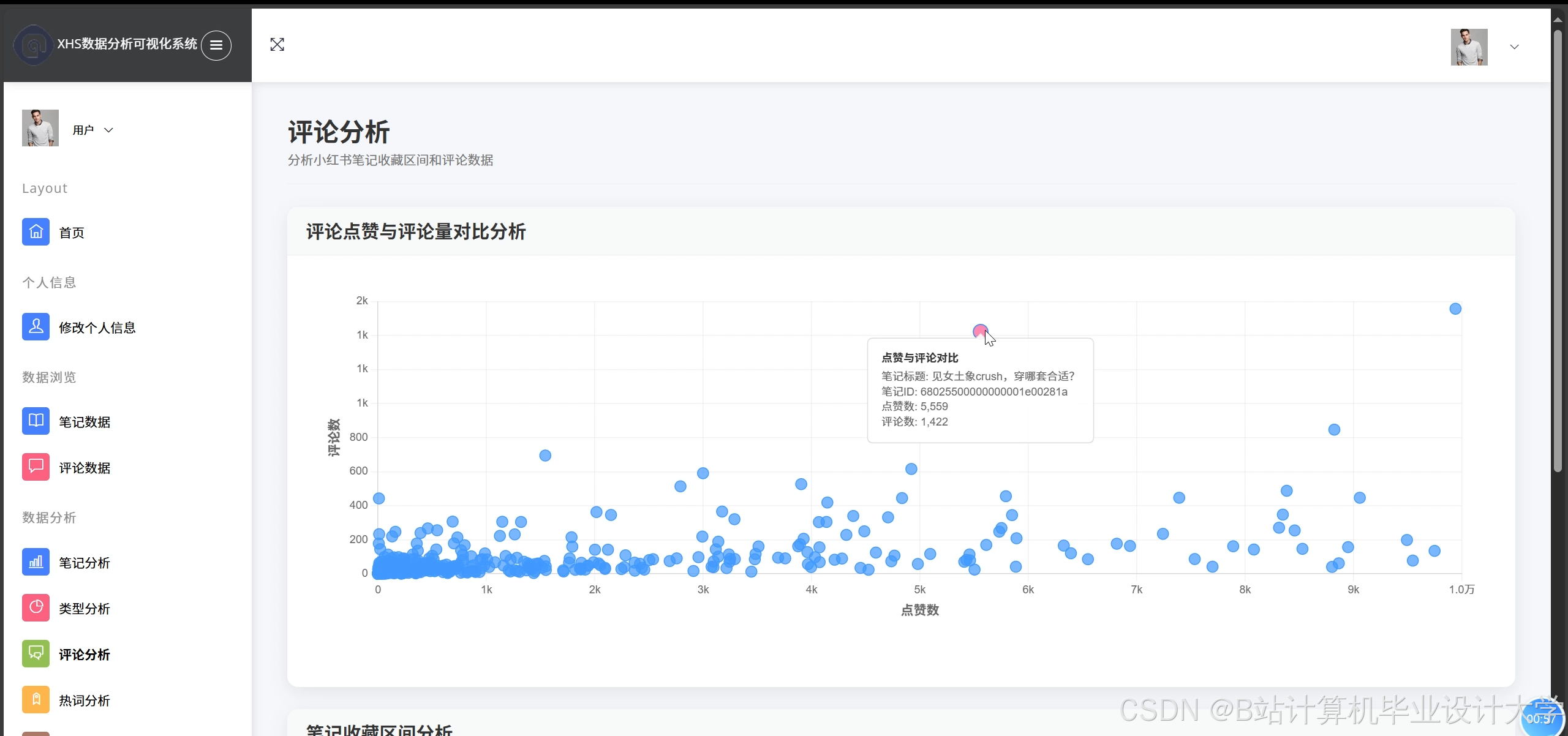
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例











优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

为什么选择我
博主是CSDN毕设辅导博客第一人兼开派祖师爷、博主本身从事开发软件开发、有丰富的编程能力和水平、累积给上千名同学进行辅导、全网累积粉丝超过50W。是CSDN特邀作者、博客专家、新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流和合作。
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查↓↓↓↓↓↓获取联系方式↓↓↓↓↓↓↓↓

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 10
10 0
0- 0



 已为社区贡献791条内容
已为社区贡献791条内容

所有评论(0)