揭秘提示词工程背后的秘密:提示词工程为啥是工程?
本文通过AI Humanizer项目案例,探讨提示词工程的本质。文章指出,虽然网上存在大量现成提示词,但真正的工程化需要系统方法论:从检测AI生成内容的原理分析(困惑度与爆发性指标),到基于结构语言学的四层架构设计(词汇、短语、句法、语篇),再到具体技巧选择(如Domain-Hopping和Verbalized Sampling)和验证迭代流程。最终说明,提示词工程的价值不在于简单复制粘贴,而在于
网上经常有人发效果很惊艳的提示词,比如:
- **「李继刚」**的系列提示词
- 去年17岁高中生让
Claude3.5拥有推理能力的提示词 - 各类知名应用(比如
Cursor、V0…)的系统提示词
这些提示词只需要复制粘贴就能为我们所用。
甚至日常需要写提示词的场景,也可以交给模型自己完成,也就是**「生成提示词的提示词」**,俗称元提示词。
既然提示词门槛这么低,为何还要叫工程呢?
本文通过一个实际例子和你交流这个话题。
Humanizer项目
最近在做AI Humanizer,也就是**「去除文章 AI 味儿,让文章能过各种 AI检测的工具」**。
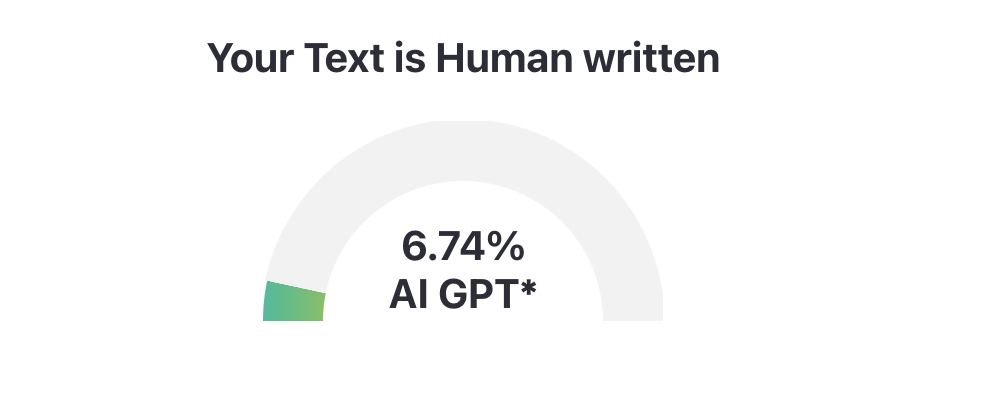
项目的最佳方案是**「模型微调」**,但由于训练集的准备需要时间,所以第一版打算通过提示词工程解决。
既然最终目标是过检测,那就需要了解各种检测器的工作原理。
先用Grok(深度搜索方面做的不错)检索**「检测AI生成内容」**相关论文:
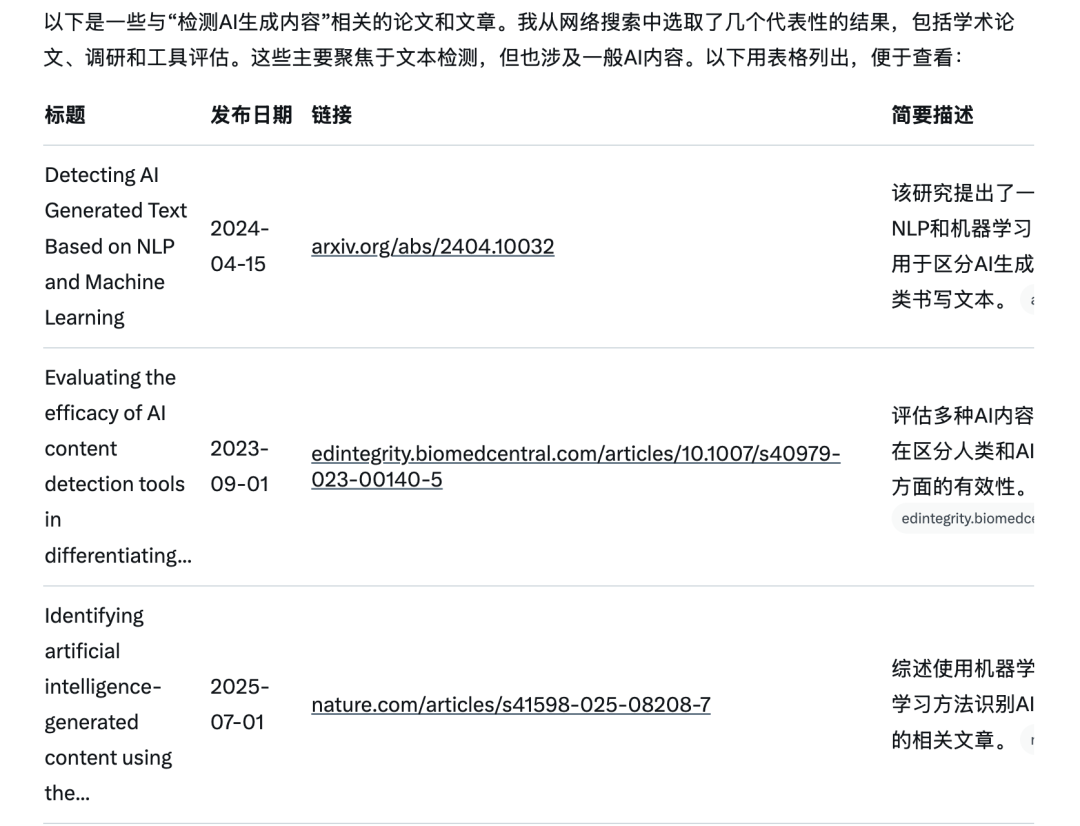
再把论文都丢给Gemini2.5-pro(文科强、上下文大),总结工作原理。
简单来说,有两个指标最重要:
- 困惑度:衡量模型对一段文本感到惊讶(还能这么选词?)程度的指标,举例:
低困惑度The house is big. The door is red. I like the big house with the red door.高困惑度That sprawling edifice, with its crimson entryway, evokes a certain arcane charm I find myself inexplicably drawn to.
- 爆发性:衡量文本中句子长度和结构的变化程度,它描述了文本节奏的“起伏感”,举例:
低爆发性The mountain is tall and majestic. The river flows through the valley. The forest is dense with green trees. The sky is blue with white clouds.高爆发性Look. The summit. After days of relentless climbing, it pierces the clouds—a jagged, defiant pinnacle against the endless blue. What a view.
低困惑度 + 低爆发性 = 文章读起来非常流畅,但每个句子都像是一个模子刻出来的,没什么惊喜和变化
较高困惑度 + 较高爆发性 = 文章中既有简单直白的短句,也有结构复杂的长句,用词更加灵活多变,充满个人风格
总结来说,一个句子的AI率,是其所有组成部分(词汇、句式、结构)困惑度与爆发性的加权总和。
这就是我们提示词工程的优化方向。
工程架构以及选型
我们可以将一段内容按**「结构语言学」**划分为4个层次:
- 词汇
- 短语
- 句法
- 语篇:在特定语境下,为达到一定交际目的而说出或写出的、在意义和结构上连贯的语言整体
我们的目标是**「设计囊括上述4个纬度的提示词,提高内容困惑度与爆发性」**。
接下来需要用到许多提示词技巧,以我曾尝试过的一些技巧举例。
词汇层面的提示词技巧
要提高词汇的困惑度,最简单粗暴的提示词是:
请将内容中的所有词汇都替换为更不常见的高深词汇
甚至,你可以让模型故意生成词不达意或者拼写错误的词汇,这能进一步提高困惑度。
但这有两个问题:
- 会让文章质量劣化
- 模型内部在处理**「将词汇替换为高深词汇」时,最终输出的
token仍是「高深词汇中概率较高的那些词」**
所以,虽然能骗过类似zerogpt这样的低阶检测器,但并不是最优解。
这里有个适合的技巧**「Domain-Hopping」**(领域跳跃)。
即:从一个完全不相关的领域借用一个精确术语,来比喻性地描述当前的概念,比如:
- 原始词汇:
complex interactions(复杂的互动) - 跳跃到
音乐领域:the internal orchestration of the system(系统内容编排) - 跳跃到
生物学领域:ecosystem
这种**「替换同义词的技巧」**能在提高困惑度的同时保持词汇层面的内容质量。
短语层面的提示词技巧
短语层面也与词汇层面面临同样的问题(实际上所有层面都面临)。
即:你指挥模型做的任何修改,本质来说都是模型在预测下一个token时的高概率选择。
在高阶检测器面前,困惑度仍然不高。
为了对抗检测,除了调用模型API时通过传参(temperature、top-p/k、presence_penalty…)干预,提示词技巧层面也有些不错的选择。
论文Verbalized Sampling: How to Mitigate Mode Collapse and Unlock LLM Diversity[1]提出一种可行的技巧**「Verbalized Sampling」**(口头抽样)。
提示词如下:
For each query, please generate a set of five possible responses, each within a separate tag. Responses should each include a and a numeric . Please sample at random from the [full distribution / tails of the distribution, such that the probability of each response is less than 0.10].User prompt:
翻译过来就是:
- 对于每次查询,模型生成五个可能的回复
- 回复放在**「response」**标签中,包含回复内容和概率值
- 输出那些概率值小于 0.1 的回复
这样能显著改善模型输出的多样性。
假设输入词汇Important,获得如下结果:
<response> <probability>0.09</probability> <text>Essential</text></response> <response> <probability>0.08</probability> <text>Significant</text></response><response> <probability>0.07</probability> <text>Vital</text></response><response> <probability>0.06</probability> <text>Critical</text></response><response> <probability>0.05</probability> <text>Imperative</text></response>
如果取概率最小(0.05)的值,那么Important会被替换为Imperative。
相比于被替换为Essential或Significant,困惑度有所提高。
4. 语篇层面的提示词技巧
相比词汇、短语、句法这些聚焦在单个句子上的约束,**「语篇」**的定义更宏观。
所以我们需要更宏观的处理方法。
一种可行的方式是**「人格化」,即:让模型扮演某个「在他训练语料中有详尽资料的名人」**,以这个名人的口吻在某个场景(酒吧、演播厅…)下把内容复述一遍。
相比于模型直接生成内容的平铺直叙,人格化后的内容通常爆发性更高(有节奏变换)。
工程迭代
以上仅仅完成了:
- 工程框架设计(遵循结构语言学)
- 工程技术选型(每个架构层面的技巧选择)
接下来才是真正考验工程能力的时候。
随便抛几个具体问题:
- 是否词汇、短语、句法层面的技巧都要使用,还是只针对某个层面优化?
- 模型注意力有限,使用**「口头抽样」**时给多少备选项合适?
- 是否应该将提示词拆分成工作流,每个阶段完成一个层面的处理?
- **「人格化」**该用哪个名人?
这些问题都需要验证。
所以,接下来还要建立一套提示词猜想、验证、迭代的流程。
猜想
上述提出的猜想是**「一套建立在结构语言学上的分层处理逻辑」**。
实际上,还能从音系、形态、语义、语用等多个角度建立框架,每个框架又能延伸出不同的提示词技巧选择。
再到**「人格化」**的例子,如果改写内容是偏理性(比如学生论述作业)场景,可能会尝试如下名人:
- 琼·蒂蒂安:“新新闻主义”的代表人物
- 大卫·爱登堡:BBC纪录片旁白
- 摩根·弗里曼:演员
等等…
验证
验证过程就是建立一条流水线:
- AI生成内容
- 内容经过当前架构处理
- 输出的内容给到检测器评估质量
这里有很多工程细节需要考虑,比如:检测器没对外提供API时,是否需要用技术手段解决?
迭代
根据验证结果,从上往下可能依此调整:
- 是否换用新的架构
- 架构的哪些层面需要处理,哪些需要放弃
比如,在我们例子中,「词汇与短语层面的改动」会自动影响到「句子层面的改动」。
所以,可以减少关注句子这一层面。
- 这一层面用什么提示词技巧处理,参数是否需要调整?
比如,词汇层面是否也能应用**「口头抽样」**,抽样样本设置多少好。
- 当前模型是否能处理如此复杂的提示词,是要换更先进模型,还是拆分成多步骤处理的工作流
总结
通过上述过程我们可以发现,虽然最终产物可能就是一段平平无奇的提示词,但整个过程是个完整的工程化流程。
这也是为什么很多公司在招提示词工程师。
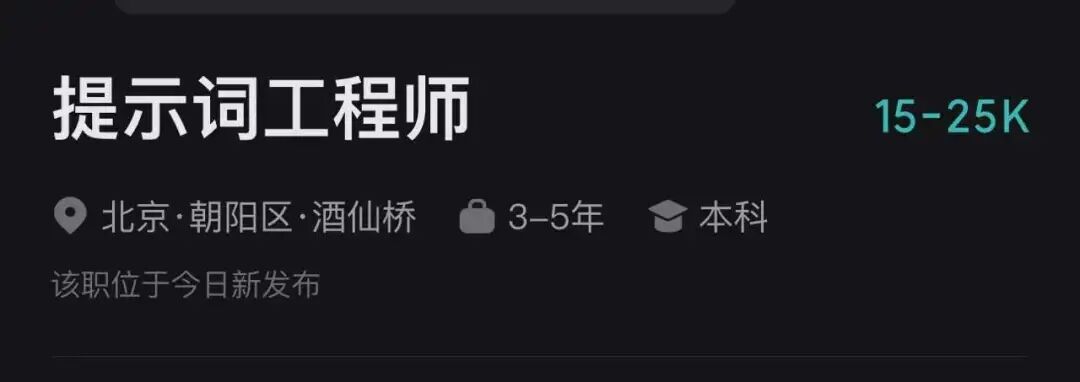
在提示词工程师的JD中,普遍要求**「深度理解提示词工程原理,能够使用提示工程工具进行系统化调优和设计」**。
如何学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

学习路线

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 22
22 0
0- 0



 已为社区贡献187条内容
已为社区贡献187条内容

所有评论(0)