大模型核心技术详解:词嵌入与注意力机制零基础入门指南!
文章介绍了大模型的两大基础概念:词嵌入将token转换为向量表示,维度越多表达越准确;注意力机制计算token间的注意力分数,确定其在句子中的比重并生成句子嵌入向量。文中提供了完整代码示例,指出词嵌入随机生成会导致理解不一致的问题,将在自注意力机制章节解决。同时提供了AI大模型学习资源包,适合不同基础的学习者。
简介
文章介绍了大模型的两大基础概念:词嵌入将token转换为向量表示,维度越多表达越准确;注意力机制计算token间的注意力分数,确定其在句子中的比重并生成句子嵌入向量。文中提供了完整代码示例,指出词嵌入随机生成会导致理解不一致的问题,将在自注意力机制章节解决。同时提供了AI大模型学习资源包,适合不同基础的学习者。

词嵌入
我们在第一章《中文词元分词器(tokenizer)》介绍如何将中文转为计算机能识别的token。我们让计算机认识token,但它还不知道每个token代表什么意思,这时候需要使用词嵌入的向量让计算机理解token的意思。
举个例子:
现在有二维的词嵌入的向量。一维表达的意思人、二维表达的意思是狗。当输入给计算机的词嵌入向量是[0.98, 0.01]。计算机就知道了输入的token大概率是表示人、小概率表示狗。
总结:词嵌入的向量维度越多,能表达的意思就越多。计算机分析和理解token的意思就越准确。
注意力机制
本次讲解是注意力机制,是后续理解自注意力机制的基础。
举个例子理解注意力:
有一段话:我今天7点半就起床,起床后洗脸刷牙就去上学了,现在我可以零食吗?
- 计算机对句子转为token,句子包含标点一共32字符,转为32个token。
- 计算机将token转为词嵌入向量(为了让计算机理解对应token的含义)。
- 计算每个token与其他token的注意力分数,从而计算出每个token在句中的比重。
- 最后计算出句子的嵌入向量(句子的意思)
完整代码如下:
import torch
inputs = torch.tensor([[0.3936, 0.6935, 0.3348], # 我
[0.5026, 0.0071, 0.5896], # 今
[0.2907, 0.6760, 0.8077], # 天
[0.9242, 0.1073, 0.6657], # 7
[0.8128, 0.5948, 0.5048], # 点
[0.1761, 0.8408, 0.7777], # 半
[0.8356, 0.9191, 0.4877], # .....
[0.8127, 0.6945, 0.1638],
[0.5169, 0.0480, 0.3206],
[0.3588, 0.7753, 0.0601],
[0.3240, 0.6933, 0.1227],
[0.7708, 0.2641, 0.2991],
[0.3765, 0.7601, 0.6736],
[0.0479, 0.2822, 0.1667],
[0.1870, 0.6520, 0.8656],
[0.1334, 0.1281, 0.0567],
[0.1888, 0.1180, 0.6571],
[0.1636, 0.4993, 0.0752],
[0.0736, 0.7483, 0.6709],
[0.2390, 0.2805, 0.2577],
[0.3149, 0.2716, 0.5238],
[0.3102, 0.9780, 0.5683],
[0.4659, 0.1817, 0.1224],
[0.2379, 0.5396, 0.0403],
[0.9871, 0.6437, 0.9737],
[0.0191, 0.7601, 0.4134], # ...
[0.5452, 0.1432, 0.0804], # 可
[0.0876, 0.3709, 0.5346], # 以
[0.2683, 0.4359, 0.4126], # 零
[0.0344, 0.3399, 0.4594], # 食
[0.8824, 0.8529, 0.4762], # 吗
[0.9383, 0.4208, 0.1570]]) # ?
print(f'输入张量的结构:{inputs.shape}')
# 计算注意力分数
attention_score = inputs @ inputs.T
# 计算注意力比重
attention_weight = torch.softmax(attention_score, dim = -1)
print(f'注意力比重的结构:{attention_weight.shape}')
print(f'注意力比重:{attention_weight}')
# 计算上下文向量分数
context_vec_score = torch.zeros(inputs.shape)
for i, x_i in enumerate(attention_weight):
for j, x_j in enumerate(x_i):
context_vec_score[i] += x_j * inputs[j]
# 计算上下文向量比重
context_vec_weight = torch.softmax(context_vec_score, dim = -1)
print(f'上下文向量比重结构:{context_vec_weight.shape}')
print(f'上下文向量比重:{context_vec_weight}')
执行后结果如下:
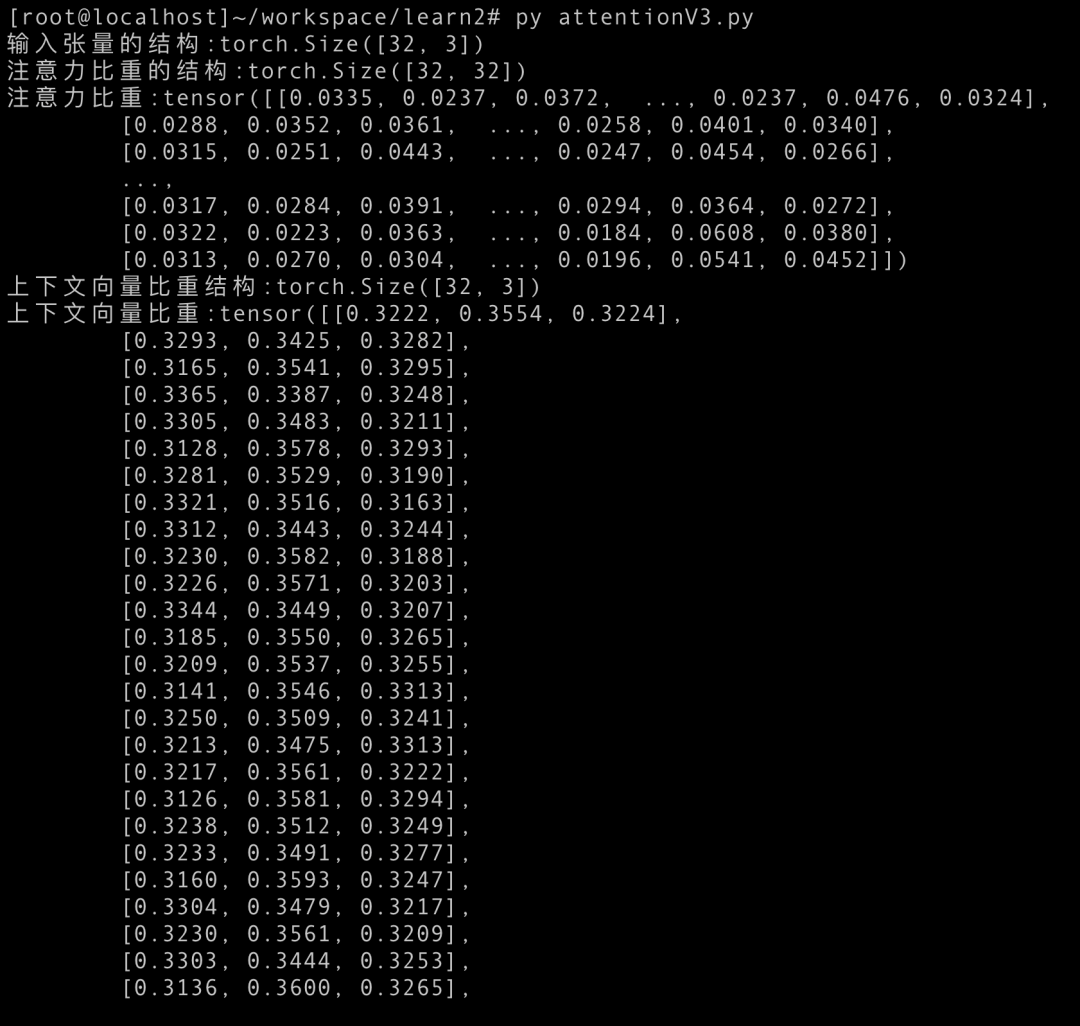
因为句子的嵌入向量依赖最开始的词嵌入的向量。词嵌入的向量是随机生成的,导致计算机每次理解就不一样了。下一章介绍自注意力的时候会解决该问题。
如何学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

学习路线

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 18
18 0
0- 0



 已为社区贡献187条内容
已为社区贡献187条内容

所有评论(0)