【AI课程领学】第七课 · 数据扩充与预处理(课时2) 特殊的数据扩充方式:MixUp/CutMix、RandAugment、Mosaic、时序增强与“遥感/科学数据”增强(含代码)
【AI课程领学】第七课 · 数据扩充与预处理(课时2) 特殊的数据扩充方式:MixUp/CutMix、RandAugment、Mosaic、时序增强与“遥感/科学数据”增强(含代码)
·
【AI课程领学】第七课 · 数据扩充与预处理(课时2) 特殊的数据扩充方式:MixUp/CutMix、RandAugment、Mosaic、时序增强与“遥感/科学数据”增强(含代码)
【AI课程领学】第七课 · 数据扩充与预处理(课时2) 特殊的数据扩充方式:MixUp/CutMix、RandAugment、Mosaic、时序增强与“遥感/科学数据”增强(含代码)
欢迎铁子们点赞、关注、收藏!
祝大家逢考必过!逢投必中!上岸上岸上岸!upupup
大多数高校硕博生毕业要求需要参加学术会议,发表EI或者SCI检索的学术论文会议论文。详细信息可扫描博文下方二维码 “
学术会议小灵通”或参考学术信息专栏:https://ais.cn/u/mmmiUz
详细免费的AI课程可在这里获取→www.lab4ai.cn
前言
当你已经掌握了翻转旋转这类“简单增强”,下一步会遇到问题:
- 模型仍然对分布漂移敏感、对小样本/长尾类不稳、对遮挡与噪声鲁棒性不足。
- 此时就需要更“结构化”的增强策略,它们往往能显著提升泛化,但也更容易踩坑。
这一篇我们分 5 类来讲:
- 样本混合类:MixUp / CutMix
- 自动化策略:RandAugment / AutoAugment
- 目标检测常用:Mosaic / Copy-Paste
- 时序数据增强:抖动、缩放、时间扭曲、遮挡
- 遥感/科学数据增强:多光谱一致性、云遮挡模拟、辐射扰动
1. MixUp:在输入与标签空间做线性插值
MixUp 的思想:
- 随机取两张样本 ( x i , y i ) , ( x j , y j ) (x_i,y_i),(x_j,y_j) (xi,yi),(xj,yj)
- 生成新样本:
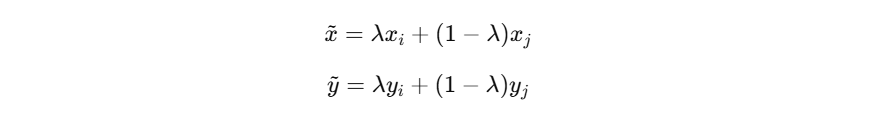
- 其中 λ ∼ B e t a ( α , α ) λ∼Beta(α,α) λ∼Beta(α,α);它的本质是“让决策边界更平滑”,减少过拟合。
1.1 PyTorch 实现(分类)
import torch
import torch.nn.functional as F
def mixup_data(x, y, alpha=0.2):
if alpha <= 0:
return x, y, y, 1.0
lam = torch.distributions.Beta(alpha, alpha).sample().item()
batch_size = x.size(0)
index = torch.randperm(batch_size).to(x.device)
mixed_x = lam * x + (1 - lam) * x[index]
y_a, y_b = y, y[index]
return mixed_x, y_a, y_b, lam
def mixup_loss(logits, y_a, y_b, lam):
return lam * F.cross_entropy(logits, y_a) + (1 - lam) * F.cross_entropy(logits, y_b)
- 训练时:
# x: (B,C,H,W), y: (B,)
x_mix, y_a, y_b, lam = mixup_data(x, y, alpha=0.2)
logits = model(x_mix)
loss = mixup_loss(logits, y_a, y_b, lam)
实践建议:
- 小数据集、强模型(ResNet/ViT)通常收益明显
- 对细粒度分类要谨慎(MixUp 会混合局部纹理导致标签含糊)
2. CutMix:用区域裁剪替代线性叠加
- CutMix 从一张图中剪一块矩形区域贴到另一张图上,并按面积比例混合标签:
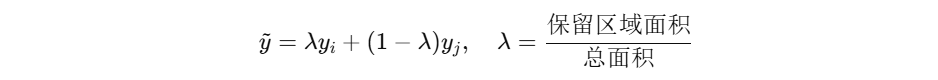
- 它比 MixUp 更符合“物体遮挡/拼接”的真实情况。
2.1 PyTorch 实现(分类)
import numpy as np
def rand_bbox(W, H, lam):
cut_rat = np.sqrt(1. - lam)
cut_w = int(W * cut_rat)
cut_h = int(H * cut_rat)
cx = np.random.randint(W)
cy = np.random.randint(H)
x1 = np.clip(cx - cut_w // 2, 0, W)
y1 = np.clip(cy - cut_h // 2, 0, H)
x2 = np.clip(cx + cut_w // 2, 0, W)
y2 = np.clip(cy + cut_h // 2, 0, H)
return x1, y1, x2, y2
def cutmix_data(x, y, alpha=1.0):
lam = np.random.beta(alpha, alpha)
B, C, H, W = x.shape
index = torch.randperm(B).to(x.device)
x1, y1, x2, y2 = rand_bbox(W, H, lam)
x_cut = x.clone()
x_cut[:, :, y1:y2, x1:x2] = x[index, :, y1:y2, x1:x2]
lam = 1 - ((x2-x1) * (y2-y1) / (W * H))
y_a, y_b = y, y[index]
return x_cut, y_a, y_b, lam
3. RandAugment:用更少超参数自动搜索增强组合
RandAugment 的思路:
- 从一组预定义增强操作里随机选 N 个
- 每个操作强度由 M 控制
- 两个超参数:
N和M
在工程上比 AutoAugment 更容易用。
在 torchvision 中可直接用:
from torchvision import transforms
train_tf = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandAugment(num_ops=2, magnitude=9),
transforms.ToTensor(),
])
- 注意:对多光谱数据不一定适用,因为 RandAugment 默认针对 RGB 颜色空间设计(遥感增强要定制)。
4. 检测/分割常用:Mosaic、Copy-Paste、Random Erasing
- Mosaic:4 张图拼成 1 张,增加尺度变化与小目标数量
- Copy-Paste:把前景实例从一张图复制到另一张图(分割很常用)
- Random Erasing / Cutout:模拟遮挡
这些更偏工程实现,建议用成熟框架(MMDetection、YOLO 系列)或 albumentations 的对应实现。
5. 时序数据增强:抖动、缩放、时间扭曲、遮挡(适合传感器/气象/生态序列)
假设序列形状为 (B, T, D),常用增强:
- Jitter(加噪):模拟测量误差
- Scaling(幅值缩放):模拟传感器标定漂移
- Time warping(时间轴扭曲):模拟速度变化
- Time masking(时间遮挡):模拟缺测
5.1 PyTorch:简单时序增强函数
import torch
def ts_jitter(x, sigma=0.02):
return x + sigma * torch.randn_like(x)
def ts_scaling(x, sigma=0.1):
# 每个样本一个缩放因子
factor = torch.randn(x.size(0), 1, 1, device=x.device) * sigma + 1.0
return x * factor
def ts_time_mask(x, mask_ratio=0.1):
B, T, D = x.shape
m = int(T * mask_ratio)
if m <= 0:
return x
start = torch.randint(0, T - m + 1, (B,), device=x.device)
x2 = x.clone()
for i in range(B):
x2[i, start[i]:start[i]+m, :] = 0.0
return x2
- 训练中可随机组合:
x_aug = ts_time_mask(ts_scaling(ts_jitter(x)))
6. 遥感/科学数据增强:为什么不能直接套 RGB 增强?
遥感(尤其多光谱/高光谱)增强需要遵守物理一致性:
- 每个波段是不同波长的反射率/辐射量
- 任意颜色抖动可能破坏谱形状(导致不物理)
- 但可以做“辐射一致”的增广,例如整体增益、加性噪声、雾霾/大气散射模拟、云遮挡模拟等
6.1 一个“谱一致”的增益 + 偏置增强(多波段通用)
def spectral_affine(x, gain_sigma=0.05, bias_sigma=0.02):
"""
x: (B, C, H, W) 多波段
对每个样本施加全波段一致的 gain 与 bias(或也可对每波段独立)
"""
B, C, H, W = x.shape
gain = torch.randn(B, 1, 1, 1, device=x.device) * gain_sigma + 1.0
bias = torch.randn(B, 1, 1, 1, device=x.device) * bias_sigma
return x * gain + bias
- 如果你希望更真实,可以“每波段不同 gain”,但要限制范围,避免谱形状破坏过大。
7. 小结与选择建议
- MixUp/CutMix:提升泛化、对小样本很有效
- RandAugment:快速提升强增强能力
- 检测/分割:Mosaic/Copy-Paste 更常用
- 时序增强:缺测/噪声/漂移更贴近真实
- 遥感增强:优先物理一致(增益、噪声、遮挡模拟),谨慎 ColorJitter
下一篇进入“深度学习数据预处理”:从数据质量、归一化、数据泄漏、划分策略、到 DataLoader 性能与可复现性,给你一套可直接照抄的工程清单。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 14
14 0
0- 0



 已为社区贡献35条内容
已为社区贡献35条内容

所有评论(0)