Agent-提示链(prompt chaining)
你有没有过这样的经历?让AI写一篇带数据支撑的报告,结果它漏了关键指标;让它处理发票提取信息,输出格式混乱根本没法用;让它解答复杂问题,要么答非所问,要么满是“幻觉”?其实不是AI不够强,而是你用错了方式——。今天要讲的「提示链(Prompt Chaining)」,就是解决这个问题的核心方法论:把棘手任务拆成“流水线”,让AI一步步接力完成,既靠谱又可控。
让LLM告别“一步错全错”!提示链(Prompt Chaining):复杂任务的拆解神器
你有没有过这样的经历?让AI写一篇带数据支撑的报告,结果它漏了关键指标;让它处理发票提取信息,输出格式混乱根本没法用;让它解答复杂问题,要么答非所问,要么满是“幻觉”?
其实不是AI不够强,而是你用错了方式——复杂任务根本不能让LLM“一步到位” 。今天要讲的「提示链(Prompt Chaining)」,就是解决这个问题的核心方法论:把棘手任务拆成“流水线”,让AI一步步接力完成,既靠谱又可控。
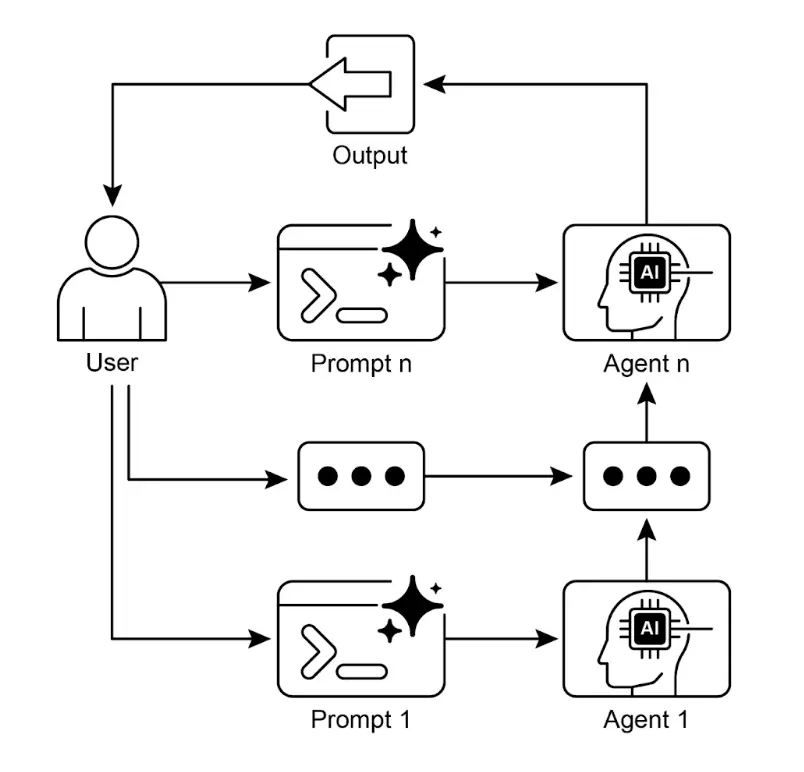
1 通俗理解:提示链到底是什么?
提示链,说白了就是「AI版流水线作业」,核心逻辑就两点:
-
分而治之:把复杂任务拆成一个个“小而聚焦”的子任务(比如“写报告”拆成“找数据→提炼观点→结构化排版”);
-
接力传递:前一个子任务的输出,直接作为下一个的输入,形成“链式依赖”,一步步逼近最终结果。
举个直观的例子:让AI写“2025母婴行业趋势邮件”,用提示链是这样的:
-
第一步:“总结这份母婴行业报告的核心数据”(输出:关键数据清单);
-
第二步:“从数据中提炼3个核心趋势”(输出:带数据支撑的趋势要点);
-
第三步:“把趋势要点写成给销售团队的简明邮件”(输出:最终邮件)。
而不是直接丢一句“写一封母婴行业趋势邮件”——这样AI不用兼顾“找数据、析趋势、写邮件”,每一步都能专注发力,准确率自然翻倍。
2 为什么一定要用提示链?单一提示的4个致命问题
很多人觉得“提示写得越详细越好”,但面对复杂任务,单一提示只会暴露LLM的短板:
-
「丢指令」:同时要求多件事,AI容易忽略关键环节(比如让它“分析+总结+写邮件”,最后漏了数据支撑);
-
「记不住」:上下文窗口有限,长文本处理时容易丢失前面的关键信息;
-
「错上加错」:一步出错全程翻车(比如数据提取错了,后面的分析和报告全白费);
-
「瞎编乱造」:复杂任务超出AI认知负荷,容易产生“幻觉”(比如编造不存在的行业数据)。
而提示链通过“拆解+接力”,完美解决这些问题:每步只做一件事,降低AI认知负担;可单独调试每一步,哪里错了改哪里;前步结果经过验证再传递,避免错误累积。
3 3个实操关键技巧:让提示链更靠谱
1. 强制结构化输出
每一步都指定输出格式(JSON/XML/表格),比如趋势提取步骤要求:
{ "trend": "趋势名称", "data": "支撑数据", "source": "数据来源" }
避免自然语言歧义,让后续步骤“看得懂、用得上”。
2. 插入验证环节
关键步骤后加“检查逻辑”,比如数据提取后验证“字段是否齐全、格式是否正确”,不合格就返回上一步重新处理,避免错误传递。
3. 善用框架简化流程
不用自己写复杂脚本,用LangChain、LangGraph、Google ADK等框架,拖拽式就能搭建提示链,还能自动集成搜索、数据库等外部工具。
5 行代码看懂提示链逻辑(非技术也能懂)
用LangChain搭建一个“提取产品参数→转为JSON”的简单提示链,核心思路一目了然:
# 1. 初始化AI模型
llm = ChatOpenAI(temperature=0)
# 2. 第一步:提取产品参数
extract_prompt = "从文本中提取CPU、内存、存储:{text}"
extract_chain = extract_prompt | llm
# 3. 第二步:转为JSON格式
json_prompt = "把参数转为JSON,含cpu、memory、storage键:{params}"
full_chain = {"params": extract_chain} | json_prompt | llm
# 4. 运行链条
result = full_chain.invoke({"text": "新款电脑:3.5GHz CPU、16GB内存、1TB存储"})
print(result)
# 输出:{"cpu":"3.5GHz","memory":"16GB","storage":"1TB"}提示链不是什么复杂技术,本质是「把复杂问题简单化」的思维方式——不让AI“一口吃成胖子”,而是让它像流水线工人一样,每次只做好一件事,通过接力完成复杂任务。
不管你是写报告、处理数据,还是做客服、搞开发,只要遇到“AI一步搞不定”的情况,试试提示链的拆解思路,你会发现AI的可靠性和效率会大幅提升。
4 上下文工程:让AI从“答问工具”升级为“懂你的伙伴”
如果说提示工程是“教AI怎么听懂单个问题”,那上下文工程就是“给AI搭建完整的信息世界”——它不是简单优化一句话的表达,而是让AI能整合所有相关信息,精准匹配你的需求,这也是普通AI工具和高级智能系统的核心区别。
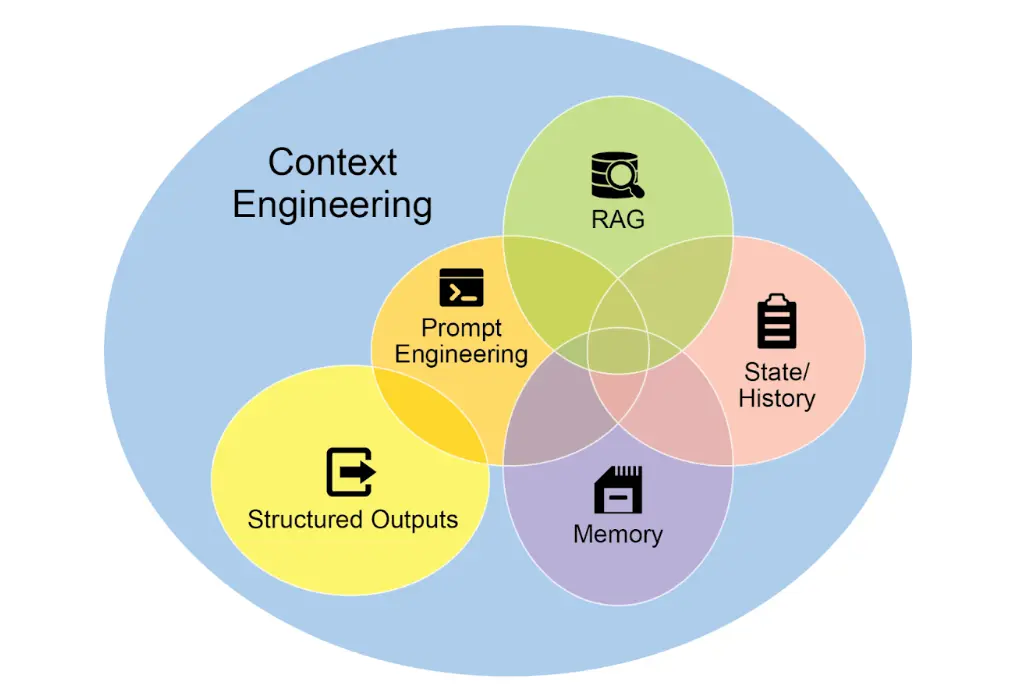
一、上下文工程:比提示工程多了“全局视野”
传统提示工程的思路很简单:把当前问题写清楚(比如“用正式语气写一封工作邮件”),但AI只知道这一个孤立指令,不知道你是谁、要发给谁、之前聊过什么。
而上下文工程是“升级玩法”,核心是给AI整合多层关键信息,让它拥有“全局视野”:
-
系统提示:给AI定身份、划边界(比如“你是职场HR,回复需专业且有温度,避免生硬术语”);
-
外部数据:让AI主动找“外援”(比如调用公司知识库查薪酬政策、用API查会议日程);
-
隐性数据:把“藏在背后”的信息补上(比如你的职位、和收件人的上下级关系、之前的沟通记录)。
简单说:提示工程让AI“听懂一句话”,上下文工程让AI“看懂一件事的来龙去脉”。哪怕是最先进的大模型,没有完整上下文,也只能给出“标准答案”,而不是“你的答案”。
二、核心价值:让AI的输出“精准踩中需求”
上下文工程的终极目标,不是让AI更“聪明”,而是让AI更“懂你”——它会为智能体构建一个“完整操作视图”,把分散的信息整合起来,生成高度个性化、实用的结果。
举个真实例子:
你让智能体帮你回复一封“关于项目延期的同事邮件”,经过上下文工程的AI会这样做:
-
先查历史交互:你们之前约定的项目节点、同事之前提过的风险点;
-
再调工具数据:查你的日程表,确认你接下来的空闲时间段;
-
补充隐性信息:你和同事是平级关系,回复需兼顾歉意和解决方案,不能推卸责任;
-
最后整合输出:既表达了对延期的歉意,又给出了具体的补工时间安排,还呼应了之前同事提到的风险,让回复既专业又有温度。
如果没有上下文工程,AI可能只生成一句“项目延期了,我们会尽快完成”——空泛又没用。
三、怎么落地?2个关键+1个实用工具
上下文工程听起来复杂,但落地核心就2点:
-
搭好“数据管道”:让AI能自动获取需要的信息(比如对接你的日程、公司知识库、聊天记录),不用手动输入;
-
建“反馈循环”:根据你的使用反馈持续优化——比如AI某次回复太生硬,下次就自动调整语气,让上下文越来越贴合你的需求。
如果不想手动折腾,还能直接用现成工具:
比如Google Vertex AI 提示优化器,只要你提供样例提示、系统指令(比如“我是市场专员,需要写推广文案”),工具会自动优化上下文输入,帮你生成更精准的AI响应,不用自己逐字修改。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 12
12 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)