自注意力机制--大模型输入的上下文【下】
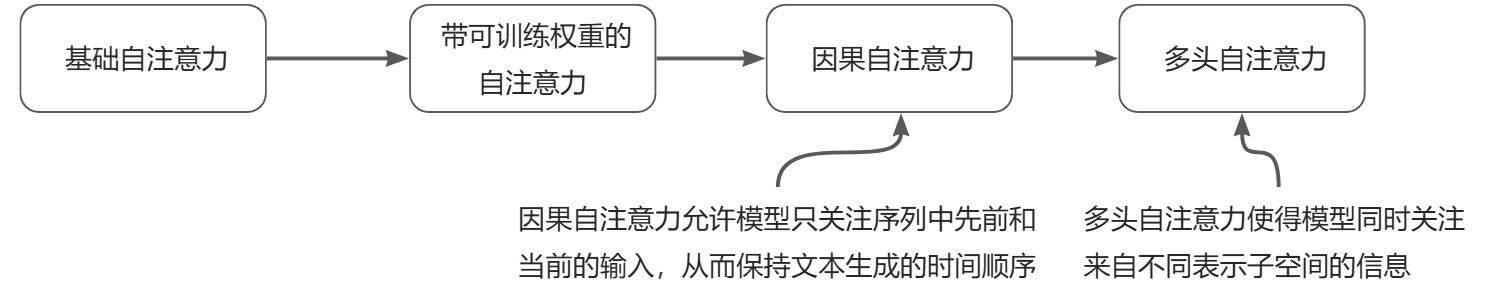
注意力机制可以将输入元素转换为增强的上下文向量表示。自注意力机制通过对输入进行加权求和来计算上下文向量表示。使用矩阵乘法替代for循环,可以提高计算效率。引入了可训练的权重矩阵来计算输入的中间变换:查询矩阵、值矩阵和键矩阵。我们从一个基础版本的自注意力机制开始,然后逐步加入可训练的权重。因果注意力机制在自注意力的基础上增加了额外掩码,使得大语言模型可以一次生成一个单词。最后,多头注意力将注意力机制
我们继续上一章的注意力机制的学习。
利用因果注意力隐藏未来词元
因果机制的作用是调整注意力机制,防止模型访问序列中未来的信息。
因果注意力(也称为掩码注意力)限制模型在处理任何给定词元时,只能基于序列中的先前和当前输入来计算注意力分数。
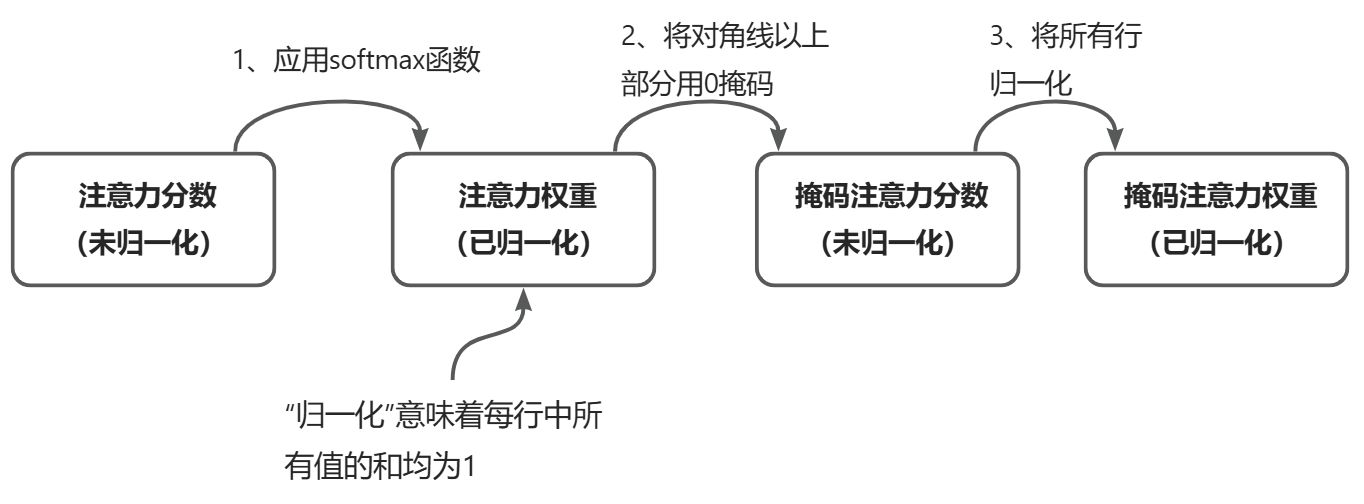
对于每个处理的词元,需要掩码当前词元之后的后续词元,我们会掩码对角线以上的注意力权重,并归一化未掩码的注意力权重,使得每一行的权重之和为1。
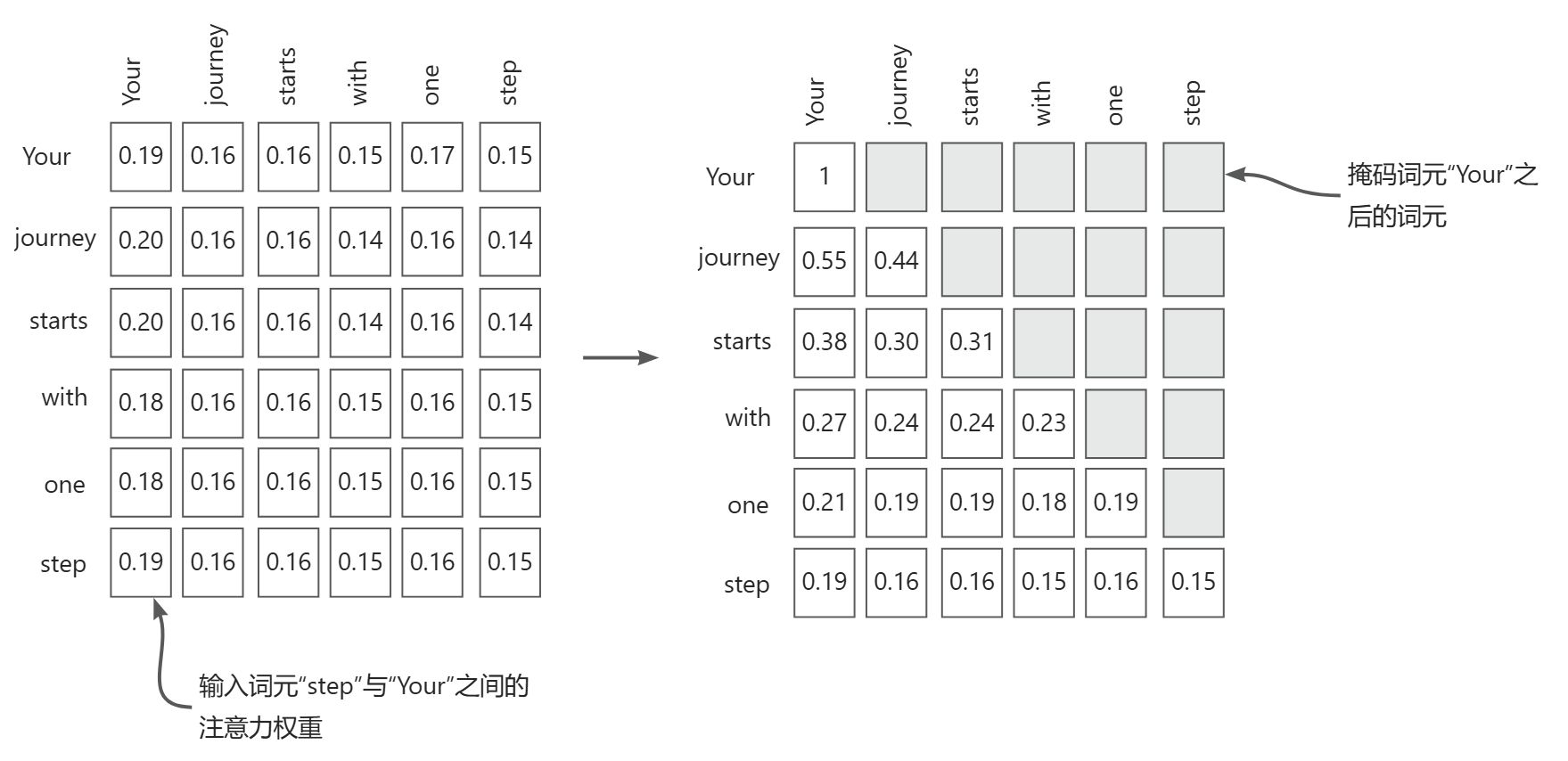
在因果注意力机制中,我们掩码了对角线以上的注意力权重,以确保在计算上下文向量时,大语言模型无法方问未来的词元。例如,对于第2行的单词"journey",仅保留当前词(“journey”)和之前词(“You”)的注意力权重。
在因果注意力中,获得掩码后的注意力权重矩阵的一种方法是对注意力分数应用 softmax函数,将对角线以上的元素清零,并对所得矩阵进行归一化。
利用 dropout 掩码额外的注意力权重
dropout 技术通过在训练过程中随机忽略一些隐藏层单元来有效地“丢弃”它们。这种方法有助于减少模型对特定隐藏层单元的依赖,从而避免过拟合。需要强调的是,dropout 仅在训练期间使用,训练结束后会被取消。
在 Transformer 架构中,一些包括 GPT 在内的模型通常会在两个特定时间点使用注意力机制中的 dropout:一是计算注意力权重之后,二是将这些权重应用于值向量之后。
我们将在计算注意力权重之后应用 dropout 掩码,因为这是实践中更常见的做法。
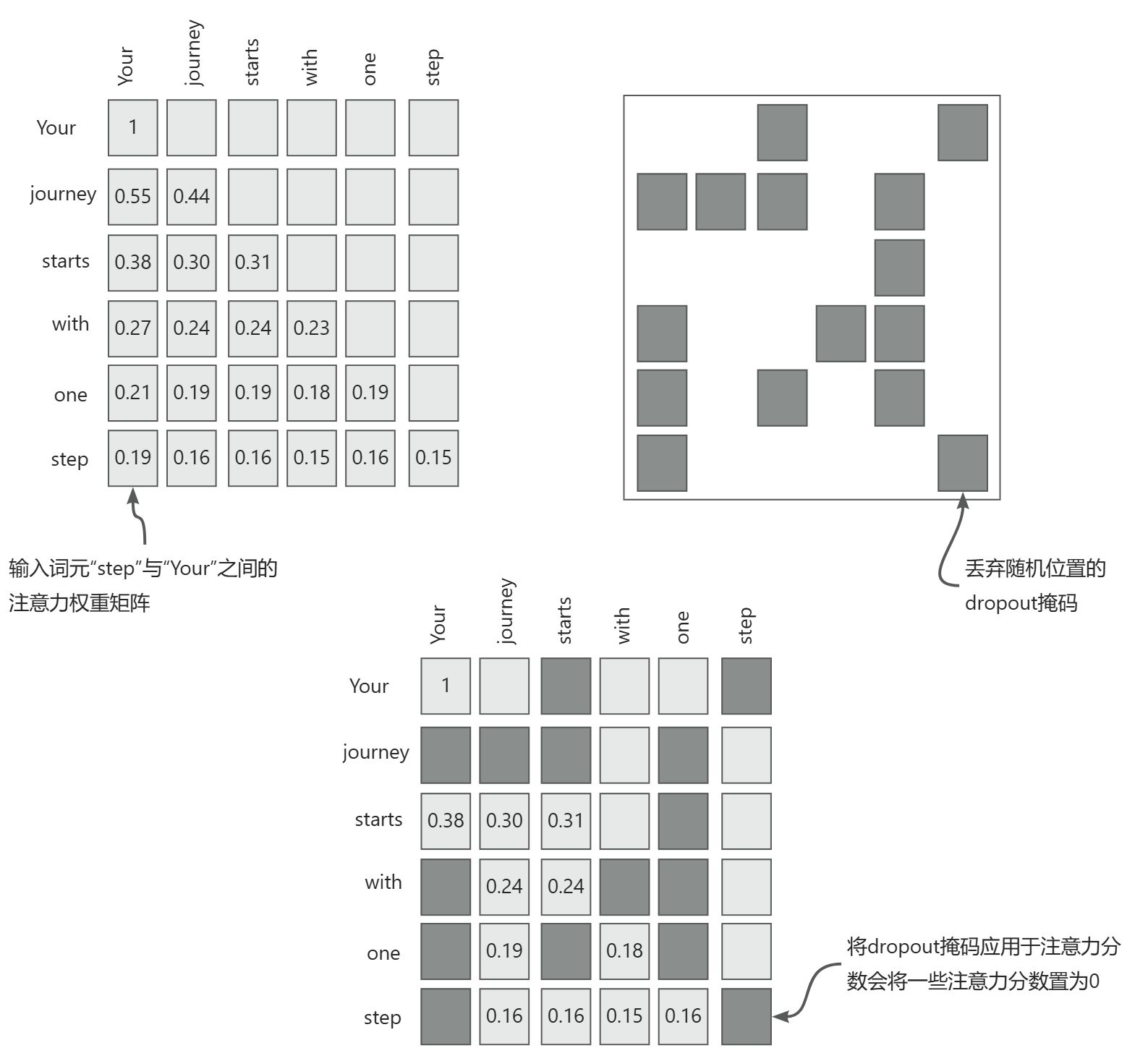
利用因果注意力掩码(左上),我们应用一个额外的dropou掩码(右上)来将额外的注意力权重置0以减少训练期间的过拟合。
将单头注意力扩展到多头注意力
基于 Transformer 的大语言模型中的注意力模块涉及多个因果注意力实例,这被称为“多
头注意力”。
“多头”指的是将注意力机制分成多个“头”,每个“头”独立工作。在这种情况下,单个因果注意力模块可以被看作单头注意力,因为它只有一组注意力权重按顺序处理输入。每个头会学习数据的不同特征,使模型能够在不同的位置同时关注来自不同表示子空间的信息。
有两种实现多头注意力方式,一种是通过堆叠多个因果注意力模块实例来创建多头注意力模块。另一种是使用批量矩阵乘法。下面我们分别进行说明。
通过叠加多个单头注意力模块来实现多头注意力
多头注意力模块的结构,可以由多个单头注意力模块依次叠加在一起组成的。如下图所示。
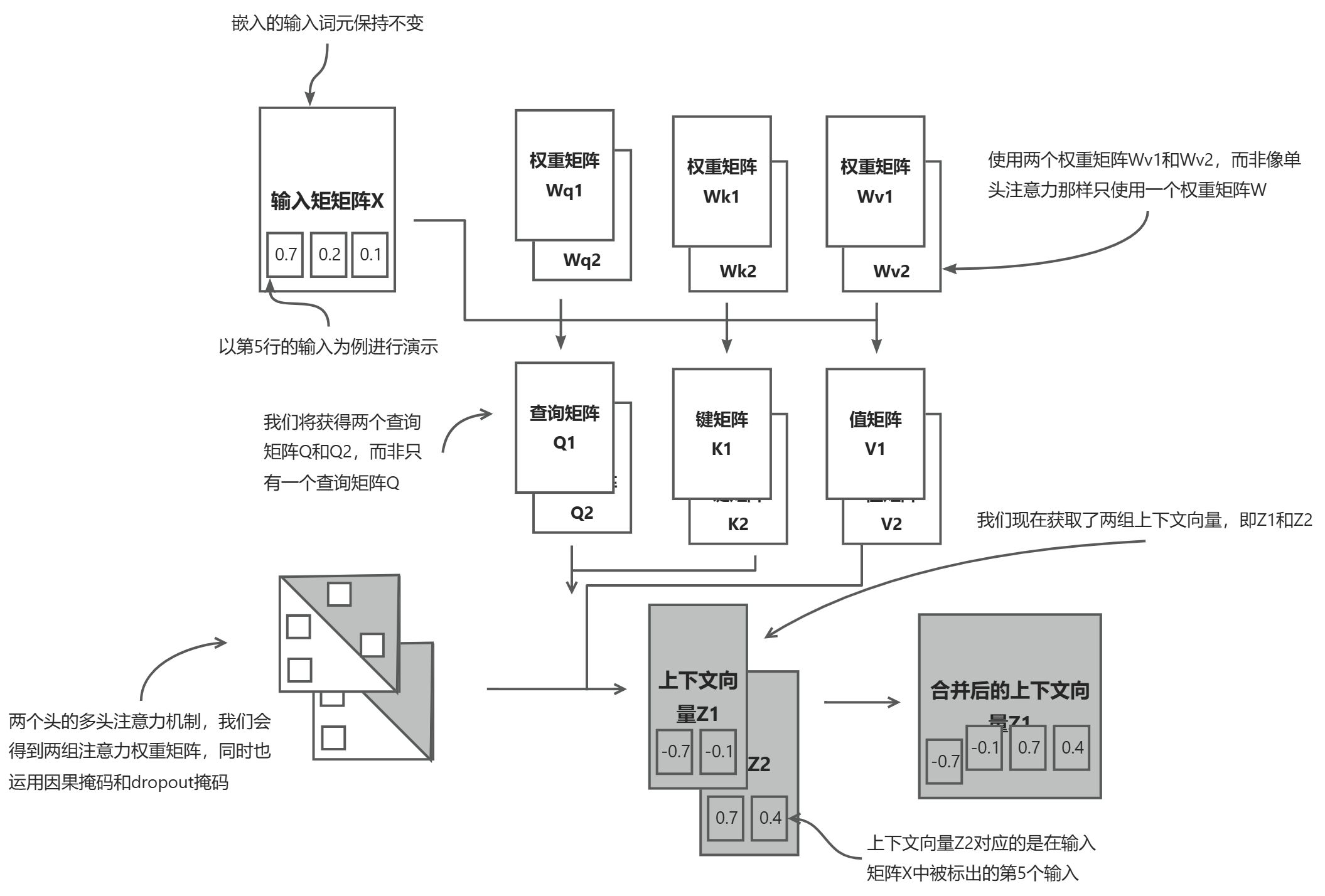
两头注意力模块包含两个堆叠在一起的单头注意力模块。因此,我们不是使用单一的矩阵Wv来计算值矩阵,而是在一个有两个头的多头注意模块中,现在有两个值权重矩阵:Wv1和Wv2。这同样适用于其他的权重矩阵,比如Wq和Wk。我们得到了两组上下文向量Z1和Z2,最终将它们合并成一个上下文向量矩阵Z。
多头注意力的主要思想是多次(并行)运行注意力机制,每次使用学到的不同的线性投影——这些投影是通过将输入数据(比如注意力机制中的查询向量、键向量和值向量)乘以权重矩阵得到的。
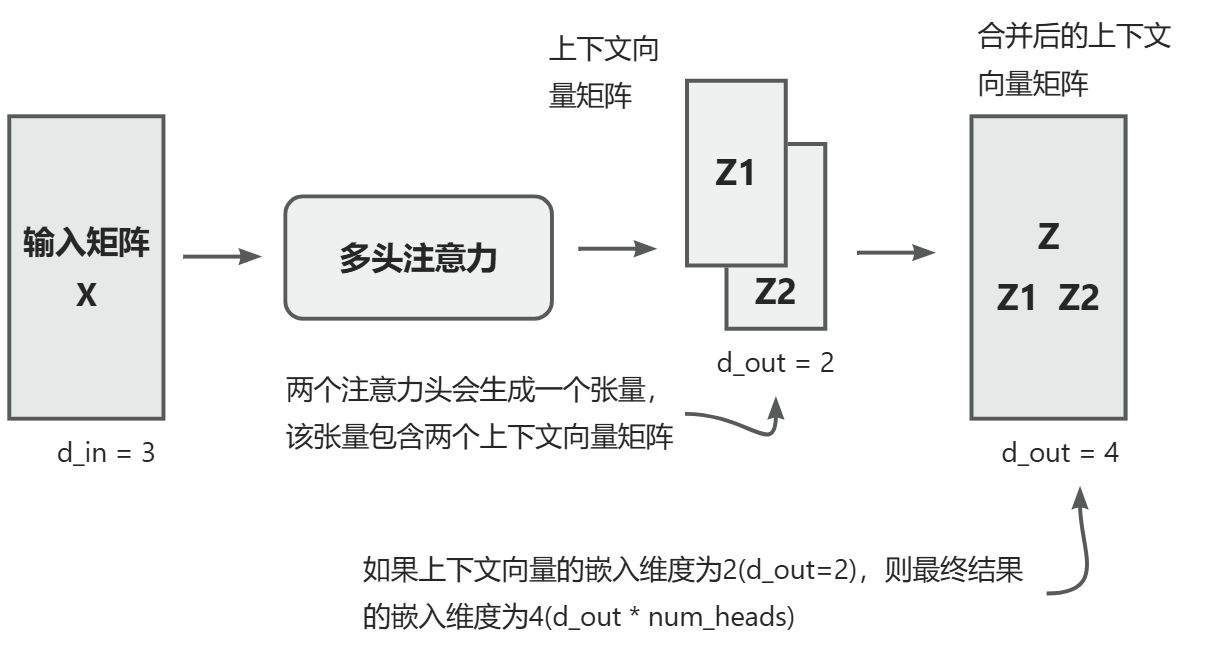
我们设置注意力头的数量为2,那么我们就会得到一个具有两组上下文向量矩阵的张量。在每个上下文向量矩阵中,行表示对应于词元的上下文向量,列则对应于通过d_out=4指定的嵌人维度。我们沿着列维度连接这些上下文向量矩阵。由于我们有两个注意力头并且嵌人维度为2,因此最终的嵌人维度是2x2=4
通过权重划分实现多头注意力
将多头功能整合。它通过重新调整投影后的查询张量、键张量和值张量的形状,将输入分为多个头,然后在计算注意力后合并这些头的结果。
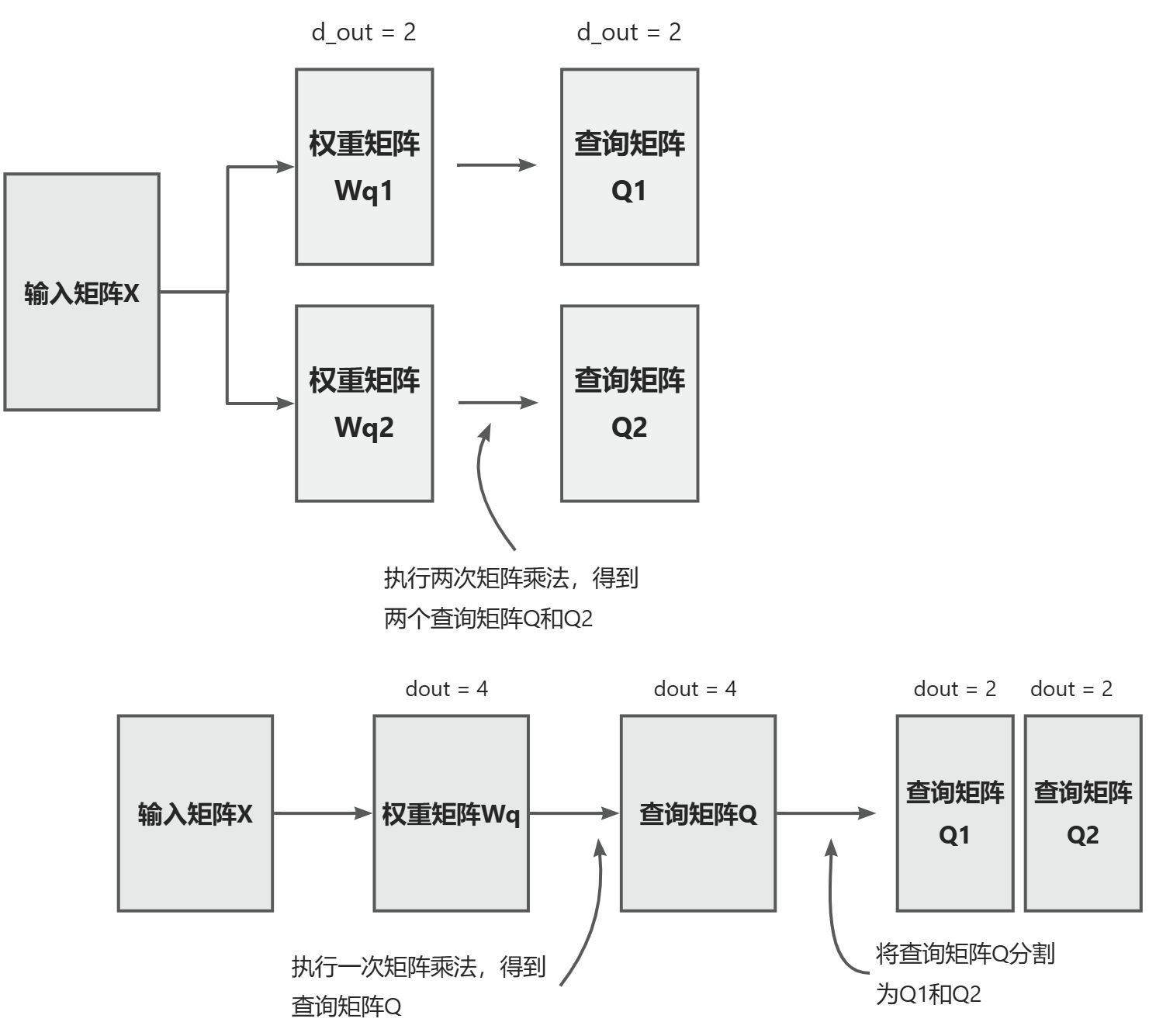
在具有两个注意力头的机制中,我们初始化了两个权重矩阵 Wq1 和 Wq2 ,并计算了两个查询矩阵 Q1 和 Q2 (上)。在通过权重划分实现多头注意力中,我们初始化一个更大的权重矩阵 Wq ,并只与输入矩阵进行一次矩阵乘法操作,得到一个查询矩阵 Q ,然后将查询矩阵分割成了 Q1 和 Q 2(下)。对键矩阵和值矩阵的操作与之类似,为了减少视觉混乱,这里没有展示。
关键操作是将 d_out 维度分割为 num_heads 和 head_dim,其中 head_dim = d_out /
num_heads。
总结
注意力机制可以将输入元素转换为增强的上下文向量表示。
自注意力机制通过对输入进行加权求和来计算上下文向量表示。
使用矩阵乘法替代for循环,可以提高计算效率。
引入了可训练的权重矩阵来计算输入的中间变换:查询矩阵、值矩阵和键矩阵。
我们从一个基础版本的自注意力机制开始,然后逐步加入可训练的权重。因果注意力机制在自注意力的基础上增加了额外掩码,使得大语言模型可以一次生成一个单词。最后,多头注意力将注意力机制划分成多个头,从而使模型能够并行捕获输入数据的各种特征。
补充
注意力机制中的键、查询和值
在注意力机制中,“键”(key)、“查询”(query)和“值”(value)这些术语借用自信息检索和数据库领域,这些领域使用类似的概念来进行信息存储、搜索和检索。
查询类似于数据库中的搜索查询。它代表了模型当前关注或试图理解的项(比如句子中的一个单词或词元)。查询用于探测输入序列中的其他部分,以确定对它们的关注程度。
键类似于用于数据库索引和搜索的键。在注意力机制中,输入序列中的每个项(比如句子中的每个单词)都有一个对应的键。这些键用于与查询进行匹配。
在这种背景下,值类似于数据库中键-值对中的值。它表示输入项的实际内容或表示。
缩放点积注意力的原理
对嵌入维度进行归一化是为了避免梯度过小,从而提升训练性能。例如,在类 GPT 大语言模型中,嵌入维度通常大于 1000,这可能导致点积非常大,从而在反向传播时由于 softmax函数的作用导致梯度非常小。当点积增大时,softmax 函数会表现得更像阶跃函数,导致梯度接近零。这些小梯度可能会显著减慢学习速度或使训练停滞。
因此,通过嵌入维度的平方根进行缩放解释了为什么这种自注意力机制也被称为缩放点积注意力机制。
权重参数
在权重矩阵 W 中,“权重”是“权重参数”的简称,表示在训练过程中可以优化的神经网络参数。注意力权重决定了上下文向量对输入的不同部分的依赖程度(网络对输入的不同部分的关注程度)。
总之,权重参数是定义网络连接的基本学习系数,而注意力权重是动态且特定于上下文的值。
pytorch的函数
tril 函数,创建一个对角线以上元素为 0 的掩码。
softmax 函数,会将其输入转换为一个概率分布。当输入中出现负无穷大值(–∞)时,softmax函数会将这些值视为零概率。
view 函数,进行张量重置
transpose 函数,进行张量转置
参考
《从零构建大模型》

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 22
22 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)