17_LangChain 分块策略:为何 chunk_size 只是一个软限制?
文章目录
在最近开发 MVP 的 RAG(知识库问答)功能时,我遇到了一个有趣的现象。看下面这张运行截图,你能发现“华点”吗?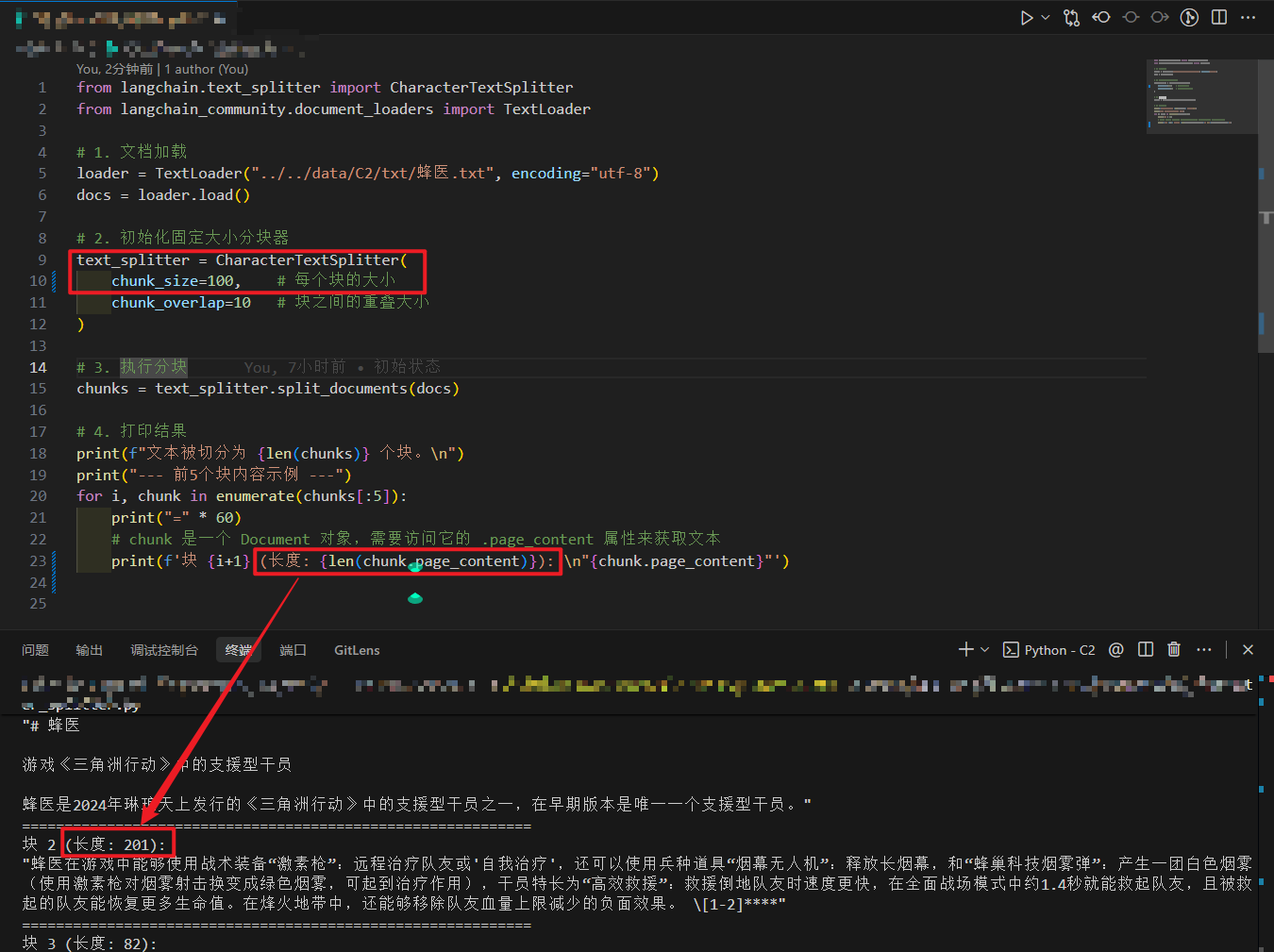
text_splitter = CharacterTextSplitter(chunk_size=100, separator="\n\n")
# 输出:1 个长度为 201 的 Chunk
🕵️♂️ 案发现场
- 我的设置:我在初始化
CharacterTextSplitter时,信誓旦旦地设置了chunk_size=100(意图:每个文本块限制在 100 字符以内)。 - 实际结果:控制台打印出的第 2 个块,长度竟然高达
201! - 内容:这是一段关于游戏《三角洲行动》中“蜂医”角色的长描述。
疑问:LangChain 是数学不好,还是直接无视了我的参数?
📦 核心原理解析:搬家箱子与“传家宝”
为了解释这个现象,我们先打个比方。
想象你是一个搬家工人,老板给你一堆限重 100 斤的小箱子(这就是 chunk_size=100),让你把家里的东西装箱。
但是,LangChain 的 CharacterTextSplitter 遵守一个最高指令:“保持物品完整性”。
- 常规情况:书本、衣服这些零散的东西,凑够 100 斤就封箱。
- 特殊情况(本次事故原因):突然,你遇到了一尊重 201 斤的整块玉雕(这就是截图里那段长长的关于“蜂医”技能的描述)。
- 你能把它敲碎吗? 不能!因为这个切分器默认只允许在“段落之间”(即
\n\n)切分,它不允许在句子中间强行把玉雕锯断。 - 你怎么办? 你只能违背“限重 100 斤”的规定,找一个超大的箱子,把这尊 201 斤的玉雕单独装进去。
结论:CharacterTextSplitter 的 chunk_size 是一个**“软限制”。它会尽力凑到这个大小,但如果遇到一个本身就比限制还长**的独立段落,它会优先保护段落的语义完整,而不是强行切断。
1.根本原因
CharacterTextSplitter 的工作流遵循 “语义原子性优先(Semantic Atomicity First)” 原则。它的算法逻辑是 先切分(Split),后合并(Merge)。
算法流程伪代码(逻辑推演):
- Tokenization/Splitting (原子化):
首先,通过separator(默认是\n\n)将全文切分为一个个“候选列表” (Splits)。
注意:在这个阶段,程序根本不关心
chunk_size。如果你的段落有 201 个字且中间没有双换行符,它就是一个不可分割的“原子单元”。
- Greedy Merging (贪婪合并):
程序遍历上述候选列表,尝试将它们合并到一个 Chunk 中。
逻辑判断如下:
if (current_chunk_length + next_split_length) > chunk_size:
# 如果加上下一段会超重 -> 封存当前块,开启新块
yield current_chunk
else:
# 没超重 -> 合并
current_chunk += next_split
- The Edge Case (边界条件):
如果单个“原子单元”本身的长度 >chunk_size怎么办?
由于CharacterTextSplitter不支持递归(Non-Recursive),它没有能力深入段落内部去寻找新的切分点。为了保证数据不丢失(Data Integrity),它只能 Bypass(绕过) 长度检查,强制输出这个超长单元。
结论:在 CharacterTextSplitter 中,separator 定义了数据的最小粒度。chunk_size 仅作用于“合并”阶段,无法作用于“原子单元”内部。
2. 架构层面的影响 (Why it Matters)
这种“软限制”行为如果处理不当,会给下游的 RAG 链路带来严重的 级联效应:
- Embedding 截断风险(Embedding Truncation):
许多 Embedding 模型(如早期的 BERT 变体)有严格的 Token 限制(如 512 tokens)。如果你的 Chunk 因为段落过长而变成了 1000+ 字符,尾部信息在向量化时会被直接丢弃,导致检索盲区。 - 向量空间分布(Vector Space Distribution):
长短不一的 Chunk 会导致向量空间分布不均匀。超长 Chunk 包含的信息密度过大,与用户简短 Query 的相似度匹配(Cosine Similarity)可能会下降,这就是所谓的 “Lost in the Middle” 现象的变种。 - LLM 上下文窗口(Context Window):
在k=5或更高的召回设置下,不可控的 Chunk 长度极易撑爆 LLM 的 Prompt Limit,导致高昂的 Token 成本或直接报错。
3. 技术解决方案:递归分块 (Recursive Chunking)
要解决这个问题,不能依赖“单层”分块器,必须升级为 DFS(深度优先搜索)风格的递归分块器。
推荐方案:使用 RecursiveCharacterTextSplitter。
工作原理
它不再只看一层,而是维护一个分隔符列表(Separators List),例如 ["\n\n", "\n", " ", ""]。算法执行流程如下:
- 尝试用 Level 1 (
\n\n) 切分。 - 检查切出的每个块:
- 如果
len(chunk) < chunk_size-> 保留。 - 如果
len(chunk) > chunk_size-> 进入递归。
- 对超长块使用 Level 2 (
\n) 继续切分。 - 如果还长,使用 Level 3 (
代码重构示例
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 针对中文环境的精细化配置
text_splitter = RecursiveCharacterTextSplitter(
# 强制硬限制:任何 Chunk 尽量不超标(除非单词本身超长)
chunk_size=100,
chunk_overlap=10,
# 优先级策略:段落 -> 句子 -> 短句 -> 字符
separators=["\n\n", "\n", "。", ";", ",", ""]
)
chunks = text_splitter.split_documents(docs)
4. 总结与最佳实践
- CharacterTextSplitter:适用于结构非常规范、段落短小且可控的简单文本(如每行一条的日志)。它是“基于聚合”的逻辑。
- RecursiveCharacterTextSplitter:RAG 系统的工业级标准。它通过牺牲少量的语义连贯性(偶尔打断句子),换取了严格的 Token 控制和系统稳定性。它是“基于分治”的逻辑。
One-line Takeaway:
不要相信 CharacterTextSplitter 的 chunk_size 会帮你切断长句;如果你需要严格的长度控制以适配 Embedding 模型,必须使用递归分块策略。
最后附上代码:
from langchain.text_splitter import CharacterTextSplitter
from langchain_community.document_loaders import TextLoader
# 1. 文档加载
loader = TextLoader("../../data/C2/txt/蜂医.txt", encoding="utf-8")
docs = loader.load()
# 2. 初始化固定大小分块器
text_splitter = CharacterTextSplitter(
chunk_size=100, # 每个块的大小
chunk_overlap=10 # 块之间的重叠大小
)
# 3. 执行分块
chunks = text_splitter.split_documents(docs)
# 4. 打印结果
print(f"文本被切分为 {len(chunks)} 个块。\n")
print("--- 前5个块内容示例 ---")
for i, chunk in enumerate(chunks[:5]):
print("=" * 60)
# chunk 是一个 Document 对象,需要访问它的 .page_content 属性来获取文本
print(f'块 {i+1} (长度: {len(chunk.page_content)}): \n"{chunk.page_content}"')

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 26
26 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)