PyTorch数据处理:从“买回食材”到“备好下锅”的完整指南(第二期)
本文以"AI厨房"为比喻,系统介绍了PyTorch数据处理流程。主要内容包括:1)回顾张量基础知识;2)提出数据处理的必要性,将原始数据转化为模型可用的标准格式;3)详细讲解数据处理三大步骤:数据加载(Dataset)、数据变换(Transform)和批量加载(DataLoader);4)提供猫狗识别和表情识别的完整实战案例;5)总结关键知识点并给出实践任务。文章通过生动比喻和
一、回顾上节课:你已经认识了“食材”
在上一篇文章中,我们学会了:
✅ 张量就是“装数字的箱子”
-
0维(一个数)、1维(一串数)、2维(表格)、3维+(多维数据)
-
就像是米、面、油、菜等各种基础食材
✅ 创建和操作张量
-
torch.tensor()、.shape、.view()、广播机制等 -
就像认识各种食材的特性,知道怎么存放它们
一句话总结上节:你认识了AI厨房里的所有基础食材!
二、今日目标:学习“切菜”——数据加载与预处理
🎯 学习路线图更新
还记得我们的“做菜式”学习路径吗?今天来到第二步: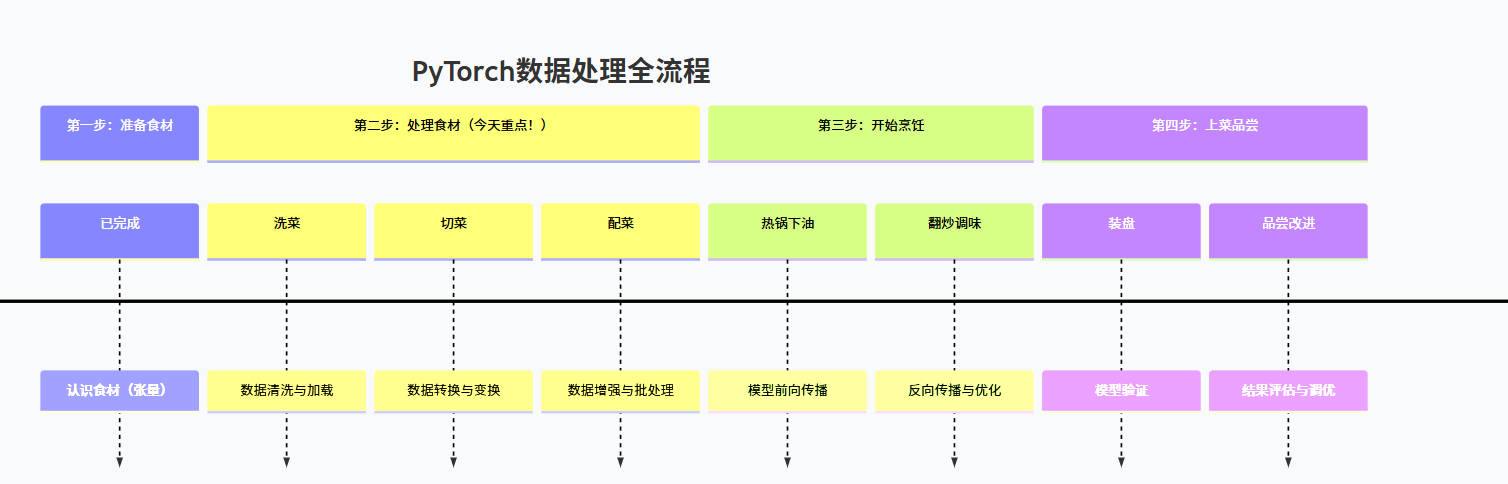
今日核心:学习如何把“买回来的菜”(原始数据)变成“可以直接下锅的食材”(模型可用的张量)。
三、为什么需要数据处理?
现实世界的“菜”长什么样?
想象一下:如果你要教AI认识猫和狗
原始数据(刚买回来的“菜”):
-
图片大小不一:有的1920×1080,有的640×480
-
格式混乱:.jpg、.png、.bmp都有
-
方向不对:有的横着拍,有的竖着拍
-
亮度差异:有的在阳光下,有的在阴影里
模型需要的“标准食材”:
-
统一尺寸:比如都变成224×224
-
统一格式:都转为RGB三通道张量
-
数值标准化:像素值从0-255变成0-1
-
批量整齐:一次处理32张,形状都是[32, 3, 224, 224]
这就是数据处理要做的事情!
四、数据处理三大步:洗、切、配
第一步:洗菜——数据加载(Dataset)
把数据从硬盘“拿”到内存,并进行初步清理。
python
import torch
from torch.utils.data import Dataset
from PIL import Image
import os
# 自定义数据集类(就像定制菜篮)
class 猫狗数据集(Dataset):
def __init__(self, 图片文件夹路径, 变换=None):
"""
参数:
图片文件夹路径:存放猫狗图片的文件夹
变换:要对图片做的处理(比如调整大小)
"""
self.所有图片路径 = []
self.标签 = [] # 0=猫,1=狗
self.变换 = 变换
# 遍历文件夹,收集所有图片路径和标签
for 文件名 in os.listdir(图片文件夹路径):
文件路径 = os.path.join(图片文件夹路径, 文件名)
if 文件名.startswith('cat'):
self.所有图片路径.append(文件路径)
self.标签.append(0) # 猫标签为0
elif 文件名.startswith('dog'):
self.所有图片路径.append(文件路径)
self.标签.append(1) # 狗标签为1
def __len__(self):
"""返回数据集大小(有多少张图片)"""
return len(self.所有图片路径)
def __getitem__(self, 索引):
"""
获取第n个样本
返回:(图片张量, 标签)
"""
# 1. 加载图片(从硬盘读到内存)
图片路径 = self.所有图片路径[索引]
图片 = Image.open(图片路径).convert('RGB') # 确保是RGB格式
# 2. 应用变换(如果有的话)
if self.变换:
图片 = self.变换(图片)
# 3. 获取标签
标签 = self.标签[索引]
return 图片, 标签
# 使用示例
print("📂 创建数据集对象...")
我的数据集 = 猫狗数据集(图片文件夹路径='./data/train')
print(f"数据集大小: {len(我的数据集)} 张图片")
print(f"第一张图片: {我的数据集[0]}")
第二步:切菜——数据变换(Transform)
把图片变成模型能吃懂的“标准形状”。
python
import torchvision.transforms as transforms
# 定义一系列“切菜刀法”
数据预处理 = transforms.Compose([
# 1. 调整大小(把大菜叶切成合适大小)
transforms.Resize((256, 256)),
# 2. 随机裁剪(从中间切出224×224的正方形)
transforms.RandomCrop((224, 224)),
# 3. 随机水平翻转(增加数据多样性)
transforms.RandomHorizontalFlip(p=0.5), # 50%概率翻转
# 4. 转为张量(从PIL图片变成PyTorch张量)
transforms.ToTensor(),
# 5. 标准化(让数值分布更稳定)
transforms.Normalize(
mean=[0.485, 0.456, 0.406], # ImageNet数据集的均值
std=[0.229, 0.224, 0.225] # ImageNet数据集的标准差
)
])
# 更简单的变换(初学者先用这个)
简单变换 = transforms.Compose([
transforms.Resize((224, 224)), # 统一大小
transforms.ToTensor(), # 转为张量
# 标准化:把0-255的像素值变成0-1,再归一化
])
# 应用到数据集
数据集带变换 = 猫狗数据集(
图片文件夹路径='./data/train',
变换=简单变换
)
# 查看处理后的图片
图片张量, 标签 = 数据集带变换[0]
print(f"\n处理后图片形状: {图片张量.shape}")
print(f"像素值范围: [{图片张量.min():.3f}, {图片张量.max():.3f}]")
print(f"标签: {'猫' if 标签==0 else '狗'}")
# 解释shape的含义:
# [3, 224, 224] = [颜色通道数, 高度, 宽度]
# 3个通道:红(Red)、绿(Green)、蓝(Blue)
第三步:配菜——批量加载(DataLoader)
把处理好的数据分成小份,方便“下锅炒菜”。
python
from torch.utils.data import DataLoader
# 创建数据加载器(就像准备多个小菜篮)
训练数据加载器 = DataLoader(
dataset=数据集带变换, # 使用哪个数据集
batch_size=32, # 每个小菜篮放32张图片
shuffle=True, # 每次打乱顺序(像洗牌)
num_workers=2 # 用2个"帮手"并行加载数据
)
# 使用示例:遍历一个批次的数据
print("\n🍽️ 准备上菜(批量加载数据)...")
for 批次索引, (图片批次, 标签批次) in enumerate(训练数据加载器):
print(f"\n第{批次索引+1}批菜:")
print(f" 图片形状: {图片批次.shape}") # [32, 3, 224, 224]
print(f" 标签形状: {标签批次.shape}") # [32]
print(f" 标签内容: {标签批次[:5]}") # 前5个标签
# 通常只查看前几个批次
if 批次索引 == 2:
break
# 高级技巧:不同阶段用不同数据
训练集 = 猫狗数据集('./data/train', 变换=训练变换)
测试集 = 猫狗数据集('./data/test', 变换=测试变换)
训练加载器 = DataLoader(训练集, batch_size=32, shuffle=True)
测试加载器 = DataLoader(测试集, batch_size=32, shuffle=False) # 测试时不打乱
五、完整实战:猫狗识别数据准备
让我们把所有步骤组合起来:
python
import torch
import torchvision.transforms as transforms
from torch.utils.data import Dataset, DataLoader
from PIL import Image
import os
# ========== 1. 定义数据变换 ==========
训练变换 = transforms.Compose([
transforms.Resize(256),
transforms.RandomCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
])
测试变换 = transforms.Compose([
transforms.Resize(224),
transforms.CenterCrop(224), # 测试时从中心裁剪
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
])
# ========== 2. 创建数据集 ==========
class 猫狗识别数据集(Dataset):
def __init__(self, 根目录, 模式='train', 变换=None):
self.文件列表 = []
self.标签列表 = []
self.变换 = 变换
文件夹路径 = os.path.join(根目录, 模式)
# 假设目录结构:
# data/
# train/
# cat.001.jpg
# dog.001.jpg
# test/
# cat.002.jpg
# dog.002.jpg
for 文件名 in os.listdir(文件夹路径):
if 文件名.endswith(('.jpg', '.png', '.jpeg')):
完整路径 = os.path.join(文件夹路径, 文件名)
self.文件列表.append(完整路径)
# 从文件名判断是猫还是狗
if 'cat' in 文件名.lower():
self.标签列表.append(0)
else:
self.标签列表.append(1)
def __len__(self):
return len(self.文件列表)
def __getitem__(self, 索引):
图片 = Image.open(self.文件列表[索引]).convert('RGB')
标签 = self.标签列表[索引]
if self.变换:
图片 = self.变换(图片)
return 图片, 标签
# ========== 3. 创建数据加载器 ==========
# 假设你的数据放在当前目录的data文件夹中
数据集 = 猫狗识别数据集(根目录='./data', 模式='train', 变换=训练变换)
数据加载器 = DataLoader(数据集, batch_size=16, shuffle=True, num_workers=4)
# ========== 4. 验证数据准备是否成功 ==========
print("=" * 50)
print("猫狗识别数据准备系统")
print("=" * 50)
print(f"\n📊 数据集统计:")
print(f" 总图片数: {len(数据集)}")
print(f" 批次大小: 16")
print(f" 总批次数: {len(数据加载器)}")
# 获取一个批次看看
图片批次, 标签批次 = next(iter(数据加载器))
print(f"\n🔍 第一个批次详情:")
print(f" 图片形状: {图片批次.shape}")
print(f" 标签形状: {标签批次.shape}")
# 统计猫狗数量
猫数量 = (标签批次 == 0).sum().item()
狗数量 = (标签批次 == 1).sum().item()
print(f" 本批次猫: {猫数量}张, 狗: {狗数量}张")
print("\n✅ 数据准备完成!可以开始训练模型了!")
六、常见问题与技巧
Q1:我的数据不在本地,怎么加载?
python
# 从网上下载标准数据集(最简单的方式)
from torchvision import datasets
# 下载MNIST手写数字数据集
mnist数据集 = datasets.MNIST(
root='./data', # 下载到哪里
train=True, # 训练集
download=True, # 如果本地没有就下载
transform=transforms.ToTensor()
)
# 下载CIFAR-10数据集(10类物体)
cifar数据集 = datasets.CIFAR10(
root='./data',
train=True,
download=True,
transform=transforms.ToTensor()
)
print(f"MNIST大小: {len(mnist数据集)}")
print(f"CIFAR-10大小: {len(cifar数据集)}")
Q2:标签不是0/1,而是文字怎么办?
python
# 方法1:使用标签映射字典
类别到编号 = {'cat': 0, 'dog': 1, 'bird': 2}
编号到类别 = {0: '猫', 1: '狗', 2: '鸟'}
# 方法2:自动生成映射
类别列表 = ['cat', 'dog', 'bird', 'fish']
类别到编号 = {类别: 编号 for 编号, 类别 in enumerate(类别列表)}
Q3:数据太大,内存放不下怎么办?
python
# 使用迭代器,一次只加载一部分
class 大数据集(Dataset):
def __init__(self, 文件列表路径):
# 只保存文件路径,不保存图片数据
with open(文件列表路径, 'r') as f:
self.文件路径列表 = f.read().splitlines()
def __getitem__(self, 索引):
# 每次需要时才从硬盘读取
图片路径 = self.文件路径列表[索引]
return Image.open(图片路径) # 现用现读
Q4:如何查看处理后的图片?
python
import matplotlib.pyplot as plt
import numpy as np
def 显示图片(图片张量, 标题=''):
"""
将张量格式的图片显示出来
图片张量形状:[C, H, W] 或 [B, C, H, W]
"""
# 如果是批量数据,取第一张
if len(图片张量.shape) == 4:
图片张量 = 图片张量[0]
# 将张量转为numpy,并调整通道顺序
图片数组 = 图片张量.numpy().transpose(1, 2, 0)
# 反标准化(如果需要)
图片数组 = 图片数组 * np.array([0.229, 0.224, 0.225]) + np.array([0.485, 0.456, 0.406])
图片数组 = np.clip(图片数组, 0, 1) # 限制在0-1范围内
plt.imshow(图片数组)
plt.title(标题)
plt.axis('off')
plt.show()
# 使用示例
图片, 标签 = 数据集带变换[0]
显示图片(图片, f'标签: {"猫" if 标签==0 else "狗"}')
七、今日总结与任务
✅ 今天你学会了:
1. Dataset类:自定义数据容器
-
像定制菜篮,告诉PyTorch你的数据在哪里、怎么读
-
必须实现
__len__和__getitem__两个方法
2. Transform变换:数据预处理流水线
-
Resize:调整大小 -
ToTensor:转为PyTorch张量 -
Normalize:标准化(重要!) -
还可以随机裁剪、翻转等增加数据多样性
3. DataLoader:批量数据加载器
-
batch_size:每批多少数据 -
shuffle:是否打乱顺序 -
num_workers:用几个线程加载
🎯 一句话记住数据处理:
Dataset定义数据在哪,Transform定义怎么处理,DataLoader定义怎么批量取用。
📝 你的实践任务:
python
"""
任务:创建一个表情识别数据管道
假设你有3类表情图片:happy(高兴)、sad(悲伤)、angry(生气)
目录结构:
emotion_data/
train/
happy_001.jpg
sad_001.jpg
angry_001.jpg
...
test/
...
要求:
1. 创建自定义Dataset类
2. 训练集使用随机裁剪和翻转
3. 测试集只做中心裁剪
4. 批量大小设为16
5. 显示第一批数据的前3张图片
提示:
- 可以用文件名判断类别(如'happy'开头)
- 图片统一缩放到256×256,再裁剪224×224
"""
# 先自己尝试,参考答案见文末
🚀 下一步学习什么?
学会了“切菜”(数据处理),下次我们将进入:
“学习炒菜”——构建第一个神经网络模型
你将学会:
-
如何定义网络层(像准备锅碗瓢盆)
-
前向传播(像下锅翻炒)
-
损失函数和优化器(像控制火候和调味)
八、数据处理参考答案
python
# 表情识别数据管道参考答案
import torch
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
from PIL import Image
import os
import matplotlib.pyplot as plt
class 表情数据集(Dataset):
def __init__(self, 根目录, 模式='train', 变换=None):
self.文件路径 = []
self.标签 = []
self.类别映射 = {'happy': 0, 'sad': 1, 'angry': 2}
self.变换 = 变换
文件夹 = os.path.join(根目录, 模式)
for 文件 in os.listdir(文件夹):
if 文件.endswith(('.jpg', '.png')):
路径 = os.path.join(文件夹, 文件)
self.文件路径.append(路径)
# 从文件名提取标签
for 类别 in self.类别映射:
if 类别 in 文件.lower():
self.标签.append(self.类别映射[类别])
break
def __len__(self):
return len(self.文件路径)
def __getitem__(self, 索引):
图片 = Image.open(self.文件路径[索引]).convert('RGB')
标签 = self.标签[索引]
if self.变换:
图片 = self.变换(图片)
return 图片, 标签
# 定义变换
训练变换 = transforms.Compose([
transforms.Resize(256),
transforms.RandomCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
测试变换 = transforms.Compose([
transforms.Resize(224),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
# 创建数据集和加载器
数据集 = 表情数据集('./emotion_data', 模式='train', 变换=训练变换)
加载器 = DataLoader(数据集, batch_size=16, shuffle=True)
# 获取并显示第一批数据
图片批次, 标签批次 = next(iter(加载器))
标签名称 = ['高兴', '悲伤', '生气']
fig, axes = plt.subplots(1, 3, figsize=(12, 4))
for i in range(3):
图片 = 图片批次[i].numpy().transpose(1, 2, 0)
图片 = 图片 * 0.5 + 0.5 # 反标准化
图片 = np.clip(图片, 0, 1)
axes[i].imshow(图片)
axes[i].set_title(f'表情: {标签名称[标签批次[i].item()]}')
axes[i].axis('off')
plt.tight_layout()
plt.show()
print(f"✅ 数据管道创建成功!")
print(f" 批次形状: {图片批次.shape}")
print(f" 标签: {标签批次[:3].tolist()}")
记住:数据处理是AI项目中最耗时但最重要的环节。一个好的数据管道,相当于备好了新鲜、干净的食材,后续烹饪(模型训练)才会顺利!
现在,你的“AI厨房”里已经备好了处理好的食材,下次我们就可以开始真正的“烹饪”了——构建和训练神经网络!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 4
4 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)