RAG(六) 文本分割器的使用
摘要:本文讨论了在RAG应用中处理长文档的关键步骤——文本分割。由于大语言模型的上下文窗口有限,需要将Document对象分割成更小的语义块(chunks)。文本分割器(TextSplitters)通过设置chunk_size和chunk_overlap参数,在保持语义连贯性的同时分割文档。这种处理既能适应模型限制,又能提升检索效率和质量,避免因文档过长导致的信息丢失或回答质量下降。LangCha
我们上一节将外部数据源加载为 Document 对象。然而,这些文档通常太长,无法直接放入模型的上下文窗口。例如,一个几十页的 PDF 文档转换成文本后,会远远超出大多数模型的 4k、8k 或甚至 128k token 的限制。
为了解决这个问题,我们需要将一个大的 Document 分割成多个小的、语义相关的“块” (chunks)。这就是“文本分割器” (Text Splitters) 的作用。
在RAG应用中,文档加载器将原始文档转换为Document对象后,通常需要对长文档进行分割处理,这是因为大语言模型的上下文窗口是有限的,如果在RAG检索完成之后,直接将检索到的长文档作为上下文传递给模型,可能会超出模型处理的上下文长度,导致信息丢失或回答质量下降,其中,进行文档分割的组件就是文本分割器。
一 为什么需要文本分割?
-
适应上下文窗口: 这是最主要的原因。将长文档分割成小块,可以让我们在处理时只关注与用户问题最相关的部分。把长文档分割成更小,缩小上下文长度
-
提升检索效率和质量: 在 RAG (检索增强生成) 流程中,我们通常会对这些小块进行嵌入并存入向量数据库。更小、更具语义焦点的文本块能够提供更精确的检索结果。如果一个文本块太大,它可能包含太多不相关的主题,从而“稀释”了其向量表示的语义。在分割过程中,能尽量保持文本的语义连贯性
二 文本分割的核心思想
一个好的文本分割策略应该力求在保持语义完整性的同时,将文本切分成合适的大小。这意味着我们不应该简单地在第 1000 个字符处硬生生地切断一个句子。相反,我们应该寻找自然的分割点,比如段落、句子等。
chunk_size 和 chunk_overlap
配置文本分割器时,有两个核心参数:
-
chunk_size: 定义了每个文本块的最大尺寸。这个尺寸通常以字符数或 token 数来衡量。 -
chunk_overlap: 定义了相邻文本块之间重叠的字符(或 token)数。设置一个小的重叠(例如,100-200 个字符)是一个非常好的实践。它有助于在两个块的边界处保持语义的连续性,避免一个完整的语义单元(如一个长句子)被硬生生切断在两个独立的块中。
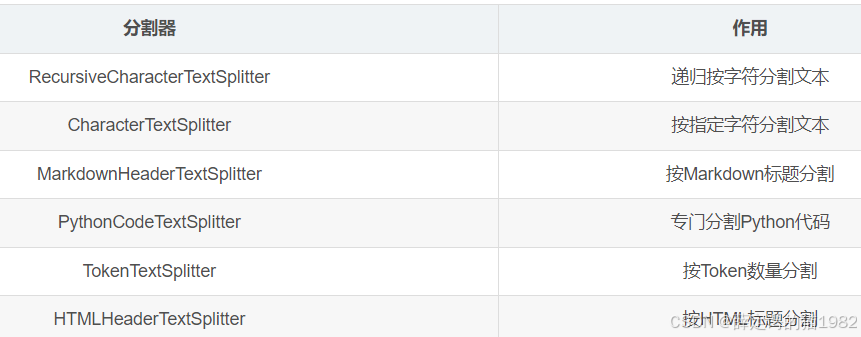
LangChain提供了多种文本分割器,常用的有:
加载文档后,您通常会想要对其进行转换以更好地适合您的应用程序。最简单的例子是,您可能希望将长文档分割成更小的块,以适合模型的上下文窗口。LangChain 有许多内置的文档转换器,可以轻松地拆分、组合、过滤和以其他方式操作文档。
当您想要处理长文本时,有必要将该文本分割成块。这听起来很简单,但这里存在很多潜在的复杂性。理想情况下,您希望将语义相关的文本片段保留在一起。“语义相关” 的含义可能取决于文本的类型。本笔记本展示了实现此目的的几种方法。
在较高层面上,文本分割器的工作原理如下:
将文本分成小的、具有意义的块(通常是句子)。
开始将这些小块组合成一个更大的块,直到达到一定的大小(通过某些函数测量)。
一旦达到该大小,请将该块设为自己的文本片段,然后开始创建具有一些重叠的新文本块(以保持块之间的上下文)。
pip install -qU langchain-text-splitters 安装文本分割器
三 通用文本分割器
RecursiveCharacterTextSplitter是LangChain中最常用的通用文本分割器,它会根据指定的字符优先级递归分割文本,直到所有片段长度不超过指定上限。
首先介绍使用split_text()方法进行文本分割,使用示例如下,其中RecursiveCharacterTextSplitter中指定的块大小为100,片段重叠字符数为30,计算长度的函数使用len。
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 1.分割文本内容
content = ("李白(701年2月28日~762年12月),字太白,号青莲居士,出生于蜀郡绵州昌隆县(今四川省绵阳市江油市青莲镇),一说山东人,一说出生于西域碎叶,祖籍陇西成纪(今甘肃省秦安县)。"
""
"唐代伟大的浪漫主义诗人,被后人誉为“诗仙”,与杜甫并称为“李杜”,为了与另两位诗人李商隐与杜牧即“小李杜”区别,杜甫与李白又合称“大李杜”。"
""
"据《新唐书》记载,李白为兴圣皇帝(凉武昭王李暠)九世孙,与李唐诸王同宗。其人爽朗大方,爱饮酒作诗,喜交友。"
""
"李白深受黄老列庄思想影响,有《李太白集》传世,诗作中多为醉时写就,代表作有《望庐山瀑布》《行路难》《蜀道难》《将进酒》《早发白帝城》等")
# 2.定义递归文本分割器
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100,
chunk_overlap=30,
length_function=len,
)
# 3.分割文本
splitter_texts = text_splitter.split_text(content)
# 4.转换为文档对象
splitter_documents = text_splitter.create_documents(splitter_texts)
print(f"分割文档数量:{len(splitter_documents)}")
for splitter_document in splitter_documents:
print(f"文档片段大小:{len(splitter_document.page_content)}, 文档元数据:{splitter_document.metadata}")
四 CharacterTextSplitter(基于字符分隔符的通用分割工具)
CharacterTextSplitter 的核心设计理念是“以字符(串)为分隔符,按固定长度切割文本”。它不依赖文本的语义结构(如段落、句子),也不针对特定格式(如 HTML、PDF),而是通过用户指定的分隔符(如换行符、逗号、自定义字符串)将文本拆分为基础单元,再按照设定的块大小(chunk_size)合并这些单元,最终得到符合要求的文本块。
实例一
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import HTMLHeaderTextSplitter, CharacterTextSplitter
# 1. 修正 CharacterTextSplitter 参数(核心修复)
text_splitter = CharacterTextSplitter(
separator="<br>", # 按<br>标签分割
chunk_size=200, # 每个文本块的最大长度(调整为合理值)
chunk_overlap=20, # 块之间的重叠长度(必须小于chunk_size)
length_function=len, # 长度计算函数
is_separator_regex=False, # 分隔符不按正则处理
)
# 2. 加载 HTML 文件(TextLoader 可读取文本格式的 HTML)
try:
loader = TextLoader("2.html", encoding="utf8")
docs = loader.load() # 注意变量名改为 docs(复数更符合语义)
# 3. 执行文本分割
if docs: # 检查是否成功加载文件
texts = text_splitter.create_documents([docs[0].page_content])
# 4. 格式化输出分割结果(便于查看)
print(f"分割后的文本块数量:{len(texts)}")
print("="*50)
for i, text in enumerate(texts):
print(f"第 {i+1} 个文本块:{text.page_content}")
print("-"*30)
except FileNotFoundError:
print("错误:未找到 2.html 文件,请检查文件路径是否正确")
except Exception as e:
print(f"运行出错:{str(e)}")实例二
from langchain_text_splitters import CharacterTextSplitter
# 配置:按段落分隔(默认 "\n\n"),块大小 2000,重叠 200
text_splitter = CharacterTextSplitter(
separator="\n\n",
chunk_size=2000,
chunk_overlap=200,
length_function=len,
is_separator_regex=False,
)
# 模拟长文本(实际场景中可从文件加载)
long_text = """LangChain 是一个用于构建大模型应用的开发框架。它提供了丰富的工具和组件,帮助开发者快速实现文本处理、向量存储、对话交互等功能。
文本分割是 LangChain 中的核心模块之一,用于将长文本拆分为符合大模型上下文窗口限制的短文本块。CharacterTextSplitter 是其中最基础、最通用的分割器。
使用 CharacterTextSplitter 时,需注意参数配置的合理性,尤其是 chunk_size 和 chunk_overlap 的关系,避免出现分割异常。"""
# 执行分割
texts = text_splitter.create_documents([long_text])
# 输出结果
print(f"分割后文本块数量:{len(texts)}")
for i, text in enumerate(texts):
print(f"\n第 {i+1} 个文本块:")
print(text.page_content)五 HTMLHeaderTextSplitter 是什么?
HTMLHeaderTextSplitter 是 LangChain 库中专门处理 HTML 文本的分割器,核心作用是:
- 解析 HTML 字符串,提取其中的标题标签(h1-h6)和对应的正文内容;
- 按照标题的层级结构,将 HTML 内容分割成「标题 + 正文」的结构化文本块;
- 保留标题的层级关系,便于后续 LLM 理解文本的结构和上下文。
5.1、核心使用场景
- 爬取网页内容后,按标题结构拆分文本(如爬取文档、博客、帮助中心页面);
- 为 LLM 提供结构化的 HTML 文本片段,提升问答、总结的准确性;
- 保留标题层级,避免纯文本分割丢失上下文结构。
5.2、完整使用示例(Python)
1. 前置条件
pip install langchain beautifulsoup4 # beautifulsoup4是解析HTML的核心依赖
2. 代码示例
from langchain.text_splitter import HTMLHeaderTextSplitter
# 1. 定义要解析的HTML内容(示例)
html_content = """
<html>
<body>
<h1>Python入门</h1>
<p>Python是一种易上手的编程语言。</p>
<h2>基础语法</h2>
<p>变量、数据类型、运算符是Python的基础。</p>
<h3>变量定义</h3>
<p>使用等号=定义变量,如x = 10。</p>
<h2>常用库</h2>
<p>numpy、pandas是Python的常用数据处理库。</p>
</body>
</html>
"""
# 2. 初始化分割器:指定要提取的标题层级(按需求选择h1-h6)
headers_to_split_on = [
("h1", "Header 1"), # 映射h1标签为"Header 1"
("h2", "Header 2"), # 映射h2标签为"Header 2"
("h3", "Header 3") # 映射h3标签为"Header 3"
]
html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
# 3. 分割HTML内容
split_documents = html_splitter.split_text(html_content)
# 4. 输出分割结果
for doc in split_documents:
print("标题层级:", doc.metadata) # 包含标题层级的元数据
print("文本内容:", doc.page_content)
print("-" * 50)
3. 输出结果
标题层级: {'Header 1': 'Python入门'}
文本内容: Python入门
Python是一种易上手的编程语言。
--------------------------------------------------
标题层级: {'Header 1': 'Python入门', 'Header 2': '基础语法'}
文本内容: 基础语法
变量、数据类型、运算符是Python的基础。
--------------------------------------------------
标题层级: {'Header 1': 'Python入门', 'Header 2': '基础语法', 'Header 3': '变量定义'}
文本内容: 变量定义
使用等号=定义变量,如x = 10。
--------------------------------------------------
标题层级: {'Header 1': 'Python入门', 'Header 2': '常用库'}
文本内容: 常用库
numpy、pandas是Python的常用数据处理库。
--------------------------------------------------
5.3、关键参数说明
headers_to_split_on:必选,指定要提取的标题标签及别名,格式为[(标签名, 别名), ...];return_each_line:可选,默认False,若设为True,则每行文本单独分割(适合长文本);strip_headers:可选,默认False,若设为True,则分割后的文本不包含标题本身,只保留正文。
5.4、进阶用法:结合 URL 加载 HTML
from langchain.document_loaders import AsyncHtmlLoader
from langchain.text_splitter import HTMLHeaderTextSplitter
# 1. 加载网页HTML
url = "https://example.com/python-guide"
loader = AsyncHtmlLoader([url])
html_doc = loader.load()[0].page_content
# 2. 分割HTML内容
headers_to_split_on = [("h1", "H1"), ("h2", "H2")]
splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
split_docs = splitter.split_text(html_doc)
# 3. 输出结果
for doc in split_docs:
print(f"层级:{doc.metadata} | 内容:{doc.page_content[:50]}...")
总结
HTMLHeaderTextSplitter是 LangChain 中解析 HTML 并按标题层级分割文本的工具,依赖beautifulsoup4解析 HTML;- 核心优势是保留标题层级的元数据,让分割后的文本具备结构化上下文;
- 常用场景是网页内容爬取、文档解析后为 LLM 提供结构化文本片段。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)