MedPlan: 基于两阶段RAG的个性化医疗治疗方案生成系统
MedPlan提出了一种基于两阶段RAG的个性化医疗治疗方案生成系统,通过模拟临床医生的SOAP诊断流程,显著提升了治疗方案的准确性和个性化水平。该系统首先基于患者主观症状和客观检查数据生成临床评估,再结合历史记录和相似病例生成治疗方案。实验表明,MedPlan在BLEU等指标上较基线方法提升约6倍,临床医生评估显示其方案质量提升66%。该系统已部署实际临床环境,采用React前端和FastAPI
MedPlan: 基于两阶段RAG的个性化医疗治疗方案生成系统
论文信息
| 项目 | 内容 |
|---|---|
| 论文标题 | MedPlan: A Two-Stage RAG-Based System for Personalized Medical Plan Generation |
| 作者 | Hsin-Ling Hsu, Cong-Tinh Dao, Luning Wang, Zitao Shuai, et al. |
| 机构 | 台湾政治大学、交通大学、密歇根大学、史蒂文斯理工学院、亚东纪念医院、佛罗里达国际大学 |
| 发表会议 | ACL 2025 Industry Track |
| 论文链接 | arXiv:2503.17900 |
| 代码仓库 | GitHub |
1. 研究背景与问题定义
1.1 医疗AI系统的现状与不足
尽管大语言模型(LLM)在电子健康记录(EHR)领域取得了显著进展,但现有系统存在一个关键缺陷:大多数系统聚焦于诊断评估(Assessment),而忽视了结构化的治疗方案规划(Plan)。
论文识别出现有方法的三大局限性:
| 局限性 | 具体问题 |
|---|---|
| 一次性生成 | 直接从临床数据生成治疗方案,未遵循临床医生的顺序认知推理过程 |
| 缺乏个性化上下文 | 很少整合患者特定的历史背景,如既往病史、历史治疗反应 |
| 信息混淆 | 未能有效区分主观患者叙述(Subjective)与客观临床测量(Objective) |
1.2 SOAP方法论
SOAP是临床文档和推理的黄金标准,将临床信息组织为结构化的顺序决策过程:
| 组件 | 含义 | 示例 |
|---|---|---|
| S (Subjective) | 患者主观叙述 | “我感觉胸闷、呼吸困难” |
| O (Objective) | 客观检查数据 | 血压160/100mmHg,心电图异常 |
| A (Assessment) | 临床评估诊断 | 高血压合并冠心病可能 |
| P (Plan) | 治疗方案计划 | 降压药物调整、心脏导管检查 |
2. 系统架构
2.1 整体设计
MedPlan采用两阶段架构,模拟临床医生的推理过程:
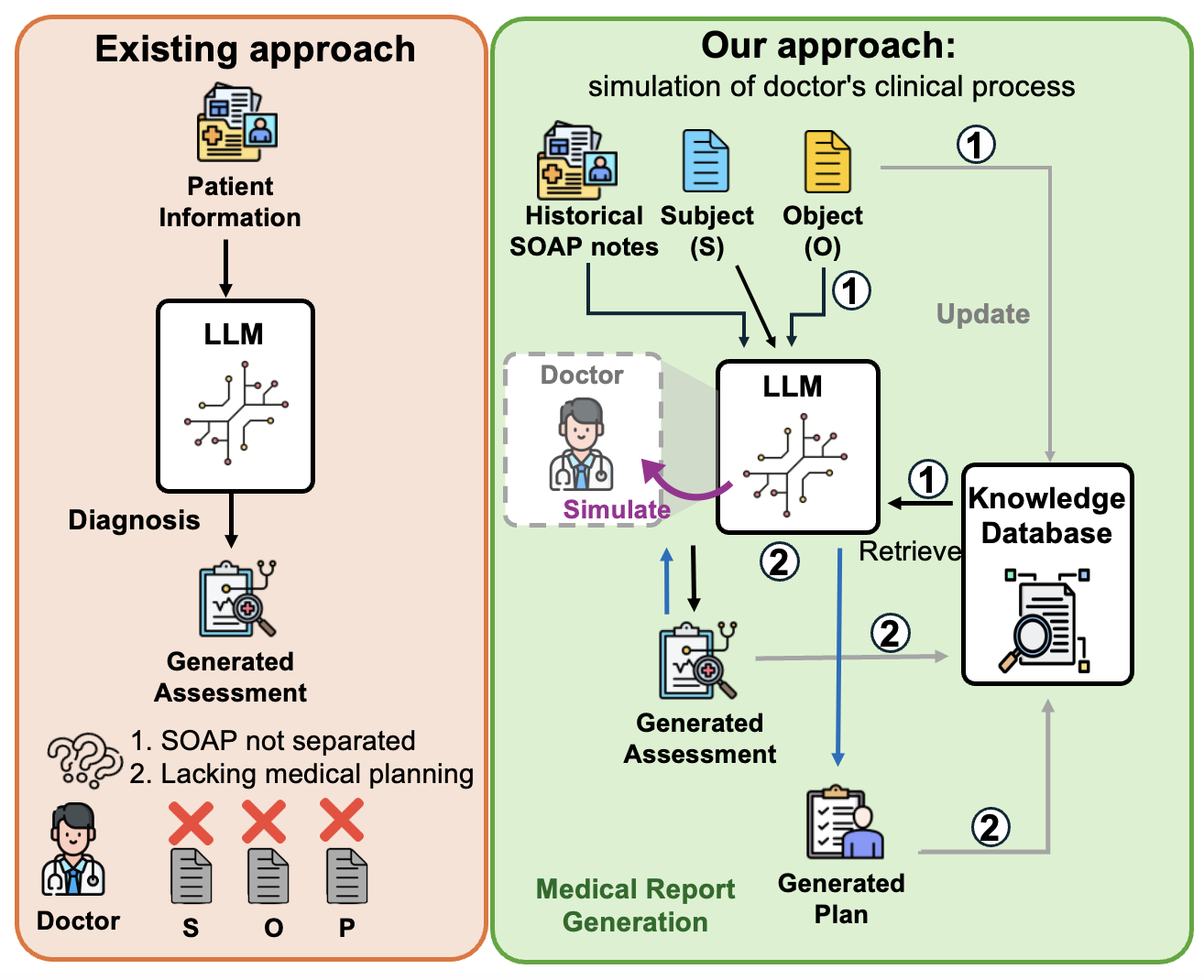
图1:现有方法(左)与MedPlan(右)的对比。MedPlan采用SOAP协议,通过LLM模拟医生诊断过程生成医疗方案
核心设计理念:
- 第一阶段:基于S(主观)和O(客观)信息生成A(临床评估)
- 第二阶段:基于生成的A和原始S、O生成P(治疗方案)
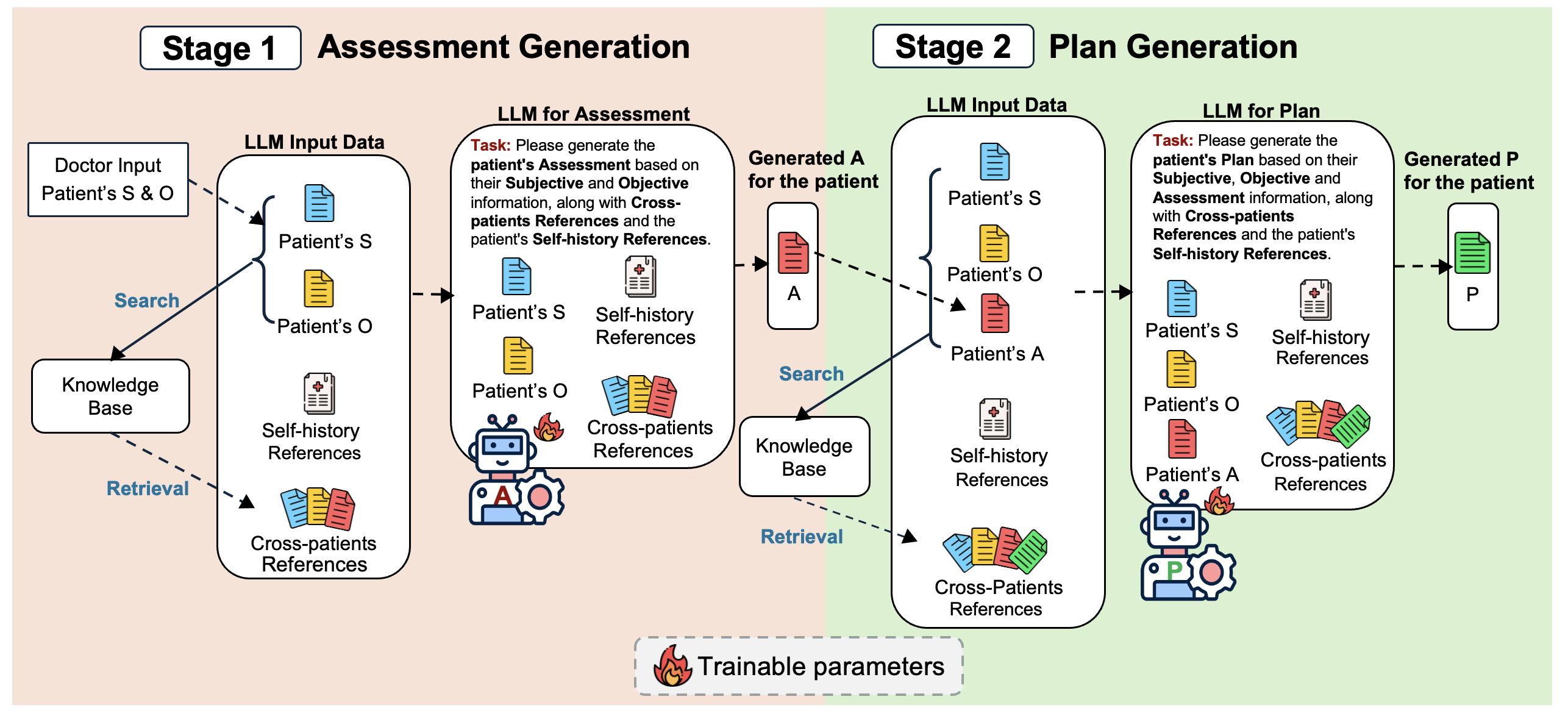
图2:MedPlan框架整体架构
2.2 两阶段生成流程
阶段一:临床评估生成(Assessment Generation)
整合患者当前S和O信息,并融入两类参考:
| 参考类型 | 说明 | 作用 |
|---|---|---|
| 自我历史参考 | 患者前期SOAP记录 | 提供个体化纵向信息 |
| 跨患者参考 | 相似病例的SOAP记录 | 借鉴类似病例的诊疗经验 |
生成公式:
A g e n = f θ A ( S , O , R S O A , R h i s t ) A_{gen} = f_{\theta_A}(S, O, R^{SOA}, R^{hist}) Agen=fθA(S,O,RSOA,Rhist)
其中 R S O A R^{SOA} RSOA 为跨患者参考, R h i s t R^{hist} Rhist 为自我历史参考。
阶段二:治疗方案生成(Plan Generation)
使用生成的评估 A g e n A_{gen} Agen 和原始S、O检索并生成治疗方案:
P g e n = f θ P ( S , O , A g e n , R S O A P , R h i s t ) P_{gen} = f_{\theta_P}(S, O, A_{gen}, R^{SOAP}, R^{hist}) Pgen=fθP(S,O,Agen,RSOAP,Rhist)
2.3 两步检索机制
每个阶段的检索采用两步精细化策略:
| 步骤 | 方法 | 说明 |
|---|---|---|
| 第一步:粗筛 | BM25 + 双编码器语义搜索 | 混合检索获取候选集 |
| 第二步:精排 | 交叉编码器重排序 | 深度语义匹配精细化选择 |
关键参数设置:
- N h i s t = 20 N_{hist} = 20 Nhist=20:自我历史记录数量
- N r e f = 10 N_{ref} = 10 Nref=10:跨患者参考数量
- N s i m = 80 N_{sim} = 80 Nsim=80:初始候选数量
3. 实验设置
3.1 数据集
| 配置项 | 设置 |
|---|---|
| 数据来源 | 台湾亚东纪念医院(FEMH)2021年数据 |
| 记录规模 | 350,684份门诊和急诊EHR SOAP记录 |
| 患者数量 | 55,890名患者 |
| 预处理 | 删除短于2字符的记录,规范化文本 |
数据划分策略(患者中心采样):
- RAG知识库:6,000名患者记录
- 训练/测试集:3,000名患者记录
3.2 实现细节
| 配置项 | 设置 |
|---|---|
| 微调框架 | Unsloth |
| 微调方法 | LoRA(参数高效微调) |
| 嵌入模型 | OpenAI text-embedding-3-large |
| 重排序模型 | VoyageAI Reranker-2 |
| 硬件环境 | NVIDIA RTX 6000 Ada GPUs |
| 最大序列长度 | 65,536 tokens |
3.3 基线模型
| 模型 | 类型 |
|---|---|
| o1 | OpenAI闭源模型 |
| GPT-4o | OpenAI闭源模型 |
| Medical-Llama3-8B | 医疗领域微调开源模型 |
| Bio-Medical-Llama3-8B | 生物医学领域微调模型 |
| Medical-Mixtral-7B-v2k | 医疗领域MoE模型 |
4. 实验结果
4.1 治疗方案生成性能
表1:不同模型和配置的治疗方案生成性能对比
| 方法 | 模型 | 自我历史 | 指令微调 | 跨患者 | BLEU | METEOR | BERTScore |
|---|---|---|---|---|---|---|---|
| S+O→P | o1 | - | - | - | 0.016 | 0.140 | 0.817 |
| S+O→P | GPT-4o | - | - | - | 0.029 | 0.166 | 0.827 |
| S+O→P | Medical-Llama3-8B | - | - | - | 0.053 | 0.173 | 0.847 |
| S+O→P | Medical-Llama3-8B | ✓ | ✓ | - | 0.179 | 0.307 | 0.867 |
| S+O→P | Medical-Llama3-8B | ✓ | ✓ | ✓ | 0.291 | 0.477 | 0.908 |
| S+O→A→P (MedPlan) | Medical-Llama3-8B | ✓ | ✓ | ✓ | 0.315 | 0.516 | 0.916 |
| S+O→A→P (MedPlan) | Medical-Mixtral-7B | ✓ | ✓ | ✓ | 0.318 | 0.521 | 0.917 |
关键发现:
- MedPlan(S+O→A→P)在所有骨干模型上均优于直接生成方案(S+O→P)
- RAG使BLEU从0.053提升至0.307(约6倍提升)
- 两阶段方法进一步将BLEU从0.307提升至0.315
4.2 临床评估生成性能
表2:患者特定评估生成性能对比
| 模型 | 自我历史 | 指令微调 | 跨患者 | BLEU | METEOR | BERTScore |
|---|---|---|---|---|---|---|
| Medical-Mixtral-7B | ✓ | - | - | 0.302 | 0.469 | 0.906 |
| Medical-Mixtral-7B | ✓ | ✓ | - | 0.485 | 0.654 | 0.941 |
| Medical-Mixtral-7B | ✓ | ✓ | ✓ | 0.493 | 0.666 | 0.943 |
4.3 定性案例分析
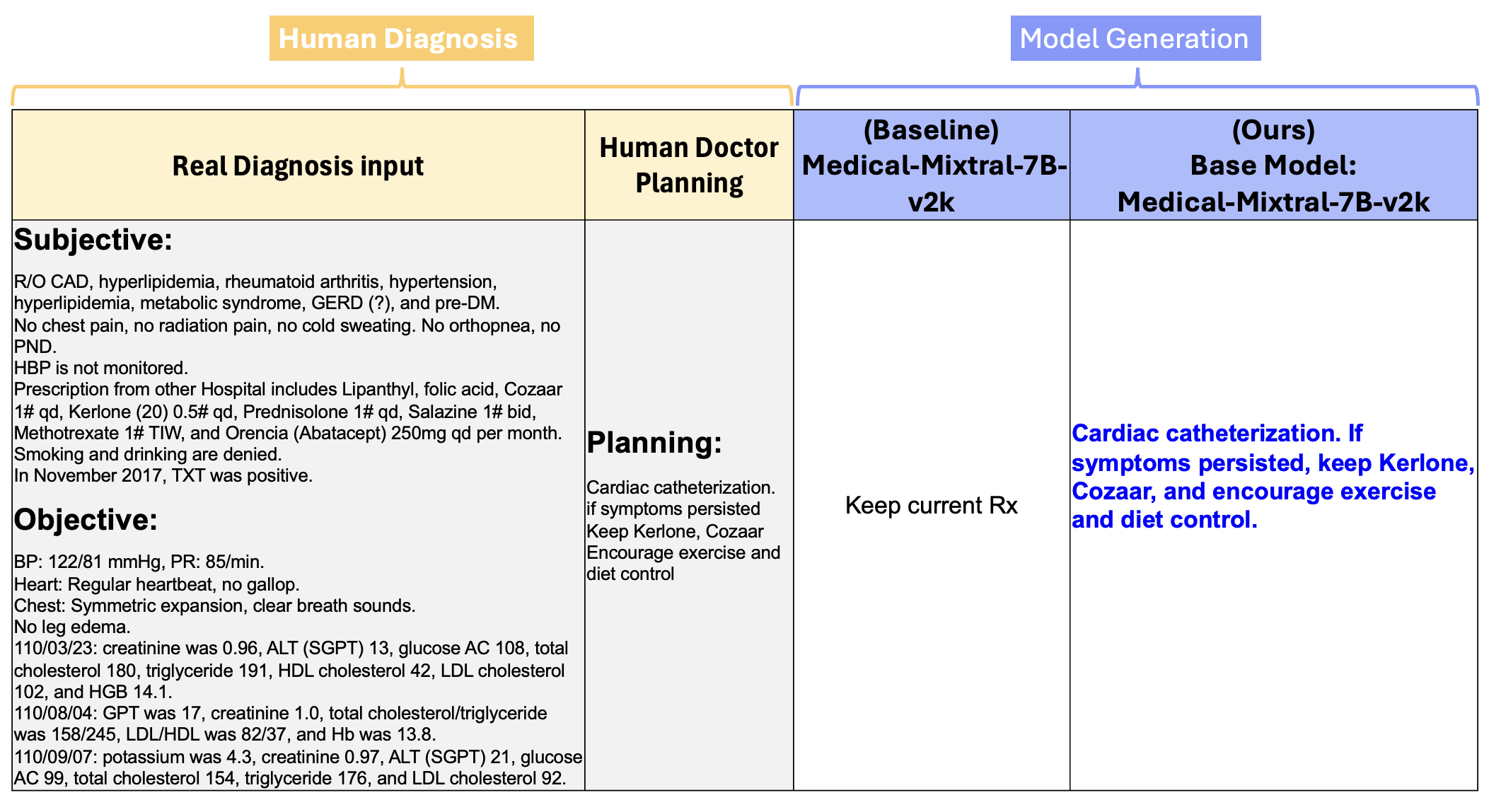
图3:人类医生、基线LLM与MedPlan的治疗方案生成对比
面对复杂病例(高脂血症、高血压、代谢综合征、糖尿病前期等心血管风险因素):
| 来源 | 生成的治疗方案 |
|---|---|
| 基线模型 | “Keep current Rx”(保持当前处方) |
| MedPlan | “Cardiac catheterization. If symptoms persist, keep Kerlone, Cozaar, and encourage exercise and diet control”(心脏导管检查。如症状持续,继续服用Kerlone、Cozaar,并鼓励运动和饮食控制) |
4.4 临床医生评估
MedPlan相比基线方法在临床评估上展示约66%的改进
5. 临床应用系统
5.1 系统架构
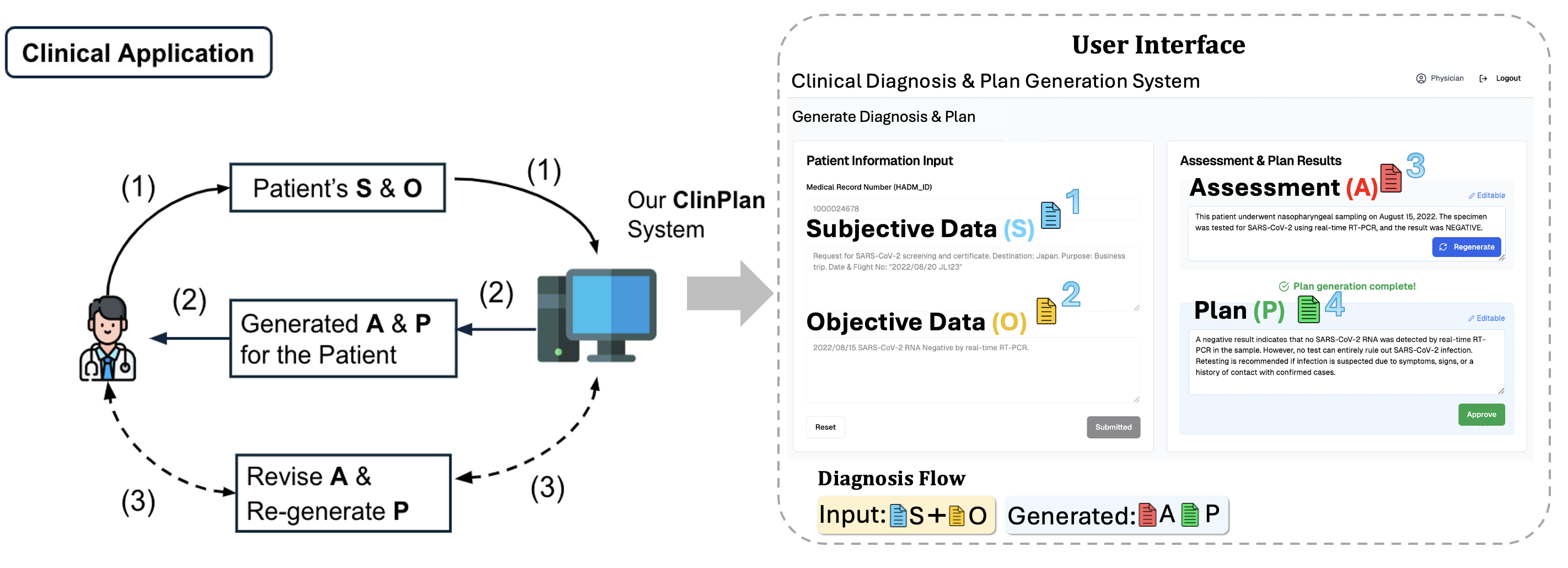
图4:MedPlan临床应用系统概览
5.2 技术实现
| 组件 | 技术栈 |
|---|---|
| 前端界面 | React |
| 后端服务 | FastAPI + RESTful API |
| 患者数据存储 | MSSQL数据库 |
| 向量检索 | Weaviate向量数据库 |
| 核心模型 | 两个专用LLM(A生成 + P生成) |
6. 技术贡献总结
6.1 核心创新
| 创新点 | 技术贡献 | 解决的问题 |
|---|---|---|
| 两阶段SOAP对齐架构 | 先生成评估再生成方案 | 符合临床推理流程 |
| 双类型RAG增强 | 自我历史 + 跨患者参考 | 个性化与经验借鉴 |
| 两步检索精排 | 混合检索 + 交叉编码器 | 高效精准的知识检索 |
| 端到端临床系统 | 完整的生产级原型 | 可实际部署应用 |
6.2 性能提升汇总
| 对比场景 | 指标 | 提升幅度 |
|---|---|---|
| 无RAG → 有RAG | BLEU | +0.254(约6倍) |
| 直接生成 → 两阶段 | BLEU | +0.008 |
| 基线 → MedPlan | 临床评估 | +66% |
7. 局限性与未来方向
7.1 当前局限
| 局限性 | 说明 |
|---|---|
| 数据依赖性 | 仅在单一医院数据上验证 |
| 语言限制 | 目前仅支持中文EHR |
| 专科覆盖 | 未验证在所有专科的泛化性 |
| 实时性 | 两阶段生成增加延迟 |
7.2 未来研究方向
- 多中心验证:在多家医院数据上验证泛化性
- 多语言支持:扩展到英文等其他语言EHR
- 专科适配:针对特定专科(如肿瘤、心内科)的定制优化
- 实时优化:通过模型蒸馏等方法降低推理延迟
8. 实践启示
8.1 医疗AI系统设计建议
- 遵循临床工作流:系统设计应对齐医生的实际推理过程(如SOAP)
- 整合患者纵向数据:历史记录是个性化治疗的关键
- 借鉴相似病例:跨患者参考可提升方案质量
- 区分信息类型:主观叙述与客观数据应分别处理
8.2 伦理考量
- MedPlan是辅助工具,最终决策权在医生
- 所有数据经过脱敏处理
- 系统经过医院伦理委员会审批
参考文献
- Lewis, P., et al. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. NeurIPS 2020.
- Weed, L.L. (1968). Medical records that guide and teach. New England Journal of Medicine.
- Touvron, H., et al. (2023). LLaMA: Open and Efficient Foundation Language Models. arXiv:2302.13971.

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 25
25 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)