LangGraph生态与RAG结合应用的最佳实践
随着人工智能和大语言模型 (LLM) 技术的快速发展,检索增强生成 (Retrieval-Augmented Generation, RAG) 已成为构建智能应用的重要技术手段。然而,传统的 RAG 实现往往往往缺乏灵活性和可控性,难以应对复杂业务场景的需求。LangGraph 作为一个新兴的工作流编排框架,为我们提供了强大的状态管理和复杂流程控制能力。它允许开发者构建具有循环、条件分支和持久化状
前言
随着人工智能和大语言模型 (LLM) 技术的快速发展,检索增强生成 (Retrieval-Augmented Generation, RAG) 已成为构建智能应用的重要技术手段。然而,传统的 RAG 实现往往往往缺乏灵活性和可控性,难以应对复杂业务场景的需求。
LangGraph 作为一个新兴的工作流编排框架,为我们提供了强大的状态管理和复杂流程控制能力。它允许开发者构建具有循环、条件分支和持久化状态的复杂 AI 工作流,极大地增强了 RAG 系统的灵活性和可控性。
本文档旨在介绍如何在实际项目中将 LangGraph 与 RAG 技术相结合,构建高效、灵活且易于维护的智能应用。
通过此文档的阅读,你将收获
- 深入理解 LangGraph 的基本概念和核心组件
- 掌握 LangGraph 与 RAG 结合的方法论和实施策略
- 学会设计和实现基于 LangGraph 的 RAG 工作流
- 了解在实际项目中应用 LangGraph+RAG 的最佳实践
- 掌握复杂状态管理和流程控制技巧
适用范围
本文档适用于以下场景和人群:
- 希望构建复杂 AI 工作流的研发工程师
- 需要增强 RAG 系统灵活性和可控性的 AI 架构师
- 对 LangGraph 技术感兴趣的技术负责人
- 正在实施或计划实施 RAG 项目的团队
特别适用于具有以下需求的项目:
- 需要多步骤、复杂决策流程的 RAG 应用
- 需要状态持久化和恢复的工作流
- 需要条件分支和循环处理的智能应用
- 需要模块化、可扩展的 AI 系统架构
具体方案
1. LangGraph 核心概念
LangGraph 是基于 LangChain 构建的一个工作流编排框架,其核心概念包括:
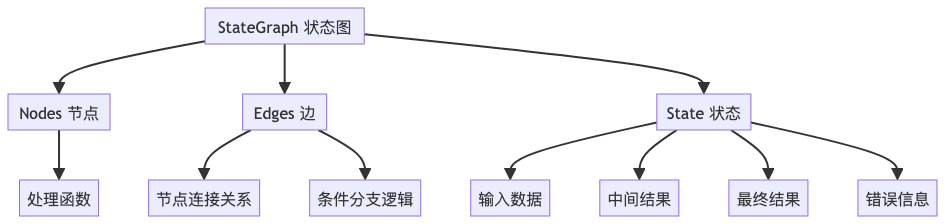
StateGraph(状态图)
状态图是 LangGraph 的核心抽象,它定义了工作流的状态和节点之间的转换关系。在我们的项目中,定义了多种状态图,例如RAGState:
class RAGState(TypedDict, total=False):
"""
RAG工作流的状态定义
"""
# 输入
query_params: QueryParams
query_text: str
tag_key: Optional[str]
form_params: Optional[List[str]]
# 中间结果
retrieval_result: QueryResult
reranked_chunks: List[Dict[str, Any]]
flow_chunks: List[FlowChunk]
version_info: Dict[str, Any]
# 最终结果
final_answer: Dict[str, Any]
error: strNodes(节点)
节点代表工作流中的一个处理步骤,每个节点都是一个函数,接收当前状态并返回状态更新。例如_retrieve_node:
def _retrieve_node(self, state: RAGState) -> Dict[str, Any]:
"""
检索节点:执行基于流程分析的知识检索
"""
try:
# 执行检索
retrieval_result = flow_retrieval_service.retrieve(state["query_params"])
return {
"retrieval_result": retrieval_result,
"error": None
}
except Exception as e:
return {
"error": f"检索失败: {str(e)}"
}Edges(边)
边定义了节点之间的连接关系,决定了工作流的执行路径。在_build_graph方法中定义了边的关系:
def _build_graph(self) -> StateGraph:
"""
构建LangGraph状态图
"""
# 创建状态图
graph = StateGraph(RAGState)
# 添加节点
graph.add_node("retrieve", self._retrieve_node)
graph.add_node("validate_result", self._validate_result_node)
graph.add_node("get_version_info", self._get_version_info_node)
graph.add_node("finalize", self._finalize_node)
# 添加边
graph.set_entry_point("retrieve")
graph.add_edge("retrieve", "validate_result")
graph.add_edge("validate_result", "get_version_info")
graph.add_edge("get_version_info", "finalize")
graph.add_edge("finalize", END)
return graph.compile()LangGraph 核心组件关系图:
2. RAG 与 LangGraph 的结合模式
在我们的项目中,RAG 与 LangGraph 的结合主要体现在以下几个方面:
模块化 RAG 服务
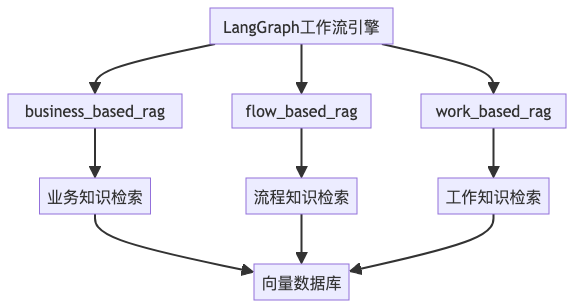
我们将 RAG 功能拆分为多个独立的服务模块,如business_based_rag、flow_based_rag和work_based_rag,每个模块都可以独立集成到 LangGraph 工作流中。
RAG 模块化架构图:
状态驱动的检索过程
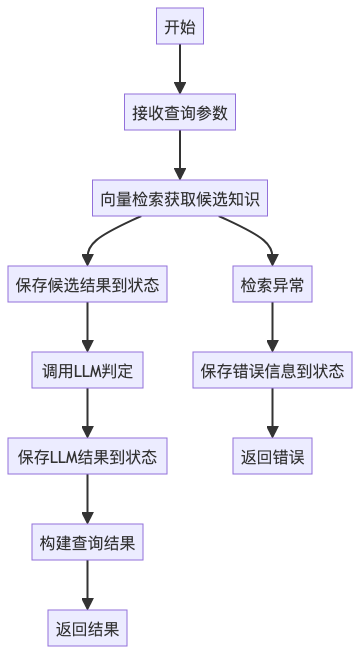
通过 LangGraph 的状态管理,我们将 RAG 的检索过程分解为多个步骤,每一步的结果都保存在状态中,便于调试和优化:
async def retrieve(self, query_params: QueryParams) -> QueryResult:
"""
检索最匹配的业务知识
Args:
query_params: 查询参数
Returns:
查询结果
"""
try:
# 1. 向量检索获取Top3候选业务知识
candidate_chunks = await self._vector_retrieval(query_params)
# 2. 调用LLM进行判定
llm_judgment_result = await self._llm_judgment(query_params, candidate_chunks)
# 3. 构建查询结果
query_result = self._build_query_result(llm_judgment_result, candidate_chunks)
return query_result
except Exception as e:
raise Exception(f"检索失败: {str(e)}")状态驱动检索流程图:
条件分支处理
利用 LangGraph 的条件边功能,可以根据中间结果决定下一步的执行路径。例如在流程检索中,根据检索结果的有效性决定是否继续处理:
def _validate_result_node(self, state: RAGState) -> Dict[str, Any]:
"""
验证结果节点:检查检索结果是否有效
"""
try:
# 检查是否已有错误
if state.get("error"):
# 如果已有错误,直接返回
return {}
# 检查retrieval_result是否存在
if "retrieval_result" not in state:
return {
"retrieval_result": QueryResult(flowId=None, nodeId=None, nodeIds=None)
}
retrieval_result = state["retrieval_result"]
# 验证检索结果
if retrieval_result.flowId or retrieval_result.nodeId or retrieval_result.nodeIds:
# 结果有效,返回成功状态
return {}
else:
# 结果无效,返回空结果
return {
"retrieval_result": QueryResult(flowId=None, nodeId=None, nodeIds=None)
}
except Exception as e:
return {
"error": f"结果验证失败: {str(e)}"
}3. 工作流设计模式(以flow_base_rag为例)
我们针对不同业务场景,设计了 3 类轻量化的 LangGraph 工作流模式,每个模式职责明确、流程清晰,适配不同的 RAG 处理需求:
1. RAG 工作流(RAGWorkflow)
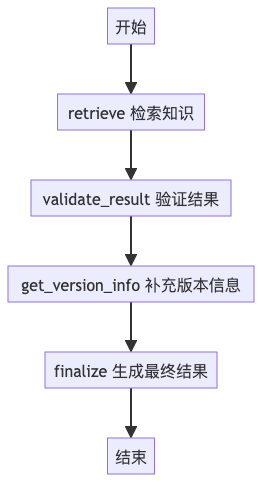
核心用途:完成从知识检索到结果输出的完整 RAG 流程核心节点(4 个):
retrieve:执行核心知识检索,从数据库获取匹配的内容validate_result:校验检索结果有效性(比如是否为空、是否符合业务规则)get_version_info:补充结果的版本信息(适配多环境 / 多版本场景)finalize:整合所有信息,生成最终可输出的结果
简化代码示例:
def _build_graph(self) -> StateGraph:
# 1. 创建状态图(定义流程可传递的状态数据)
graph = StateGraph(RAGState)
# 2. 注册节点(每个节点对应一个处理函数)
graph.add_node("retrieve", self._retrieve_node)
graph.add_node("validate_result", self._validate_result_node)
graph.add_node("get_version_info", self._get_version_info_node)
graph.add_node("finalize", self._finalize_node)
# 3. 定义执行顺序:检索→验证→补版本→生成最终结果
graph.set_entry_point("retrieve") # 流程入口
graph.add_edge("retrieve", "validate_result")
graph.add_edge("validate_result", "get_version_info")
graph.add_edge("get_version_info", "finalize")
graph.add_edge("finalize", END) # 流程结束
return graph.compile() # 编译生效流程示意图:
2. 检索工作流(RetrieveWorkflow)
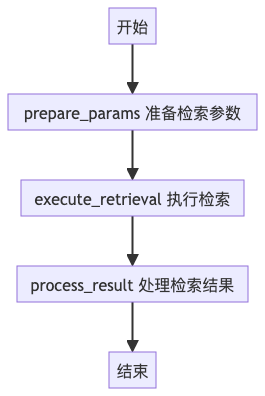
核心用途:专注处理 “检索” 单一任务,轻量化完成参数准备→检索→结果处理核心节点(3 个):
prepare_params:整理检索参数(比如格式化用户输入、补充业务标识)execute_retrieval:执行具体的检索逻辑(核心检索动作)process_result:对检索结果做基础处理(比如格式转换、简单过滤)
简化代码示例:
def __init__(self):
# 1. 创建状态图
self.graph = StateGraph(WorkflowState)
# 2. 注册节点
self.graph.add_node("prepare_params", self.prepare_params)
self.graph.add_node("execute_retrieval", self.execute_retrieval)
self.graph.add_node("process_result", self.process_result)
# 3. 定义执行顺序:准备参数→执行检索→处理结果
self.graph.set_entry_point("prepare_params")
self.graph.add_edge("prepare_params", "execute_retrieval")
self.graph.add_edge("execute_retrieval", "process_result")
self.graph.add_edge("process_result", END)
# 4. 编译(无需持久化状态,轻量化运行)
self.app = self.graph.compile()流程示意图:
3. 存储工作流(StorageWorkflow)
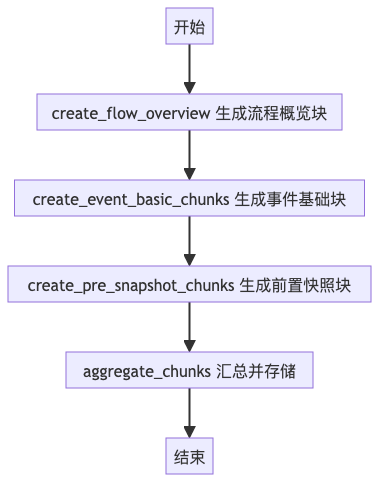
核心用途:专门处理 RAG 所需数据的存储,把不同类型的信息整理后存入数据库核心节点(4 个):
create_flow_overview:生成 “流程概览” 类数据块(Chunk)create_event_basic_chunks:生成 “事件基础信息” 类数据块create_pre_snapshot_chunks:生成 “前置快照” 类数据块aggregate_chunks:汇总所有数据块,统一存入向量数据库
简化代码示例:
def _build_graph(self) -> StateGraph:
# 1. 创建状态图
graph = StateGraph(StorageWorkflowState)
# 2. 注册节点
graph.add_node("create_flow_overview", self._create_flow_overview_node)
graph.add_node("create_event_basic_chunks", self._create_event_basic_chunks_node)
graph.add_node("create_pre_snapshot_chunks", self._create_pre_snapshot_chunks_node)
graph.add_node("aggregate_chunks", self._aggregate_chunks_node)
# 3. 定义执行顺序:生成各类数据块→汇总存储
graph.set_entry_point("create_flow_overview")
graph.add_edge("create_flow_overview", "create_event_basic_chunks")
graph.add_edge("create_event_basic_chunks", "create_pre_snapshot_chunks")
graph.add_edge("create_pre_snapshot_chunks", "aggregate_chunks")
graph.add_edge("aggregate_chunks", END)
return graph.compile()流程示意图:
成果展示
通过将 LangGraph 与 RAG 技术相结合,我们的项目取得了以下显著成果:
1. 工作流可视化和可调试性
LangGraph 提供了强大的状态管理和可视化能力,使复杂的工作流变得透明和可调试。每一个处理步骤的状态变化都可以被追踪和分析,大大降低了调试难度。
2. 灵活的流程控制
通过 LangGraph 的条件边和循环机制,我们可以轻松实现复杂的业务逻辑。例如,在 RAG 流程中,可以根据检索结果的质量决定是否重新检索或调整检索策略。
3. 模块化架构
将 RAG 功能拆分为多个独立模块,并通过 LangGraph 进行编排,实现了高度模块化的架构。这种设计使系统更容易扩展和维护。
4. 高性能和可扩展性
LangGraph 的工作流机制允许我们并行处理多个任务,并通过状态持久化机制支持长时间运行的工作流,满足了高性能和可扩展性的要求。
5. 易于测试和验证
每个工作流节点都是独立的函数,可以单独进行单元测试。同时,整个工作流也可以作为一个整体进行集成测试。
总结
LangGraph 与 RAG 的结合为构建复杂 AI 应用提供了强有力的支持。通过合理设计工作流和状态管理,我们可以构建出既灵活又可靠的智能系统。
在实际应用中,需要注意以下几点:
- 合理划分工作流节点:节点应该具有明确的职责,避免过于复杂或过于细碎。
- 状态设计的重要性:良好的状态设计是工作流成功的关键,需要仔细考虑哪些信息需要在节点间传递。
- 错误处理机制:在复杂工作流中,错误处理变得更加重要,需要设计合理的错误恢复机制。
- 性能优化:对于计算密集型节点,应考虑并行处理或异步执行。
- 监控和日志:复杂工作流需要完善的监控和日志机制,以便及时发现问题。
参考文档

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 9
9 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)