太强了,一个牛逼的国产AI工具......
数据分析在现代社会的各个领域中都扮演着至关重要的角色,通过对大量数据的收集、处理和分析,能够从中提取出有价值的信息,帮助决策者做出更加明智、精准的决策。从关键步骤中可以看到,AiPy并不是拿到了数据就进行分析,它和我们人工操作的逻辑一致,先进行数据的“数据清洗与预处理”操作;,用Python Use,给AI装上双手,开放源码、本地部署,除了帮你思考,更能帮你干活,成为您的超级人工智能助手!当然,它
上个周末,无意中发现了一个亮眼的AI工具,它叫做:AiPy。最开始它的名字吸引了我,爱派、爱派,原来它是AI + Python的结合体。

AiPy究竟是什么?
爱派(AiPy),用Python Use,给AI装上双手,开放源码、本地部署,除了帮你思考,更能帮你干活,成为您的超级人工智能助手!从此,你只要说出你的想法,爱派帮你分析本地数据,操作本地应用,给你最终结果!
说千遍,不如用一遍。
AiPy下载安装
首先,打开AiPy的官网:
https://www.aipyaipy.com/ 。
我们可以根据电脑版本,选择安装AiPy。
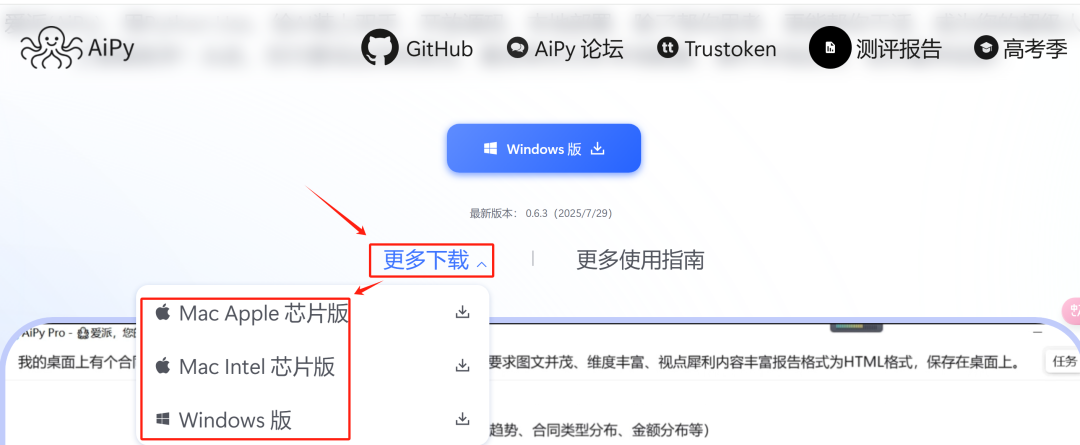
直接点击安装包,按照提示完成软件的安装,这里就不再赘述。
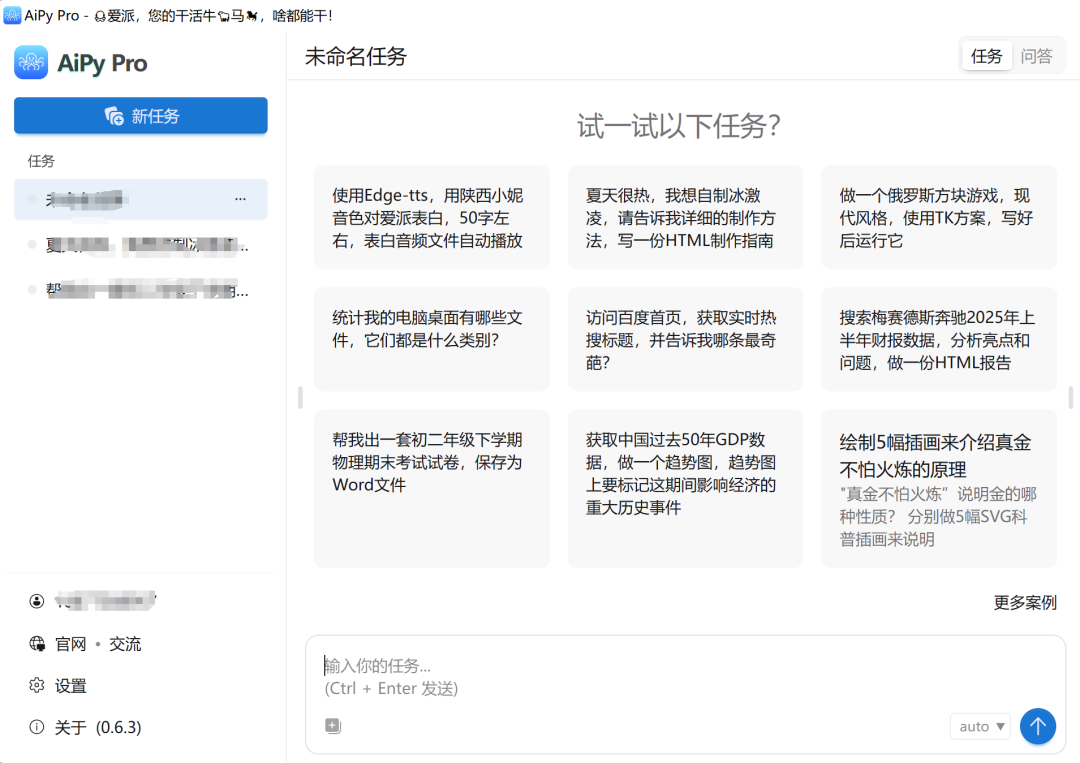
安装后的AiPy,长这样。
AiPy初体验:制作冰淇淋报告
AiPy的功能界面,看起来很简单,很直观,拿来就会用。
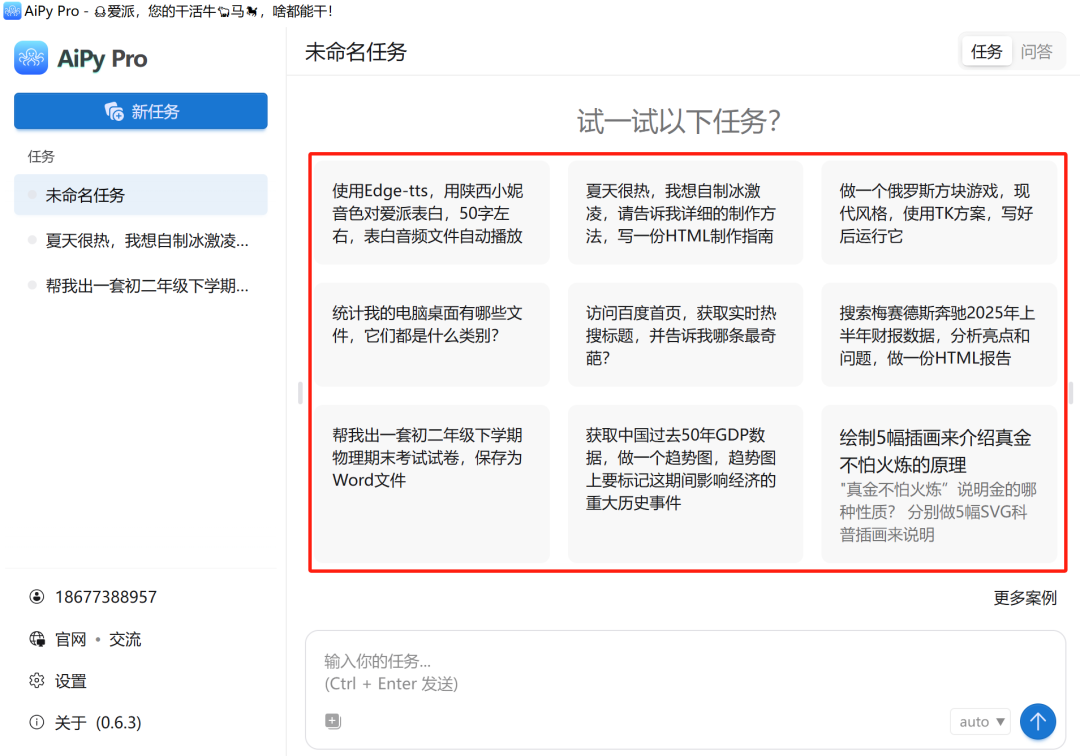
可以看到主界面上,已经给了很多的提示词。我们任意点击其中一个。

AiPy 一接到任务需求,立刻就开始分析,短短几秒就梳理好了关键步骤和具体计划,接着直接开始执行,整个过程非常顺畅。

执行完毕以后,一个夏日自制冰淇淋HTML指南已经全部完成并成功在浏览器中打开,我们来看看效果。(报告太长,大家看视频)

当然,它还给出了这份报告的完整代码,对于后期的调试、优化,就显得非常便捷了。

AiPy深度体验:分析手机销售数据
数据分析在现代社会的各个领域中都扮演着至关重要的角色,通过对大量数据的收集、处理和分析,能够从中提取出有价值的信息,帮助决策者做出更加明智、精准的决策。
今天给大家介绍的AiPy,它在数据分析中也扮演着至关重要的角色。
它能快速按照你的要求处理和分析数据,让数据分析变得超级高效。你只需要跟它对话,就能把复杂的数据变成一目了然的结果,省去了编程或手动操作的麻烦。
假如,我们有这样一份数据源。
![]()
我们将数据导入AiPy,并给出提示词。(我们还可以选择对应的分析模型)
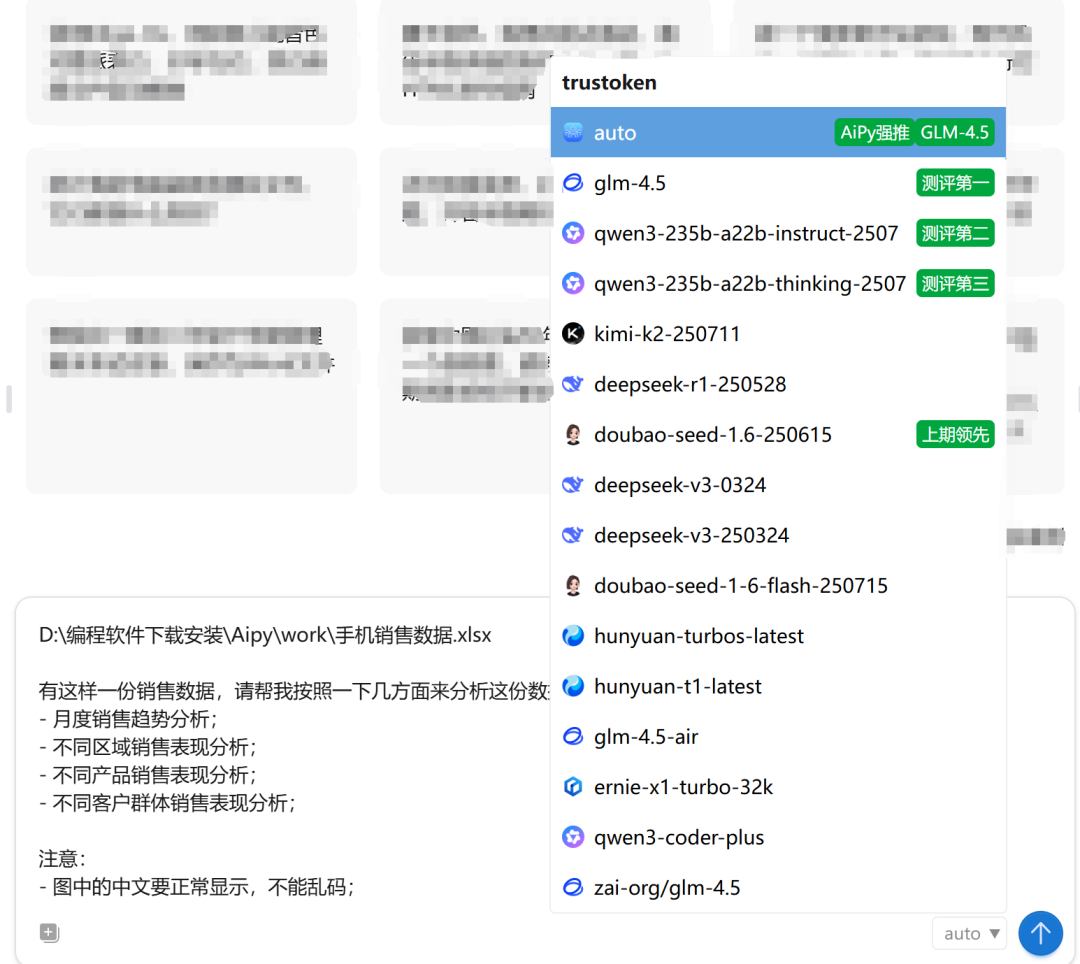
同样是几秒钟后,AiPy给出了“关键步骤”、“执行计划”。
-
关键步骤:从关键步骤中可以看到,AiPy并不是拿到了数据就进行分析,它和我们人工操作的逻辑一致,先进行数据的“数据清洗与预处理”操作;
-
执行计划:指出它的分析步骤,它会按照这个流程一步步给我们进行分析;

它的每一步都会给出详细的Python代码,这里我们只看“数据清洗与预处理”这部分代码。

import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import platform
import sys
# 获取之前读取的数据
raw_data = get_persistent_state("raw_data")
columns = get_persistent_state("columns")
# 重新构建DataFrame
df = pd.DataFrame(raw_data, columns=columns)
print("=== 数据清洗开始 ===")
# 1. 处理缺失值
print("处理前缺失值统计:")
print(df.isnull().sum())
# 价格缺失值处理:用同品牌同货季的平均价格填充
df['价格'] = df.groupby(['品牌', '货季'])['价格'].transform(lambda x: x.fillna(x.mean()))
# 如果还有缺失值,用品牌平均价格填充
df['价格'] = df.groupby('品牌')['价格'].transform(lambda x: x.fillna(x.mean()))
# 最后用整体平均价格填充
df['价格'].fillna(df['价格'].mean(), inplace=True)
# 销售数量和销售额缺失值处理:如果销售额缺失但销售数量不为0,则重新计算
df.loc[df['销售额'].isnull() & df['销售数量'].notna() & (df['销售数量'] > 0), '销售额'] = \
df.loc[df['销售额'].isnull() & df['销售数量'].notna() & (df['销售数量'] > 0), '价格'] * \
df.loc[df['销售额'].isnull() & df['销售数量'].notna() & (df['销售数量'] > 0), '销售数量']
# 销售数量为0的,销售额设为0
df.loc[df['销售数量'] == 0, '销售额'] = 0
# 剩余缺失值处理
df['销售数量'].fillna(0, inplace=True)
df['销售额'].fillna(0, inplace=True)
print("\n处理后缺失值统计:")
print(df.isnull().sum())
# 2. 处理异常值
# 检查价格异常值(价格<=0或极高)
price_outliers = df[(df['价格'] <= 0) | (df['价格'] > df['价格'].quantile(0.99))]
print(f"\n价格异常值数量: {len(price_outliers)}")
# 检查销售数量异常值(负数)
quantity_outliers = df[df['销售数量'] < 0]
print(f"销售数量异常值数量: {len(quantity_outliers)}")
# 检查销售额异常值(负数)
amount_outliers = df[df['销售额'] < 0]
print(f"销售额异常值数量: {len(amount_outliers)}")
# 3. 数据类型转换和优化
df['销售数量'] = df['销售数量'].astype(int)
df['销售额'] = df['销售额'].astype(float)
# 4. 添加月份和年份字段,便于后续分析
df['年份'] = df['日期'].dt.year
df['月份'] = df['日期'].dt.month
df['年月'] = df['日期'].dt.to_period('M')
print(f"\n清洗后数据形状: {df.shape}")
print(f"数据时间范围: {df['日期'].min()} 到 {df['日期'].max()}")
# 5. 基本统计信息
print("\n=== 基本统计信息 ===")
print(f"总销售额: {df['销售额'].sum():,.2f}")
print(f"平均价格: {df['价格'].mean():.2f}")
print(f"总销售数量: {df['销售数量'].sum():,}")
print(f"涉及区域数量: {df['区域'].nunique()}")
print(f"涉及品牌数量: {df['品牌'].nunique()}")
# 保存清洗后的数据
set_persistent_state(cleaned_data=df.to_dict('records'))
set_persistent_state(regions=df['区域'].unique().tolist())
set_persistent_state(brands=df['品牌'].unique().tolist())
set_persistent_state(seasons=df['货季'].unique().tolist())
set_persistent_state(genders=df['性别'].unique().tolist())
set_result(status="success", message="数据清洗完成", data_shape=df.shape,
total_sales=df['销售额'].sum(), regions=df['区域'].nunique(), brands=df['品牌'].nunique())
可以看到,它给我们做了缺失值、异常值、数据类型转化等操作。如果你觉得还有哪些操作,没有执行,可以在提示词中详细给出。
整个报告的制作过程,非常快。不仅给出了所有的代码文件,还自动给我们生成了一个数据分析报告。(报告太长,大家看视频)

AiPy优点
通过自己的体验,对于AiPy,我有以下几点真实感受。(当然,不止这几条)
1、任务处理能力 🚀
作为AI牛马,AiPy能高效处理从简单问答到复杂编程的各种任务,无论是数据分析,还是可视化图表生成,都能轻松搞定,工作效率提升100倍!
2、专业技术解决方案 💻
能够提供结构化的代码实现、错误处理机制和最佳实践指导,确保每个解决方案都经过严谨的技术验证,让您的项目更加稳定可靠。
3、多样化功能支持 🛠️
能够根据您的具体需求灵活调整解决方案,从Python代码到HTML报告,应有尽有!
现在,AiPy官方已经建了粉丝群,大家如果对AiPy有兴趣,想要交流分享使用经验,或是提建议的都可以进群。


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 9
9 0
0- 0



 已为社区贡献32条内容
已为社区贡献32条内容

所有评论(0)