阿里开源Wan2.2视频生成全家桶
Wan2.2是阿里通义万相团队推出的第二代视频生成大模型。从官方定位来看,它对标的是 Runway、Pika、可灵等闭源商业产品,目标是成为开源领域最强的视频生成模型。从技术路线上看,Wan2.2 基于架构,并在此基础上做了大量创新。引入 MoE(混合专家)架构:这是 Wan2.2 最大的技术亮点训练数据大幅扩增:图片增加了 65.6%,视频增加了 83.2%电影级美学优化:专门针对光影、构图、色

大家好,我是 Ai 学习的老章。
最近阿里放了个大招——Wan2.2 全家桶正式开源了。
这不是一个简单的版本升级,而是一整套视频生成解决方案的集体亮相:文生视频、图生视频、语音驱动视频、甚至人物动画替换,能想到的玩法几乎都给安排上了。
更让我惊喜的是,这次专门发布了一个 5B 参数的轻量版模型,在的 RTX 4090 上就能跑 720P@24fps 的视频生成,这对于咱们普通玩家来说,简直是天大的福音。
今天,就让我带大家全面解读一下这个"视频生成全家桶"。
简介:Wan2.2 是什么?
Wan2.2 是阿里通义万相团队推出的第二代视频生成大模型。从官方定位来看,它对标的是 Runway、Pika、可灵等闭源商业产品,目标是成为开源领域最强的视频生成模型。
从技术路线上看,Wan2.2 基于 Diffusion Transformer (DiT) 架构,并在此基础上做了大量创新。相比前代 Wan2.1,Wan2.2 的核心升级点包括:
- 引入 MoE(混合专家)架构:这是 Wan2.2 最大的技术亮点
- 训练数据大幅扩增:图片增加了 65.6%,视频增加了 83.2%
- 电影级美学优化:专门针对光影、构图、色调进行了精细标注
- 推出高效的 5B 轻量模型:支持消费级显卡部署
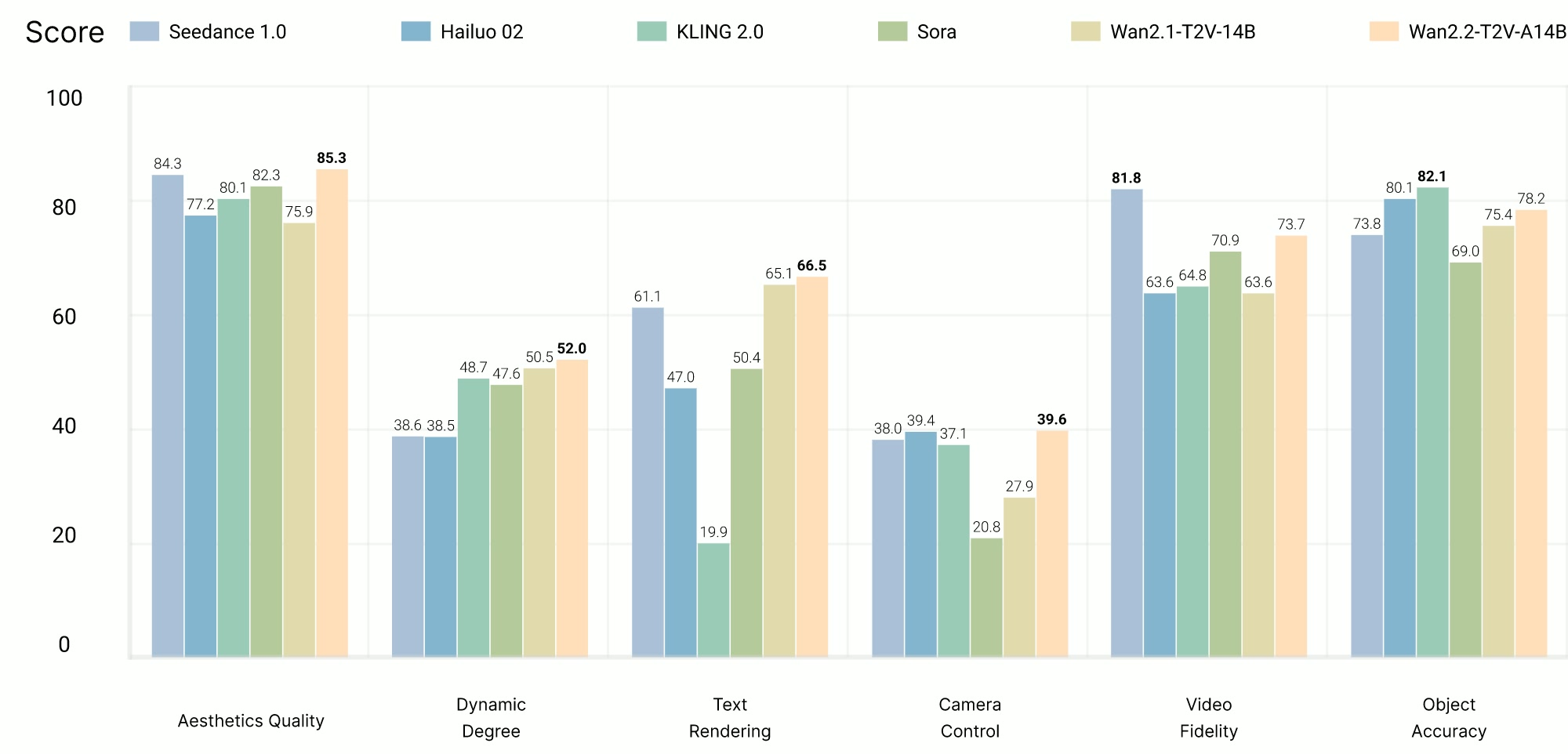
官方宣称,Wan2.2 在他们自研的 Wan-Bench 2.0 评测中,已经超越了所有开源和闭源的竞品。
模型全家桶:五大模型一览
Wan2.2 这次发布的不是单一模型,而是一整个"全家桶"。我给大家梳理一下:
| 模型名称 | 任务类型 | 参数量 | 最低显存 | 特点 |
|---|---|---|---|---|
| Wan2.2-T2V-A14B | 文生视频 | 27B (MoE) | 80GB | 文本生成视频,MoE 架构 |
| Wan2.2-I2V-A14B | 图生视频 | 27B (MoE) | 80GB | 图片驱动视频生成 |
| Wan2.2-TI2V-5B | 文图生视频 | 5B | 24GB | 轻量级,支持 T2V 和 I2V |
| Wan2.2-S2V-14B | 语音生视频 | 14B | 80GB | 音频驱动视频生成 |
| Wan2.2-Animate-14B | 人物动画 | 14B | 80GB | 人物动作迁移/替换 |
核心技术:MoE 架构详解
Mixture-of-Experts(MoE,混合专家) 架构最早在大语言模型(如 Mixtral、DeepSeek)中得到广泛应用。它的核心思想是:模型虽然总参数量很大,但每次推理只激活其中一部分参数,从而在保持性能的同时控制计算成本。
Wan2.2 把这个思路搬到了视频生成的 Diffusion 模型中,具体做法非常巧妙:
| 专家类型 | 触发条件 | 职责 |
|---|---|---|
| 高噪声专家 | 生成早期(噪点多) | 负责整体布局、构图 |
| 低噪声专家 | 生成后期(噪点少) | 负责细节打磨、画质提升 |
工作原理:
视频生成过程本质上是一个"去噪"过程。在早期阶段,画面充满噪点,此时需要模型做的是"定大方向"——人物在哪里、背景是什么、运动趋势是怎样的。这时候激活"高噪声专家"。
随着去噪的推进,画面逐渐清晰,这时候需要的是"抠细节"——人物的表情、衣服的纹理、光影的过渡。这时候切换到"低噪声专家"。
切换的时机由官方测量:根据信噪比(SNR)计算找到最佳的切换阈值 t m o e t_{moe} tmoe。
参数规模:
- 每个专家约 14B 参数
- 两个专家总共约 27B 参数
- 每次推理只激活 14B 参数
这意味着你获得了 27B 模型的能力,但只付出了 14B 模型的计算成本。就问你划不划算?
高效部署:Wan2.2-VAE 与 TI2V-5B
对于咱们普通玩家来说,14B 甚至 27B 的模型还是太重了。好在 Wan2.2 团队专门推出了一个 TI2V-5B 模型,这是真正面向消费级硬件的诚意之作。
什么是 TI2V-5B?
TI2V = Text-Image-to-Video,也就是文图混合生视频。这个 5B 模型既能做纯文生视频(T2V),也能做图生视频(I2V),一个模型搞定两种任务。
技术亮点:
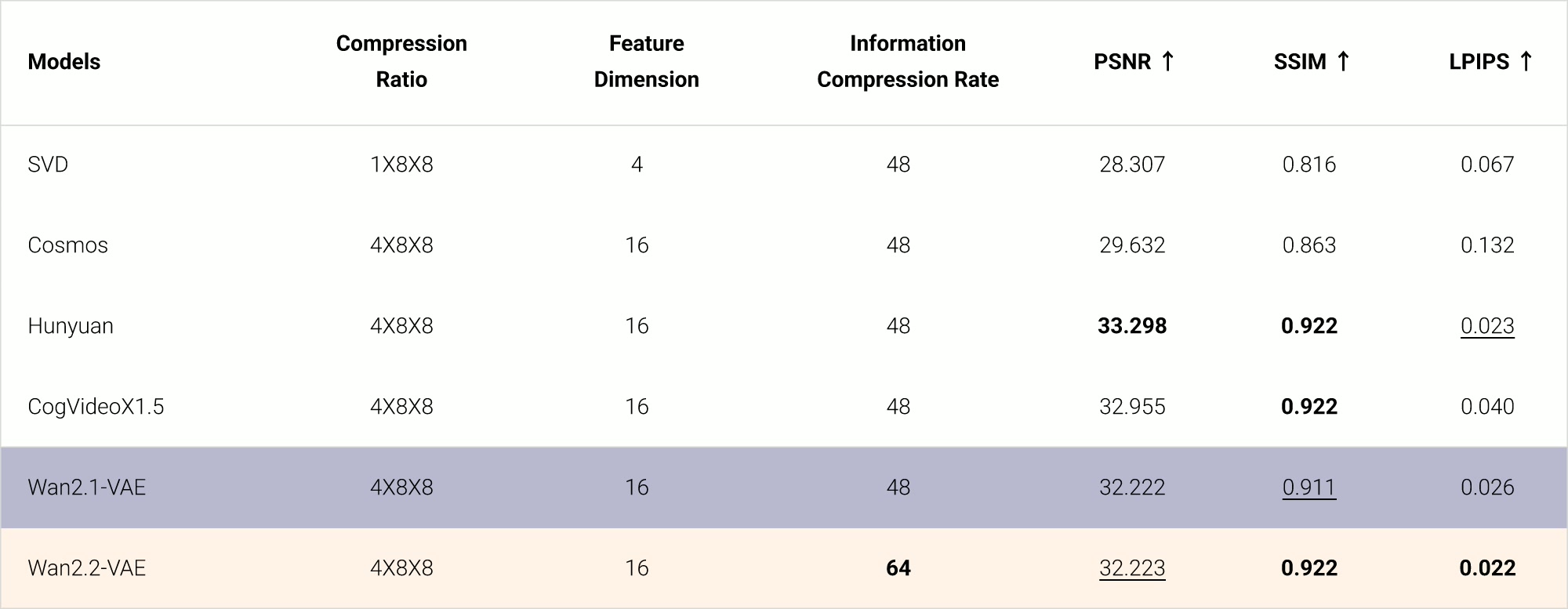
- 高压缩率 VAE:Wan2.2-VAE 实现了 4 × 16 × 16 4 \times 16 \times 16 4×16×16 的时空压缩比,整体压缩率达到 64 倍
- 额外的 Patchification 层:进一步将压缩比提升到 4 × 32 × 32 4 \times 32 \times 32 4×32×32
- 720P@24fps 支持:在消费级 GPU 上生成高清视频
显存需求:
| GPU | 能否运行 | 备注 |
|---|---|---|
| RTX 4090 (24GB) | ✅ | 需要开启 offload 模式 |
| RTX 3090 (24GB) | ✅ | 需要开启 offload 模式 |
| A100 (80GB) | ✅ | 可关闭 offload,速度更快 |
生成速度:
官方数据显示,TI2V-5B 在单卡(无特别优化)上生成 5 秒 720P 视频大约需要 9 分钟以内,是目前开源模型中速度最快的之一。
官方也提供了线上试玩
还有使用指南:https://alidocs.dingtalk.com/i/nodes/jb9Y4gmKWrx9eo4dCql9LlbYJGXn6lpz

玩法一:文生视频(Text-to-Video)
最基础的功能,给一段文字描述,生成对应的视频。
快速上手(以 5B 模型为例):
python generate.py \
--task ti2v-5B \
--size 1280*704 \
--ckpt_dir ./Wan2.2-TI2V-5B \
--offload_model True \
--convert_model_dtype \
--t5_cpu \
--prompt "Two anthropomorphic cats in comfy boxing gear and bright gloves fight intensely on a spotlighted stage"
参数说明:
--task ti2v-5B:指定使用 TI2V-5B 模型--size 1280*704:输出视频分辨率(720P 的尺寸是 1280×704,不是 1280×720 哦)--offload_model True:开启模型卸载,用 CPU 内存换 GPU 显存--t5_cpu:将 T5 文本编码器放到 CPU 上运行--convert_model_dtype:转换模型数据类型以节省显存
进阶玩法:Prompt 扩展
如果你觉得自己写的 Prompt 太简单,可以开启提示词扩展功能。它会调用 Qwen(通义千问)模型帮你把简单描述"润色"成导演级的详细剧本。
两种方式:
- 使用阿里云 Dashscope API(需要申请 API Key)
DASH_API_KEY=your_key python generate.py \
--task ti2v-5B \
... \
--use_prompt_extend \
--prompt_extend_method 'dashscope'
- 使用本地 Qwen 模型
python generate.py \
--task ti2v-5B \
... \
--use_prompt_extend \
--prompt_extend_method 'local_qwen' \
--prompt_extend_model 'Qwen/Qwen2.5-14B-Instruct'
本地模型可选:
Qwen/Qwen2.5-14B-Instruct(效果最好,显存需求高)Qwen/Qwen2.5-7B-Instruct(平衡之选)Qwen/Qwen2.5-3B-Instruct(轻量级)
玩法二:图生视频(Image-to-Video)
给一张图片,让它"动起来"。这个功能在产品展示、创意动画等场景非常实用。
快速上手(以 5B 模型为例):
python generate.py \
--task ti2v-5B \
--size 1280*704 \
--ckpt_dir ./Wan2.2-TI2V-5B \
--offload_model True \
--convert_model_dtype \
--t5_cpu \
--image examples/i2v_input.JPG \
--prompt "Summer beach vacation style, a white cat wearing sunglasses sits on a surfboard."
关键点:
- 加上
--image参数就是图生视频;不加就是文生视频 --size参数代表输出视频的面积,宽高比会跟随输入图片
如果你懒得写 Prompt,可以让模型自动从图片中提取描述:
DASH_API_KEY=your_key python generate.py \
--task ti2v-5B \
--image examples/i2v_input.JPG \
--prompt '' \
--use_prompt_extend \
--prompt_extend_method 'dashscope'
玩法三:语音驱动视频(Speech-to-Video)🔥
这是 Wan2.2 最让我兴奋的功能之一。
Wan2.2-S2V-14B 可以根据一段音频,生成与之匹配的说话人视频。你可以:
- 给一张人物图片 + 一段音频,生成这个人说话的视频
- 结合姿态视频 (pose video),实现更精准的动作控制
- 使用 CosyVoice 语音合成,直接从文字生成语音再驱动视频
基础用法:
python generate.py \
--task s2v-14B \
--size 1024*704 \
--ckpt_dir ./Wan2.2-S2V-14B/ \
--offload_model True \
--convert_model_dtype \
--prompt "Summer beach vacation style, a white cat wearing sunglasses sits on a surfboard." \
--image "examples/i2v_input.JPG" \
--audio "examples/talk.wav"
高级玩法:文字直接生成说话视频
如果你没有现成的音频,可以让模型先用 CosyVoice 合成语音:
python generate.py \
--task s2v-14B \
--size 1024*704 \
--ckpt_dir ./Wan2.2-S2V-14B/ \
--offload_model True \
--convert_model_dtype \
--prompt "Summer beach vacation style, a white cat wearing sunglasses sits on a surfboard." \
--image "examples/i2v_input.JPG" \
--enable_tts \
--tts_prompt_audio "examples/zero_shot_prompt.wav" \
--tts_prompt_text "希望你以后能够做的比我还好呦。" \
--tts_text "收到好友从远方寄来的生日礼物,那份意外的惊喜与深深的祝福让我心中充满了甜蜜的快乐,笑容如花儿般绽放。"
使用场景:
- 虚拟主播/数字人
- 新闻播报自动化
- 教育视频生成
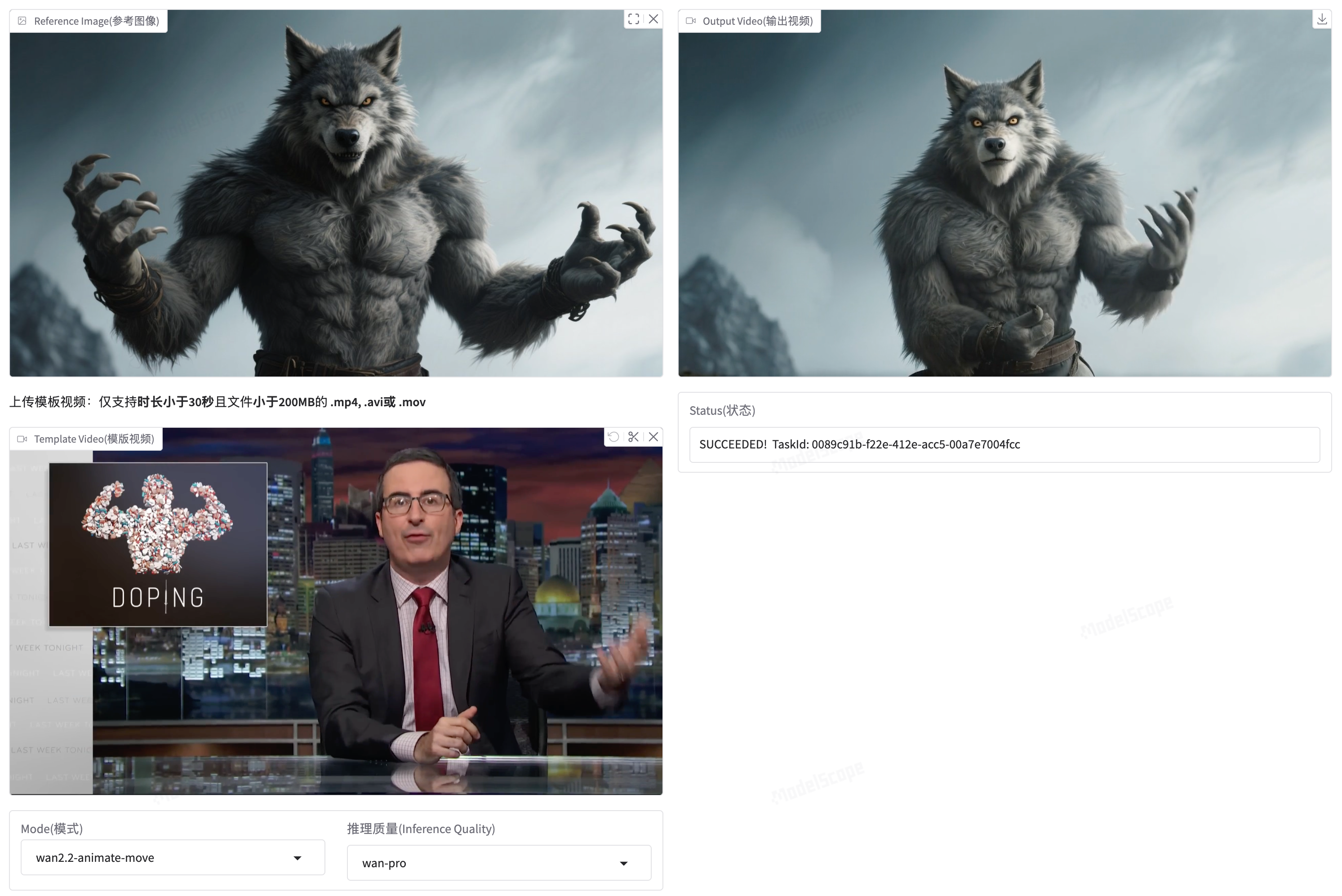
玩法四:人物动画(Wan-Animate)
Wan2.2-Animate-14B 是专门用于人物动画生成的模型,支持两种模式:
| 模式 | 功能 | 适用场景 |
|---|---|---|
| Animation | 让参考图片中的人物模仿视频中的动作 | 舞蹈教学、动作迁移 |
| Replacement | 将视频中的人物替换为参考图片中的人物 | 换脸、虚拟主播 |
工作流程:
- 预处理:先将输入视频处理成姿态、面部等素材
python ./wan/modules/animate/preprocess/preprocess_data.py \
--ckpt_path ./Wan2.2-Animate-14B/process_checkpoint \
--video_path ./examples/wan_animate/animate/video.mp4 \
--refer_path ./examples/wan_animate/animate/image.jpeg \
--save_path ./examples/wan_animate/animate/process_results \
--resolution_area 1280 720 \
--retarget_flag \
--use_flux
- 生成动画
python generate.py \
--task animate-14B \
--ckpt_dir ./Wan2.2-Animate-14B/ \
--src_root_path ./examples/wan_animate/animate/process_results/ \
--refert_num 1
Diffusers 集成(更简洁的调用方式):
from diffusers import WanAnimatePipeline
from diffusers.utils import export_to_video, load_image, load_video
import torch
device = "cuda:0"
dtype = torch.bfloat16
model_id = "Wan-AI/Wan2.2-Animate-14B-Diffusers"
pipe = WanAnimatePipeline.from_pretrained(model_id, torch_dtype=dtype)
pipe.to(device)
image = load_image("/path/to/reference/image.png")
pose_video = load_video("/path/to/pose/video.mp4")
face_video = load_video("/path/to/face/video.mp4")
animate_video = pipe(
image=image,
pose_video=pose_video,
face_video=face_video,
prompt="People in the video are doing actions.",
mode="animate",
guidance_scale=1.0,
num_inference_steps=20,
generator=torch.Generator(device=device).manual_seed(42),
).frames[0]
export_to_video(animate_video, "output.mp4", fps=30)
生态集成:ComfyUI、Diffusers 全覆盖
Wan2.2 的生态建设做得相当完善。目前已经支持:
| 工具 | 支持状态 | 备注 |
|---|---|---|
| HuggingFace Diffusers | ✅ | T2V、I2V、TI2V、Animate 全覆盖 |
| ComfyUI | ✅ | 官方文档:中文 / 英文 |
| ModelScope | ✅ | 国内用户友好 |
| Gradio Demo | ✅ | HuggingFace Space 可直接体验 |
社区生态:加速、量化、优化
开源项目的好处就是社区会不断贡献优化方案。目前围绕 Wan2.2 已经有不少第三方项目:
-
LightX2V:轻量级视频生成框架,提供步骤蒸馏模型、量化模型、轻量级 VAE 等
-
FastVideo:包含稀疏注意力的蒸馏 Wan 模型,大幅加速推理
-
Cache-dit:唯品会开源的缓存加速方案,支持 DBCache、TaylorSeer、Cache CFG
-
DiffSynth-Studio:阿里 ModelScope 团队的综合工具,支持 FP8 量化、序列并行、LoRA 训练等
-
Kijai’s ComfyUI WanVideoWrapper:ComfyUI 的替代实现,更新更快,更容易集成前沿功能
-
HuMo:基于 Wan 的人类视频生成框架,支持文本、图像、音频等多模态输入
安装部署完整指南
1. 克隆代码
git clone https://github.com/Wan-Video/Wan2.2.git
cd Wan2.2
2. 安装依赖
# 确保 PyTorch >= 2.4.0
pip install -r requirements.txt
# 如果 flash_attn 安装失败,可以先装其他包,最后再装 flash_attn
3. 下载模型
推荐使用 huggingface-cli:
pip install "huggingface_hub[cli]"
# 下载 5B 轻量模型(推荐)
huggingface-cli download Wan-AI/Wan2.2-TI2V-5B --local-dir ./Wan2.2-TI2V-5B
# 下载 14B MoE 模型
huggingface-cli download Wan-AI/Wan2.2-T2V-A14B --local-dir ./Wan2.2-T2V-A14B
国内用户可以使用 ModelScope:
pip install modelscope
modelscope download Wan-AI/Wan2.2-TI2V-5B --local_dir ./Wan2.2-TI2V-5B
4. 可选:安装语音生成依赖
如果你想玩 Speech-to-Video:
pip install -r requirements_s2v.txt
不同 GPU 的性能参考
官方给出了详细的性能测试数据(格式:总耗时 / 峰值显存):
测试条件:
- 多卡:14B 模型使用
--ulysses_size 4/8 --dit_fsdp --t5_fsdp - 单卡:14B 模型使用
--offload_model True --convert_model_dtype - 单卡:5B 模型使用
--offload_model True --convert_model_dtype --t5_cpu - 使用 FlashAttention3(Hopper 架构 GPU)
我的评价
讲真,Wan2.2 这次的诚意给满分。
优点:
- 技术扎实:MoE 架构在视频生成领域的应用很有创新性
- 产品线齐全:T2V、I2V、S2V、Animate 一应俱全,覆盖主流需求
- 对硬件友好:5B 模型让普通玩家也能参与进来
- 生态完善:Diffusers、ComfyUI 等主流工具全部支持
- 完全开源:Apache 2.0 协议,商用友好
不足:
- 14B 模型门槛高:想用最强的 MoE 模型,还是得 80GB 显存起步
- Animate 预处理繁琐:需要先跑预处理脚本,不够开箱即用
- 文档分散:官方文档分布在 GitHub、钉钉文档、阿里云等多个地方,查资料得翻好几个网站
适合谁用?
- 有 4090/3090 的本地玩家:TI2V-5B 完美适配
- 有 A100 集群的团队/公司:全套模型随便玩
- 想做数字人/虚拟主播的:S2V-14B 值得深入研究
- ComfyUI 工作流玩家:生态支持已经很完善
相关资源汇总
| 资源 | 链接 |
|---|---|
| GitHub | https://github.com/Wan-Video/Wan2.2 |
| 官网 | https://wan.video |
| 论文 | https://arxiv.org/abs/2503.20314 |
| HuggingFace | https://huggingface.co/Wan-AI/ |
| ModelScope | https://modelscope.cn/organization/Wan-AI |
| 中文使用指南 | 钉钉文档 |
| Discord | https://discord.gg/AKNgpMK4Yj |
总的来说,Wan2.2 是目前开源视频生成领域最全面、最强大的解决方案之一。如果你对 AI 视频生成感兴趣,强烈建议去试一试。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 32
32 1
1- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)