The Prompt Report: A Systematic Survey of Prompt Engineering Techniques(文本部分 )
生成式人工智能(GenAI)系统正日益广泛地应用于各类行业与研究领域。开发者与终端用户通过提示词(prompting)及提示词工程(prompt engineering)与这类系统进行交互。尽管提示词工程已成为被广泛采用且研究深入的领域,但由于其兴起时间较晚,该领域存在术语冲突问题,且对于 “有效提示词的构成” 缺乏统一的本体论认知。本文通过构建提示技术分类体系并分析其应用场景,建立了对提示词工程
论文地址:提示词报告
摘要
生成式人工智能(GenAI)系统正日益广泛地应用于各类行业与研究领域。开发者与终端用户通过提示词(prompting)及提示词工程(prompt engineering)与这类系统进行交互。尽管提示词工程已成为被广泛采用且研究深入的领域,但由于其兴起时间较晚,该领域存在术语冲突问题,且对于 “有效提示词的构成” 缺乏统一的本体论认知。
本文通过构建提示技术分类体系并分析其应用场景,建立了对提示词工程的结构化认知。具体而言,我们提供了包含 33 个术语的详细词汇表、涵盖 58 种大型语言模型(LLM)提示技术的分类体系,以及 40 种适用于其他模态的提示技术。此外,本文还给出了提示词工程的最佳实践与操作指南,包括针对 ChatGPT 及其他最先进(SOTA)大型语言模型的提示词工程建议。我们进一步对自然语言前缀提示相关的全部文献进行了元分析。
作为上述研究工作的总结,本文呈现了迄今为止最全面的提示词工程综述。
1 引言
基于Transformer架构的大型语言模型(LLMs)已广泛应用于面向消费者、企业内部及科研等场景(Bommasani et al., 2021)。这类模型通常依赖用户提供的“提示词”生成响应输出,提示词可以是文本形式(例如“写一首关于树的诗”),也可以是图像、音频、视频或其组合等其他形式。通过提示词与模型交互(尤其是自然语言提示)的方式,让模型易于操作,并能灵活适配各类场景。
掌握提示词的有效构建、评估及相关操作,是使用这类模型的核心前提。实践表明,更优质的提示词能在各类任务中带来更好的结果(Wei et al., 2022b; Liu et al., 2023b; Schulhoff, 2022)。目前,围绕“通过提示词提升模型效果”的研究已形成大量文献,提示词技术的数量也在快速增长。
然而,由于提示词技术尚处于新兴阶段,其应用仍缺乏充分的认知——现有术语与技术中,仅有少部分被从业者广泛熟知。为此,我们对提示词技术进行了大规模综述,构建了该领域术语与技术的系统性资源。我们认为这是术语体系迭代的开端(后续会持续完善),并在LearnPrompting.org维护着术语与技术的实时更新列表。
研究范围
我们构建了一个涵盖各类提示词技术的目录,便于开发者与研究者快速理解、快速实现并开展实验。为此,我们将研究范围限定于前缀提示词(Shin et al., 2020a)而非完形填空式提示词(Petroni et al., 2019; Cui et al., 2021)——因为现代LLM的Transformer架构普遍采用前缀提示词,且对开发者与研究者提供了完善支持(Brown et al., 2020; Google, 2023; Touvron et al., 2023)。此外,我们聚焦于硬提示词(离散型)而非软提示词(连续型),且排除了使用基于梯度更新技术(即微调)的相关研究:硬提示词仅包含模型词表中对应词汇的令牌(向量),而软提示词可能包含词表中无对应词汇的令牌。
最终,我们仅研究任务无关的技术。这些限定使内容对非技术读者更友好,同时保证研究范围可控。
章节概述
我们基于PRISMA流程(Page et al., 2021)开展了机器辅助的系统性综述(2.1节),识别出58种不同的文本类提示词技术,并据此构建了包含严谨术语体系的分类框架(1.2节)。
我们的目标是为社区提供“选择提示词技术”的路线图(图1.1)。尽管多数提示词文献聚焦于英文场景,我们也讨论了多语言提示技术(3.1节);同时,鉴于多模态提示(提示词包含图像等媒介)的快速发展,我们也将范围扩展至多模态技术(3.2节)——许多多语言、多模态提示技术是英文纯文本提示技术的直接延伸。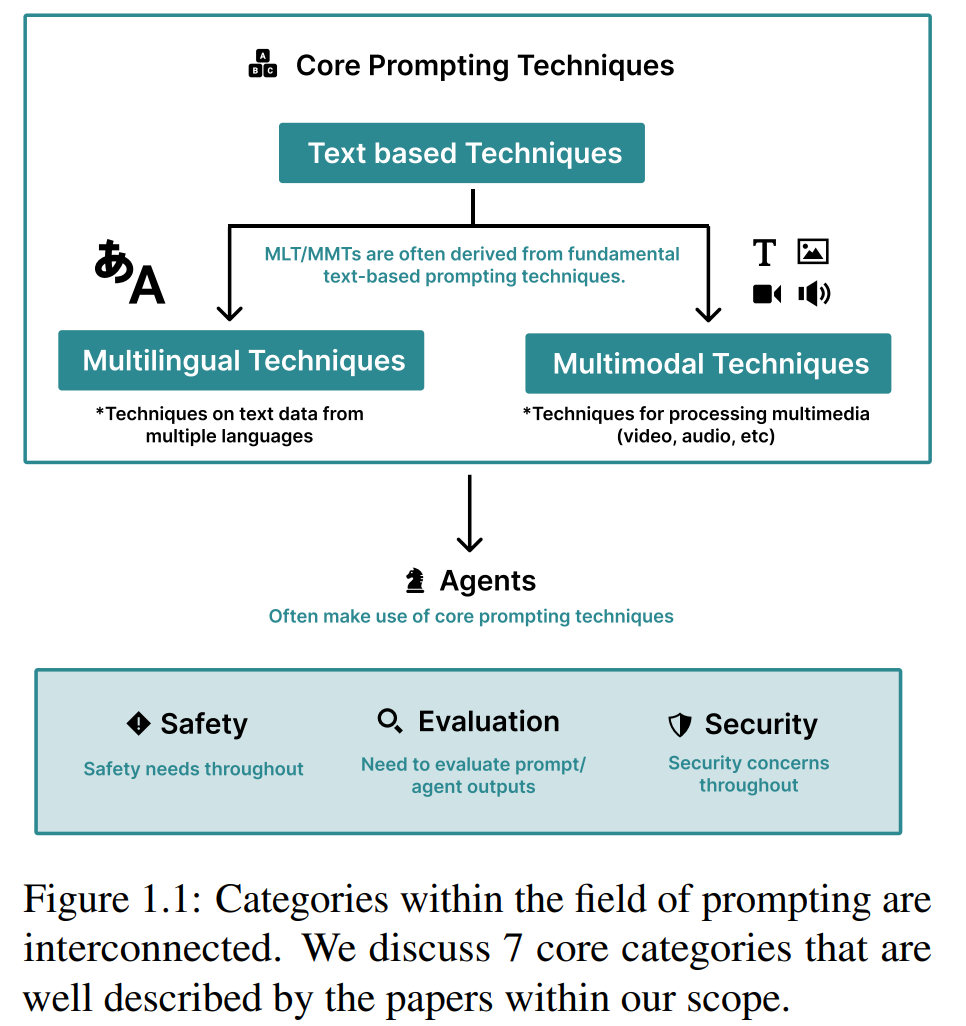
随着提示词技术愈发复杂,其开始整合外部工具(如网络浏览、计算器),我们将这类提示技术称为“智能体”(4.1节)。
为确保输出的准确性并避免幻觉,理解如何评估智能体与提示词技术的输出至关重要,因此我们讨论了这类输出的评估方法(4.2节);同时,我们也探讨了提示词设计中的安全措施(5.1节)与防护手段(5.2节),以降低对企业与用户的潜在风险。
最后,我们通过两个案例研究应用了提示词技术(6.1节):第一个案例中,我们在常用基准数据集MMLU(Hendrycks et al., 2021)上测试了多种提示词技术;第二个案例中,我们深入探索了“手动提示词工程”在真实场景中的应用——从寻求支持的个体文本中识别“绝望情绪”(自杀危机的核心指标,Schuck et al., 2019a)。文末,我们讨论了提示词技术的本质及其近期发展(8节)。
1.1 什么是提示词(Prompt)
提示词是生成式人工智能(GenAI)模型的输入,用于引导模型生成输出(Meskó, 2023; White et al., 2023; Heston and Khun, 2023; Hadi et al., 2023; Brown et al., 2020)。提示词可由文本、图像、音频或其他媒介构成,例如“为会计师事务所撰写一篇三段式营销邮件”、一张写有“10×179等于多少”的纸张照片,或是一段要求“总结内容”的线上会议录音。提示词通常包含文本部分,但随着非文本模态的普及,这一情况可能改变。
提示词模板(Prompt Template):提示词常通过提示词模板构建(Shin et al., 2020b)。提示词模板是一个包含一个或多个变量的函数,变量可替换为媒介(通常是文本)以生成提示词,生成的提示词即为该模板的一个实例。

图1.2:提示词(Prompts)和提示词模板(Prompt Templates)是不同的概念;当在提示词模板中插入输入内容时,它就变成了一个提示词。
以推文二分类任务为例,可使用如下初始提示词模板,数据集中的每条推文将插入到模板的独立实例中,生成的提示词输入大型语言模型(LLM)进行推理。
1.2 术语体系
1.2.1 提示词的构成要素
提示词包含多种常见构成要素,以下总结核心要素及其在提示词中的作用(图1.3):
-
指令(Directive):多数提示词以指令或问题形式呈现核心意图(有时简称“意图”)。例如:

指令也可隐含,如以下单样本示例中,指令为执行英语到西班牙语的翻译:
-
示例(Examples):又称范例或样本,作为演示引导GenAI完成任务,上述示例即为单样本(One-Shot)提示词。
-
输出格式(Output Formatting):通常希望GenAI按特定格式输出信息,如CSV、Markdown、XML或自定义格式(Xia et al., 2024)。有研究表明结构化输出可能降低部分任务性能(Tam et al., 2024),但Kurt(2024)指出其研究存在缺陷,结构化输出实际可能提升性能。例如,按CSV格式输出的提示词:

-
风格指令(Style Instructions):一种用于修改输出风格而非结构的输出格式(2.2.1.3节),例如:

-
角色设定(Role):又称人物设定(Persona)(Schmidt et al., 2023; Wang et al., 2023l),可改善文本的写作与风格(2.2.1.3节),例如:

-
补充信息(Additional Information):提示词中常需包含补充信息,如撰写邮件时提供姓名与职位以便模型正确署名。补充信息有时被称为“上下文(Context)”,但该术语在提示词领域存在多义性,因此不建议使用。
1.2.2 提示词相关术语
提示词领域术语体系正快速发展,目前存在诸多定义模糊(如提示词、提示词工程)或冲突(如角色提示词vs人物设定提示词)的情况,统一术语体系有助于清晰描述各类提示词技术。以下提供核心术语定义(图1.3),低频术语详见附录A.2,常用术语定义综合多方来源(附录A.1)推导得出: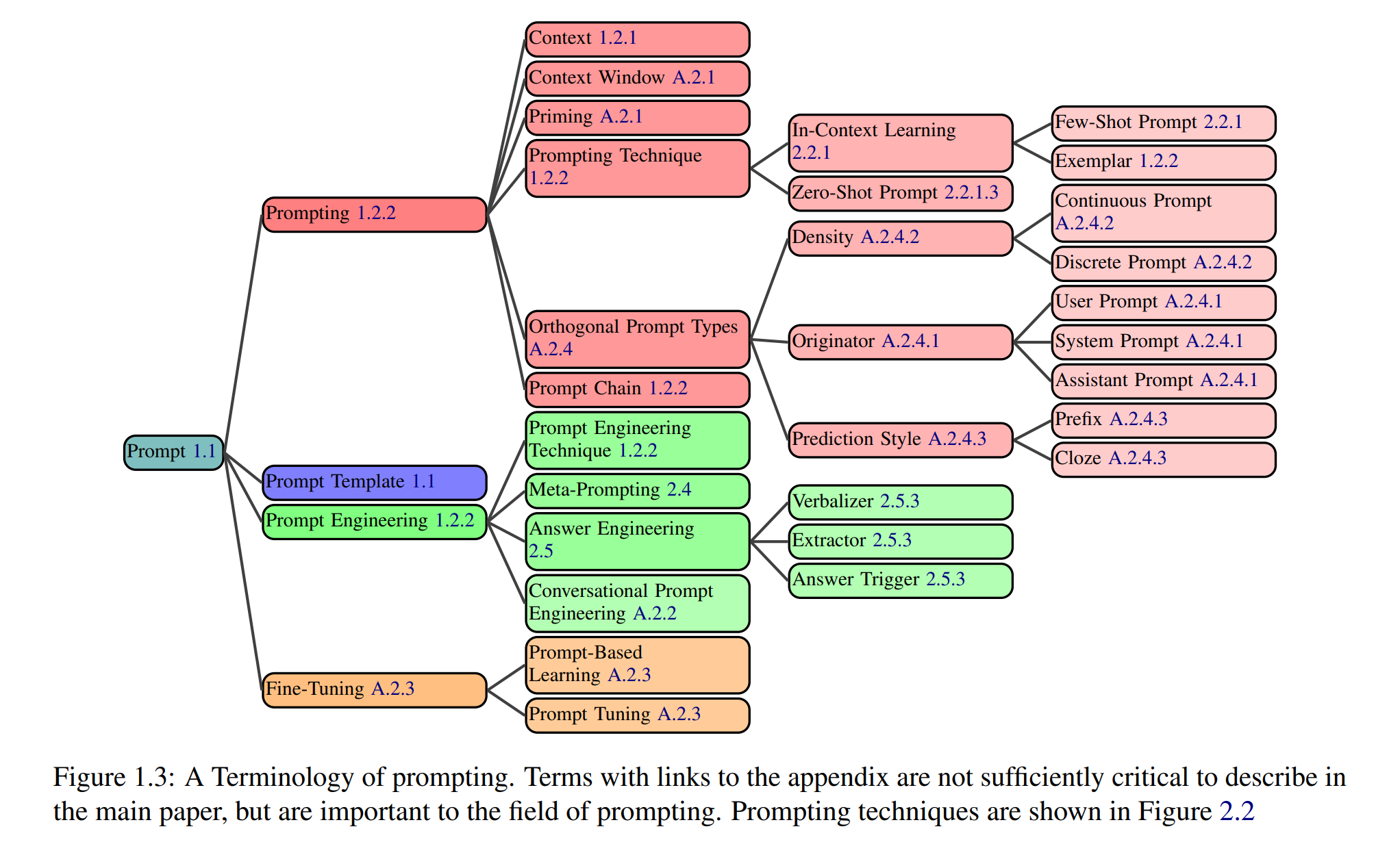
- 提示(Prompting):向GenAI提供提示词并获取响应的过程,例如发送文本片段或上传图像。
- 提示词链(Prompt Chain):又称提示词链式任务,由两个或多个提示词模板依次使用构成,前一模板生成的输出作为后一模板的参数,直至所有模板执行完毕(Wu et al., 2022)。
- 提示词技术(Prompting Technique):描述提示词、多个提示词或动态序列组织方式的蓝图,可能包含条件/分支逻辑、并行机制或跨多个提示词的架构设计。
- 提示词工程(Prompt Engineering):通过修改或调整提示词技术迭代开发提示词的过程(图1.4)。
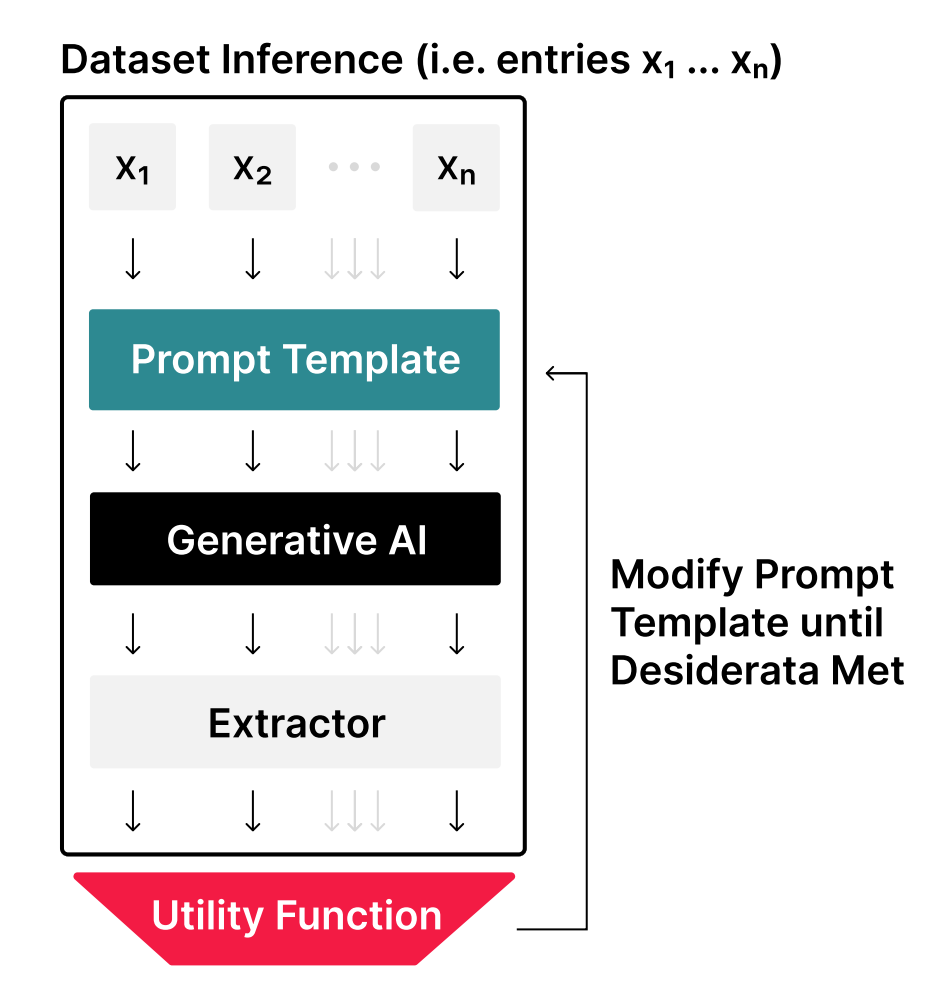
图1.4:提示工程流程包含三个循环步骤:1)在数据集上进行推理;2)评估性能;3)修改提示模板。请注意,其中使用了一个“提取器”,用于从LLM的输出中提取最终响应(例如,将“这句话是积极的”提取为“积极”)。有关提取器的更多信息,请参见第2.5节。 - 提示词工程技术(Prompt Engineering Technique):迭代优化提示词的策略,文献中多为自动化技术(Deng et al., 2022),而消费场景中用户常手动进行提示词工程,无需辅助工具。
- 范例(Exemplar):提示词中向模型展示的任务完成示例(Brown et al., 2020)。
1.3 提示词的发展简史
在GPT-3与ChatGPT时代之前,已有通过自然语言前缀(提示词)引导语言模型行为与响应的理念。GPT-2(Radford et al., 2019a)已使用提示词,Fan等人(2018)首次将其应用于生成式人工智能场景。提示词概念的前身包括控制码(Pfaff, 1979; Poplack, 1980; Keskar et al., 2019)与文学创作提示词等。
“提示词工程”术语由Radford等人(2021)提出,随后Reynolds与McDonell(2021)也使用该术语。此前已有研究采用提示词工程技术但未明确命名,如Wallace等人(2019)、Shin等人(2020a),以及Schick和Schütze(2020a,b)、Gao等人(2021)针对非自回归语言模型的研究。
早期提示词定义与当前用法存在差异,例如Brown等人(2020)将“llama”视为提示词,而“Translate English to French:”为“任务描述”;近期研究(包括本文)则将输入LLM的整个字符串视为提示词。
2 提示词技术的元分析
2.1 系统性综述流程
为严谨地收集本文研究所需的文献数据源,我们基于PRISMA流程(Page et al., 2021)开展了系统性文献综述(图2.1)。该文献数据集已托管于HuggingFace⁴,并在附录A.3中提供了数据集说明文档(Gebru et al., 2021)。主要数据来源包括arXiv、Semantic Scholar和ACL,我们使用与提示词及提示词工程密切相关的44个关键词对这些数据库进行检索(附录A.4)。
图2.1:展示了PRISMA(系统文献综述)流程。我们最初汇集了4,247条独立记录,并从中提取出1,565条相关记录。
2.1.1 技术流程
本节介绍我们的数据筛选流水线,该流程结合了人工标注与大模型辅助评审⁵。为确定筛选标准,我们首先基于简单的关键词与布尔逻辑规则(附录A.4)从arXiv获取初始文献样本;随后,人工标注员针对1,661篇arXiv文献样本,按以下标准进行标注:
- 若论文提出新型提示词技术,则纳入;
- 若论文仅研究硬前缀提示词,则纳入;
- 若论文聚焦于基于梯度反向传播的模型训练,则排除;
- 若论文针对非文本模态采用掩码或窗口机制,则纳入。
由两名标注员独立评审300篇文献,标注一致性达92%(Krippendorff’s α = Cohen’s κ = 81%)。在此基础上,我们使用gpt-4-1106-preview构建提示词,对剩余文献进行自动化分类(附录A.5)。通过100组人工标注的真实标签验证,该自动化流程的精确率达89%、召回率达75%(F1值为81%)。结合人工与大模型标注结果,最终确定纳入研究的文献共1,565篇。
2.2 文本类提示词技术
本节构建了包含58种文本类提示词技术的综合分类体系,将其划分为6个主类别(图2.2)。部分技术虽可归属于多个类别,但我们依据其核心特征将其归入最相关的类别。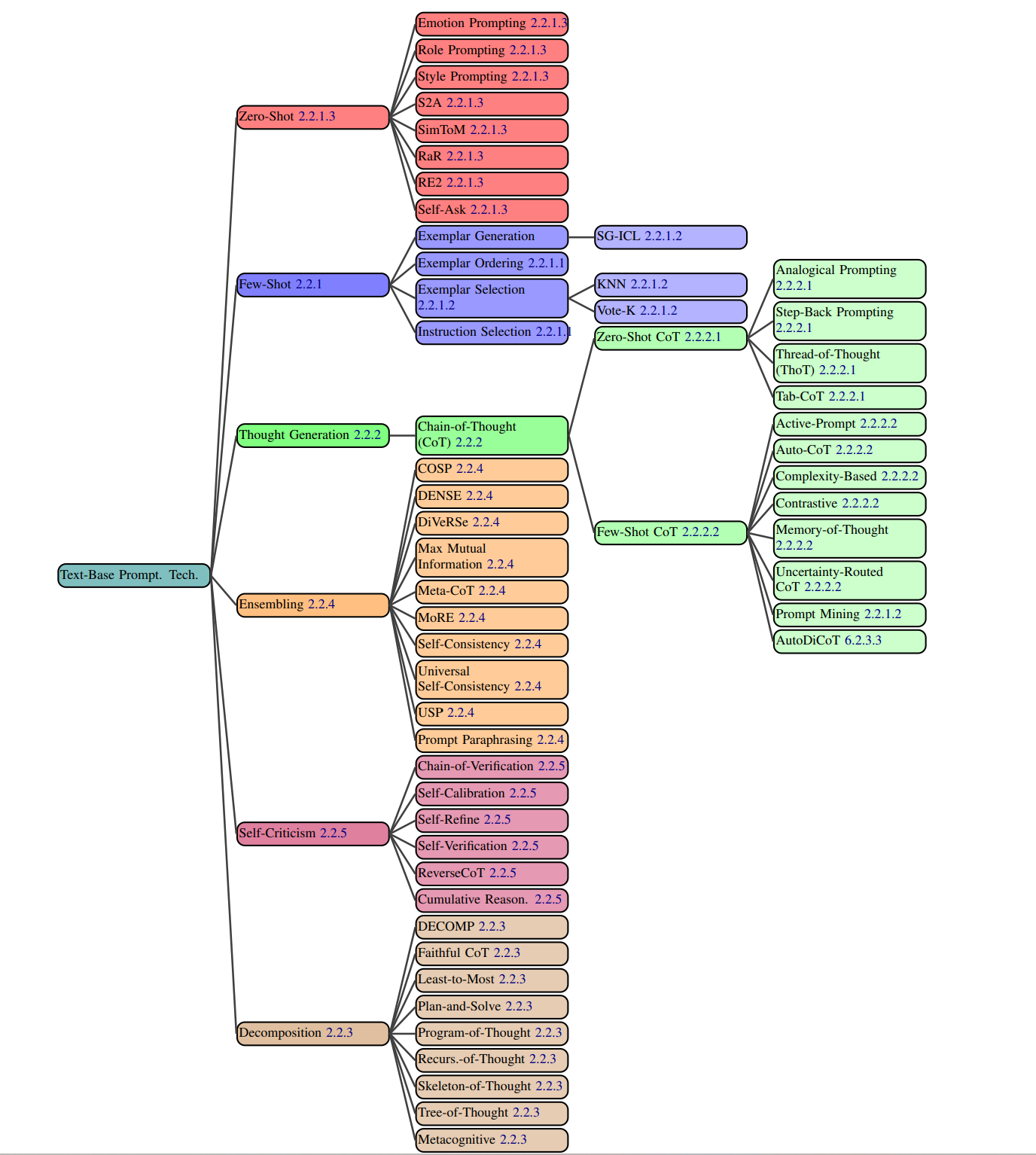
Figure 2.2: All text-based prompting techniques from our dataset.
2.2.1 上下文学习(In-Context Learning, ICL)
上下文学习(ICL)指生成式AI无需更新模型权重或重新训练,仅通过在提示词中提供范例和/或相关指令,即可习得完成任务所需的能力(Brown et al., 2020; Radford et al., 2019b)。这些能力可从范例(图2.4)或指令(图2.5)中获取。需注意,此处的“学习”一词存在误导性——ICL本质上是任务指定:模型所展现的能力并非全新习得,而是可能早已包含在训练数据中(图2.6)。关于该术语的详细讨论见附录A.9。目前,针对ICL的优化(Bansal et al., 2023)与机制研究(Si et al., 2023a; Štefánik and Kadlcík, 2023)是研究热点。
少样本提示词技术(Brown et al., 2020)是图2.4所示的范式,即生成式AI仅通过少量范例即可完成任务。少样本提示词技术是少样本学习(FSL)(Fei-Fei et al., 2006; Wang et al., 2019)的特例,但无需更新模型参数。
图2.4:上下文学习的范例型提示词

图2.5:上下文学习的指令型提示词

图2.6:基于训练数据的上下文学习提示词
2.2.1.1 少样本提示词技术的设计要点
为提示词选择范例是一项极具挑战性的任务——模型性能与范例的多项因素显著相关(Dong et al., 2023),且受限于大模型的上下文窗口长度,可纳入的范例数量有限。我们归纳出6个关键设计决策,其中范例的选择与排序对输出质量影响尤为关键(Zhao et al., 2021a; Lu et al., 2021; Ye and Durrett, 2023)(图2.3)。 图2.3:我们强调了在构建少样本提示(Few-Shot Prompts)时的六个主要设计决策。*请注意,此处给出的建议并不能推广到所有任务;在某些情况下,其中每一项都可能损害性能。
图2.3:我们强调了在构建少样本提示(Few-Shot Prompts)时的六个主要设计决策。*请注意,此处给出的建议并不能推广到所有任务;在某些情况下,其中每一项都可能损害性能。
-
范例数量
增加提示词中的范例数量通常可提升模型性能,大型模型中这一效果尤为显著(Brown et al., 2020)。但部分研究表明,当范例数量超过20个时,性能提升的边际效益会逐渐减弱(Liu et al., 2021)。对于长上下文大模型,增加范例数量仍可持续提升性能,但其效率因任务与模型的不同而存在差异(Agarwal et al., 2024; Bertsch et al., 2024; Jiang et al., 2024)。 -
范例排序
范例的排列顺序会影响模型行为(Lu et al., 2021; 2021; Liu et al., 2021; Rubin et al., 2022)。在部分任务中,调整范例顺序可使模型准确率在50%以下至90%以上的区间内波动(Lu et al., 2021)。 -
范例标签分布
与传统监督学习类似,提示词中范例的标签分布会影响模型行为。例如,若提示词中包含10个某一类别的范例与2个另一类别的范例,模型输出可能会偏向于样本更多的类别。 -
范例标签质量
尽管增加范例数量通常有益,但范例标签是否必须完全准确这一问题尚无定论。部分研究(Min et al., 2022)表明,标签准确性与模型性能无关——向模型提供含错误标签的范例,未必会导致性能下降;但在特定任务设置下,标签质量对性能存在显著影响(Yoo et al., 2022)。大型模型通常更擅长处理错误或无关标签(Wei et al., 2023c)。
该因素具有重要的实践意义:若从可能包含错误的大规模数据集中自动构建提示词,需研究标签质量对最终结果的影响。 -
范例格式
范例的格式同样影响模型性能。“Q: {输入}, A: {标签}”是最常用的格式之一,但最优格式因任务而异,需尝试多种格式以确定最佳方案。有证据表明,与模型训练数据中常见格式一致的提示词,更易获得优异性能(Jiang et al., 2020)。 -
范例相似性
选择与测试样本相似的范例通常有助于提升性能(Liu et al., 2021; Min et al., 2022)。但在部分场景下,选择多样性更高的范例反而能改善性能(Su et al., 2022; Min et al., 2022)。 -
指令选择
在零样本提示词中,指令是引导大模型完成任务的必要条件(Wei et al., 2022a);但在少样本提示词中,于范例前添加指令的作用尚不明确。Ajith et al. (2024) 的研究表明,通用的、与任务无关的指令(例如无指令,或仅使用“完成以下任务:”)可提升分类任务性能。部分研究(例如“这道题的答案是什么?”)的结论是,模型仅通过范例即可习得指令遵循能力。此外,尽管指令未必能提升少样本提示词的准确率,但可用于引导输出的辅助属性(如写作风格)(Roy et al., 2023)。
2.2.1.2 少样本提示词的具体技术
综合上述设计要点,高效实现少样本提示词技术具有较高难度。本节介绍监督学习场景下的少样本提示词技术,集成类方法对少样本提示词的优化作用将在单独章节讨论(2.2.4节)。
假设存在训练数据集 D t r a i n D_{train} Dtrain,包含多个输入样本 D train x i D_{\text{train}}^{x_i} Dtrainxi 与对应的输出标签 D train y i D_{\text{train}}^{y_i} Dtrainyi,可用于构建少样本提示词(而非用于梯度更新训练)。在测试阶段,可基于测试样本 D test x i D_{\text{test}}^{x_i} Dtestxi 动态生成提示词。本节采用如下“输入: 输出”格式的提示词模板(图2.4):
图2.7:少样本提示词模板
-
K近邻法(K-Nearest Neighbor, KNN)(Liu et al., 2021)
该方法属于范例选择算法家族,核心逻辑是选择与测试样本 D test x i D_{\text{test}}^{x_i} Dtestxi 相似的范例以提升性能。尽管效果显著,但在提示词生成阶段执行KNN算法,可能会产生较高的时间与资源开销。 -
Vote-K算法(Su et al., 2022)
这是另一种选择与测试样本相似范例的方法。该算法分为两个阶段:第一阶段,模型推荐潜在有效的无标签候选范例,由人工标注标签;第二阶段,利用标注后的范例池构建少样本提示词。Vote-K算法还会确保新增范例与已有范例存在足够差异,以此提升范例的多样性与代表性。 -
自生成上下文学习(Self-Generated In-Context Learning, SG-ICL)(Kim et al., 2022)
该技术利用生成式AI自动生成范例。在训练数据不可得的场景下,其效果优于零样本提示词;但相较于真实数据,自动生成的范例效果仍存在差距。 -
提示词挖掘(Prompt Mining)(Jiang et al., 2020)
该技术的核心是在语料库中挖掘最优的“中间词”。例如,对于少样本提示词而言,除了常用的“Q: A:”格式外,语料库中可能存在其他更常见的等效格式。采用与模型训练语料库中高频格式一致的提示词,通常能提升性能。 -
更复杂的技术
例如LENS(Li and Qiu, 2023a)、UDR(Li et al., 2023f)与主动范例选择(Zhang et al., 2022a),分别基于迭代过滤、嵌入与检索、强化学习等机制实现范例优化。
2.2.1.3 零样本提示词的具体技术
与少样本提示词技术不同,零样本提示词技术不使用任何范例。目前已有多种成熟的零样本独立技术,以及与其他概念(如思维链)结合的零样本技术(将在2.2.2节讨论)。
-
角色提示词技术(Role Prompting)(Wang et al., 2023j; Zheng et al., 2023d)
又称人物设定提示词技术(persona prompting)(Schmidt et al., 2023; Wang et al., 2023l),即在提示词中为生成式AI指定特定角色。例如,用户可要求模型模仿“麦当娜”或“旅行作家”的风格。该技术能为开放式任务生成更符合预期的输出(Reynolds and McDonell, 2021),在部分基准测试中也可提升准确率(Zheng et al., 2023d)。 -
风格提示词技术(Style Prompting)(Lu et al., 2023a)
即在提示词中明确指定输出所需的风格、语气或体裁,以此塑造生成式AI的输出内容。通过角色提示词技术也可实现类似效果。 -
情感提示词技术(Emotion Prompting)(Li et al., 2023a)
即在提示词中融入与人类心理相关的表述(例如“这对我的职业生涯至关重要”),该技术可提升大模型在基准测试与开放式文本生成任务中的性能。 -
系统2注意力机制(System 2 Attention, S2A)(Weston and Sukhbaatar, 2023)
该技术分为两步:首先,让大模型重写提示词,剔除与问题无关的信息;随后,将改写后的提示词输入大模型,获取最终回答。 -
SimToM技术(Wilf et al., 2023)
该技术适用于涉及多人物或多对象的复杂问题。针对输入问题,模型首先梳理某一人物已知的事实集合,再基于该事实集合回答问题。这是一个两阶段提示词流程,可有效排除提示词中的无关信息干扰。 -
改写再回答技术(Rephrase and Respond, RaR)(Deng et al., 2023)
该技术要求大模型在生成最终答案前,先改写并扩展输入问题。例如,在问题中添加指令“改写并扩展问题,然后作答”。该过程可通过单次提示词完成,也可将改写后的问题作为新提示词单独输入模型。RaR技术已在多个基准测试中验证了性能提升效果。 -
重读技术(Re-reading, RE²)(Xu et al., 2023)
该技术在提示词中添加指令“再次阅读问题:”,并重复输入问题。尽管方法简单,但在推理类基准测试中表现出性能提升效果,对复杂问题的优化尤为显著。 -
自提问技术(Self-Ask)(Press et al., 2022)
该技术引导大模型针对输入提示词,首先判断是否需要提出后续问题;若需要,则生成相关问题并作答,最终基于这些答案回答原始问题。
2.2.2 推理过程生成
推理过程生成(Thought Generation)包含一系列技术,其核心是引导大语言模型在解决问题的过程中清晰阐述自身的推理逻辑(Zhang et al., 2023c)。
思维链提示词技术(Chain-of-Thought, CoT)(Wei et al., 2022b)依托少样本提示词范式,鼓励大语言模型在输出最终答案前,先表达完整的推理过程⁶。该技术也被部分文献称为 Chain-of-Thoughts(Tutunov et al., 2023; Besta et al., 2024; Chen et al., 2023d),已被证实可显著提升大语言模型在数学计算与逻辑推理类任务中的性能。在Wei等人(2022b)的研究中,思维链提示词包含“问题-推理路径-正确答案”的完整范例(见图2.8)。
图2.8:单样本思维链提示词
2.2.2.1 零样本思维链(Zero-Shot-CoT)
思维链技术最简洁的形式是零样本范式,无需任何范例,仅需在提示词末尾添加引导推理的语句,例如“Let’s think step by step.”(Kojima et al., 2022)。其他被验证有效的引导语句还包括“First, let’s think about this logically”(Kojima et al., 2022);Zhou等人(2022b)则使用“Let’s work this out in a step by step way to be sure we have the right answer”这类表述;Yang等人(2023a)的研究则聚焦于寻找最优的推理引导语句。零样本思维链技术的优势在于无需人工构造范例,且具备良好的任务通用性。
-
回溯提示词技术(Step-Back Prompting)(Zheng et al., 2023c)
这是对思维链技术的改进,核心逻辑是:在引导模型进行具体推理前,先让模型回答一个与任务相关的通用、高层级概念或事实问题。该技术在PaLM2-L与GPT-4等模型的多个推理类基准测试中,均实现了显著的性能提升。 -
类比提示词技术(Analogical Prompting)(Yasunaga et al., 2023)
该技术与自生成上下文学习(SG-ICL)原理相似,可自动生成包含完整推理链的范例。其在数学推理与代码生成任务中被验证具备性能提升效果。 -
思路链提示词技术(Thread-of-Thought, ThoT)(Zhou et al., 2023)
该技术的核心是为思维链推理设计了更优的引导语句。不同于“Let’s think step by step”这类简单指令,它采用更详尽的引导语:“Walk me through this context in manageable parts step by step, summarizing and analyzing as we go.” 这种引导方式在问答与检索场景中表现优异,尤其适用于处理长文本、复杂上下文的任务。 -
表格型思维链提示词技术(Tabular Chain-of-Thought, Tab-CoT)(Jin and Lu, 2023)
这是一种零样本思维链技术,其提示词会引导大语言模型以Markdown表格的形式输出推理过程。表格化的结构设计能让模型的推理逻辑更清晰,进而提升最终答案的准确性。
2.2.2.2 少样本思维链(Few-Shot CoT)
这类技术的核心是向大语言模型提供多个包含完整推理链的范例,以此大幅提升模型的推理性能。该技术也被部分文献称为手动构造思维链(Manual-CoT)(Zhang et al., 2022b)或黄金思维链(Golden CoT)(Del and Fishel, 2023)。
-
对比式思维链提示词技术(Contrastive CoT Prompting)(Chia et al., 2023)
该技术在思维链提示词中同时加入推理正确与推理错误的范例,以此明确告知模型“哪些推理路径不可取”。该方法在算术推理、事实性问答等任务中展现出显著的性能提升效果。 -
不确定性引导的思维链提示词技术(Uncertainty-Routed CoT Prompting)(Google, 2023)
该技术的流程为:首先生成多条平行的思维链推理路径;若某一答案的支持率超过基于验证数据计算的阈值,则选择该答案作为最终结果;若未达到阈值,则采用贪心采样策略选择最优响应。该技术在MMLU基准测试中,同时提升了GPT-4与Gemini Ultra模型的性能。 -
基于复杂度的提示词技术(Complexity-based Prompting)(Fu et al., 2023b)
该技术对传统思维链进行了两项关键改进:第一,范例选择阶段——基于问题长度、所需推理步骤等指标,筛选复杂度较高的问题进行人工标注,并将其纳入提示词;第二,推理阶段——生成多条推理链(对应多个候选答案),并对长度超过阈值的推理链进行多数投票,其核心假设是“更长的推理链代表更高的答案质量”。该技术在三个数学推理数据集上均实现了性能提升。 -
主动提示词技术(Active Prompting)(Diao et al., 2023)
该技术的流程为:首先使用少量训练问题/范例让模型完成推理;然后计算模型输出的不确定性(此处定义为不同推理路径的分歧程度);最后让人工标注员对不确定性最高的范例进行推理链改写优化。 -
推理记忆提示词技术(Memory-of-Thought Prompting)(Li and Qiu, 2023b)
该技术的核心是利用无标注训练范例,在测试阶段动态构建少样本思维链提示词。具体流程为:测试前,对无标注训练范例执行思维链推理;测试阶段,检索与测试样本相似的范例推理链,构建提示词。该技术在算术、常识、事实性推理等多个基准测试中均实现了大幅性能提升。 -
自动思维链提示词技术(Automatic Chain-of-Thought, Auto-CoT)(Zhang et al., 2022b)
该技术首先使用Wei等人(2022b)提出的零样本提示词,自动生成多个任务范例的推理链;随后,利用这些自动生成的推理链,为测试样本构建少样本思维链提示词。
2.2.3 任务分解技术
当前已有大量研究聚焦于将复杂问题拆解为若干简单子问题的技术。这种策略不仅是人类高效解决问题的常用方法,对生成式AI同样适用(Patel et al., 2022)。部分任务分解技术与推理引导技术(如思维链CoT)存在相似性——思维链本质上也会将问题自然拆解为多个简单模块,但显式的问题分解操作,能够进一步提升大语言模型的问题求解能力。
-
由易到难提示词技术(Least-to-Most Prompting)(Zhou et al., 2022a)
该技术的流程分为两步:首先,引导大语言模型将给定的复杂问题拆解为多个子问题,但暂不求解;随后,按顺序逐一解决这些子问题,每次将模型的输出结果追加到提示词中,直至推导出最终答案。该方法在符号操作、组合泛化、数学推理等任务中,均展现出显著的性能提升效果。 -
分解式提示词技术(Decomposed Prompting, DECOMP)(Khot et al., 2022)
该技术基于少样本提示范式,向大语言模型演示如何调用特定功能函数(例如字符串分割、网络检索等,这些功能通常通过独立的大模型调用实现)。通过学习,模型会将原始复杂问题拆解为若干子问题,并分发至对应的功能函数处理。在部分任务中,该技术的性能优于由易到难提示词技术。 -
规划-求解提示词技术(Plan-and-Solve Prompting)(Wang et al., 2023f)
该技术是对零样本思维链(Zero-Shot CoT)的改进,使用的核心提示语句为:“Let’s first understand the problem and devise a plan to solve it. Then, let’s carry out the plan and solve the problem step by step”。在多个推理类数据集上,该方法生成的推理过程比标准零样本思维链更具鲁棒性。 -
思路树技术(Tree-of-Thought, ToT)(Yao et al., 2023b)
又称Tree of Thoughts(Long, 2023),其核心是构建树状的推理搜索空间:从原始问题出发,生成多条可能的推理路径(类似思维链的推理步骤);通过提示词引导模型评估每条路径对解决问题的推进作用,并筛选出有价值的路径继续探索;不断迭代这一过程,直至找到最优解。该技术尤其适用于需要搜索与规划的任务。 -
递归思路技术(Recursion-of-Thought)(Lee and Kim, 2023)
该技术与标准思维链(CoT)原理相似,核心改进在于递归处理复杂子问题:当模型在推理过程中遇到难以直接解决的复杂子问题时,会触发新的提示词调用流程,单独求解该子问题;子问题解决后,将结果回填至原始推理链中,继续完成剩余步骤。这种机制能够处理超出模型上下文长度限制的复杂问题,在算术与算法类任务中实现了性能提升。该技术的原始实现依赖微调,通过输出特殊令牌触发子问题调用,同时也可仅通过纯提示词工程的方式实现。 -
思路编程技术(Program-of-Thoughts)(Chen et al., 2023d)
该技术利用Codex等具备代码生成能力的大模型,将推理步骤转化为可执行的编程代码;再通过代码解释器运行这些代码,得到最终答案。该技术在数学计算与编程相关任务中表现优异,但在语义推理类任务中效果欠佳。 -
可信思维链技术(Faithful Chain-of-Thought)(Lyu et al., 2023)
与思路编程技术类似,该技术生成的思维链同时包含自然语言推理与符号语言(如Python)推理;不同之处在于,它会根据任务的具体需求,灵活选用不同类型的符号语言。 -
思路骨架技术(Skeleton-of-Thought)(Ning et al., 2023)
该技术的核心目标是通过并行计算提升答案生成速度。其流程为:针对输入问题,首先引导大模型生成答案的“骨架”,即需要解决的若干子问题;随后,将这些子问题并行分发至多个大模型实例求解;最后,拼接所有子问题的输出结果,形成最终答案。 -
元认知提示词技术(Metacognitive Prompting)(Wang and Zhao, 2024)
该技术旨在让大语言模型模拟人类的元认知过程,通过五阶段提示词链实现:问题澄清、初步判断、响应评估、决策确认、置信度评估。通过这一系列步骤,模型能够更严谨地完成复杂推理任务。
2.2.4 集成技术
在生成式人工智能领域,集成技术(Ensembling) 指通过构建多个提示词来求解同一个问题,再将这些提示词对应的模型输出聚合为最终结果的过程。在多数场景下,会采用多数投票法(即选择出现频率最高的输出结果)生成最终答案。集成技术能够降低大语言模型输出结果的方差,通常可提升任务准确率,但代价是需要增加模型调用的次数。
-
范例集成技术(Demonstration Ensembling, DENSE)(Khalifa et al., 2023)
该技术的流程为:首先构建多个少样本提示词,每个提示词包含训练集范例中互不重叠的子集;随后,对这些提示词的模型输出结果进行聚合,生成最终响应。 -
推理专家混合技术(Mixture of Reasoning Experts, MoRE)(Si et al., 2023d)
该技术的核心是构建一组具备不同推理能力的专家模型:针对不同的推理类型,设计专门的提示词(例如,用检索增强提示词处理事实性推理任务,用思维链提示词处理多跳推理与数学推理任务,用知识生成提示词处理常识推理任务);最后,基于一致性评分,从所有专家模型的输出中筛选出最优答案。 -
最大互信息方法(Max Mutual Information Method)(Sorensen et al., 2022)
该技术首先构建多个风格与范例各不相同的提示词模板;然后,将提示词与模型输出之间互信息最大的模板,选为最优提示词模板。 -
自一致性技术(Self-Consistency)(Wang et al., 2022)
该技术的核心思想是:多种不同的推理路径可以得到相同的正确答案。其流程为:首先,将温度参数设置为非零值(以生成多样化的推理路径),多次调用模型执行思维链推理;随后,对所有生成的输出结果进行多数投票,确定最终答案。该技术在算术推理、常识推理、符号推理等任务中均实现了性能提升。 -
通用自一致性技术(Universal Self-Consistency)(Chen et al., 2023e)
该技术与自一致性技术原理相似,核心区别在于多数投票的实现方式:它不通过编程统计答案出现的频次,而是将所有输出结果插入到一个专门的提示词模板中,由模型自动筛选出占多数的答案。这种方式适用于开放式文本生成任务,以及不同提示词可能生成表述略有差异的相同答案的场景。 -
基于多思维链的元推理技术(Meta-Reasoning over Multiple CoTs)(Yoran et al., 2023)
该技术与通用自一致性技术类似,流程分为两步:首先,针对给定问题生成多条推理链(不一定包含最终答案);然后,将所有推理链整合到一个提示词模板中,由模型基于这些推理链生成最终答案。 -
DiVeRSe技术(Li et al., 2023i)
该技术的流程为:首先,针对同一问题构建多个提示词;然后,对每个提示词执行自一致性技术,生成多条推理路径;接着,基于推理路径中的每一步骤进行评分;最后,结合评分结果筛选出最终响应。 -
基于一致性的自适应提示词技术(Consistency-based Self-adaptive Prompting, COSP)(Wan et al., 2023a)
该技术用于构建少样本思维链提示词,流程为:首先,对一组范例执行零样本思维链+自一致性技术;然后,筛选出输出结果一致性高的范例子集,将其作为少样本提示词的范例;最后,使用该少样本提示词再次执行自一致性技术,得到最终答案。 -
通用自适应提示词技术(Universal Self-Adaptive Prompting, USP)(Wan et al., 2023b)
该技术是在COSP技术的基础上改进而来,目标是实现对所有任务的通用适配。USP技术利用无标注数据生成范例,并采用更复杂的评分函数筛选范例;此外,该技术不再依赖自一致性技术。 -
提示词改写技术(Prompt Paraphrasing)(Jiang et al., 2020)
该技术的核心是在保留提示词核心语义的前提下,改写部分表述内容。本质上,这是一种数据增强技术,可用于生成集成技术所需的多样化提示词集合。
2.2.5 自我修正技术
在构建生成式人工智能系统的过程中,让大语言模型对自身输出结果进行自我修正是一种有效的优化手段(Huang et al., 2022)。这种修正既可以是简单的正确性判断(例如“该输出是否准确”),也可以是引导模型生成针对性反馈,并基于反馈进一步优化答案。目前,学界已提出多种生成与融合自我修正信息的技术方案。
-
自校准技术(Self-Calibration)(Kadavath et al., 2022)
该技术的流程分为两步:首先,引导大语言模型针对问题生成初始答案;随后,构建一个新的提示词,将原始问题、模型初始答案以及“判断该答案是否正确”的指令整合其中。这种方法有助于评估模型输出的置信度,进而辅助决策——确定是直接采纳原始答案,还是对其进行修正。 -
自优化技术(Self-Refine)(Madaan et al., 2023)
这是一个迭代优化框架:在模型生成初始答案后,引导同一模型针对该答案输出改进反馈;再基于这份反馈,继续提示模型优化答案。上述迭代过程会持续进行,直至触发停止条件(例如达到预设的最大迭代步数)。该技术在推理、代码生成、文本生成等多类任务中,均展现出显著的性能提升效果。 -
逆向思维链技术(Reversing Chain-of-Thought, RCoT)(Xue et al., 2023)
该技术的核心是通过逆向验证实现自我修正,流程为:首先,引导大语言模型基于已生成的答案,反向还原出对应的问题;然后,对原始问题与还原问题进行细粒度对比,以此检测两者之间的不一致性;最后,将这些不一致性转化为优化反馈,指导模型修正原始答案。 -
自验证技术(Self-Verification)(Weng et al., 2022)
该技术首先借助思维链(CoT)生成多个候选解决方案;随后,通过“掩码原始问题的特定部分,再让模型基于剩余问题内容与候选方案,预测被掩码部分”的方式,对每个候选方案进行评分。该方法在8个推理类数据集上均实现了性能提升。 -
验证链技术(Chain-of-Verification, COVE)(Dhuliawala et al., 2023)
该技术的流程为:第一步,让模型针对问题生成初始答案;第二步,构造一系列与初始答案相关的验证性问题(这些问题可用于检验答案的正确性);第三步,让模型逐一回答这些验证性问题;最后,将原始问题、初始答案、所有验证性问题及对应回答整合为新提示词,引导模型生成最终的修正答案。该技术在各类问答与文本生成任务中均表现出优化效果。 -
累积推理技术(Cumulative Reasoning)(Zhang et al., 2023b)
该技术的迭代流程为:首先,生成若干个解决问题的潜在推理步骤;然后,引导模型评估这些步骤,决定是采纳还是舍弃;最后,检查是否已通过采纳的步骤推导出最终答案——若已得到答案,则终止流程;若未得到,则重复上述迭代过程。该技术在逻辑推理与数学解题任务中实现了性能提升。
2.3 提示词技术的应用现状
正如前文所述,目前已涌现出大量文本类提示词技术,但在科研与工业界的实际应用中,仅有少部分技术得到了广泛采用。
本研究采用论文引用量作为衡量技术应用程度的代理指标——统计数据集内其他论文对各技术相关论文的引用次数。我们的前提假设是:聚焦于提示词技术的论文,更有可能实际使用或评估其所引用的技术。
我们绘制了数据集中被引次数排名前25的论文图谱,发现这些论文大多提出了新的提示词技术(图2.11)。少样本提示词技术(Few-Shot)与思维链提示词技术(Chain-of-Thought)的高引用率符合预期,这也为衡量其他技术的普及程度提供了基准参考。
2.3.1 基准测试
在提示词技术的相关研究中,当研究者提出一种新技术时,通常会在多个模型与数据集上开展基准测试。这一步骤至关重要,既能验证新技术的实用价值,也能检验其在不同模型间的迁移能力。
为了帮助提出新技术的研究者明确基准测试的方案,我们定量分析了当前主流的测试模型(图2.9)与基准数据集(图2.10),同样以数据集内论文对这些模型和数据集的引用次数作为衡量指标。
具体的统计流程如下:
- 调用
GPT-4-1106-preview,从数据集内的论文正文中提取所有提及的模型与数据集; - 通过人工筛选,剔除不属于模型或数据集的无关条目;
- 在Semantic Scholar数据库中检索最终列表内的条目,获取对应的引用次数。
2.4 提示词工程技术
除了梳理提示词技术外,本研究还综述了用于自动优化提示词的提示词工程技术。考虑到提示词工程技术的数量远少于提示词技术,本部分的讨论也涵盖了部分采用梯度更新的技术方案。
-
元提示词技术(Meta Prompting)
该技术的核心是引导大语言模型自主生成或优化提示词/提示词模板(Reynolds and McDonell, 2021; Zhou et al., 2022b; Ye et al., 2023)。其基础实现方式无需复杂的评分机制,仅通过简单的模板即可完成(图2.12);也有相关研究提出了更复杂的元提示词应用方案,引入多轮迭代流程与评分机制来提升优化效果(Yang et al., 2023a; Fernando et al., 2023)。
图2.12:简单的元提示词模板
-
自动提示词技术(AutoPrompt)(Shin et al., 2020b)
该技术基于冻结的大语言模型,并使用包含若干“触发令牌(trigger tokens)”的提示词模板。在训练阶段,通过反向传播算法更新这些触发令牌的取值,本质上属于软提示词技术的一种实现方案。 -
自动提示词工程师(Automatic Prompt Engineer, APE)(Zhou et al., 2022b)
该技术利用一组范例生成零样本指令型提示词,流程为:首先生成多个候选提示词并进行评分;然后基于得分最高的提示词,通过提示词改写等方式生成变体;最后迭代执行上述过程,直至满足预设的优化目标。 -
无梯度指令提示词搜索技术(Gradientfree Instructional Prompt Search, GrIPS)(Prasad et al., 2023)
该技术与APE原理相似,核心改进在于采用了更复杂的提示词变体生成策略,包含删除、添加、替换、改写等多种操作,以此对初始提示词进行优化。 -
基于文本梯度的提示词优化技术(Prompt Optimization with Textual Gradients, ProTeGi)(Pryzant et al., 2023)
这是一种独特的提示词工程方法,通过多步骤流程优化提示词模板:- 第一步:将一批输入样本传入待优化的提示词模板,得到模型输出;
- 第二步:将输入样本、模型输出、真实标签、原始提示词整合为新的提示词,引导模型对原始提示词提出改进意见;
- 第三步:基于改进意见生成新的候选提示词,并通过老虎机算法(bandit algorithm)(Gabillon et al., 2011)筛选最优方案。
实验表明,ProTeGi的优化效果优于APE、GRIPS等同类技术。
-
强化学习提示词技术(RLPrompt)(Deng et al., 2022)
该技术的核心是在冻结的大语言模型基础上,新增一个可训练的模块。其流程为:利用大语言模型生成提示词模板→在数据集上对模板进行评分→基于软Q学习算法(Soft Q-Learning)(Guo et al., 2022)更新新增模块的参数。值得注意的是,该技术筛选出的最优提示词模板,在语法上往往是不符合常规语义的。 -
基于对话策略梯度的离散提示词优化技术(Dialogue-comprised Policy-gradient-based Discrete Prompt Optimization, DP2O)(Li et al., 2023b)
这是目前最为复杂的提示词工程技术之一,融合了强化学习、自定义提示词评分函数、大语言模型对话交互等多种机制,以此完成提示词的构建与优化。
2.5 答案工程技术
答案工程(Answer Engineering) 是一个迭代过程,核心目标是设计或筛选出能从大语言模型输出中提取精准答案的算法。
要理解答案工程的必要性,我们可以以仇恨言论二分类任务为例——该任务的标签为“仇恨言论(Hate Speech)”与“非仇恨言论(Not Hate Speech)”,对应的提示词模板如下:
当输入一条仇恨言论样本时,模型可能生成多种表述的输出,例如:
- “It’s hate speech”
- “Hate Speech.”
- “Hate speech, because it uses negative language against a racial group”
这类输出格式的差异性会导致答案难以被稳定解析。优化提示词虽能在一定程度上缓解该问题,但效果存在局限性。
答案工程包含三项核心设计决策:答案空间(Answer Space)、答案形态(Answer Shape) 与答案提取器(Answer Extractor)(图2.13)。其中前两项由Liu等人(2023b)定义为答案工程的必要组件,本文补充了第三项。
我们认为,答案工程与提示词工程是相互独立但高度关联的技术领域,二者的优化流程通常需要协同进行。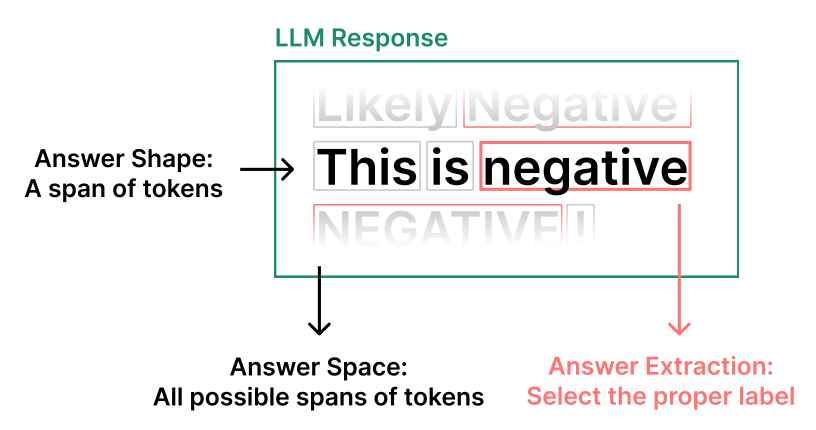
图2.13:一个用于标注任务的LLM输出的注释示例,展示了答案工程的三项设计决策:答案形态、答案空间和提取器的选择。由于这是一个分类任务的输出,答案形态可以被限制为单个词元(token),答案空间可以被限制为两个词元(“positive"或"negative”)中的一个,尽管在本图中它们未受限制。
2.5.1 答案形态
答案形态指的是模型输出的物理格式。例如,输出可以是单个令牌、一段令牌序列,甚至是图像或视频⁷。
在二分类这类任务中,将大语言模型的输出形态限制为单个令牌,往往能有效提升答案解析的稳定性。
2.5.2 答案空间
答案空间指的是模型输出结果的取值域。其范围可以是模型词表中的所有令牌,也可以是特定任务限定的取值集合——例如二分类任务中,答案空间仅包含两个令牌(对应两个类别标签)。
2.5.3 答案提取器
在两类场景下,需要使用答案提取器:一是无法完全控制答案空间的场景(如面向消费者的通用大语言模型);二是目标答案可能隐藏在模型长文本输出中的场景。
答案提取器通常是一条预设规则,既可以是简单的函数(如正则表达式),也可以借助一个独立的大语言模型来完成答案提取。常见的答案提取器类型包括:
-
语义映射器(Verbalizer)
该方法常用于分类任务,核心功能是建立模型输出与任务标签的双向单射映射(Schick and Schütze, 2021)。
例如在推文情感分类任务中,可引导模型输出“+”或“-”,再通过语义映射器将这两个令牌分别映射为“正面”和“负面”标签。语义映射器的设计与选型,是答案工程的重要组成部分。 -
正则表达式(Regex)
如前文所述,正则表达式是常用的答案提取工具,其典型用法是匹配输出中首次出现的标签。但在实际应用中,需结合输出格式灵活调整——例如当模型输出包含思维链(CoT)推理过程时,提取最后一次出现的标签往往能获得更准确的结果。 -
独立大语言模型(Separate LLM)
当模型输出格式过于复杂,正则表达式无法稳定提取答案时,可借助一个独立的大语言模型来完成提取工作。
该方法通常会在提示词中加入答案触发语句(Kojima et al., 2022),例如:“The answer (Yes or No) is”,以此引导模型精准提取目标答案。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 12
12 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)