GitHub热榜----打破语言巴别塔!BabelDOC:基于AI的文档翻译神器,格式完美保留!
摘要:BabelDOC是一款基于大语言模型的开源智能文档翻译工具,专为解决传统翻译工具的痛点而设计。它能完美保留PDF/Word的原始格式,精准处理代码块和专业术语,支持本地部署确保隐私安全。通过布局分析和Markdown中间态技术,BabelDOC实现了文档的结构化重组翻译,显著优于Google翻译等工具。文章详细介绍了从Docker部署到本地模型运行的完整教程,包括配置API、启动服务等步骤,
摘要:读英文论文、看原版技术文档还在用 Google 翻译复制粘贴?格式乱了、代码变了、专业术语翻得一塌糊涂?今天给你安利一款开源神器 BabelDOC。它利用大模型(LLM)的理解能力,不仅能精准翻译,还能完美保留 PDF/Word 的原始排版和格式。本文带你从原理到部署,彻底搞定本地化 AI 翻译流。


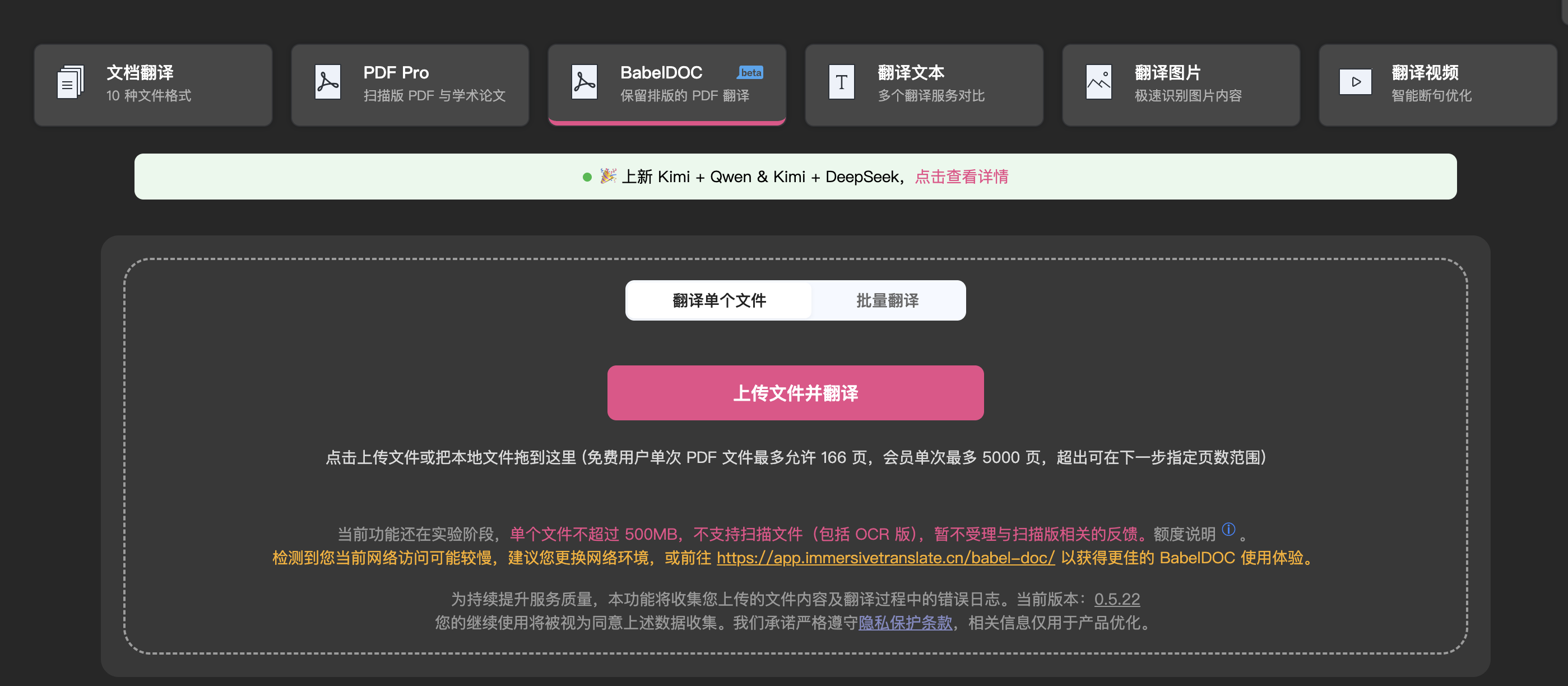
免部署直接使用链接:https://app.immersivetranslate.com/babel-doc/
😫 前言:我们受够了“机翻”的苦
作为开发者或科研人员,啃英文文档是日常。但传统的翻译工具有三大硬伤:
-
格式毁灭者:PDF 复制出来全是换行符,翻译完还得重新排版。
-
上下文缺失:一段代码、公式被强行翻译成中文,甚至变量名都被改了。
-
隐私泄露:机密文档上传到在线网站,心里总是不踏实。
GitHub 上的开源项目 BabelDOC 正是为了解决这些问题而生。它不仅仅是“翻译”,更是“文档重构”。
🔍 什么是 BabelDOC?
BabelDOC 是一个智能文档翻译框架。不同于传统的基于统计机器翻译(SMT)或神经网络翻译(NMT),BabelDOC 基于大语言模型(LLM)。
核心黑科技:
-
布局分析 (Layout Analysis):先识别文档中的标题、段落、表格、图片和代码块,确保翻译时不动这些结构。
-
Markdown 中间态:将复杂的 PDF/Word 转为 Markdown 进行翻译,然后再还原回原格式。
-
上下文感知:利用 GPT-4 或 DeepSeek 等模型的长窗口能力,理解整段逻辑,避免“断章取义”。
🛠️ 为什么它比 Google 翻译强?
我们来做一个简单的对比:
| 特性 | Google/DeepL 网页版 | BabelDOC (AI 驱动) |
| 翻译引擎 | 专用翻译模型 | 通用大模型 (LLM) |
| 专业术语 | 经常翻车 (尤其IT领域) | 精准 (可提示词调优) |
| 代码块处理 | 经常误翻译代码 | 完美保留代码原样 |
| 排版还原 | 弱,经常错位 | 强,基于结构化重组 |
| 隐私 | 数据上云 | 支持本地部署 (Ollama) |
💻 实战教程:5分钟搭建你的私有翻译站
下面教大家如何在本地跑起来(以 Docker 部署为例,这是最稳的方法)。
1. 环境准备
-
一台安装了 Docker 的电脑(Win/Mac/Linux 均可)。
-
一个 API Key(OpenAI、Anthropic 或 DeepSeek 均可)。
2. 获取项目
打开终端,Clone 项目代码:
Bash
git clone https://github.com/YourUsername/babeldoc.git
# 注:此处为示例链接,请替换为实际 GitHub 仓库地址
cd babeldoc
3. 配置模型 (Config)
大部分 AI 翻译工具都需要配置 .env 文件。复制模板:
Bash
cp .env.example .env
编辑 .env 文件,填入你的模型信息。为了省钱且效果好,强烈推荐使用 DeepSeek-V3:
代码段
LLM_PROVIDER=openai_compatible
API_BASE_URL=https://api.deepseek.com
API_KEY=sk-your-key-here
MODEL_NAME=deepseek-chat
4. 启动服务 (Docker Compose)
一键启动:
Bash
docker-compose up -d
5. 开始翻译
打开浏览器访问 http://localhost:3000。
-
上传你的 PDF 文件(例如《Attention Is All You Need》)。
-
选择源语言(English)和目标语言(Chinese Simplified)。
-
点击 Start Translate。
🎨 进阶玩法:本地模型零成本运行
如果你有显卡(Nvidia 3060 以上),甚至连 API 钱都不用花。
-
安装 Ollama:从官网下载并运行。
-
拉取模型:
Bashollama run qwen2.5:7b -
修改 BabelDOC 配置:
将 API_BASE_URL 指向 http://host.docker.internal:11434/v1。
这样,你的文档就在本地显卡里跑了一圈,变成了中文,断网也能用,安全感拉满!
⚠️ 常见问题与避坑
-
PDF 扫描件怎么办?
如果 PDF 是纯图片的扫描件,BabelDOC 通常会自动调用 OCR(如 PaddleOCR 或 Tesseract),但这会显著增加翻译时间。
-
表格错乱?
复杂的跨页表格是所有翻译工具的噩梦。建议在翻译前,先用 Adobe Acrobat 将 PDF 简单转为 Word,效果会好很多。
-
Token 消耗:
翻译一本 50 页的论文会消耗大量 Token。建议先用 DeepSeek 或 Qwen 等高性价比模型测试,土豪请直接上 GPT-4o。
🎯 总结
BabelDOC 代表了翻译工具的未来——不仅是语言的转换,更是信息的重构。
它不再只是把 "Hello" 变成 "你好",而是像一个懂技术的助教,帮你把晦涩的英文文档重新排版、整理成你熟悉的中文资料。
如果你也是“文档苦主”,赶紧去 GitHub 上 Star 一下,部署一套试试吧!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 10
10 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)