从零开始学DeepResearch:使用LangGraph构建专业AI研究框架!
DeepResearch是一种专业AI研究范式,采用Plan-Execute-Synthesize三步流程,将复杂研究任务分解为可执行的工作流。文章介绍了多种DeepResearch框架实现,并重点展示如何使用LangGraph进行实践,包括状态管理、工具集成和工作流可视化。通过模块化设计,可整合网络搜索、网页访问和学术搜索等工具,构建完整的AI研究助手,帮助用户系统性地完成深度研究任务。
简介
DeepResearch是一种专业AI研究范式,采用Plan-Execute-Synthesize三步流程,将复杂研究任务分解为可执行的工作流。文章介绍了多种DeepResearch框架实现,并重点展示如何使用LangGraph进行实践,包括状态管理、工具集成和工作流可视化。通过模块化设计,可整合网络搜索、网页访问和学术搜索等工具,构建完整的AI研究助手,帮助用户系统性地完成深度研究任务。
想象这样一个场景,老板让你:“研究下电动汽车行业的发展趋势,下周一交付”。
面对这个任务,你会怎么做?直接问DeepSeek:“电动汽车行业发展趋势如何”?还是在谷歌百度上搜索些文章,组合一下?还是会像专业研究员一样,制定研究计划,多方收集信息,深度分析后形成报告?
这就是DeepResearch的价值所在。它不是简单的推理问答,而是一套完整的研究范式,定义了如何进行深度研究的标准流程和思维模式,将复杂的研究任务分解为工作流,让你也具有专业研究员的能力。
本文将通过LangGraph来实践DeepResearch工作流,从零构建一个专业AI研究助手。
DeepResearch:研究范式
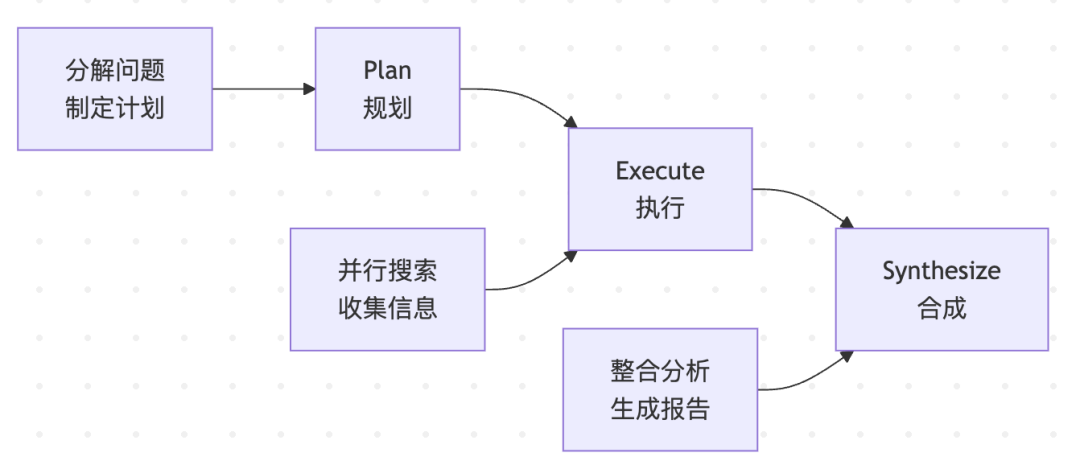
三步范式:Plan → Execute → Synthesize
根据OpenAI官方发布的Deep Research指导文档,DeepResearch的核心架构是三步范式:
-
- Plan(规划阶段)
- • 目标: 将复杂问题分解为可独立研究的子问题
比如研究电动汽车行业发展趋势,拆解的问题可能是:收集2025年全球电动汽车市场规模数据、研究电动汽车技术突破、分析各国电动汽车政策影响。每个子问题都是独立的、具体的、可执行的研究任务。
-
- Execute(执行阶段)
- • 目标: 执行子任务收集和分析信息
在执行阶段会使用多种工具,整合数据库的信息,做对比总结。
-
- Synthesize(合成阶段)
- • 目标: 将子问题的答案整合成连贯的最终报告
DeepResearch框架
DeepResearch是一个范式,具体有多种框架实现。目前主流的DeepResearch实现如下:
| 框架名称 | 组织 | 特色功能 | GitHub Stars |
|---|---|---|---|
| 通义DeepResearch | Alibaba | 开源,IterResearch范式,端到端训练 | 2.8k |
| DeerFlow | ByteDance | 完整WebUI,集成Coder做数据分析 | 15.1k |
| OpenDeepResearch | HuggingFace | ReAct范式,动作即代码 | 21.2k |
| LangChain版本 | LangChain | 加入反思(Reflect)机制 | 4.3k |
| DeepResearchAgent | SkyworkAI | 使用browser-use自动化 | 1.1k |
| AutoDeepResearch | HKUDS | 基于AutoAgent框架 | 1k |
LangGraph实践优势
-
- 状态管理
class ResearchState(TypedDict): """研究状态定义 - 管理整个研究流程的状态""" question: str # 原始研究问题 research_plan: List[Dict[str, Any]] # 研究任务计划 search_results: List[Dict[str, Any]] # 搜索结果历史 final_answer: Optional[str] # 最终答案 should_continue: bool # 是否继续研究
-
- 可视化工作流
LangGraph可以把复杂的研究逻辑转化为流程图:
workflow = StateGraph(ResearchState)workflow.add_node("plan_research", plan_research_node)workflow.add_node("execute_search", execute_search_node)workflow.add_node("synthesize_answer", synthesize_answer_node)# 添加条件边 - 实现智能路由workflow.add_conditional_edges( "plan_research", decide_next_action, { "search": "execute_search", "synthesize": "synthesize_answer" })
-
- 不同工具集成
可以定义不同的工具来执行
# 工具定义@tooldef web_search(query: str, num_results: int = 5) -> List[Dict]: """网络搜索工具""" return search_engine.search(query, num_results)@tool def academic_search(query: str, field: str = "all") -> List[Dict]: """学术搜索工具""" return scholar_api.search(query, field)
通过Langgraph来实践,可以理解并掌握DeepResearch的实现原理,又能根据需求定制。
项目:基于LangGraph的DeepResearch实现
https://github.com/ditingdapeng/langgraph-deepresearch
项目采用模块化设计,组件包括:
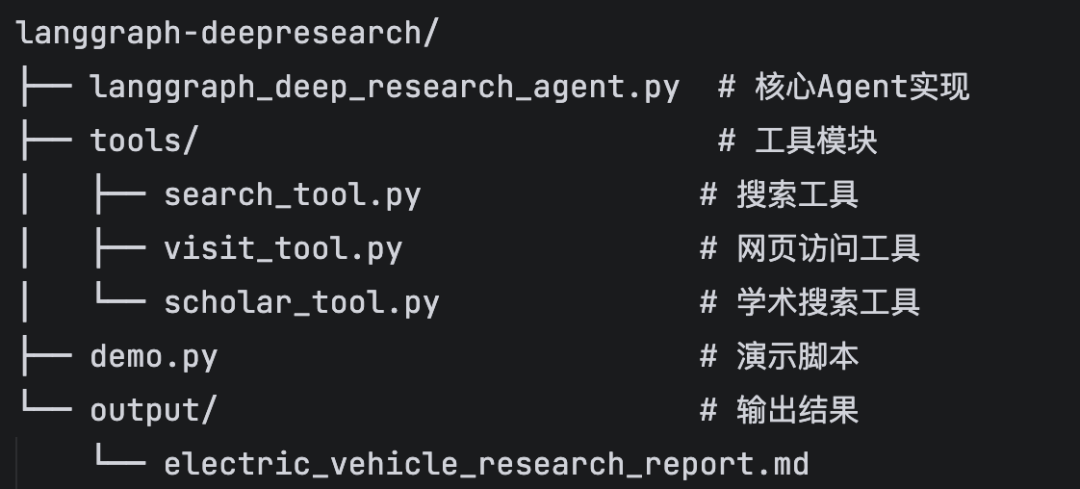
定义状态管理
状态管理就像研究员的笔记本,要记录整个研究过程:研究计划、研究过程、思考分析、输出报告。
class ResearchState(TypedDict): """研究状态定义 - 管理整个研究流程的状态""" # 基础信息 question: str# 原始研究问题 current_round: int# 当前研究轮次 max_rounds: int# 最大研究轮次 # 研究计划 research_plan: List[Dict[str, Any]] # 研究任务计划 current_task: Optional[Dict[str, Any]] # 当前执行任务 completed_tasks: List[int] # 已完成任务ID列表 # 研究过程 search_results: List[Dict[str, Any]] # 搜索结果历史 visit_results: List[Dict[str, Any]] # 网页访问结果历史 scholar_results: List[Dict[str, Any]] # 学术搜索结果历史 # 思考和报告 round_thoughts: List[str] # 每轮思考记录 round_reports: List[str] # 每轮报告记录 # 最终输出 final_answer: Optional[str] # 最终答案 research_summary: Optional[str] # 研究总结
集成工具
定义工具箱,即你需要从哪个数据来源获取数据。我这里定义了三个:Serper网络搜索、Jina网页提取、学术搜索。
-
- 搜索工具 (SearchTool)
class SearchTool: """基于Serper API的搜索工具""" def _run(self, query: str) -> str: """执行搜索并返回结果""" # 调用Serper API进行搜索 # 返回格式化的搜索结果
-
- 网页访问工具 (VisitTool)
class VisitTool: """基于Jina API的网页内容提取工具""" def _run(self, url: str) -> str: """访问网页并提取关键内容""" # 使用Jina API提取网页内容 # 通过LLM分析和总结内容
-
- 学术搜索工具 (ScholarTool)
class ScholarTool: """Google Scholar学术搜索工具""" def _run(self, query: str) -> str: """搜索学术论文和引用""" # 搜索Google Scholar # 提取论文标题、作者、引用等信息
工作流实现
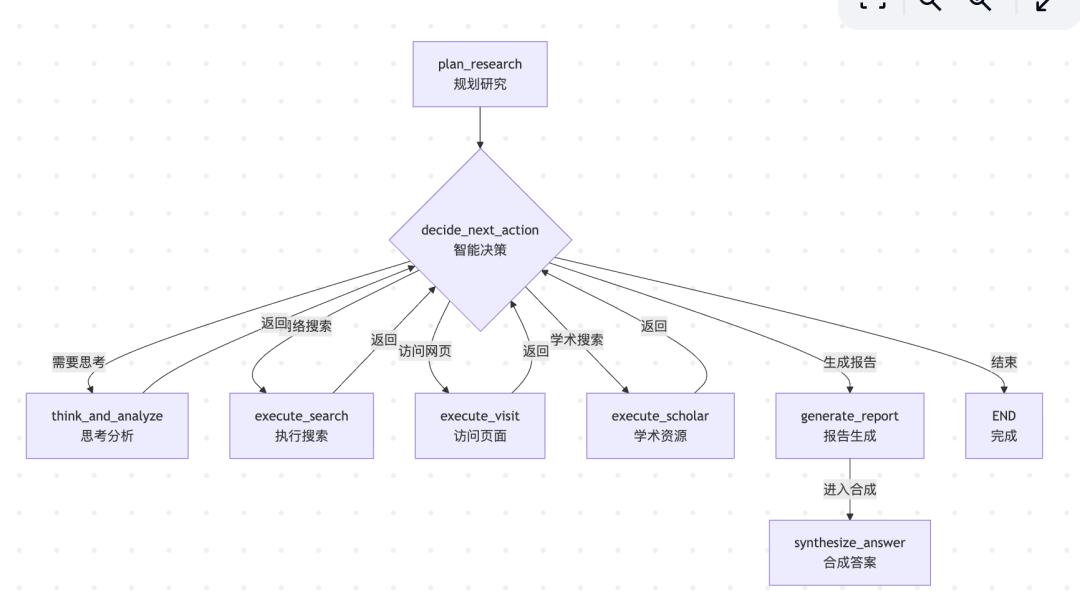
将Plan-Execute-Synthesize范式转化为LangGraph工作流。
-
- 规划节点 (plan_research_node)
def _plan_research_node(self, state: ResearchState) -> ResearchState: """规划研究任务""" # 分析研究问题 # 生成研究计划 # 分解子任务 return updated_state
-
- 思考分析节点 (think_and_analyze_node)
def _think_and_analyze_node(self, state: ResearchState) -> ResearchState: """思考和分析当前研究状态""" # 分析已收集的信息 # 决定下一步行动 # 更新研究策略 return updated_state
-
- 执行节点群
- •
execute_search_node: 执行网络搜索 - •
execute_visit_node: 访问具体网页 - •
execute_scholar_node: 搜索学术资源
-
- 合成节点 (synthesize_answer_node)
def _synthesize_answer_node(self, state: ResearchState) -> ResearchState: """合成最终答案""" # 整合所有研究结果 # 生成结构化报告 # 评估答案质量 return updated_state
运行效果:
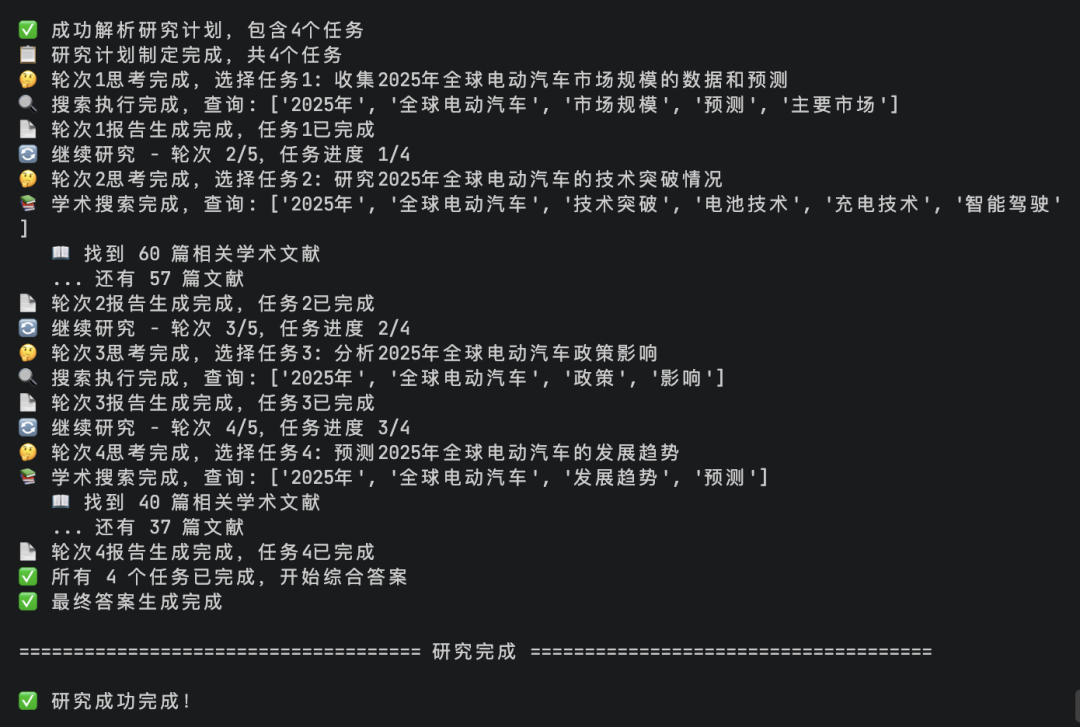
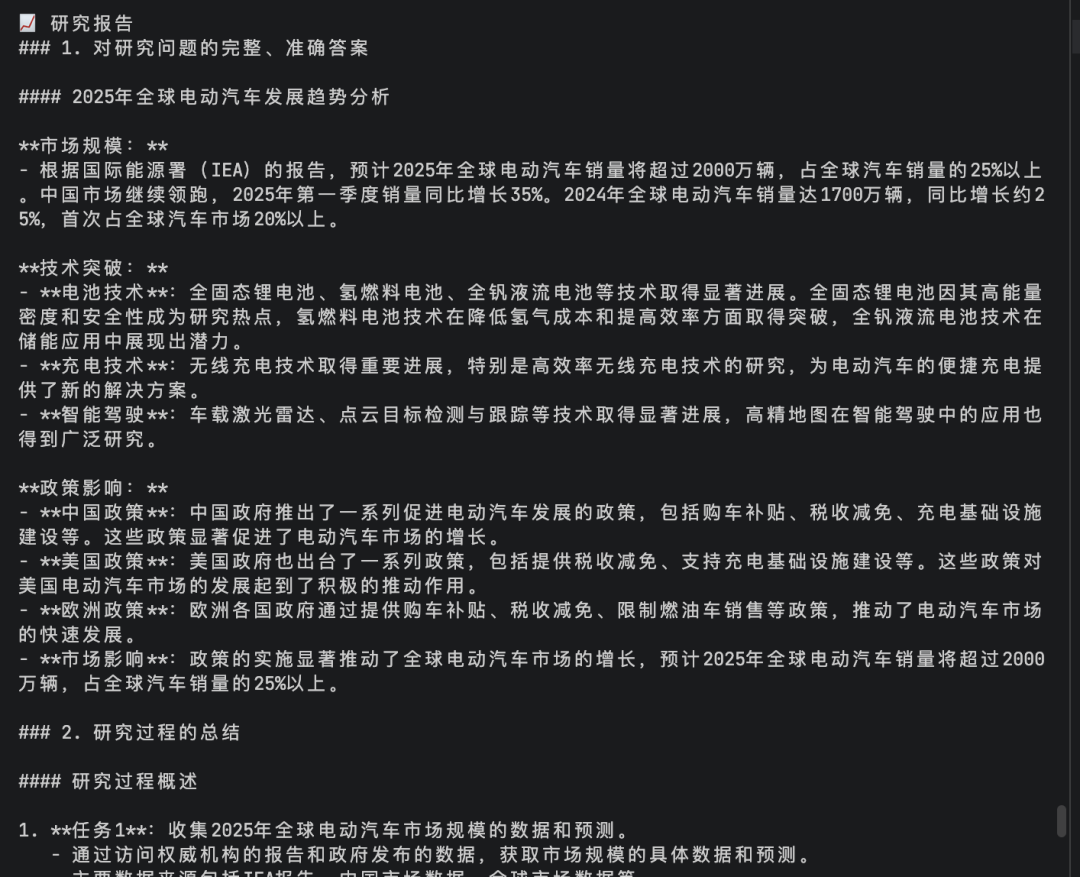
报告生成内容如下:
如何学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

学习路线

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 12
12 0
0- 0



 已为社区贡献196条内容
已为社区贡献196条内容

所有评论(0)