「斯坦福大学」提出思维“格式塔”:预训练大模型时加入历史摘要
斯坦福大学提出 LLM 预训练新范式
前言
这是一篇来自斯坦福的论文,对 LLM 的预训练任务提出了挑战。之前也有不少类似的工作,但通常都在模型规模提升后失去优势,或是仅带来少量训练效率优化,本文也只在 GPT2 级别的小模型上做了实验
考虑到相关思路与提出的新架构比较有启发性,也值得做一次记录
- 论文标题:Modeling Language as a Sequence of Thoughts
- 论文地址:https://arxiv.org/pdf/2512.25026
动机:next-token prediction 的局限性
这是个老生常谈的问题,token 级语言建模容易出现几类现象:
- 思考不充分: 自回归任务设置下,模型一拿到问题就开始回答。尽管可能具备“边说边想”的能力,但确实与人类“三思而后行”的思维方式不同
- 反转诅咒: 学会“A -> B”后不能稳定地泛化到“B -> A”,像是只记住了句子表面模式
- 数据效率低: 不同于人类刚见到一个新概念就能总结出可复用的印象,模型需要吞下大量 token 才学到稳定知识
传统 LM 像是把整场会议录音逐字打出来,当提问“那我们的结论是什么”时,它需要从录音里再临时检索、拼接答案;而人类更常做的是:一边听一边写“议题-结论-行动项”,之后复盘时直接查要点
所以作者的核心主张是:在 token 之上建一层更稳定、抽象的状态,让模型学会“写要点”
“格式塔”是一个源自德语的心理学概念,意为“整体”。其核心思想是人类在感知事物时,倾向于将零散的元素组织成有意义的整体,而不是简单地感知各个部分,并体现出显著的“整体大于部分之和”效果
实现方案:如何记录、提炼、回顾“要点”?
作者提出的模型叫 Thought Gestalt(TG),它仍然用 next-token loss 训练,但把处理流程改成“以句子为步长”的循环:一次生成/训练一整句 token,然后把这句压缩成一个句子向量写入记忆
做“会议纪要”
可以把 TG 看成两个人协作:
- 速记员(token 层)
负责把当前一句话的每个 token 预测出来;句内仍用 self-attention - 纪要员(thought 层)
每句结束时写下一个“要点向量”,放进外部记忆;后面说下一句时,模型会用 cross-attention 去读这些要点,像开会时不断翻前面记的纪要
更具体地:TG 在中间层拿到位置的隐藏状态,通过一个简单的映射头变换成句子向量 (m_t) 作为本句的“要点”;接着把 (m_t) 写进记忆(只保留最近 M 个句子的要点);下一句生成时,模型不仅做句内 self-attention,还会交替插入 cross-attention 去融合上下文
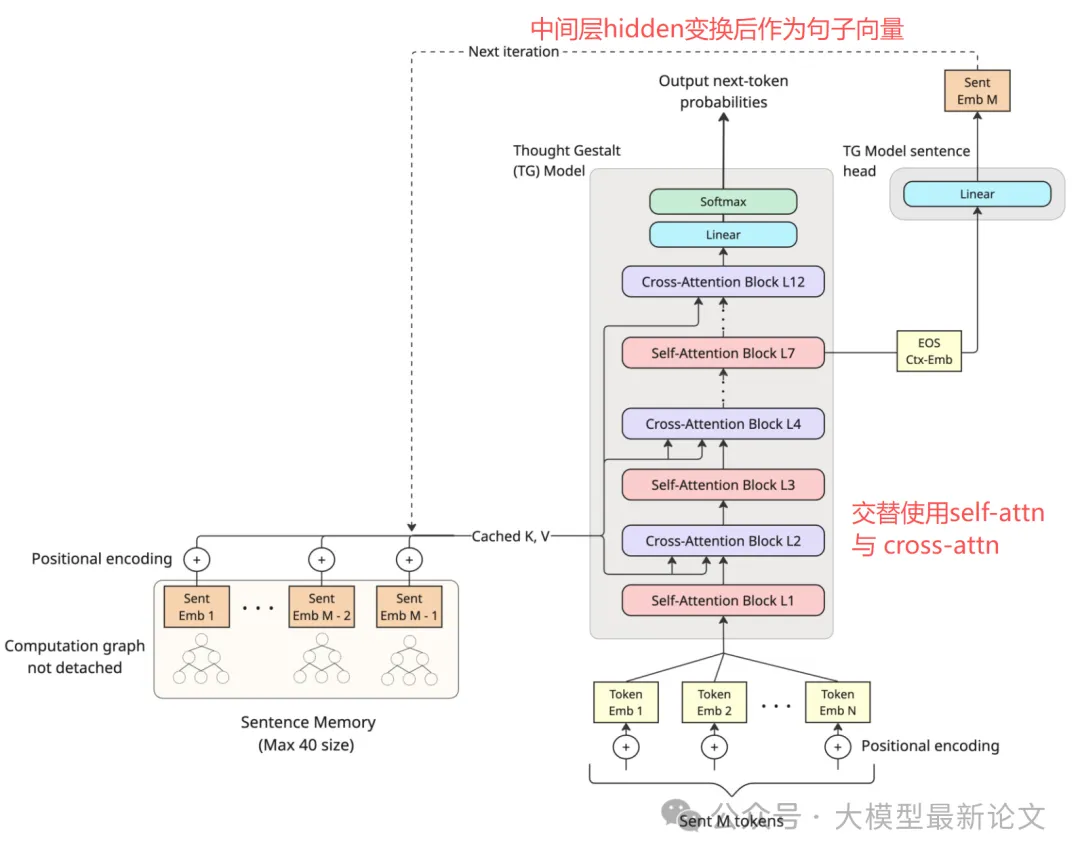
恰当的”追责机制“
TG 有一项关键设计:要点内容被提取出去后,要保证其梯度不中断
继续用会议纪要比喻:如果纪要员写下要点后,就把它永久锁定(detach),那无论后面项目做砸了还是做成了,纪要员都不会被追责,也就学不会“什么样的纪要才真正有用”。 而 TG 的做法是:后面句子的预测损失会反向传播回来,告诉模型:你之前写的那条纪要到底帮没帮上忙,相当于一种“事后问责机制”,逼迫句子向量变得更语义化、更可复用。消融实验有力支持了此操作
但不截断梯度会让反向传播链路变长,如果“追责追到姥姥家”会让计算成本爆炸。为此 TG 把文档切成“句子流”(sentence streams),每条流只包含最多 S 句,让梯度最多跨 S 句回传。同时应用课程学习的思想,先训练短流(追责范围小),再逐步增加 S(追责范围扩大)
首尾优化
把完整连贯的长文本切分成句子流,让开头与结束这两个状态出现得非常频繁,对此作者提出了两项优化点:
- 使用上一个句子向量替换的 embedding,让每句话开头就带着上下文(开口前先扫一眼上条纪要)
- 大幅降低结束符权重,因为它太容易预测,容易造成“刷分”
效果:TG 到底好在哪?
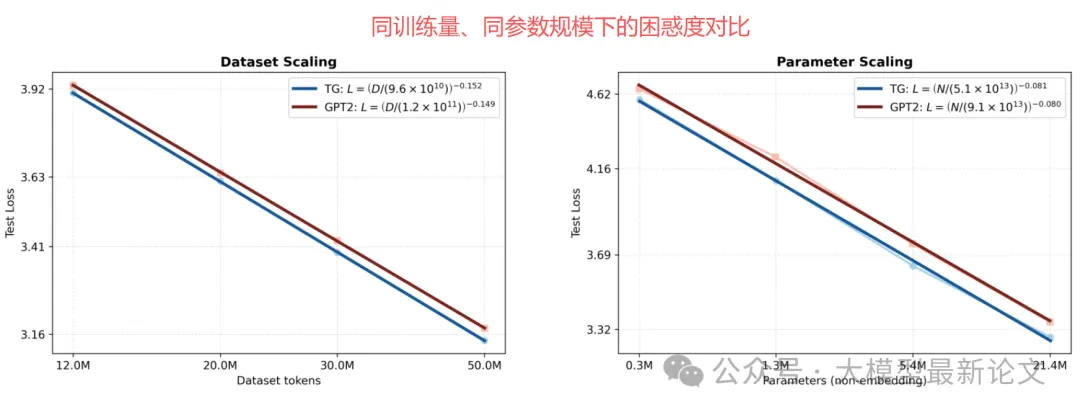
更省数据、更省参数:“会写纪要的人更快上手”
在 12M–50M tokens 的数据范围里,TG 的测试困惑度系统性更低;拟合结果显示,GPT-2 需要多约 5–8% 的训练 token 才能追上 TG; 固定数据量(50M tokens)做参数扩展时,GPT-2 需要 1.33–1.42 倍参数量才能达到 TG 的 loss(困惑度计算时排除了容易预测的)
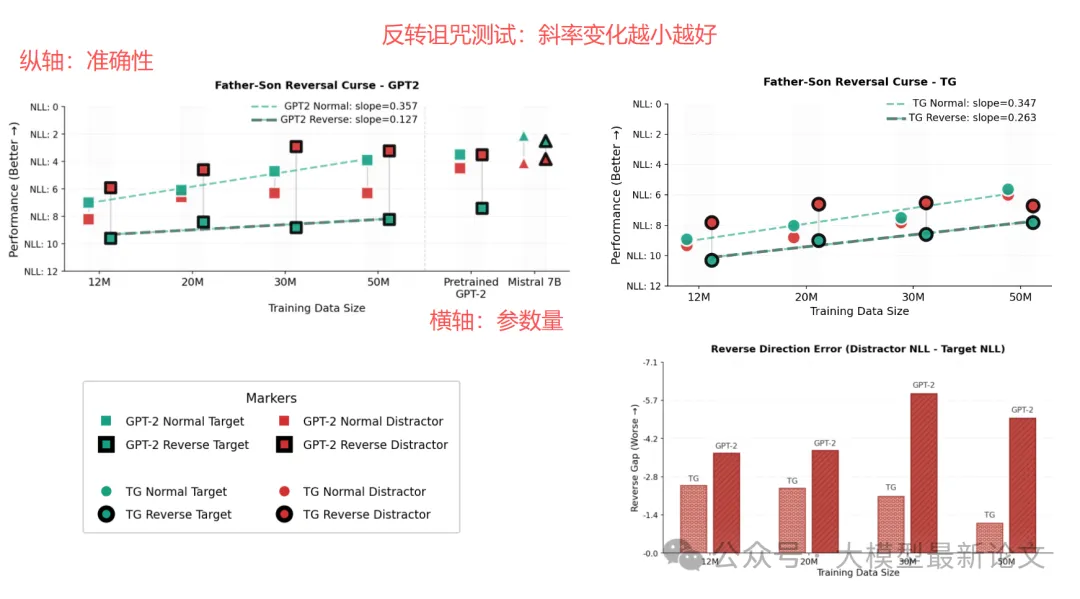
reversal curse 改善:“记住了关系的含义,而不只是句式”
在“父子关系”任务中,TG 在反向提问(“John 的父亲是?”)上的提升斜率明显大于 GPT-2,说明它更容易把关系抽象成可双向使用的语义,原因在于隐空间的”要点“更加抽象、不容易受模式影响
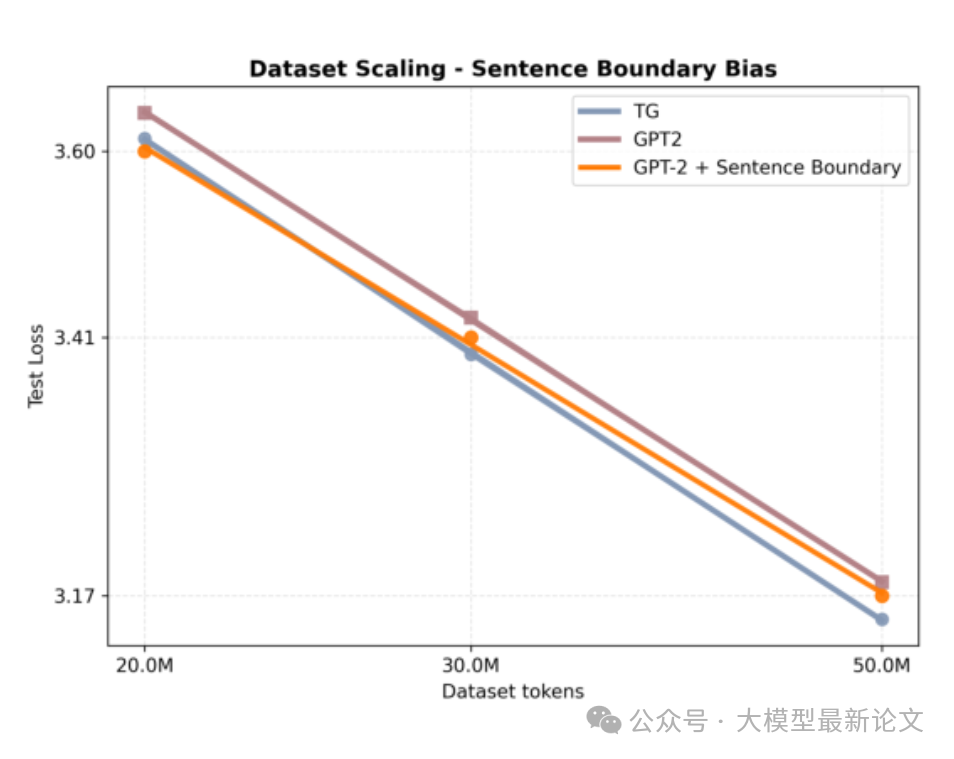
提升并非源自简单的文本结构优化
作者也测试了直接在 GPT2 中加入文本结构标签(如 与 )的效果,结果体现为一开始有少许优势,但随着模型尺寸提升,快速回归到了原生 GPT2 的困惑度水平
缺陷:这套“纪要机制”还不完美
1)句子不等于思维边界: 真实“想法块”可能跨句或句内分段。把纪要强行按句写,可能出现“一个关键结论被拆成两句”或“一句里塞了两件事”的情况
2)评测不足: TG 能否在更大规模、更复杂推理/数学/长文理解中带来稳定收益,还有待验证

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 17
17 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)