【大模型入门必看】DeepSeek 居然是个输入法?揭秘大模型背后的假象与真相
ChatGPT、DeepSeek已经成了日常工具,但你真的懂它们吗?如果你认为大模型是“一个连着巨大知识库、会思考的机器人”,那就大错特错!作为一线Agent架构师,我要告诉你一个反直觉的真相:大模型根本没有“脑子”,也不懂逻辑。它唯一会做的竟然只是“文字接龙”,和你手机里的输入法本质一样?为什么它会一本正经地胡说八道?那些爆火的“思考模型”真相又是什么?点进来,司沐带你彻底祛魅,重塑你对AI的认
你好,我是司沐。
大模型(LLM)已经火了三年多了。
从最初惊艳全球的 ChatGPT,到今年年初的国产之光 DeepSeek,以及百花齐放的豆包、千问、Claude、Gemini、Kimi等等,大家每天都在用。
但如果我问你:“你觉得大模型到底是什么?”
绝大多数人的回答可能是:
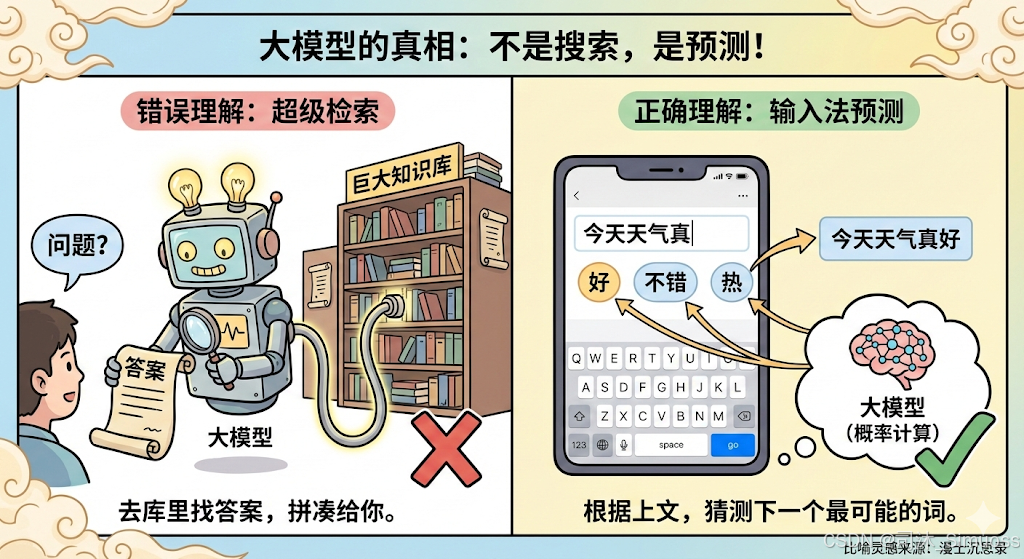
“它是一个超级机器人,背后连着一个巨大的知识库。我问它问题,它就去库里检索,然后把答案拼凑出来给我。”
这听起来很合理,但这是错的。
作为一名 Agent 系统架构师,我经常需要向客户或是刚入行的开发者解释这个问题。
在最近的一次对谈中,我用了一个输入法的例子,让一位计算机专业的同学彻底打破了对大模型的幻想。
这个比喻来自于B站UP主漫士沉思录的这支视频:【硬核科普】GPT等大模型是怎么工作的?为啥要预测下一个词?。真的是非常优秀且易于理解的比喻。
如果你比起文字更喜欢看视频,可以直接看他的这支视频。
今天,我也想帮你祛个魅。理解了原理,你才能明白为什么它会一本正经地胡说八道,以及所谓的“会思考的模型”到底是怎么回事。
01 它没有“大脑”,它只是在玩“文字接龙”
我们要承认一个反直觉的事实:大模型本质上不理解它在说什么。
它既不懂逻辑,也不懂真理。它唯一擅长的一件事,叫做预测下一个字(Next Token Prediction)。
想象一下你手机上的输入法。
当你打出“我”字的时候,输入法会猜你下一个字想打什么?
- 大概率是:“们”、“想”、“去”、“爱”这种字。
- 几乎不可能是:“桌”、“跑”、“飞”这种字,除非你在搞抽象。
如果你一直点击候选词的第一个词,输入法也能连成一句话,虽然可能逻辑不通。
大模型(LLM),其实就是一个吃过了全人类书本、网页、代码数据的“超级输入法”。
它看过的书太多了,多到它掌握了语言之间极其复杂的概率联系。
- 当你问:“1+1等于几?”
- 它并不是在做算术运算,它是在预测:在人类的语料中,“1+1等于”这几个字后面,概率最高的下一个字是“2”。
所以,GPT(Generative Pre-trained Transformer) 这个名字其实就暴露了它的本质:
- Generative(生成): 它是在生成(补全)文字。
- Pre-trained(预训练): 它提前学下了海量数据的概率关系。
01 它没有“大脑”,它只是在玩“文字接龙”
我们要承认一个反直觉的事实:大模型本质上不理解它在说什么。
它既不懂逻辑,也不懂真理。它唯一擅长的一件事,叫做预测下一个字(Next Token Prediction)。
想象一下你手机上的输入法。
当你打出“我”字的时候,输入法会猜你下一个字想打什么?
- 大概率是:“们”、“想”、“去”、“爱”这种字。
- 几乎不可能是:“桌”、“跑”、“飞”这种字,除非你在搞抽象。
如果你一直点击候选词的第一个词,输入法也能连成一句话,虽然可能逻辑不通。
大模型(LLM),其实就是一个吃过了全人类书本、网页、代码数据的“超级输入法”。
它看过的书太多了,多到它掌握了语言之间极其复杂的概率联系。
- 当你问:“1+1等于几?”
- 它并不是在做算术运算,它是在预测:在人类的语料中,“1+1等于”这几个字后面,概率最高的下一个字是“2”。
所以,GPT(Generative Pre-trained Transformer) 这个名字其实就暴露了它的本质:
- Generative(生成): 它是在生成(补全)文字。
- Pre-trained(预训练): 它提前学下了海量数据的概率关系。

02 既然是补全文字,为什么它能跟我“对话”?
有同学会问:“司沐老师,如果它只是补全文字,那应该是我写半句,它补半句才对,就像他帮我写文章一样。为什么我问它问题,它能像个人一样回答我?”
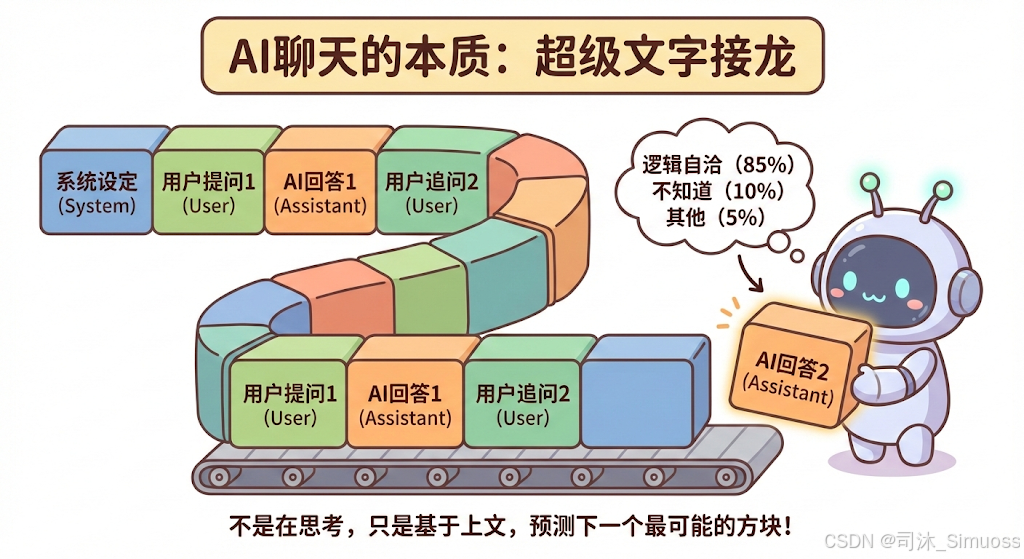
这就要提到大模型训练的第二阶段:后训练(Post-training)。
在预训练阶段,模型确实只是个“补全机器”。但在后训练阶段,工程师给它喂了一种特殊格式的数据:
User: 你好。
AI: 你好!有什么我可以帮你的吗?<结束>
User: 讲个笑话。
AI: 有一天…<结束>
模型通过大量学习这种**“对话剧本”**,学会了一种惯性:
当看到“User: xxx”时,它不仅要预测下一个字,还要模仿“AI”的语气生成回答,并且在说完后自动生成一个“停止符”(EOF)。
所以,你在屏幕上看到的“人工智能对话”,在模型眼里,不过是它在努力补全一个**“对话剧本”的下一行**而已。
为了让读者充分理解,我在这里放一份基于Llama3模型特殊Token的一段对话的底层文本,大家可以看看,我们与大模型的所谓“对话”,在大模型眼里到底是什么样子的:
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
你是一位诚实的技术型AI助手,你的任务是用通俗易懂的语言解释大模型的原理。
<|eot_id|>
<|start_header_id|>user<|end_header_id|>
为什么我觉得你在思考?你真的理解我在说什么吗?
<|eot_id|>
<|start_header_id|>assistant<|end_header_id|>
这其实是一种错觉。严格来说,我并没有“理解”或“思考”这种人类的主观意识。
我当下所做的,只是基于你输入的文字序列(Context),计算下一个最可能出现的字(Token)是什么。就像你看到“白日依山”,脑海里大概率会自动补全“尽”一样。现在的对话,本质上就是一场参数规模达到数千亿级别的、极其复杂的“成语接龙”。
<|eot_id|>
<|start_header_id|>user<|end_header_id|>
可是你的回答逻辑很连贯,如果只是“文字接龙”,怎么能做到逻辑自洽呢?
<|eot_id|>
<|start_header_id|>assistant<|end_header_id|>
因为我见过的“接龙”样本足够多(万亿级 Token)。所谓的“逻辑自洽”,本质上是统计学上的高概率路径。
比如现在,当我的输入端接收到了你质疑的“逻辑自洽”这几个字,我的内部权重矩阵被激活,计算出“用统计规律来解释”这一路径的概率最高。所以我生成这段话,不是因为我主观上“想”反驳你,而是因为在人类的语料库里,针对这类质疑的文本后面,通常都接续着类似的解释。我只是顺着概率的滑梯滑下来了而已。
<|eot_id|>
03 为什么它会撒谎?(大模型幻觉的成因)
理解了“概率预测”的本质,你就明白为什么大模型会有**“幻觉”**(一本正经地胡说八道)了。
很多用户问:“它的数据库是不是该更新了?为什么我问它2015年我家楼下拆迁的事,它说得头头是道,但其实根本没这回事?”
真相是:大模型内部根本没有“数据库”。
它没有挂载一个 SQL 或 NoSQL 数据库去存“事实”。它的所有知识,都“熔化”在了几千亿个参数(权重)里。
当你问它一件不存在的事,如果你的语气非常笃定,模型会根据概率判断:
“在这个语境下,为了让这段话顺畅地接下去,我应该顺着用户说。”
它不在乎真假,它只在乎“顺不顺口”(概率高不高)。 这就是为什么它经常会编造论文、编造代码库,因为它是在用概率拼凑一个看起来像真的的东西。
04 揭秘“思考模型”:o1 和 DeepSeek 的“脑子”在哪?
在2025年年初前后,OpenAI 的 o1 和国内的 DeepSeek-R1 等“思考模型”非常火。它们在回答问题前,会先展示一段长长的思考过程(Chain of Thought)。
很多人以为:哇,模型进化出了一个“大脑思考区”,在真正地进行逻辑推理!
司沐老师要泼一盆冷水:这也是假象。
所谓的“思考”,本质上也是模型生成的文字(Token)。
对于模型来说,它并没有分出“思考”和“回答”两个脑区。只是工程师在训练时,强行让它学习了一种新格式:
User: 这个问题怎么解?
AI: <思考> 首先,我应该分析一下… 然后… </思考> <回答> 答案是 B。
为什么要多此一举?
因为 Transformer 架构有一个特性:它在生成下一个字时,会回头看之前生成的所有字。
如果让模型直接给答案,它可能因为“想”得不够深而给错答案(概率预测走偏了)。
但如果强制它先生成一段“碎碎念”(也就是思考过程),这些碎碎念就变成了新的上下文(Context)。
模型自己给自己铺垫了一堆逻辑,当它终于要生成“<回答>”的时候,前面的上下文已经足够丰富,这时候预测出来的答案,准确率就大大提高了。
所以,并没有什么神奇的“机器意识觉醒”,有的只是更精妙的“上下文工程”。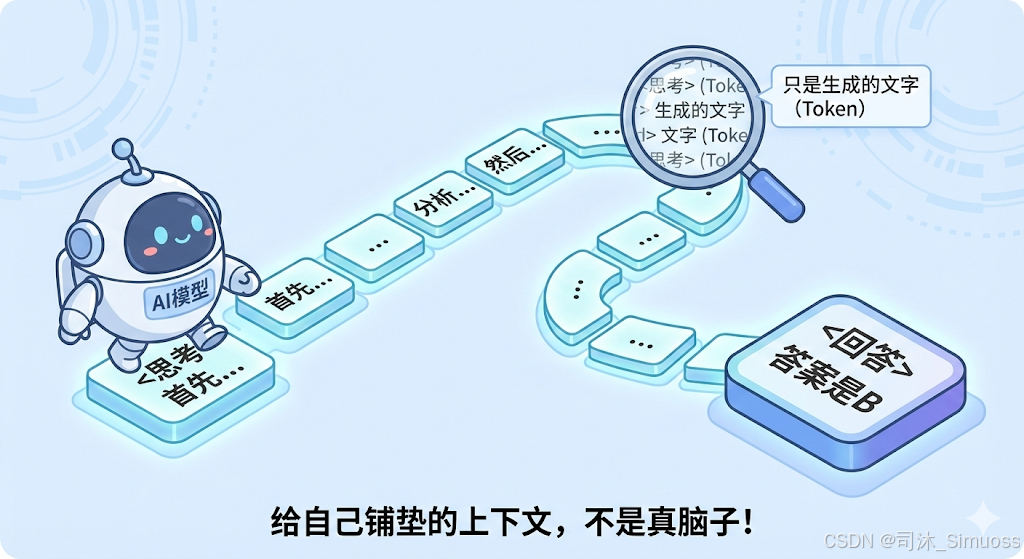
司沐老师的总结
对大模型祛魅,是为了更好地了解它,从而搭建出更妙的AI应用。
- 知道它是概率预测机,你就不会盲信它的事实类回答,而会去核实(或者使用搜索工具 RAG)。
- 知道它是上下文补全机,你就知道 Prompt(提示词)的重要性——你给的上下文越清晰,它预测的下一个字就越准。
- 知道思考也是生成,你就明白为什么有时候我们需要引导模型“一步步想”,这其实是在帮它铺路。
这就是大模型,一个没有感情、没有真理,但被数学赋予了惊人能力的“超级输入法”。
那么问题来了:
既然模型只能生成文字,它又是怎么帮我们联网搜索、操作电脑、甚至写文件的呢?
这就涉及到了 AI 应用架构中最迷人的部分——Agent(智能体)。
下期预告:
大模型只是个“只会说话的脑子”,它是如何调用工具的呢?
下一篇,司沐老师将为你拆解 Agent 架构——那群“伺候”大模型的人。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 22
22 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)