AI大模型:python汉字识别+数字识别+字母识别系统 百度API 检测识别系统 文档 基于 Python 与百度 API 的多类型字符识别与管理系统
AI大模型:python汉字识别+数字识别+字母识别系统 百度API 检测识别系统 文档 基于 Python 与百度 API 的多类型字符识别与管理系统
·
博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2025年计算机专业毕业设计选题汇总(建议收藏)✅
1、项目介绍
技术栈: Python语言、Django框架、百度API【手写文字识别】、数据集、
汉字+数字+字母识别系统+百度API+文档
2、项目界面
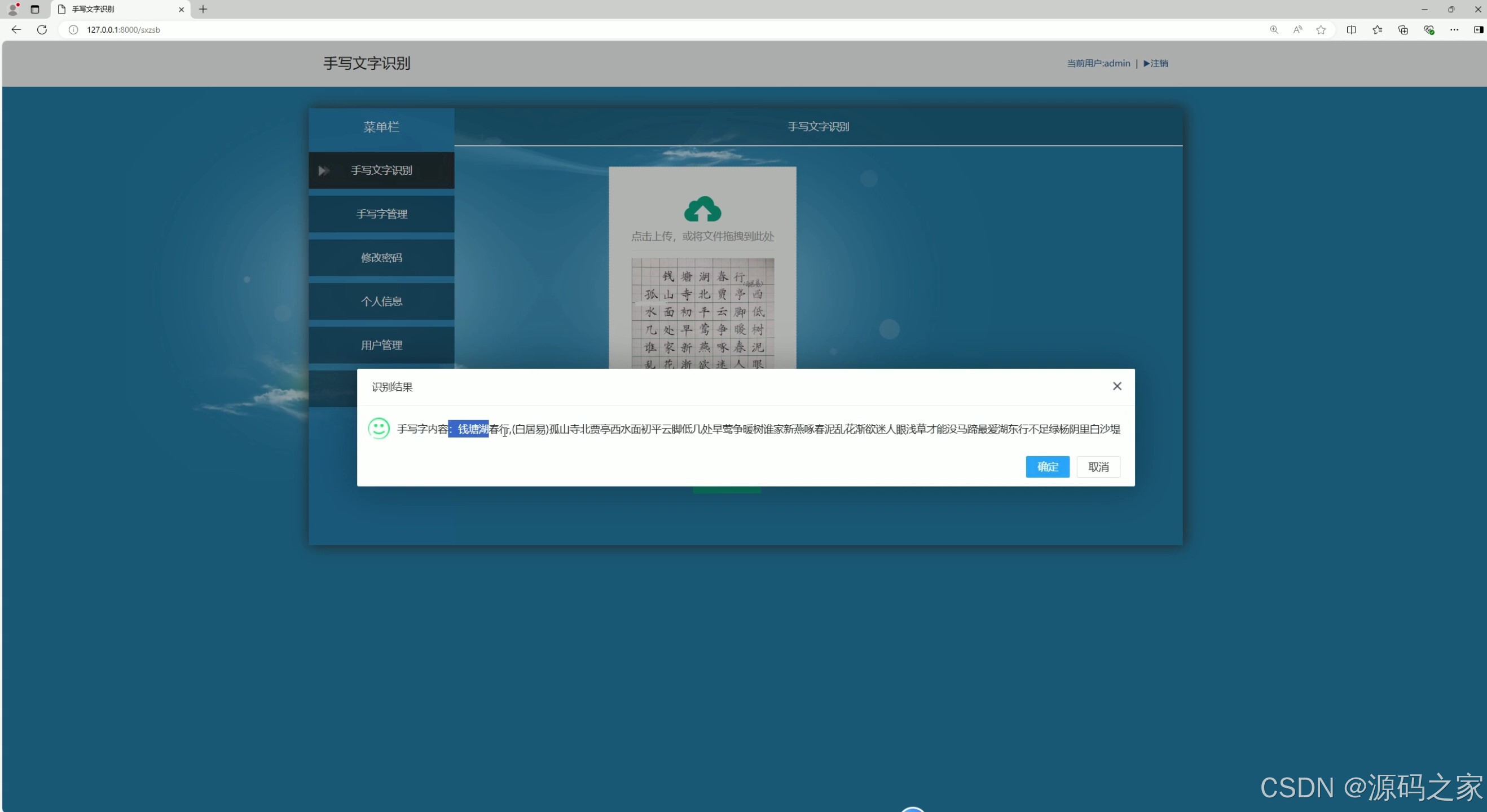
(1)汉字检测识别
(2)数字检测识别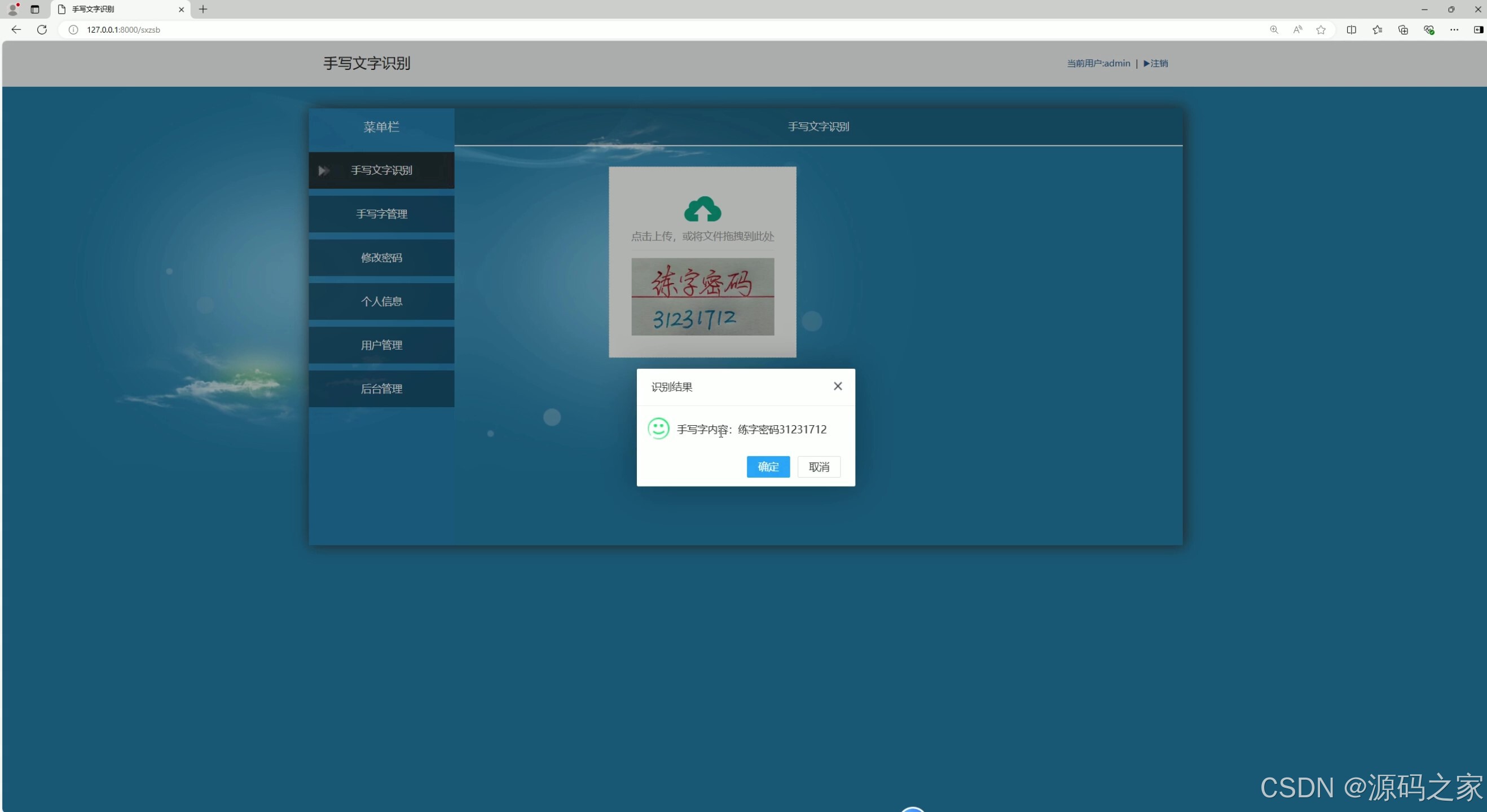
(3)英文字母检测识别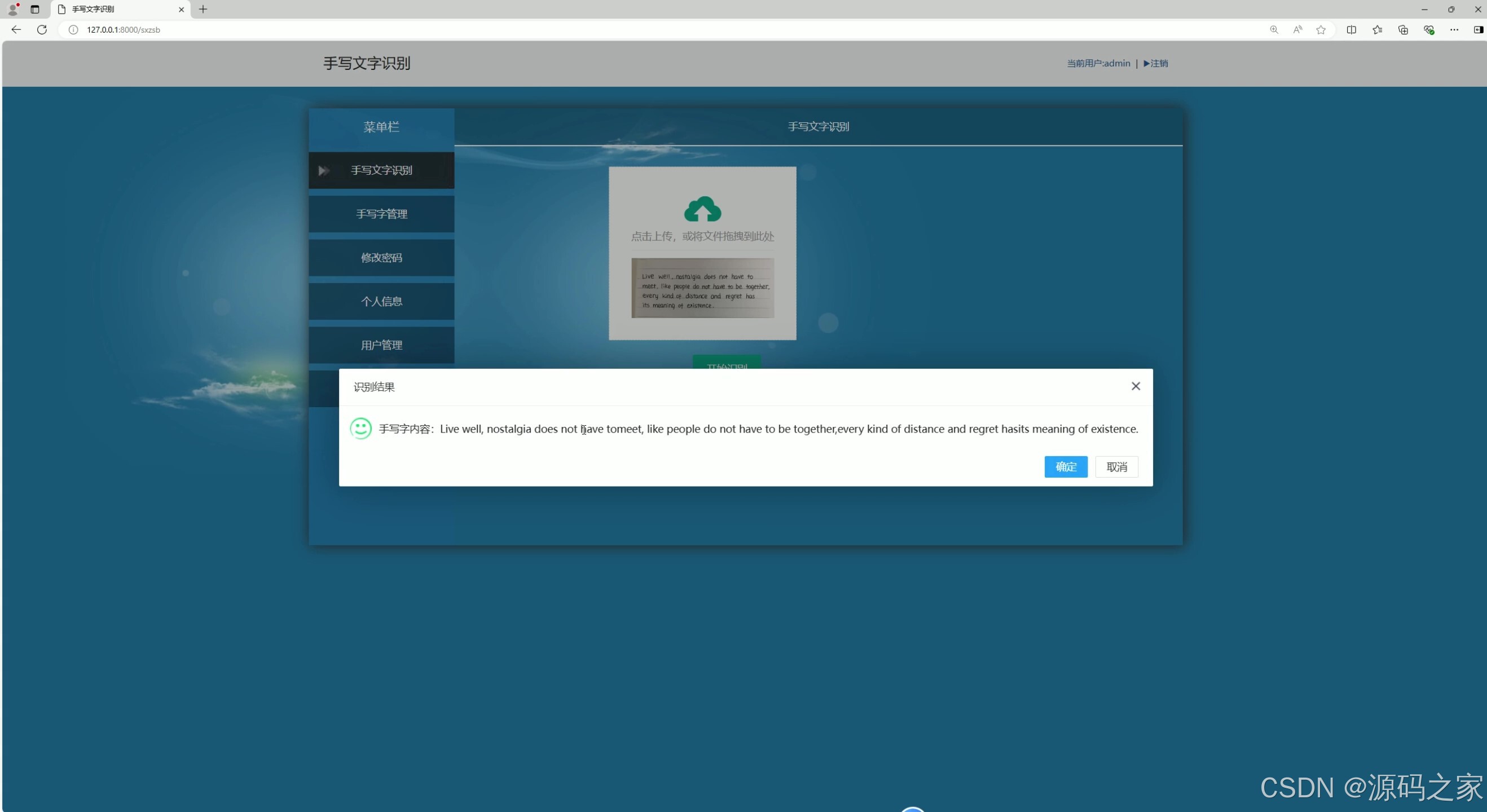
(4)数学公式检测识别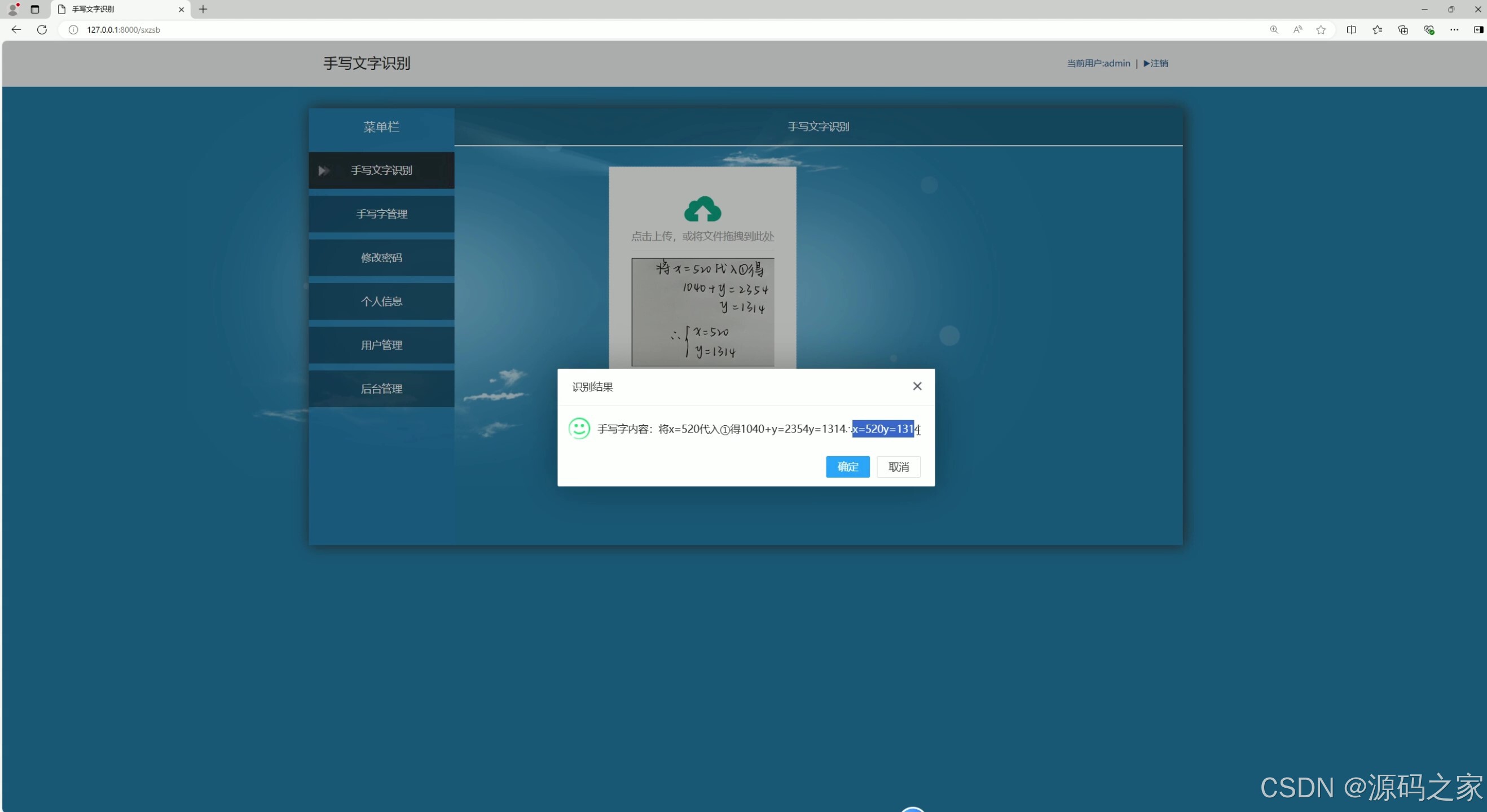
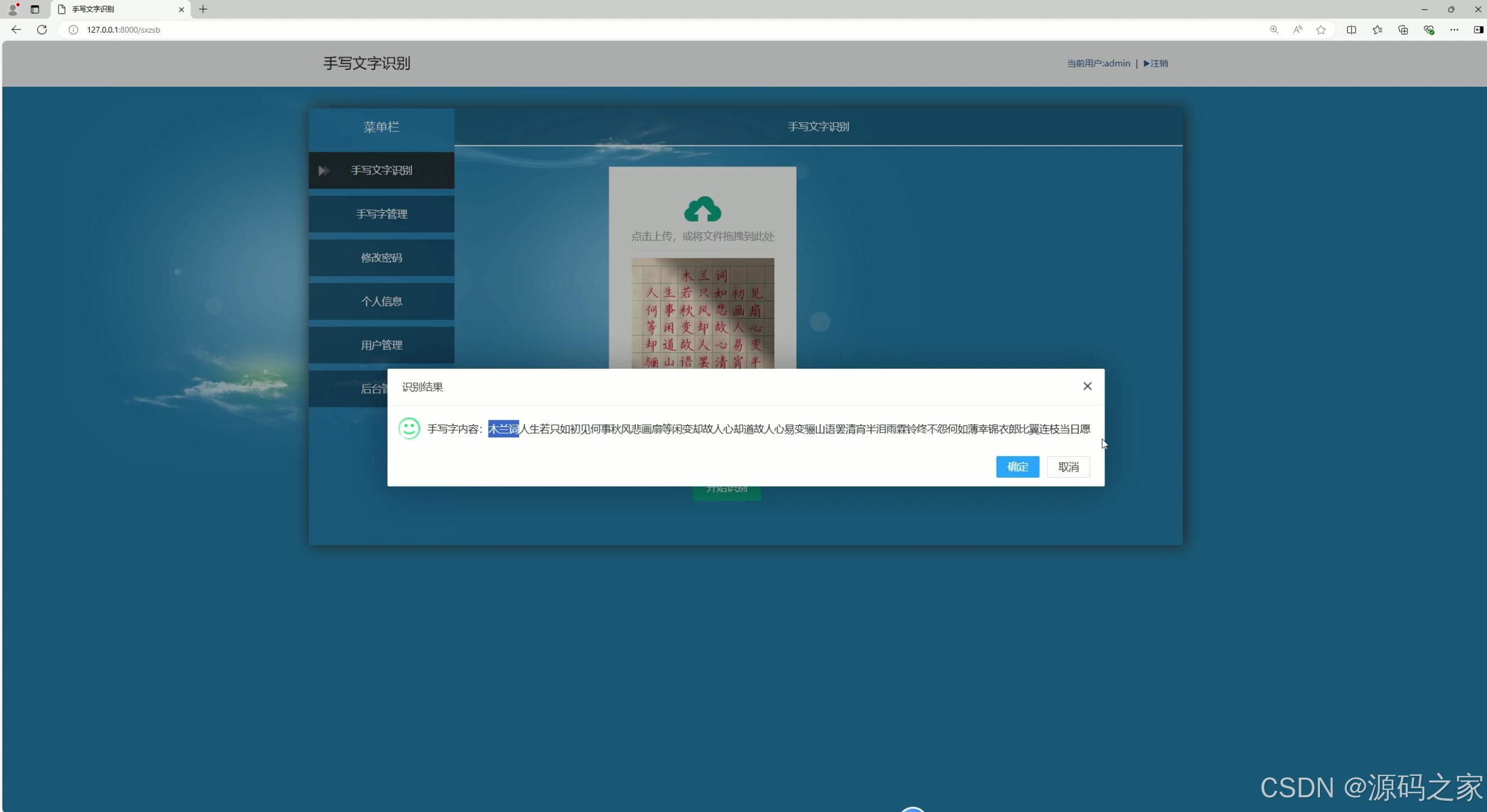
(5)汉字识别
(6)识别内容管理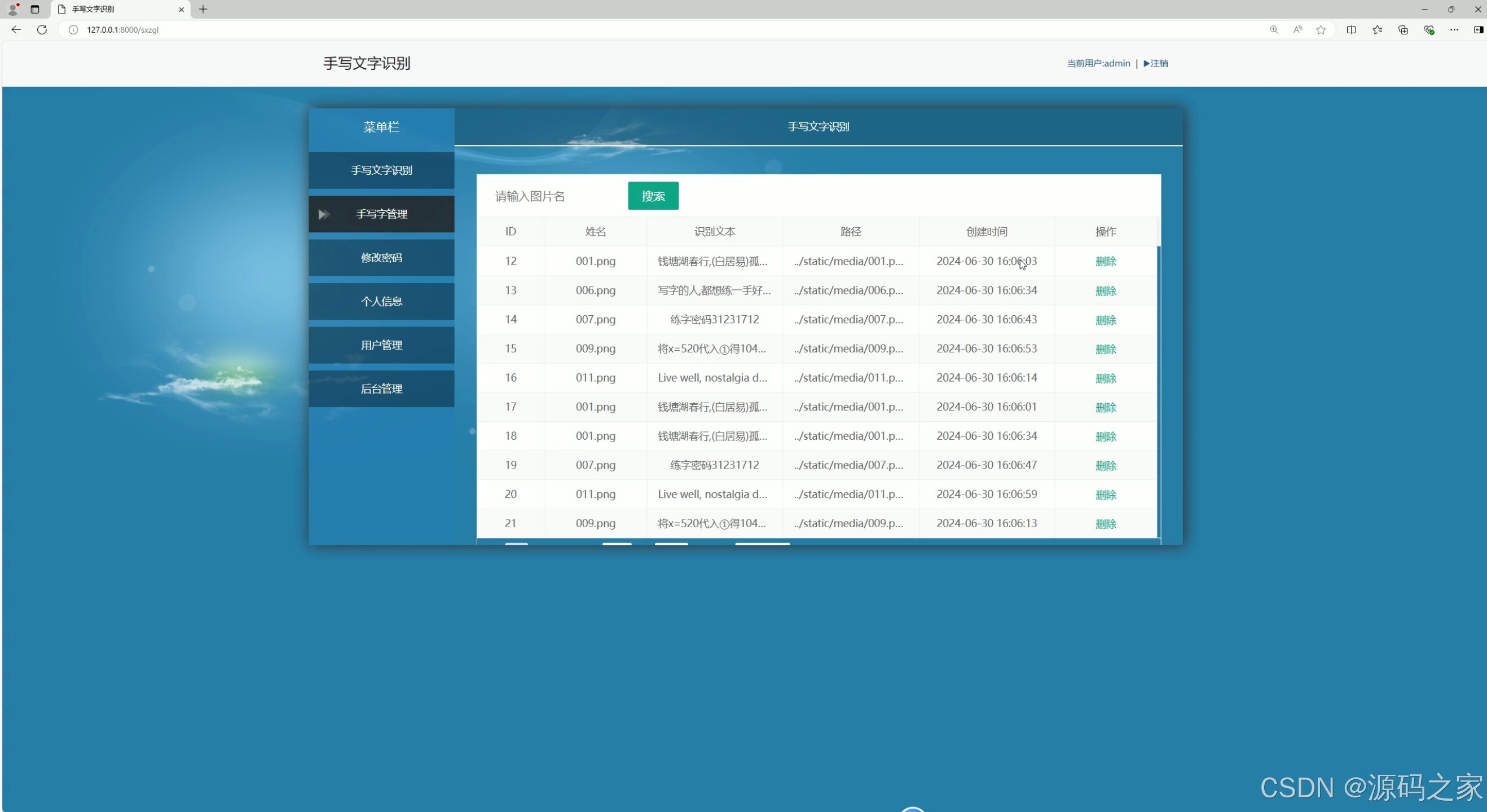
(7)用户管理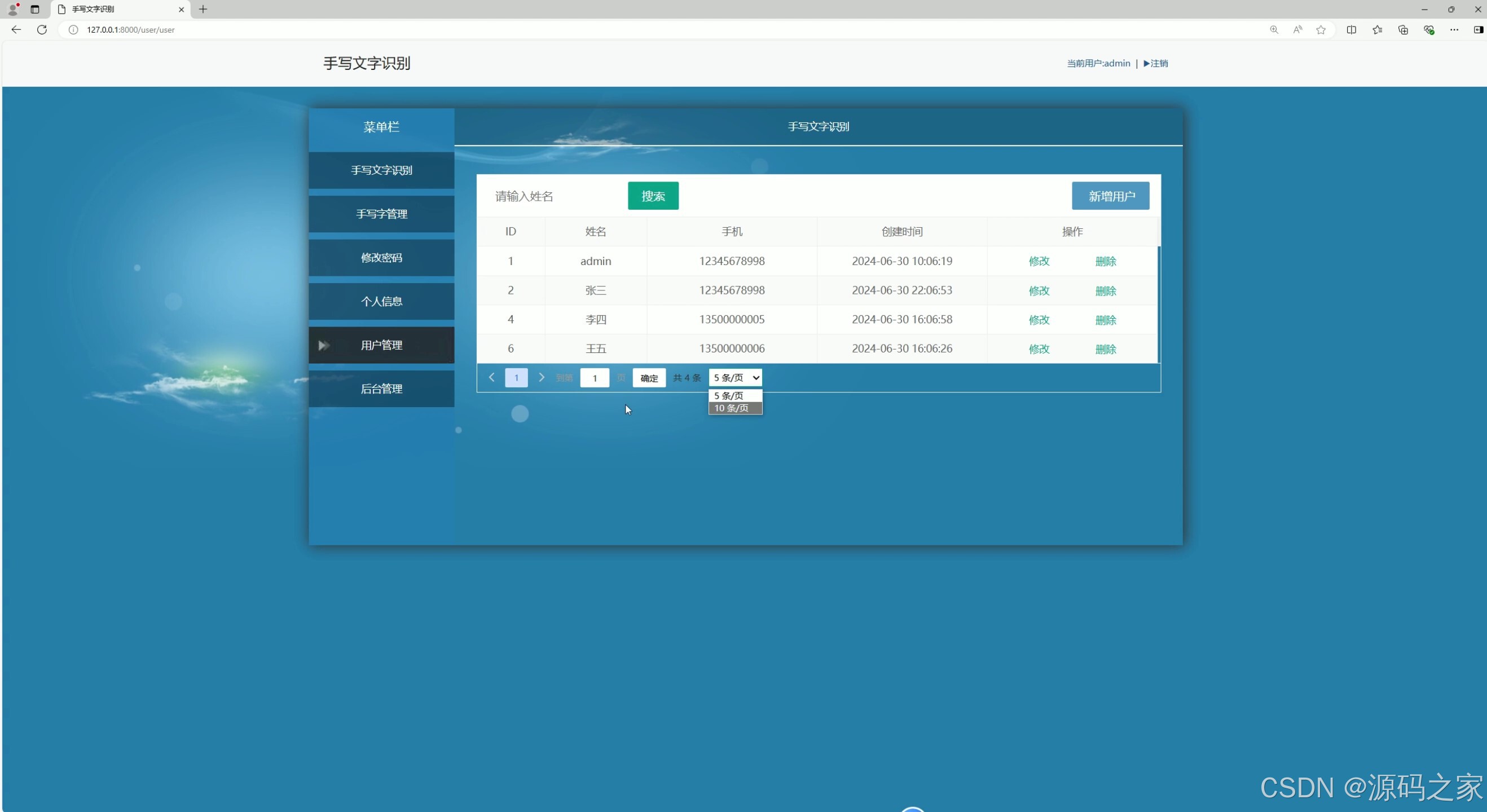
(8)后台数据管理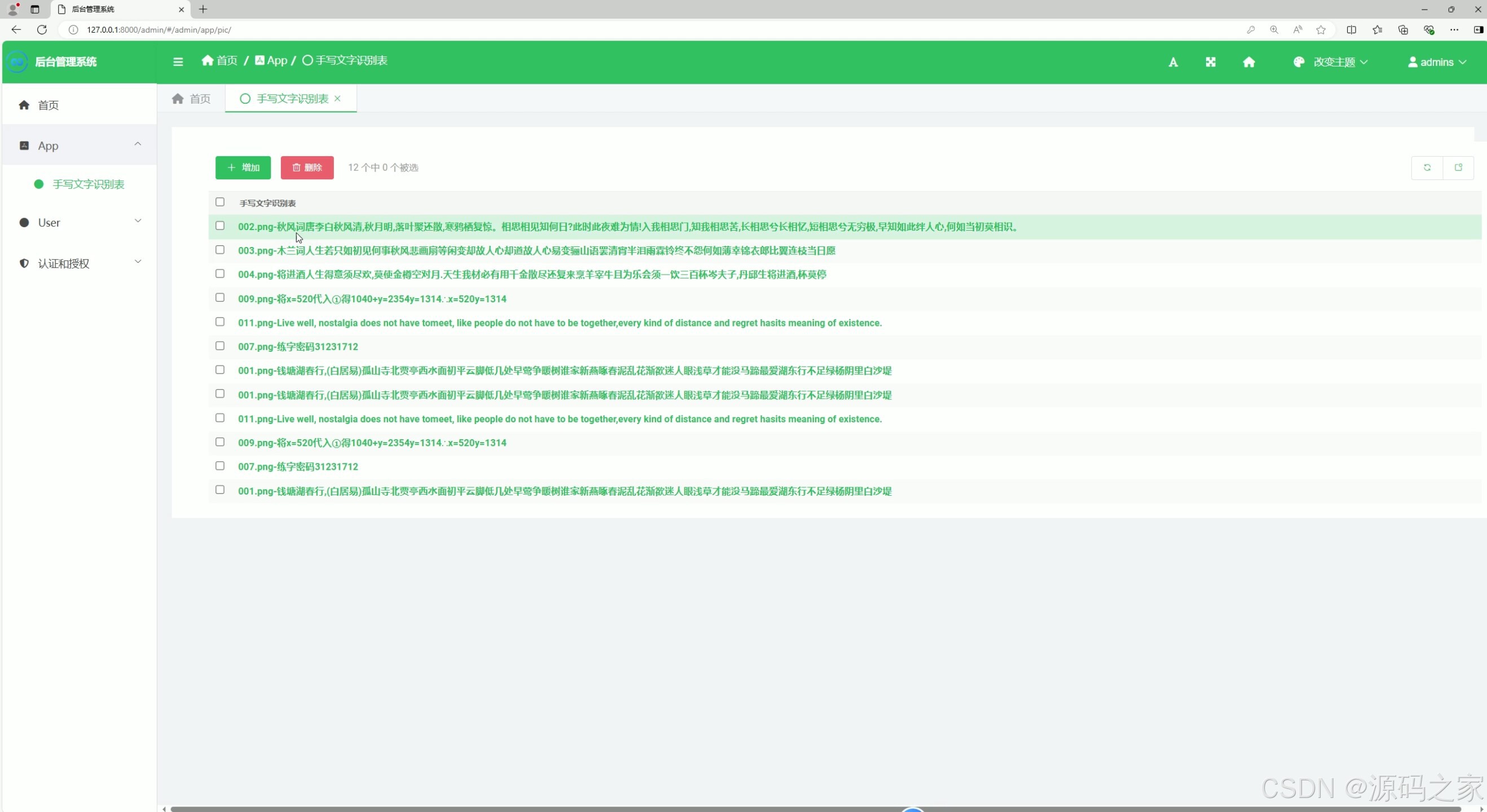
(9)注册登录
3、项目说明
本项目是一款专注于字符识别的智能化系统,以Python 语言为开发基础,借助Django 框架搭建稳定的 Web 架构,集成百度手写文字识别 API实现高精度字符提取,结合专业数据集优化识别模型,可高效完成汉字、数字、字母及数学公式的识别任务,同时支持文档相关处理,适用于办公文档录入、教育资料识别、数据统计等多场景。
系统界面功能覆盖识别全流程,且分工明确。汉字检测识别界面(含 2 个细分界面)与数字、英文字母检测识别界面,分别针对不同类型字符优化识别算法,上传待识别图像后,能快速输出识别结果并展示准确率;数学公式检测识别界面则突破常规字符识别局限,可精准识别复杂公式结构与符号,解决公式手动录入效率低的问题;识别内容管理界面支持对历史识别记录进行查询、导出、删除等操作,方便用户追溯与复用识别结果;用户管理界面与后台数据管理界面构建完善的系统管控体系,前者实现用户账号注册、权限分配,后者负责识别数据存储、系统参数配置,保障数据安全与系统稳定;注册登录界面通过身份验证机制,确保只有授权用户可使用系统功能,守护数据隐私。
该系统将 API 技术与多类型字符识别需求深度结合,大幅提升字符录入效率,减少人工操作误差,同时通过 Django 框架实现功能模块化管理,兼顾实用性与易用性,为各行业字符处理提供高效、精准的技术解决方案。
4、核心代码
import numpy as np
import os
from PIL import Image
from sklearn.svm import SVC
import joblib
from sklearn.metrics import confusion_matrix, classification_report
import glob
import time, os
workdir = os.path.dirname(os.path.dirname(__file__))
class DataLoader(object):
def get_files(self,fpath):
return [os.path.join(fpath,x) for x in os.listdir(fpath)]
def get_data_labels(self, fpath1):
#paths = glob.glob(fpath + os.sep + "*")
#print(fpath,paths,os.sep)
X = []
y = []
for fpath in fpath1:
print(fpath)
if os.path.isdir(fpath):
fs = self.get_files(fpath)
else:
fs = fpath
X.append(self.img2vec(fs))
print(fpath)
label = np.repeat(1, 1)
y.append(label)
labels = y[0]
for i in range(len(y) - 1):
labels = np.append(labels, y[i + 1])
return np.array(X), labels
def img2vec(self, fn):
"""将jpg等格式的图片转为向量"""
im = Image.open(fn).convert('L')
im = im.resize((28, 28))
tmp = np.array(im)
vec = tmp.ravel()
return vec
class Trainer(object):
'''训练器;'''
def svc(self, x_train, y_train):
'''构建分类器'''
model = SVC(kernel = 'poly',degree = 4,probability= True)
model.fit(x_train, y_train)
return model
class Tester(object):
'''测试器;'''
def __init__(self, model_path):
trainer = Trainer()
self.clf =joblib.load(model_path)
def clf_metrics(self,X_test,y_test):
"""评估分类器效果"""
pred = self.clf.predict(X_test)
cnf_matrix = confusion_matrix(y_test, pred)
score = self.clf.score(X_test, y_test)
clf_repo = classification_report(y_test, pred)
return cnf_matrix, score, clf_repo
def main(path):
loader = DataLoader()
trainer = Trainer()
#X, y = loader.get_data_labels()
#clf = trainer.svc(X, y)
# joblib.dump(clf, "mnist_svm.m")
X_test, y_test = loader.get_data_labels([os.path.join(workdir,"train",'2.jpg')])
tester = Tester("mnist_svm.m")
mt, score, repo = tester.clf_metrics(X_test, y_test)
print(mt,score)
return mt
# encoding:utf-8
import requests
import base64
def main(path):
request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/handwriting"
# 二进制方式打开图片文件
f = open(path, 'rb')
img = base64.b64encode(f.read())
params = {"image": img}
request_url = request_url + "?access_token=" + access_token
headers = {'content-type': 'application/x-www-form-urlencoded'}
response = requests.post(request_url, data=params, headers=headers)
result = "未识别出来"
if response:
results = response.json()['words_result']
result = ''
for i in results:
result += i['words']
return result
5、项目获取
(绿色聊天软件)yuanmazhiwu 或 biyesheji0005

🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看我的【用户名】、【专栏名称】、【顶部选题链接】就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看👇🏻获取联系方式👇🏻

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 19
19 0
0- 0



 已为社区贡献31条内容
已为社区贡献31条内容

所有评论(0)