【论文分享-扩散模型】MICCAI 2025 基于扩散引导扩散模型的成对图像生成
文章提出了一种无需外部条件、可同时生成图像及其标注的成对生成方法,从而提升DBT病灶生成质量并缓解标注数据不足,进而提高后续分割性能。

论文标题:Paired Image Generation with Diffusion-Guided Diffusion Models
发表期刊:The Medical Image Computing and Computer Assisted Intervention
论文链接:https://papers.miccai.org/miccai-2025/paper/4386_paper.pdf
关键词:配对图像生成、扩散引导型扩散模型、数字乳腺断层合成(DBT)肿块分割
Abstract
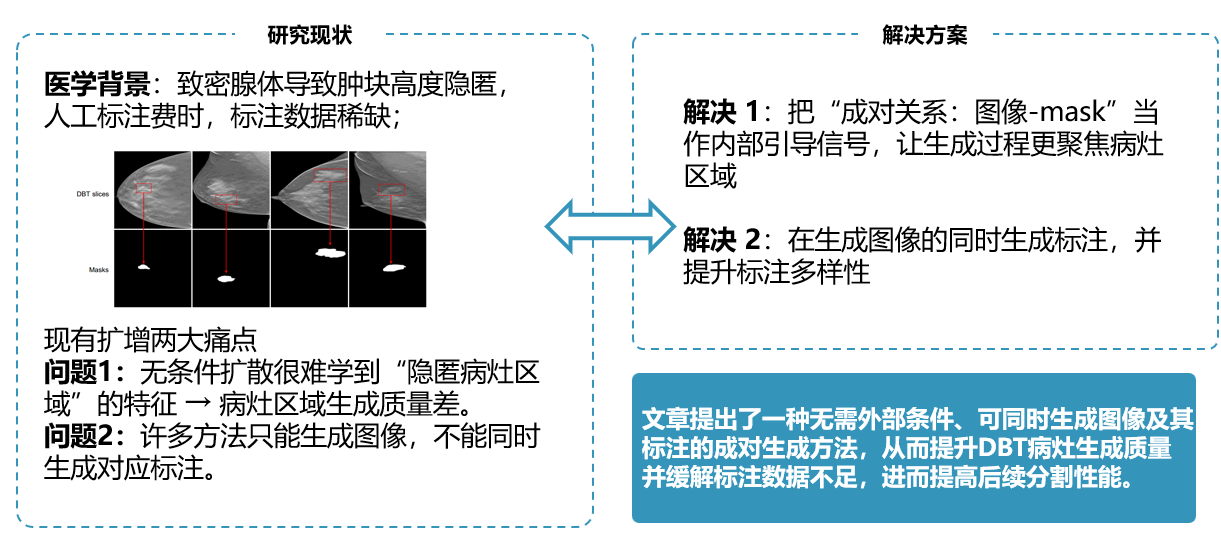
乳腺断层合成摄影(DBT)图像中肿块病灶的分割对于乳腺癌的早期筛查具有重要意义。
然而,乳腺组织的高密度往往导致肿块病灶的高隐蔽性,这使得人工标注困难且耗时。因此,缺乏用于模型训练的标注数据。
扩散模型通常用于数据增强。但现有方法面临两个挑战:
一是由于病变的高度隐蔽性,模型难以学习病变区域的特征,导致病变区域的生成质量较低,从而限制了生成图像的质量;
二是现有方法只能生成图像,不能生成相应的标注,这限制了生成图像在监督训练中的可用性。
在这项工作中,我们提出了一种成对图像生成方法。该方法不需要外部条件,并且可以通过为条件扩散模型训练额外的扩散引导器来实现成对图像的生成。
在实验阶段,实验结果表明,该方法能够在不依赖外部条件的情况下提高生成质量,并有助于缓解标注数据不足的问题,从而提高后续任务的性能.
一、方法
理论基础
- 扩散模型基础:前向加噪(Forward)
对干净样本 x 0 x_0 x0,定义逐步加噪的马尔可夫过程:
q ( x 1 : T ∣ x 0 ) = ∏ t = 1 T q ( x t ∣ x t − 1 ) , q ( x t ∣ x t − 1 ) = N ( x t ; 1 − β t x t − 1 , β t I ) q(x_{1:T}\mid x_0)=\prod_{t=1}^T q(x_t\mid x_{t-1}), \quad q(x_t\mid x_{t-1})=\mathcal N\!\left(x_t;\sqrt{1-\beta_t}\,x_{t-1},\beta_t I\right) q(x1:T∣x0)=t=1∏Tq(xt∣xt−1),q(xt∣xt−1)=N(xt;1−βtxt−1,βtI)
并有闭式形式(可直接从 x 0 x_0 x0 得到任意步的 x t x_t xt):
x t = α ˉ t x 0 + 1 − α ˉ t ϵ , ϵ ∼ N ( 0 , I ) , α ˉ t = ∏ i = 1 t ( 1 − β i ) x_t=\sqrt{\bar\alpha_t}\,x_0+\sqrt{1-\bar\alpha_t}\,\epsilon, \quad \epsilon\sim\mathcal N(0,I), \quad \bar\alpha_t=\prod_{i=1}^t(1-\beta_i) xt=αˉtx0+1−αˉtϵ,ϵ∼N(0,I),αˉt=i=1∏t(1−βi)
-
成对数据:双扩散前向过程(Paired Forward)
PIG 把训练样本看作一对 ( x 0 , y 0 ) (x_0,y_0) (x0,y0)(例如 mask 与 DBT slice),分别加噪:
q ( x 1 : T , y 1 : T ∣ x 0 , y 0 ) = ∏ t = 1 T q x ( x t ∣ x t − 1 ) q y ( y t ∣ y t − 1 ) q(x_{1:T},y_{1:T}\mid x_0,y_0)=\prod_{t=1}^T q_x(x_t\mid x_{t-1})\,q_y(y_t\mid y_{t-1}) q(x1:T,y1:T∣x0,y0)=t=1∏Tqx(xt∣xt−1)qy(yt∣yt−1)
x t = α ˉ t x 0 + 1 − α ˉ t ϵ 1 , y t = α ˉ t y 0 + 1 − α ˉ t ϵ 2 , ϵ 1 , ϵ 2 ∼ N ( 0 , I ) x_t=\sqrt{\bar\alpha_t}x_0+\sqrt{1-\bar\alpha_t}\epsilon_1,\quad y_t=\sqrt{\bar\alpha_t}y_0+\sqrt{1-\bar\alpha_t}\epsilon_2, \quad \epsilon_1,\epsilon_2\sim\mathcal N(0,I) xt=αˉtx0+1−αˉtϵ1,yt=αˉty0+1−αˉtϵ2,ϵ1,ϵ2∼N(0,I) -
联合反向去噪(Joint Reverse)
生成时从高斯噪声开始:
P ( x T ) = N ( 0 , I ) , P ( y T ) = N ( 0 , I ) P(x_T)=\mathcal N(0,I),\quad P(y_T)=\mathcal N(0,I) P(xT)=N(0,I),P(yT)=N(0,I)
并学习联合一步去噪:
p θ ( x 0 : T , y 0 : T ) = P ( x T ) P ( y T ) ∏ t = 1 T p θ ( x t − 1 , y t − 1 ∣ x t , y t ) p_\theta(x_{0:T},y_{0:T})=P(x_T)P(y_T)\prod_{t=1}^T p_\theta(x_{t-1},y_{t-1}\mid x_t,y_t) pθ(x0:T,y0:T)=P(xT)P(yT)t=1∏Tpθ(xt−1,yt−1∣xt,yt) -
关键理论点:联合去噪可分解(Proposition 1)
论文证明联合一步转移可以用两个条件去噪串行实现:
p θ ( x t − 1 , y t − 1 ∣ x t , y t ) = p x ( x t − 1 ∣ x t , y t ) ⋅ p y ( y t − 1 ∣ x t − 1 , y t ) p_\theta(x_{t-1},y_{t-1}\mid x_t,y_t) = p_x(x_{t-1}\mid x_t,y_t)\cdot p_y(y_{t-1}\mid x_{t-1},y_t) pθ(xt−1,yt−1∣xt,yt)=px(xt−1∣xt,yt)⋅py(yt−1∣xt−1,yt)
直观流程:先用 ( x t , y t ) (x_t,y_t) (xt,yt) 更新 x t − 1 x_{t-1} xt−1,再用 ( x t − 1 , y t ) (x_{t-1},y_t) (xt−1,yt) 更新 y t − 1 y_{t-1} yt−1。
- 实现要点:噪声预测 + 互引导
训练时让网络预测噪声(MSE):
ϵ x = m o d e l x ( x t , y t , t ) , L x = ∥ ϵ 1 − ϵ x ∥ 2 2 \epsilon_x=model_x(x_t,y_t,t),\quad \mathcal L_x=\|\epsilon_1-\epsilon_x\|_2^2 ϵx=modelx(xt,yt,t),Lx=∥ϵ1−ϵx∥22
采样时每步先得到更干净的 (\hat x_0),再用它作为条件引导生成 (y)(论文强调用 (\hat x_0) 比用带噪 (x_t) 更“干净”)。
网络架构
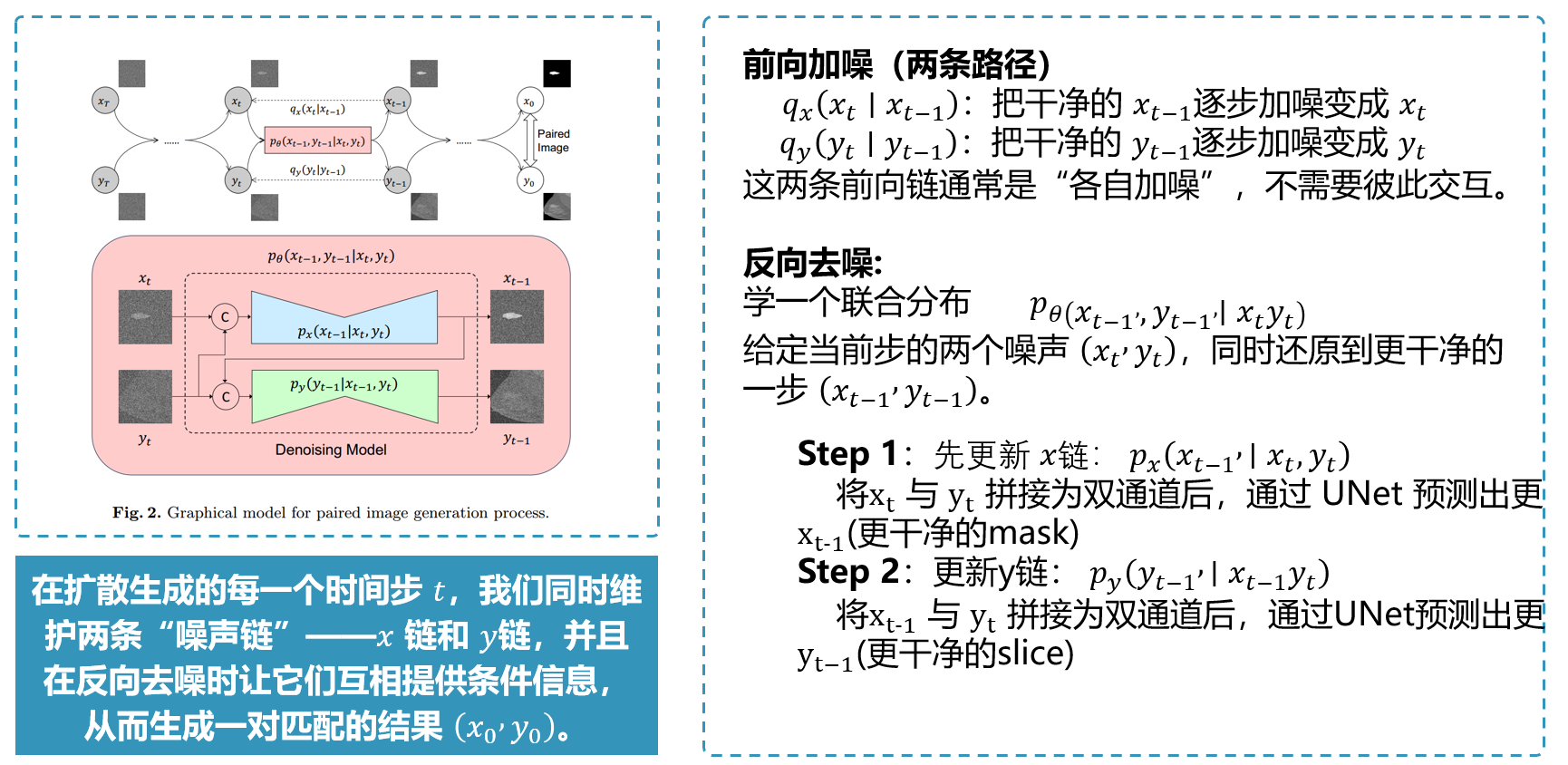
1) 两条并行状态: x t x_t xt 与 y t y_t yt
PIG 同时维护两条扩散链的“当前状态”:
- x t x_t xt:第 t t t 步的 x x x(例如 lesion mask)的加噪版本
- y t y_t yt:第 t t t 步的 y y y(例如 DBT slice)的加噪版本
初始化(采样开始):
x T ∼ N ( 0 , I ) , y T ∼ N ( 0 , I ) x_T \sim \mathcal N(0,I),\qquad y_T \sim \mathcal N(0,I) xT∼N(0,I),yT∼N(0,I)
每一步的目标是把 ( x t , y t ) (x_t,y_t) (xt,yt) 更新到更干净的 ( x t − 1 , y t − 1 ) (x_{t-1},y_{t-1}) (xt−1,yt−1)。
2) 一步反向更新的“串行数据流”
核心思想:先更新 x x x,再用更新后的 x x x 去引导更新 y y y。
论文的联合转移核可以写成(联合去噪):
p θ ( x t − 1 , y t − 1 ∣ x t , y t ) p_\theta(x_{t-1},y_{t-1}\mid x_t,y_t) pθ(xt−1,yt−1∣xt,yt)
并分解为两个串行的条件去噪过程:
p θ ( x t − 1 , y t − 1 ∣ x t , y t ) = p x ( x t − 1 ∣ x t , y t ) ⋅ p y ( y t − 1 ∣ x t − 1 , y t ) p_\theta(x_{t-1},y_{t-1}\mid x_t,y_t)= p_x(x_{t-1}\mid x_t,y_t)\cdot p_y(y_{t-1}\mid x_{t-1},y_t) pθ(xt−1,yt−1∣xt,yt)=px(xt−1∣xt,yt)⋅py(yt−1∣xt−1,yt)
这对应到数据流就是:
( x t , y t ) → x t − 1 → y t − 1 (x_t,y_t)\ \rightarrow\ x_{t-1}\ \rightarrow\ y_{t-1} (xt,yt) → xt−1 → yt−1。
3) 模块 A: y t y_t yt 引导 x t x_t xt 去噪(model_x)
输入流: ( x t , y t , t ) (x_t,\ y_t,\ t) (xt, yt, t)
输出流:预测噪声 ϵ x \epsilon_x ϵx,进而得到 x ^ 0 \hat x_0 x^0、 x t − 1 x_{t-1} xt−1
3.1 噪声预测
ϵ x = model x ( x t , y t , t ) \epsilon_x = \text{model}_x(x_t,y_t,t) ϵx=modelx(xt,yt,t)
3.2 由噪声预测恢复“干净估计” x ^ 0 \hat x_0 x^0
x ^ 0 = x t − 1 − α ˉ t ϵ x α ˉ t \hat x_0=\frac{x_t-\sqrt{1-\bar\alpha_t}\,\epsilon_x}{\sqrt{\bar\alpha_t}} x^0=αˉtxt−1−αˉtϵx
3.3 更新到下一步 x t − 1 x_{t-1} xt−1
(论文采样设置 σ t = 0 \sigma_t=0 σt=0,可写为)
x t − 1 = α ˉ t − 1 x ^ 0 + 1 − α ˉ t − 1 ϵ x x_{t-1}=\sqrt{\bar\alpha_{t-1}}\hat x_0+\sqrt{1-\bar\alpha_{t-1}}\,\epsilon_x xt−1=αˉt−1x^0+1−αˉt−1ϵx
数据流总结(模块 A):
x t , y t , t → ϵ x → x ^ 0 → x t − 1 x_t,y_t,t \rightarrow \epsilon_x \rightarrow \hat x_0 \rightarrow x_{t-1} xt,yt,t→ϵx→x^0→xt−1
4) 模块 B:用更干净的 x ^ 0 \hat x_0 x^0 引导 y t y_t yt 去噪(model_y)
关键点:条件不直接用带噪的 x t x_t xt,而用更“干净”的 x ^ 0 \hat x_0 x^0。
输入流: ( x ^ 0 , y t , t ) (\hat x_0,\ y_t,\ t) (x^0, yt, t)
输出流:预测噪声 ϵ y \epsilon_y ϵy,进而得到 y ^ 0 \hat y_0 y^0、 y t − 1 y_{t-1} yt−1
4.1 噪声预测
ϵ y = model y ( x ^ 0 , y t , t ) \epsilon_y = \text{model}_y(\hat x_0,y_t,t) ϵy=modely(x^0,yt,t)
4.2 恢复“干净估计” y ^ 0 \hat y_0 y^0
y ^ 0 = y t − 1 − α ˉ t ϵ y α ˉ t \hat y_0=\frac{y_t-\sqrt{1-\bar\alpha_t}\,\epsilon_y}{\sqrt{\bar\alpha_t}} y^0=αˉtyt−1−αˉtϵy
4.3 更新到下一步 y t − 1 y_{t-1} yt−1
y t − 1 = α ˉ t − 1 y ^ 0 + 1 − α ˉ t − 1 ϵ y y_{t-1}=\sqrt{\bar\alpha_{t-1}}\hat y_0+\sqrt{1-\bar\alpha_{t-1}}\,\epsilon_y yt−1=αˉt−1y^0+1−αˉt−1ϵy
数据流总结(模块 B):
x ^ 0 , y t , t → ϵ y → y ^ 0 → y t − 1 \hat x_0,y_t,t \rightarrow \epsilon_y \rightarrow \hat y_0 \rightarrow y_{t-1} x^0,yt,t→ϵy→y^0→yt−1
5) 把一步合起来:完整的 per-step 数据流
在每个时间步 t t t,网络按如下顺序执行:
- 先更新 x x x(得到更干净的结构/标注)
( x t , y t , t ) → model x ϵ x → x ^ 0 → x t − 1 (x_t,y_t,t) \xrightarrow{\text{model}_x} \epsilon_x \rightarrow \hat x_0 \rightarrow x_{t-1} (xt,yt,t)modelxϵx→x^0→xt−1 - 再更新 y y y(用 x ^ 0 \hat x_0 x^0 作为条件引导细节生成)
( x ^ 0 , y t , t ) → model y ϵ y → y ^ 0 → y t − 1 (\hat x_0,y_t,t) \xrightarrow{\text{model}_y} \epsilon_y \rightarrow \hat y_0 \rightarrow y_{t-1} (x^0,yt,t)modelyϵy→y^0→yt−1
循环 t = T , T − 1 , … , 1 t=T,T-1,\dots,1 t=T,T−1,…,1,最终输出成对结果:
( x ^ 0 , y ^ 0 ) (\hat x_0,\hat y_0) (x^0,y^0)
6) 符号说明(最小必要集)
- x 0 , y 0 x_0,y_0 x0,y0:干净的成对样本(如 mask 与 slice)
- x t , y t x_t,y_t xt,yt:第 t t t 步加噪状态
- T T T:扩散总步数
- β t \beta_t βt:噪声日程
- α ˉ t = ∏ i = 1 t ( 1 − β i ) \bar\alpha_t=\prod_{i=1}^t(1-\beta_i) αˉt=∏i=1t(1−βi):累计系数
- ϵ x , ϵ y \epsilon_x,\epsilon_y ϵx,ϵy:网络预测的噪声
- x ^ 0 , y ^ 0 \hat x_0,\hat y_0 x^0,y^0:对干净样本的估计
- model x , model y \text{model}_x,\text{model}_y modelx,modely:两个去噪网络( y y y 引导 x x x; x ^ 0 \hat x_0 x^0 引导 y y y)
二、实验
1) 实验目标
- 进行成对生成实验:把肿块 mask 作为 x 0 x_0 x0、DBT 切片作为 y 0 y_0 y0,生成成对样本 ( x ^ 0 , y ^ 0 ) (\hat x_0,\hat y_0) (x^0,y^0)。:contentReference[oaicite:1]{index=1}
- 将生成的成对数据加入到下游 DBT 肿块分割监督训练中,验证其有效性。:contentReference[oaicite:2]{index=2}
2) 数据集与预处理
- 使用私有数据集 DBTMassSeg:367 名患者,包含 CC/MLO 视角及对应肿块 mask;共有 8,723 张含肿块切片;由两位有经验的放射科医生手工标注。
- 预处理:裁掉空白区域并 resize 到 512 × 512 512\times512 512×512。
3) 扩散模型实现设置(生成模型侧)
- 归一化:线性缩放到 [ − 1 , 1 ] [-1,1] [−1,1];噪声日程 β t \beta_t βt 线性从 10 − 4 10^{-4} 10−4 增到 0.02 0.02 0.02;最大步数 T = 1024 T=1024 T=1024。
- 网络:两条扩散模型均用 U-Net;输入通道数为 2;“引导信号”通过 channel 维拼接引入。
- 采样:采用 DDIM 的 uniform-step 采样策略,采样步数设为 256。
4) 对比实验 A:与无条件扩散模型的生成质量对比(FID)
- 基线:DDPM、DDIM(无条件生成)。每种方法各生成 2048 张 DBT 切片;采样步数:DDPM=1024,DDIM=256;指标:FID。
- 结果(Table 1):PIG 的 FID 明显更低(更好):

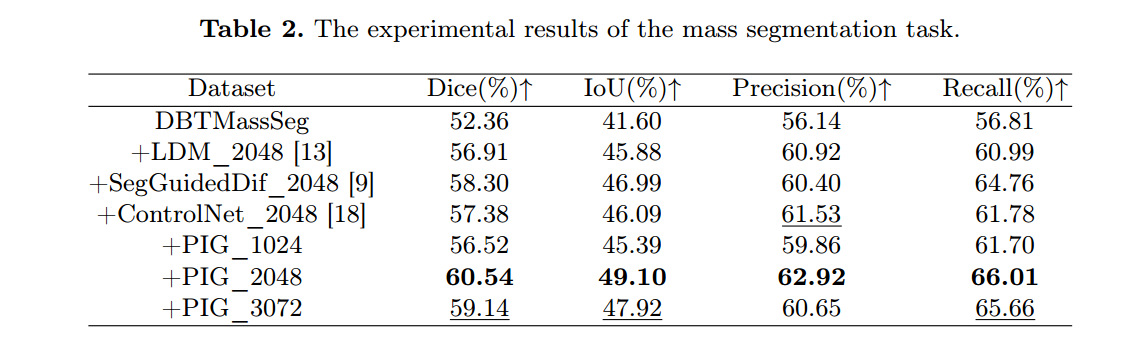
5) 对比实验 B:与条件扩散方法对比(看“下游分割收益”)
- 思路:条件扩散可用“已有 mask 作为条件”生成图像,因此作者用“把生成数据加入分割训练后效果如何”来间接比较生成数据的价值。
6) 定性实验:逐步生成过程可视化
- 作者展示了 PIG 的逐步生成:早期先形成病灶形状(mask 更快“定形”),后期再细化切片整体纹理,用来说明“引导”让模型更关注病灶区域。
三、总结


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 19
19 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)