scrapy 爬取知名博客
本文介绍了使用Scrapy框架爬取博客园新闻数据的完整流程,主要包括: 环境配置:创建虚拟环境并安装Scrapy及相关依赖库,初始化项目并生成爬虫模板。 开发调试:通过创建main.py文件实现Pycharm调试功能,介绍了路径处理的关键方法。 数据提取:详细讲解了XPath和CSS选择器的语法与使用方法,强调编写简洁路径的重要性。 模拟登录:使用undetected_chromedriver实现
1.scrapy安装和配置
第一步配置虚拟环境
#创建虚拟环境
mkvirtualenv -p python.exe路径 article_spider
#在虚拟环境内安装scrapy,记得换源,
pip install lxml
pip install Twisted
pip install pywin32
pip install scrapy
创建项目
scrapy startproject ArticleSpider
进入项目
cd ArticleSpider
创建爬虫
scrapy genspider cnblogs news.cnblogs.com #这里为了兼容后面的项目所以为jobbole,否则为cnblogs
jobbole.py文件的内容
import scrapy
class JobboleSpider(scrapy.Spider):
name ='jobbole'
allowed_domains = ['news.cnblogs.com']
start_urls = ['http://news.cnblogs.com/']
def parse(self,response):
pass
2.需求分析
博客圆新闻数据:
深度优先和广度优先?
3.pycharm中调试scrapy源码
在ArticleSpider目录下创建main.py文件
from scrapy.cmdline import execute
import sys
import os
#print(__file__) #__file__可以告诉系统文件的路径是什么
#os.path.dirname()#是 Python 中用于提取文件路径目录部分的核心函数。它通过移除路径中最后一个斜杠(/ 或 \)及其之后的内容,返回父目录路径。
#os.path.abspath(__file__)#是Python中用于获取当前执行脚本的绝对路径
#sys.path是一个列表(list),包含了Python解释器在导入模块时搜索的目录路径。
# 默认情况下,它包括Python安装路径、标准库路径等。
# 使用sys.path.append()可以将用户自定义路径添加到这个列表的末尾,
# 扩展模块搜索范围。
#sys.path.append()
#避免项目在不同系统中因为文件路径不同而报错
sys.path.append(os.path.dirname(os.abspath(__file__)))
execute(["scrapy","crawl","jobbole"])

4.xpath基础语法



5.xpath提取元素
文件的内容
为什么要写尽量简洁的xpath路径,因为HTML页面经常发生变化,不简洁下次就可能获取不到数据
import scrapy
class CnblogsSpider(scrapy.Spider):
name = "cnblogs"
allowed_domains = ["www.cnblogs.com"]
start_urls = ["https://www.cnblogs.com"]
def parse(self, response):
#xpath的路径有很多种比如:
#/html/body/div[1]/div[3]/div/div[2]/div[1]/div[4]/article[19]/section/div/a
#//*[@id="post_list"]/article[]/section/div/a
#为什么要写尽量简洁的xpath路径,因为HTML页面经常发生变化
url_list = response.xpath('//div[@id="main_flow"]//div[@class="post-item-text"]/a/@href').extract()
for url in url_list:
print(url)
#print(response.text)
pass
利用xpath函数提取元素
由于response.xpath()提取出来的是一个selectorlist对象,可以利用extract()[0]提取数据,但是这样有一个问题,如果没有数据会报错。正常的想法是判断selectorlist是否为空然后选择是否抽取。但是可以换一个方法,可以用extract_first()抽取第一个元素
url=response.xpath(“”).extract_first(“”)
当xpath路径相同时,extract()可以把所有的满足条件的元素都提取出来成为一个列表
url =response.xpath(“”).extract()
6.css选择器



spider文件的内容
import scrapy
class CnblogsSpider(scrapy.Spider):
name = "cnblogs"
allowed_domains = ["www.cnblogs.com"]
start_urls = ["https://www.cnblogs.com"]
def parse(self, response):
#xpath的路径有很多种比如:
#/html/body/div[1]/div[3]/div/div[2]/div[1]/div[4]/article[19]/section/div/a
#//*[@id="post_list"]/article[]/section/div/a
#为什么要写尽量简洁的xpath路径,因为HTML页面经常发生变化
#url_list = response.xpath('//div[@id="main_flow"]//div[@class="post-item-text"]/a/@href').extract()
url_list = response.css('div#main_flow div.post-item-text>a::attr(href)').extract()
for url in url_list:
print(url)
#print(response.text)
pass
- 当文件没有导入scrapy的时候如何使用css选择器呢?
from scrapy import Selector
sel = Selector(text=response.text)
url = sel.css(" ")
7. .cnbligs模拟登录(新增内容)
在虚拟环境安装selenium和undetected_chromedriver
pip install selenium
pip install undetected_chromedriver
spider文件的内容
custom_settings可以覆盖掉settings里的设置,只改变本爬虫的配置,不修改其他爬虫
import scrapy
import undetected_chromedriver
class CnblogsSpider(scrapy.Spider):
name = "cnblogs"
allowed_domains = ["www.cnblogs.com"]
start_urls = ["https://www.cnblogs.com"]
custom_settings = {
"COOKIES_ENABLED": True
}
def start_requests(self):
# 模拟登录入口
import undetected_chromedriver as uc
browser = uc.Chrome()
browser.get("https://account.cnblogs.com/signin?returnUrl=https:%2F%2Fwww.cnblogs.com%2F")
input("回车继续:")
cookies = browser.get_cookies()
cookies_dict = {}
for cookie in cookies:
cookies_dict[cookie['name']] = cookie['value']
for url in self.start_urls:
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36 Edg/135.0.0.0'
}
yield scrapy.Request(url, cookies=cookies_dict, dont_filter=True)
def parse(self, response):
#xpath的路径有很多种比如:
#/html/body/div[1]/div[3]/div/div[2]/div[1]/div[4]/article[19]/section/div/a
#//*[@id="post_list"]/article[]/section/div/a
#为什么要写尽量简洁的xpath路径,因为HTML页面经常发生变化
#url_list = response.xpath('//div[@id="main_flow"]//div[@class="post-item-text"]/a/@href').extract()
url_list = response.css('div#main_flow div.post-item-text>a::attr(href)').extract()
for url in url_list:
print(url)
print(response.text)
pass
8.编写spider完成爬取过程-1
获取新闻列表页中的新闻url并交给scrapy进行下载后调用相应的解析方法
在spider的parse函数中添加爬取过程,parse函数修改为
def parse(self, response):
'''
1.获取新闻列表页中的新闻url并交给scrapy进行下载后调用相应的解析方法
2.获取下一页的url并交给scrapy进行下载,下载完成后交给parse继续跟进
:param response:
:return:
'''
post_nodes = response.css('div#main_flow div.post-item-text')
for post_node in post_nodes:
post_url = post_node.css('a::attr(href)').extract_first("")
image_url = post_node.css('img::attr(src)').extract_first("")
#yield Request(url=post_url)这样做有巨大隐患
#因为post_url提取出来可能只是url的片段例如:
#详情页的路径为https://www.cnblogs.com/ChenAI-TGF/p/19430267
#而这里提取的为:ChenAI-TGF/p/19430267
#那么调用yield Request(url=post_url)缺域名。
#正常的思路是:url="{}{}".format("https://www.cnblogs.com/",post_url)
#但是post_url也可能是完整的,所以不能这样写,这样就可能重复了
#meta 是为了将image_url传递给parse_detail函数
#callback是该请求给的函数,这里的函数不能跟()因为跟了括号,那么就是
#callback=一个返回值,而不是将请求传递给该函数
#dont_filter是过滤,如果为True,就是不要过滤 meta={"front_image_url": image_url}meta={"front_image_url": image_url}
yield scrapy.Request(url=parse.urljoin(response.url, post_url), meta={"front_image_url":image_url},
callback=self.parse_detail)
def parse_detail(self, response):
print(response.meta['front_image_url'])
print(response.url)
print(response.status)
print("****" * 20)
pass
- yield Request(url=post_url)这样做有巨大隐患,因为post_url提取出来可能只是url的片段例如:
- 详情页的路径为https://www.cnblogs.com/ChenAI-TGF/p/19430267
- 而这里提取的为:ChenAI-TGF/p/19430267
- 那么调用yield Request(url=post_url)缺域名。
- 正常的思路是:url=“{}{}”.format(“https://www.cnblogs.com/”,post_url)
但是post_url也可能是完整的,所以不能这样写,这样就可能重复了
meta 是为了将image_url传递给parse_detail函数 - callback是该请求给的函数,这里的函数不能跟()因为跟了括号,那么就是callback=一个返回值,而不是将请求传递给该函数
- dont_filter是过滤,如果为True,就是不要过滤
- scrapy抓取策略是深度优先策略
9.编写spider完成爬取过程-2
获取下一页的url并交给scrapy进行下载,下载完成后交给parse继续跟进
提取下一页并交给scrapy进行下载
两种思路:>
第一种:下页的时候,url也会跟着变化,可以通过url来改变页数
第二种:在最后面有一个页数显示,可以通过获取下一页的链接,然后跳转到下一页
#提取下一页并交给scrapy进行下载
#两种思路:>
#第一种:下页的时候,url也会跟着变化,可以通过url来改变页数
#第二种:在最后面有一个页数显示,可以通过获取下一页的链接,然后跳转到下一页
def parse(self, response):
next_text = response.css('#pager_bottom div.pager a:last-child::text').extract_first("")
if next_text == ">":
next_url = response.css('#pager_bottom div.pager a:last-child::attr(href)').extract_first("")
print(next_url)
yield scrapy.Request(url=parse.urljoin(response.url, next_url))
- start_urls默认回掉函数调用parse函数
- scrapy是异步的框架,在调用parse函数时,将请求抛出,然后会继续执行parse直到结束
- 而抛出的请求会执行callback对应的方法
10.scrapy中为什么要使用yield
scrapy是异步io,没有多线程,没有引入消息队列
yield是可以停止的函数
列如:
def myGen():
yield 1
yield 2
yield 3
return 4
def myfun():
return 4
print(myGen())#输出的是一个对象
print(myfun())#输出的是4
#输出myGen()
for data in myGen():
print(data)#4 1 2 3
mygen=myGen()
print(next(mygen()) #1
print(next(mygen()) #2
print(next(mygen()) #3
11.提取详情页信息-1
javaScript动态渲染页面抓取
问题:
在抓取评论数,观看数的时候,直接抓取会发现,数据为空,检查原始页面,发现在HTML中,没有这些数据,这些数据是经过JavaScript渲染形成的不能直接抓取
解决方法:
可以直接使用requests()函数在分析的方法中直接请求这个页面的数据接口,然后爬取
但这样存在一个问题
scrapy是异步的,直接使用request会阻塞,
#####解决方法
所以应该继续使用:
yield scrapy.Request(
url=parse.urljoin(response.url, "/NewsAjax/GetAjaxNewsInfo?contentId={}".format(post_id)),
meta={"article_item": item_loader, "url": response.url},
callback=self.parse_nums
)
使用同步requests同步加载:spider.py中parse_detail函数代码
import requests
import re
import json
def parse_detail(self,response):
title = response.css("#news_title a::text").extract_first("")
create_data = response.xpath('//*[@id="news_info"]/span[@class="time"]/text()').extract_first("")
content = response.css("#news_content").extract()[0]
# content = response.xpath('//*[@id="news_content"]').extract()[0]
tag_list = response.css(".news_tags a::text").extract()
# tag_list = response.xpath('//*[@class="news_tags"]//a/text()').extract()
tags = ",".join(tag_list)
#获取网站的post_id
match_re = re.match(".*?(\d+),response.url)
if match_re:
create_date = match_re.group(1)
#获取接口的数据
html =requests.get(parse.urljion(response.url,"/NewsAjas/GetjaxNewsInfo?contentId={}".format(post_id)))
#加载接口数据
j_data = json.loads(html.text)
- 这样写有一个错误,如果post_id 不存在,requests继续执行,会报错,所以应该改写为:
import requests
import re
import json
def parse_detail(self,response):
#获取网站的post_id
match_re = re.match(".*?(\d+)",response.url)
if match_re:
create_date = match_re.group(1)
#获取接口的数据
html =requests.get(parse.urljion(response.url,"/NewsAjas/GetjaxNewsInfo?contentId={}".format(post_id)))
#加载接口数据
j_data = json.loads(html.text)
praise_nums = j_data["DiggCount"] #赞成
fav_nums = j_data["TotalView"] #观看量
comment_nums = j_data["CommentCount"]#评论
title = response.css("#news_title a::text").extract_first("")
create_data = response.xpath('//*[@id="news_info"]/span[@class="time"]/text()').extract_first("")
content = response.css("#news_content").extract()[0]
# content = response.xpath('//*[@id="news_content"]').extract()[0]
tag_list = response.css(".news_tags a::text").extract()
# tag_list = response.xpath('//*[@class="news_tags"]//a/text()').extract()
tags = ",".join(tag_list)
12.提取详情页信息-2
将其改为异步
from ArticleSpider.items import ArticlespiderItem
def parse_detail(self, response):
article_item = ArticlespiderItem()
# 获取网站的post_id
match_re = re.match(".*?(\d+)",response.url)
if match_re:
post_id = match_re.group(1)
#create_data = response.css("#news_info .time::text").extract_first("")
# 获取接口的数据
'''
html = requests.get(parse.urljion(response.url, "/NewsAjas/GetjaxNewsInfo?contentId={}".format(post_id)))
# 加载接口数据
j_data = json.loads(html.text)
praise_nums = j_data["DiggCount"] #赞成
fav_nums = j_data["TotalView"] #观看量
comment_nums = j_data["CommentCount"]#评论
'''
title = response.css("#news_title a::text").extract_first("")
create_data = response.xpath('//*[@id="news_info"]/span[@class="time"]/text()').extract_first("")
match_re = re.match(".*?(\d+.*)", create_data)
if match_re:
create_date = match_re.group(1)
content = response.css("#news_content").extract()[0]
# content = response.xpath('//*[@id="news_content"]').extract()[0]
tag_list = response.css(".news_tags a::text").extract('')
# tag_list = response.xpath('//*[@class="news_tags"]//a/text()').extract()
tags = ",".join(tag_list)
#print(parse.urljoin(response.url, "/NewsAjax/GetAjaxNewsInfo?contentId={}".format(post_id)))
yield scrapy.Request(
url=parse.urljoin(response.url, "/NewsAjax/GetAjaxNewsInfo?contentId={}".format(post_id)),
meta={"article_item": article_item, "url": response.url},
callback=self.parse_nums
)
def parse_nums(self, response):
j_data = json.loads(response.text)
praise_nums = j_data["DiggCount"] # 赞成
fav_nums = j_data["TotalView"] # 观看量
comment_nums = j_data["CommentCount"] # 评论
13.item的定义和使用-1
解决数据传递问题item
item.py代码
class ArticlespiderItem(scrapy.Item):
title = scrapy.Field()
create_date = scrapy.Field()
url = scrapy.Field()
#url_object_id = scrapy.Field()不好做
front_image_url = scrapy.Field()
front_image_path = scrapy.Field()
praise_nums = scrapy.Field()
comment_nums = scrapy.Field()
fav_nums = scrapy.Field()
tags = scrapy.Field()
content = scrapy.Field()
- 打开管道settings.py
14.item的定义和使用-2
- 将所有内容导入item的方法
def parse_detail(self, response):
article_item = ArticlespiderItem()
# 获取网站的post_id
match_re = re.match(".*?(\d+)",response.url)
if match_re:
post_id = match_re.group(1)
title = response.css("#news_title a::text").extract_first("")
create_data = response.xpath('//*[@id="news_info"]/span[@class="time"]/text()').extract_first("")
match_re = re.match(".*?(\d+.*)", create_data)
if match_re:
create_date = match_re.group(1)
content = response.css("#news_content").extract()[0]
# content = response.xpath('//*[@id="news_content"]').extract()[0]
tag_list = response.css(".news_tags a::text").extract('')
# tag_list = response.xpath('//*[@class="news_tags"]//a/text()').extract()
tags = ",".join(tag_list)
article_item["title"] = title
article_item["create_date"] = create_date
article_item["content"] = content
article_item["tags"] = tags
article_item["url"] = response.url
#为什么不使用response.meta['front_image_url']因为如果没有值会报错
if response.meta.get("front_image_url", ""):
article_item["front_image_url"] = [response.meta.get("front_image_url", "")]
else:
article_item["front_image_url"] = []
yield scrapy.Request(
url=parse.urljoin(response.url, "/NewsAjax/GetAjaxNewsInfo?contentId={}".format(post_id)),
meta={"article_item": article_item, "url": response.url},
callback=self.parse_nums
)
def parse_nums(self, response):
j_data = json.loads(response.text)
article_item = response.meta.get("article_item", "")
praise_nums = j_data["DiggCount"] # 赞成
fav_nums = j_data["TotalView"] # 观看量
comment_nums = j_data["CommentCount"] # 评论
article_item["praise_nums"] = praise_nums
article_item["fav_nums"] = fav_nums
article_item["comment_nums"] = comment_nums
yield article_item
15.scrapy 配置图片下载
- 打开图片管道:
ITEM_PUPELINES ={
'scrapy.pipelines.images.ImagesPipeline':1
}
- 创建一个图片文件夹
images - 配置存放图片的目录
import sys
import os
project_dir = os.path.dirname(os.path.abspath(__file__))
FILES_STORE = os.path.join(project_dir,'images')
- 指明要下载哪一个字段
IMAGES_URLS_FIELD = "front_image_url"
- 由于下载图片时,是一个for循环。所以图片的url应该是一个list,所以在spider中应该将url用中括号括起来,由于可能没有图片所以用if
if response.meta.get("front_image_url", ""):
article_item["front_image_url"] = [response.meta.get("front_image_url", "")]
else:
article_item["front_image_url"] = []
为了知道文件的名称和路径,需要重新创建一个pipeline,重载scrapy.pipelines.images.ImagesPipeline
from scrapy.pipelines.images import ImagesPipeline
class ArticleImagePipeline(ImagesPipeline):
def item_completed(self,results,item,info):
if "front_image_url" in item:
for ok, value in results:
image_file_path = value["path"]
item["front_image_path"] = image_file_path
return item
- 所以开启的管道也会发生变化:
ITEM_PUPELINES ={
#'scrapy.pipelines.images.ImagesPipeline':1
#这里的数字设置一定要小,因为要先于其他管道
"ArticleSpider.pipelines.ArticleImagePipeline": 1,
}
16.item数据写入到json文件中
- 在pipeline.py中创建管道:
import codecs
class JsonWithEncodingPipeline(object):
#自定义json文件的导出
def __init__(self):
#a为追加
self.file = codecs.open('article.json', 'w', encoding="utf-8")
#将数据导入
def process_item(self, item, spider):
lines = json.dumps(dict(item), ensure_ascii=False, default=json_serial) + "\n"
self.file.write(lines)
return item
def spider_closed(self, spider):
self.file.close()
- 在settings添加管道
ITEM_PUPELINES ={
#'scrapy.pipelines.images.ImagesPipeline':1
#这里的数字设置一定要小,因为要先于其他管道
"ArticleSpider.pipelines.ArticleImagePipeline": 1,
"ArticleSpider.pipelines.JsonWithEncodingPipeline": 2,
}
利用scrapy已经有的导出
from scrapy.exporters import JsonItemExporter
class JsonExporterPipleline(object):
#调用scrapy提供的json export导出json文件
def __init__(self):
self.file = open('articleexport.json', 'wb')
self.exporter = JsonItemExporter(self.file, encoding="utf-8", ensure_ascii=False)
self.exporter.start_exporting()
def close_spider(self, spider):
self.exporter.finish_exporting()
self.file.close()
def process_item(self, item, spider):
self.exporter.export_item(item)
return item
- 在settings添加管道
ITEM_PUPELINES ={
#'scrapy.pipelines.images.ImagesPipeline':1
#这里的数字设置一定要小,因为要先于其他管道
"ArticleSpider.pipelines.ArticleImagePipeline": 1,
"ArticleSpider.pipelines.JsonWithEncodingPipeline": 2,
"ArticleSpider.pipelines.JsonExporterPipleline": 3,
}
17.MySQL表结构设计
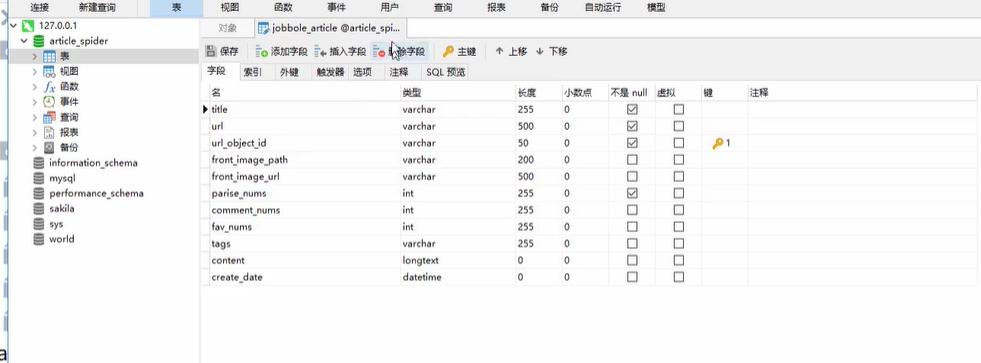
18. pipeline数据库保存
数据进入数据库需要驱动,所以需要安装驱动
pip install mysqlclient
import MySQLdb
import MySQLdb.cursors
class MysqlPipeline(object):
#采用同步的机制写入mysql
def __init__(self):
self.conn = MySQLdb.connect(
'192.168.0.106',
'root',
'root',
'article_spider', #数据库名
charset="utf8",
use_unicode=True
)
self.cursor = self.conn.cursor()
def process_item(self, item, spider):
insert_sql = """
insert into jobbole_article(title, url, create_date, fav_nums)
VALUES (%s, %s, %s, %s)
"""
params = list()
#这里不要使用item["title"],因为item可能没有值,append()会报错
params.append(item.get("title",""))
params.append(item.get("url",""))
params.append(item.get("create_date",""))
params.append(item.get("fav_nums",""))
self.cursor.execute(insert_sql,tuple(params))
#self.cursor.execute(insert_sql, (item["title"], item["url"], item["create_date"], item["fav_nums"]))
#self.cursor.execute(insert_sql, (item.get("title", ""), item["url"], item["create_date"], item["fav_nums"]))
self.conn.commit()
- 记得打开管道
19.异步方式入库mysql
- 在settings.py配置
MYSQL_HOST = "127.0.0.1"
MYSQL_DBNAME = "article_spider"
MYSQL_USER = "root"
MYSQL_PASSWORD = "root"
import MySQLdb
import MySQLdb.cursors
import twisted.enterprise import adbapi
class MysqlTwistedPipline(object):
def __init__(self, dbpool):
self.dbpool = dbpool
@classmethod
def from_settings(cls, settings):
dbparms = dict(
host = settings["MYSQL_HOST"],
db = settings["MYSQL_DBNAME"],
user = settings["MYSQL_USER"],
passwd = settings["MYSQL_PASSWORD"],
charset='utf8',
cursorclass=MySQLdb.cursors.DictCursor,
use_unicode=True,
)
dbpool = adbapi.ConnectionPool("MySQLdb", **dbparms)
return cls(dbpool)
def process_item(self, item, spider):
#使用twisted将mysql插入变成异
#将某个方法放到池里执行
query = self.dbpool.runInteraction(self.do_insert, item)
#处理异常,告诉我item和spider
query.addErrback(self.handle_error, item, spider)
return item
#处理错误
def handle_error(self, failure, item, spider):
#处理异步插入的异常
print (failure)
def do_insert(self, cursor, item):
#执行具体的插入
#根据不同的item 构建不同的sql语句并插入到mysql中
insert_sql = """
insert into jobbole_article(title, url, create_date, fav_nums)
VALUES (%s, %s, %s, %s)
"""
params = list()
#这里不要使用item["title"],因为item可能没有值,append()会报错
params.append(item.get("title",""))
params.append(item.get("url",""))
params.append(item.get("create_date",""))
params.append(item.get("fav_nums",""))
#self.cursor.execute(insert_sql,tuple(params))
#self.cursor.execute(insert_sql, (item["title"], item["url"], item["create_date"], item["fav_nums"]))
#insert_sql, params = item.get_insert_sql()
cursor.execute(insert_sql, params)
- 开启管道
20.数据插入主键冲突的解决方法
MySQL主键冲突问题解决方法详解
主键冲突是指在MySQL中插入或更新数据时违反主键的唯一性约束,导致出现Duplicate entry错误。这会影响数据完整性和系统稳定性。以下基于引用内容,结合专业知识和最佳实践,逐步介绍解决MySQL主键冲突的方法。回答结构清晰,涵盖排查、解决和预防措施,确保真实可靠。
主键冲突的常见原因(排查起点)
在解决冲突前,需先识别原因。主键冲突通常由以下情况引发:
-
重复插入:手动或程序错误插入重复主键值。
-
自增主键溢出:自增ID达到上限
-
批量导入数据:导入文件(如CSV)包含重复主键值。
-
分库分表策略冲突:全局自增ID未正确同步,导致不同分片生成重复ID。
排查时,优先查看MySQL错误日志,定位具体冲突值和SQL语句
解决方法:
冲突时更新现有记录。最推荐的方法,避免删除操作,高效处理"更新或插入"场景
insert_mysql = '''
INSERT INTO table_name (id, column1) VALUES (1001, 'data') ON DUPLICATE KEY UPDATE column1 = VALUES(column1)
'''
21.itemloader提取信息-1
#使用itemloader需要导入该模块
from scrapy.loader import ItemLoader
def parse_detil(self,response):
#这里有了Response,就只写提取规则其他的不用管
#item_loader 其值是list
item_loader = ItemLoader(item=ArticlespiderItem(),response)
#在itemloader中有三种方法非常重要:分别是add_css,add_value,add_xpath
item_loader.add_css("title", "#news_title a::text")
item_loader.add_css("create_date", "#news_info .time::text")
item_loader.add_css("content", "#news_content")
item_loader.add_css("tags", ".news_tags a::text")
item_loader.add_value("url", response.url)
if response.meta.get("front_image_url", []):
item_loader.add_value("front_image_url",response.meta.get("front_image_url", []))
#如何得到item
#article_item = item_loader.load_item()
item,scrapy.Field()的功能
from scrapy.loader.processor import MapCompose,TakeFirst
class ArticlespiderItem(scrapy.Item):
#MapCompose相当于一个管道
title = scrapy.Field(
input_processor = MapCompose(),output_processor = TakeFirst
)
create_date = scrapy.Field()
url = scrapy.Field()
#url_object_id = scrapy.Field()不好做
front_image_url = scrapy.Field()
front_image_path = scrapy.Field()
praise_nums = scrapy.Field()
comment_nums = scrapy.Field()
fav_nums = scrapy.Field()
tags = scrapy.Field()
content = scrapy.Field()
#定义一个方法:
#这里的value就是item传进来的值
def add_aa(value):
return value+"-aa"
def add_test(value):
return value+"-test"
title = scrapy.Field(
input_processor = MapCompose(add_aa,add_test)
)
#输出:"标题-aa-test"
- 为了将list()里的数据取出来调用output_processor = TakeFirst(),输出字符串
title = scrapy.Field(output_processor = TakeFirst())


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 17
17 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)