ebrains的数据批量获取
使用kimi,来帮助我进行ebrains的数据的批量下载和整理。
可以使用学校账户来进行ebrains的注册
现在页面更新了, 有账号之后,可以通过
https://ebrains.eu/data-tools-services/data-knowledge/find-data
这个网址来进行数据的检索和下载。
部分的数据可能需要授权和请求。
以我使用的数据为例。
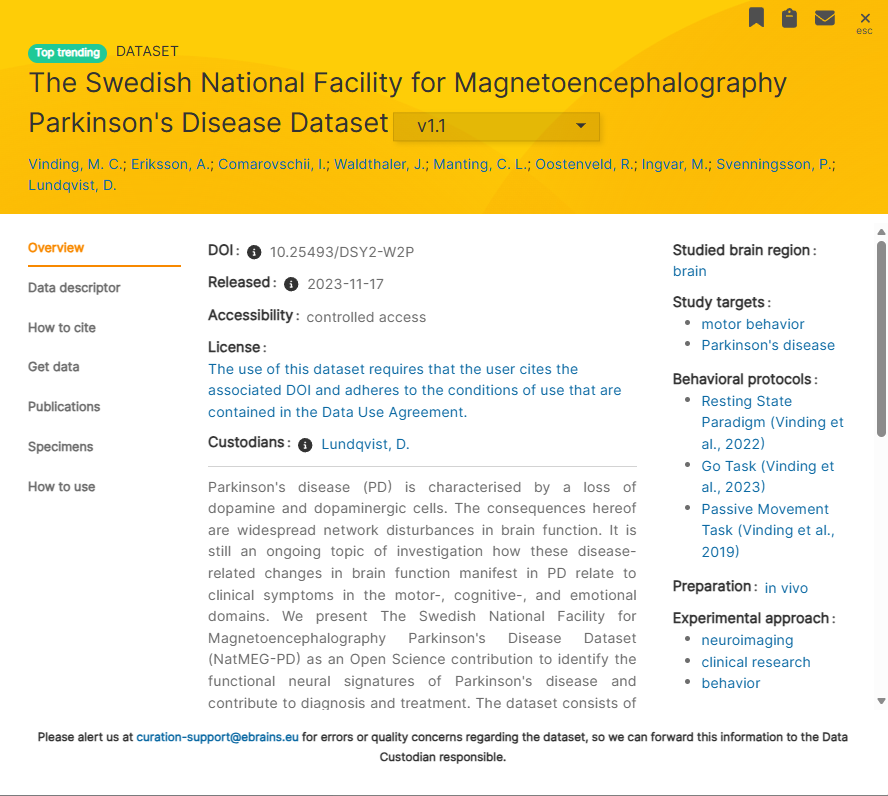
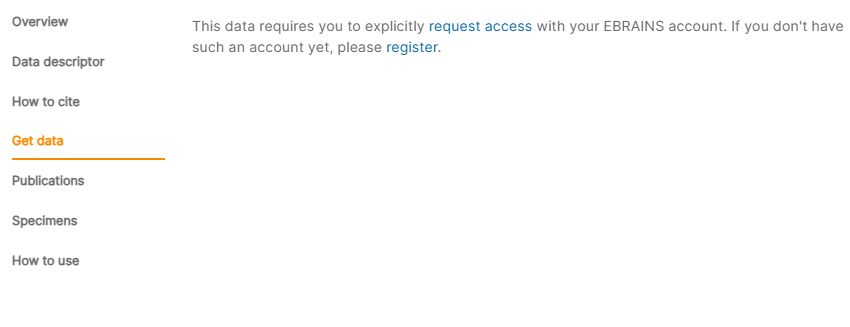
会在邮件中提供一个链接。
在这个页面可以查看文件,并且可以下载。但是无法进行批量下载。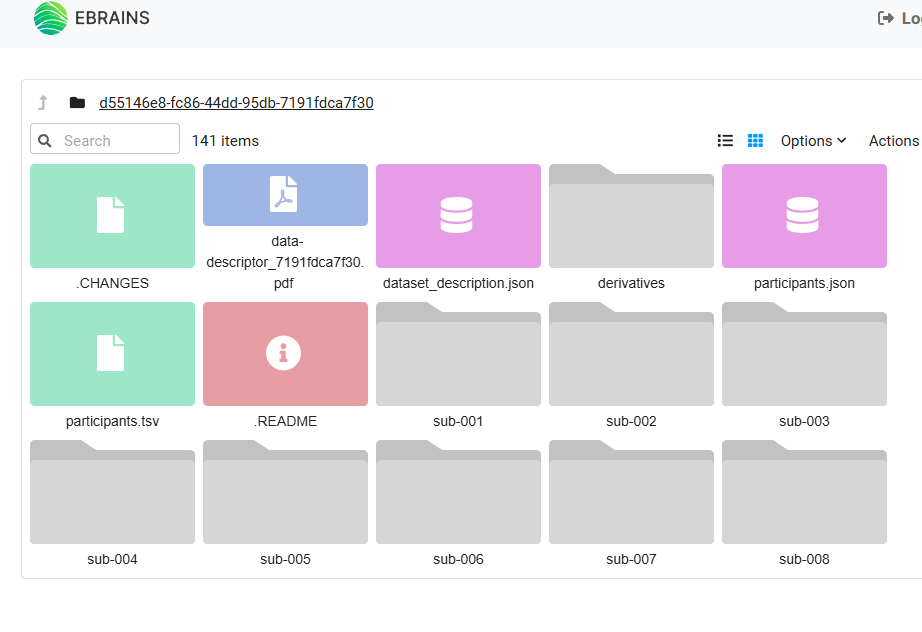
因此,我们尝试通过网页来进行批量下载构造。
我们可以通过F12的浏览器
EBRAINS Data Proxy API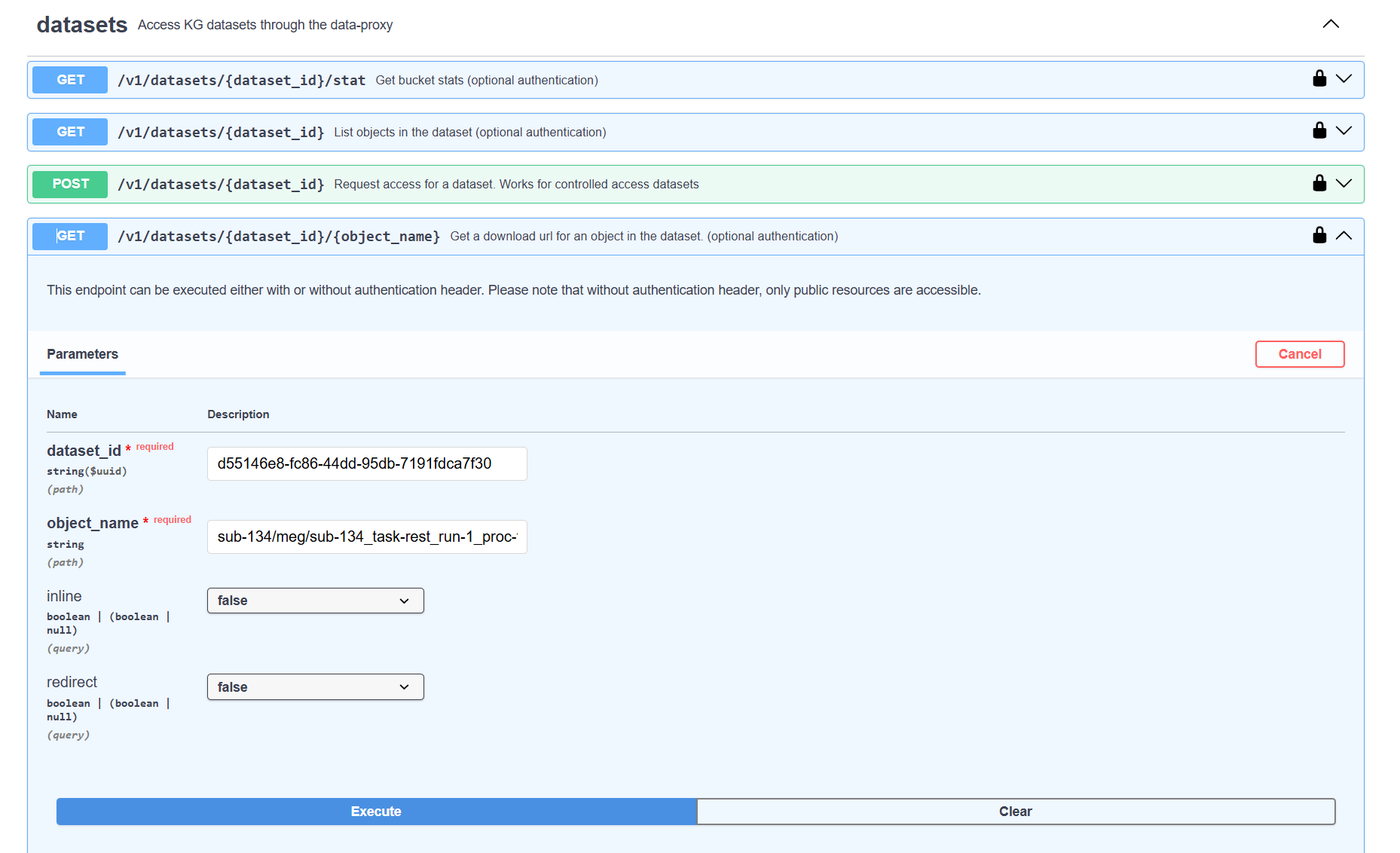
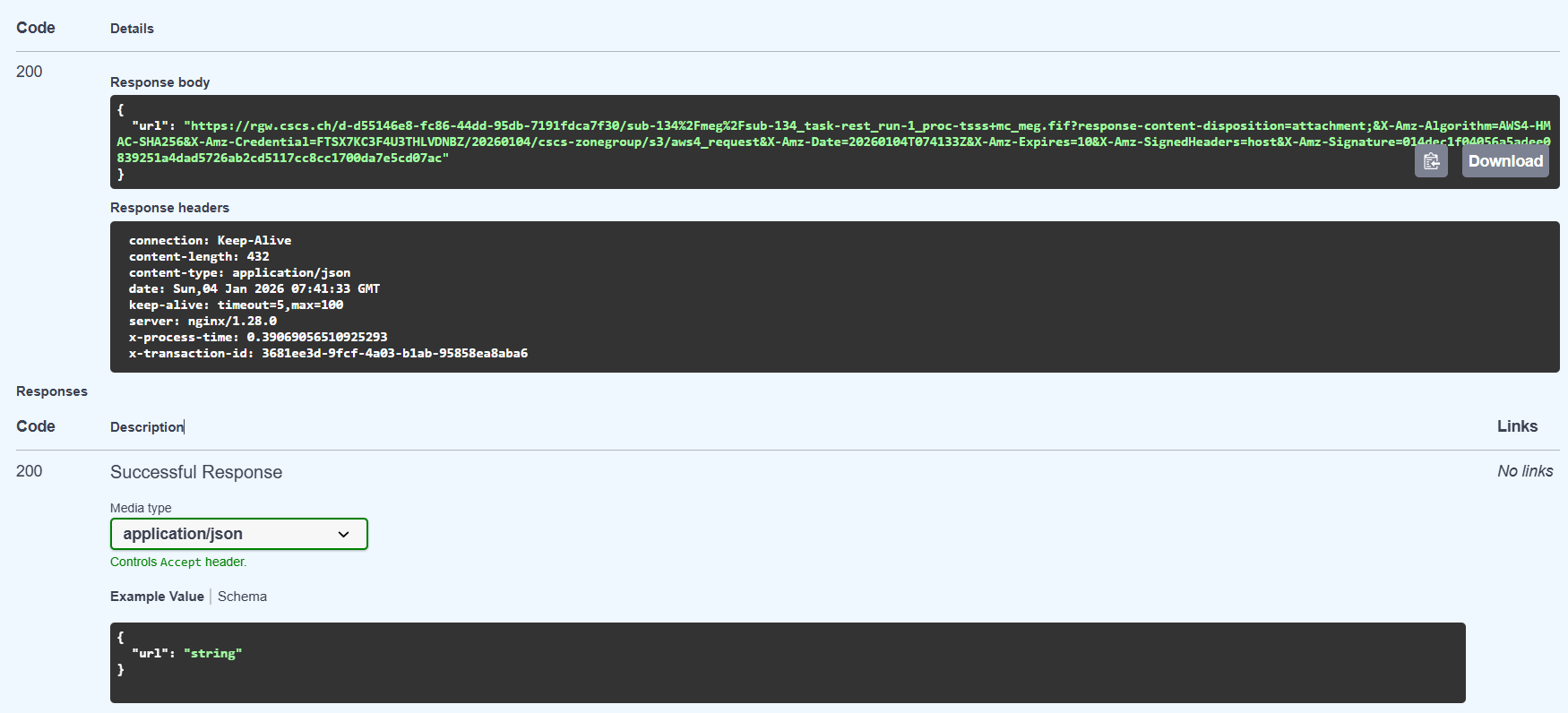
可惜在实际测试过程中,这个url并不可用。
因为可能是超时了。
因为在F12测试真实的响应链接的时候。
可以看到,主要使用的是Bearer的authorization。
让ai生成一个curl请求的链接命令
这个authorization是临时的。
curl -X GET \
'https://data-proxy.ebrains.eu/api/v1/datasets/d55146e8-fc86-44dd-95db-7191fdca7f30/sub-134/meg/sub-134_task-go_run-1_proc-tsss%2Bmc_meg.fif?redirect=false' \
-H 'Authorization: Bearer eyJhbGciOiJSUzI1NiIsInR5cCIgOiAiSldUIiwia2lkIiA6ICJLYU01NTRCM2RmMHBIamZYWi1aRl94bUUwMThPS1R0RkNjMjR3aVVqQmFvIn0.eyJleHAiOjE3Njc1NTMwNTQsImlhdCI6MTc2NzUwOTg1NCwiYXV0aF90aW1lIjoxNzY3NDQ0NjA1LCJqdGkiOiIzMzlkNDExYi1jNDgxLTRlZWYtYTAwZi0zYjdkZDRmMDMwMWQiLCJpc3MiOiJodHRwczovL2lhbS5lYnJhaW5zLmV1L2F1dGgvcmVhbG1zL2hicCIsImF1ZCI6WyJqdXB5dGVyaHViIiwianVweXRlcmh1Yi1qc2MiLCJ0ZWFtIiwiZ3JvdXAiXSwic3ViIjoiOWFmMDZmOWQtZWQ2Ny00ZWE4LTkyYzUtMjFmNTVkYzM3Yzc2IiwidHlwIjoiQmVhcmVyIiwiYXpwIjoiZGF0YS1wcm94eS1mcm9udCIsInNpZCI6ImZlOTI1OTQ5LTM2MjctNGI2My1iMDdlLWQ1MjY1YTAwZmZmMSIsImFsbG93ZWQtb3JpZ2lucyI6WyJodHRwczovL2RhdGEtcHJveHkuZWJyYWlucy5ldSIsImh0dHBzOi8vZGF0YS1wcm94eS1wcm9kLmVicmFpbnMuZXUiLCJodHRwczovL2RhdGEtcHJveHktcHBkLmVicmFpbnMuZXUiXSwic2NvcGUiOiJwcm9maWxlIHJvbGVzIGVtYWlsIG9wZW5pZCBncm91cCB0ZWFtIiwiZW1haWxfdmVyaWZpZWQiOnRydWUsIm5hbWUiOiLpqawg6IW-IiwibWl0cmVpZC1zdWIiOiI5NTYzNDI4NDgyOTg0NjM3IiwicHJlZmVycmVkX3VzZXJuYW1lIjoibWF0ZyIsImdpdmVuX25hbWUiOiLpqawiLCJmYW1pbHlfbmFtZSI6IuiFviIsImVtYWlsIjoibWF0ZW5nNjZAc3R1bWFpbC55c3UuZWR1LmNuIn0.BxZNUM91FDdWCoZ9nPAZIEJerVfjSCQ75EYpCU0PNbmYnUZ0USEJVjjaaLKIo_pR_4_s4CPoBOojbcuqeR81qfqpa9kLIthDDcwYA9ZTyiYbIoXHk3TpVEhMW9lEcWqd82RcLjW0bmrfOugtDyo6Q11o09MCSV-zC7q_iTiP3tqunEowLEm4D-JznMY-93SGquGHnY16nJiWe9Eo3MYFl4-K_ZVz2Qpn_w6gN13ir9zlgkWs8uamuK85fOHIhOqqmKryzS8u12b1jUULYXra5klMtS3v4UOTxTICpv3qEeRm8s7PtgZ81f_zOfOqDJcaEyug4LhoYXdSQ-jn1tyr5A' \
-H 'Accept: application/json, text/plain, */*' \
-H 'Cache-Control: no-cache' \
-H 'Pragma: no-cache'
返回的url是有效的,但是有时效。
{"url":"https://rgw.cscs.ch/d-d55146e8-fc86-44dd-95db-7191fdca7f30/sub-134/meg/sub-134_task-go_run-1_proc-tsss+mc_meg.fif?response-content-disposition=attachment;&X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=FTSX7KC3F4U3THLVDNBZ/20260104/cscs-zonegroup/s3/aws4_request&X-Amz-Date=20260104T075549Z&X-Amz-Expires=10&X-Amz-SignedHeaders=host&X-Amz-Signature=e064289a27f7c15fa8182c302a4a88d40782c290faa0a9509303ba587d054eb7"}
如果延迟,就会出现下面错误的页面。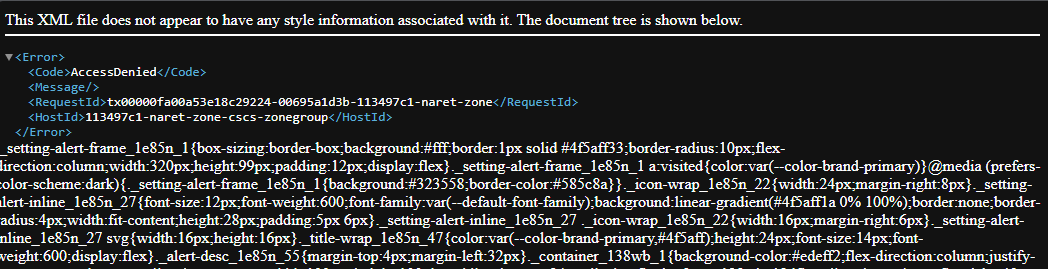
尝试通过python构造访问和批量下载。
但是出现了一个文件可访问,但是一个不可以的情况。
因此,统一为使用bash脚本来处理下载的过程。
通过kimi的ai助手构造一个批量下载的链接。
首先测试脚本的返回链接的有效性,其次,构建批处理下载的脚本。
BEARER_TOKEN需要按照上面的步骤来获取。
批处理代码
batch_download.sh
#!/bin/bash
# ========================================
# EBRAINS MEG 数据批量下载脚本
# ========================================
# 配置参数
DATASET_ID="d55146e8-fc86-44dd-95db-7191fdca7f30"
BEARER_TOKEN="eyJhbGciOiJSUzI1NiIsInR5cCIgOiAiSldUIiwia2lkIiA6ICJLYU01NTRCM2RmMHBIamZYWi1aRl94bUUwMThPS1R0RkNjMjR3aVVqQmFvIn0.eyJleHAiOjE3Njc1NTMwNTQsImlhdCI6MTc2NzUwOTg1NCwiYXV0aF90aW1lIjoxNzY3NDQ0NjA1LCJqdGkiOiIzMzlkNDExYi1jNDgxLTRlZWYtYTAwZi0zYjdkZDRmMDMwMWQiLCJpc3MiOiJodHRwczovL2lhbS5lYnJhaW5zLmV1L2F1dGgvcmVhbG1zL2hicCIsImF1ZCI6WyJqdXB5dGVyaHViIiwianVweXRlcmh1Yi1qc2MiLCJ0ZWFtIiwiZ3JvdXAiXSwic3ViIjoiOWFmMDZmOWQtZWQ2Ny00ZWE4LTkyYzUtMjFmNTVkYzM3Yzc2IiwidHlwIjoiQmVhcmVyIiwiYXpwIjoiZGF0YS1wcm94eS1mcm9udCIsInNpZCI6ImZlOTI1OTQ5LTM2MjctNGI2My1iMDdlLWQ1MjY1YTAwZmZmMSIsImFsbG93ZWQtb3JpZ2lucyI6WyJodHRwczovL2RhdGEtcHJveHkuZWJyYWlucy5ldSIsImh0dHBzOi8vZGF0YS1wcm94eS1wcm9kLmVicmFpbnMuZXUiLCJodHRwczovL2RhdGEtcHJveHktcHBkLmVicmFpbnMuZXUiXSwic2NvcGUiOiJwcm9maWxlIHJvbGVzIGVtYWlsIG9wZW5pZCBncm91cCB0ZWFtIiwiZW1haWxfdmVyaWZpZWQiOnRydWUsIm5hbWUiOiLpqawg6IW-IiwibWl0cmVpZC1zdWIiOiI5NTYzNDI4NDgyOTg0NjM3IiwicHJlZmVycmVkX3VzZXJuYW1lIjoibWF0ZyIsImdpdmVuX25hbWUiOiLpqawiLCJmYW1pbHlfbmFtZSI6IuiFviIsImVtYWlsIjoibWF0ZW5nNjZAc3R1bWFpbC55c3UuZWR1LmNuIn0.BxZNUM91FDdWCoZ9nPAZIEJerVfjSCQ75EYpCU0PNbmYnUZ0USEJVjjaaLKIo_pR_4_s4CPoBOojbcuqeR81qfqpa9kLIthDDcwYA9ZTyiYbIoXHk3TpVEhMW9lEcWqd82RcLjW0bmrfOugtDyo6Q11o09MCSV-zC7q_iTiP3tqunEowLEm4D-JznMY-93SGquGHnY16nJiWe9Eo3MYFl4-K_ZVz2Qpn_w6gN13ir9zlgkWs8uamuK85fOHIhOqqmKryzS8u12b1jUULYXra5klMtS3v4UOTxTICpv3qEeRm8s7PtgZ81f_zOfOqDJcaEyug4LhoYXdSQ-jn1tyr5A"
# 设置下载目录
DOWNLOAD_DIR="./downloads"
mkdir -p "$DOWNLOAD_DIR"
echo "=========================================="
echo "EBRAINS MEG 批量下载工具"
echo "=========================================="
echo "下载目录: $DOWNLOAD_DIR"
echo "数据范围: sub-001 到 sub-134"
echo "=========================================="
# 显示使用帮助
show_help() {
cat << EOF
用法: $0 <任务类型> [起始编号] [结束编号]
参数:
任务类型 - 必需: noise, rest, 或 all
起始编号 - 可选: 从哪个被试开始 (1-134, 默认: 1)
结束编号 - 可选: 到哪个被试结束 (1-134, 默认: 134)
示例:
# 下载所有被试的 noise 数据
./batch_download.sh noise
# 下载 sub-001 到 sub-010 的 rest 数据
./batch_download.sh rest 1 10
# 下载所有被试的所有类型数据
./batch_download.sh all
EOF
}
# 检查参数
if [ $# -lt 1 ]; then
show_help
exit 1
fi
TASK_TYPE="$1"
START_SUBJ=${2:-1}
END_SUBJ=${3:-134}
# 验证参数
if [[ "$TASK_TYPE" != "noise" && "$TASK_TYPE" != "rest" && "$TASK_TYPE" != "all" ]]; then
echo "错误: 任务类型必须是 'noise', 'rest', 或 'all'"
show_help
exit 1
fi
if [[ $START_SUBJ -lt 1 || $START_SUBJ -gt 134 ]] || [[ $END_SUBJ -lt 1 || $END_SUBJ -gt 134 ]]; then
echo "错误: 被试编号必须在 1-134 之间"
exit 1
fi
if [[ $START_SUBJ -gt $END_SUBJ ]]; then
echo "错误: 起始编号不能大于结束编号"
exit 1
fi
# 日志文件
LOG_FILE="$DOWNLOAD_DIR/download_$(date +%Y%m%d_%H%M%S).log"
echo "日志将保存到: $LOG_FILE"
echo "=========================================="
# 下载单个文件的函数
download_file() {
local subj_num="$1"
local task="$2"
# 格式化被试编号
local subj_id=$(printf "sub-%03d" $subj_num)
# 确定文件名格式
if [ "$task" = "noise" ]; then
local filename="${subj_id}_task-noise_proc-tsss+mc_meg.fif"
else
local filename="${subj_id}_task-rest_run-1_proc-tsss+mc_meg.fif"
fi
local filepath="$DOWNLOAD_DIR/$filename"
# 检查文件是否已存在且不是错误文件
if [ -f "$filepath" ]; then
local filesize=$(stat -c%s "$filepath" 2>/dev/null || echo 0)
local filetype=$(file "$filepath" 2>/dev/null || echo "")
if [[ $filesize -gt 1000000 ]] && [[ "$filetype" =~ "Biosig/FIFF" ]]; then
echo "[跳过] $filename (已存在, 大小: $(ls -lh "$filepath" | awk '{print $5}'))" | tee -a "$LOG_FILE"
return 0
fi
fi
echo "[开始] 下载 $filename ..." | tee -a "$LOG_FILE"
# URL 编码文件名(对 + 等特殊字符进行编码)
local encoded_filename=$(python3 -c "from urllib.parse import quote; print(quote('${filename}', safe=''))")
# 获取重定向URL
local redirect_url="https://data-proxy.ebrains.eu/api/v1/datasets/${DATASET_ID}/${subj_id}/meg/${encoded_filename}?redirect=false"
local redirect_json=$(curl -s -X GET "$redirect_url" \
-H "Authorization: Bearer ${BEARER_TOKEN}" \
-H "Accept: application/json, text/plain, */*")
local real_url=$(echo $redirect_json | grep -o '"url":"[^"]*' | cut -d'"' -f4)
if [ -z "$real_url" ]; then
echo " ❌ 错误: 无法获取重定向 URL" | tee -a "$LOG_FILE"
if [[ "$redirect_json" =~ "NotFound" || "$redirect_json" =~ "NoSuchKey" ]]; then
echo " ⚠️ 文件可能不存在: $filename" | tee -a "$LOG_FILE"
return 2
else
echo " 响应: $redirect_json" | tee -a "$LOG_FILE"
return 1
fi
fi
# 下载文件
if curl -L -X GET "$real_url" -o "$filepath" --progress-bar 2>&1 | tee -a "$LOG_FILE"; then
# 验证下载的文件
if [ -f "$filepath" ]; then
local filesize=$(stat -c%s "$filepath" 2>/dev/null || echo 0)
local filetype=$(file "$filepath" 2>/dev/null || echo "")
if [[ $filesize -gt 1000000 ]] && [[ "$filetype" =~ "Biosig/FIFF" ]]; then
echo " ✅ 下载成功: $(ls -lh "$filepath" | awk '{print $5}')" | tee -a "$LOG_FILE"
return 0
else
echo " ❌ 下载失败: 文件无效或太小 ($filesize bytes)" | tee -a "$LOG_FILE"
rm -f "$filepath"
return 1
fi
else
echo " ❌ 下载失败: 文件未创建" | tee -a "$LOG_FILE"
return 1
fi
else
echo " ❌ 下载失败: CURL 错误" | tee -a "$LOG_FILE"
rm -f "$filepath"
return 1
fi
}
# 统计变量
TOTAL_TASKS=0
SUCCESS_COUNT=0
FAIL_COUNT=0
NOT_FOUND_COUNT=0
# 计算总任务数
if [ "$TASK_TYPE" = "all" ]; then
TOTAL_TASKS=$((($END_SUBJ - $START_SUBJ + 1) * 2))
else
TOTAL_TASKS=$(($END_SUBJ - $START_SUBJ + 1))
fi
CURRENT_TASK=0
# 主下载循环
echo ""
echo "开始批量下载 (任务数: $TOTAL_TASKS)"
echo "=========================================="
echo ""
for subj in $(seq $START_SUBJ $END_SUBJ); do
if [ "$TASK_TYPE" = "all" ] || [ "$TASK_TYPE" = "noise" ]; then
CURRENT_TASK=$((CURRENT_TASK + 1))
echo "[$CURRENT_TASK/$TOTAL_TASKS]"
if download_file $subj "noise"; then
SUCCESS_COUNT=$((SUCCESS_COUNT + 1))
elif [ $? -eq 2 ]; then
NOT_FOUND_COUNT=$((NOT_FOUND_COUNT + 1))
else
FAIL_COUNT=$((FAIL_COUNT + 1))
fi
echo ""
fi
if [ "$TASK_TYPE" = "all" ] || [ "$TASK_TYPE" = "rest" ]; then
CURRENT_TASK=$((CURRENT_TASK + 1))
echo "[$CURRENT_TASK/$TOTAL_TASKS]"
if download_file $subj "rest"; then
SUCCESS_COUNT=$((SUCCESS_COUNT + 1))
elif [ $? -eq 2 ]; then
NOT_FOUND_COUNT=$((NOT_FOUND_COUNT + 1))
else
FAIL_COUNT=$((FAIL_COUNT + 1))
fi
echo ""
fi
# 每下载几个文件后稍微休息一下,避免请求过于频繁
if [ $(($subj % 5)) -eq 0 ]; then
sleep 2
fi
done
# 汇总报告
echo ""
echo "=========================================="
echo "下载完成汇总"
echo "=========================================="
echo "总任务数: $TOTAL_TASKS"
echo "成功: $SUCCESS_COUNT"
echo "失败: $FAIL_COUNT"
echo "文件不存在: $NOT_FOUND_COUNT"
echo "=========================================="
echo "日志已保存到: $LOG_FILE"
echo ""
echo "已下载的文件:"
ls -lh $DOWNLOAD_DIR/*.fif 2>/dev/null
./batch_download.sh rest 75 86
实现批量下载,此外,还可以指定整理的文件夹形式,让kimi来帮助进行整理。
好的,记录完毕。
为什么使用这种形式,因为网络连接和速度不稳定,且文件较大。尝试了官方提供的api,总是出错。在下载页面进行请求体的构造,进行下载。
使用代理ai,可以帮助我们处理一些繁琐,重复的步骤。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 4
4 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)