3步创建智能数字员工:TextIn+火山引擎颠覆企业文档处理,效率提升90%
近期,合合信息TextIn与火山引擎联合升级的“大模型加速器”正式发布,旨在解决企业文档处理中的格式碎片化、语言壁垒及大模型幻觉等核心痛点。该方案通过TextIn的高精度解析与火山引擎的低代码平台协同,为企业提供快速构建智能数字员工的路径。本文将深入解析如何三步实现从非结构化文档到自动化业务处理的效能革命,并探讨其能否真正解决企业AI落地的“最后一公里”难题。想象一下,你的法务同事正对着一份20页
文章概要
近期,合合信息TextIn与火山引擎联合升级的“大模型加速器”正式发布,旨在解决企业文档处理中的格式碎片化、语言壁垒及大模型幻觉等核心痛点。该方案通过TextIn的高精度解析与火山引擎的低代码平台协同,为企业提供快速构建智能数字员工的路径。本文将深入解析如何三步实现从非结构化文档到自动化业务处理的效能革命,并探讨其能否真正解决企业AI落地的“最后一公里”难题。

想象一下,你的法务同事正对着一份20页的跨国合同,用肉眼逐行扫描“自动续约”的隐藏条款;你的财务同事正将上百张模糊的发票信息,手动敲进ERP系统。这不是某个效率低下的旧时代场景,而是2025年许多企业仍在经历的日常。
企业文档处理的“最后一公里”,正卡在格式与语言的双重壁垒上。核心知识被锁死在PDF、扫描件、Word等非结构化文档里,它们形态各异,语言混杂。一份来自德国供应商的电机规格书,可能同时包含德文专业术语、英文注释和复杂的嵌套表格。传统OCR技术在这里频频“翻车”——它或许能认出字符,却无法理解“94.4%”这个数字,究竟是“满载效率”还是“功率因数”,更无法将表格的行列关系准确还原。
当这些支离破碎的文本碎片被喂给大模型(LLM)时,问题被进一步放大。LLM如同一位博学但视力不佳的学者,你给它一堆顺序错乱的字符,它只能基于碎片进行“幻觉式”推理,给出看似合理实则错误的答案。这就是为什么你问AI“合同里的付款条件是什么”,它可能自信地编造出一个根本不存在的条款。
更深层的瓶颈在于业务敏捷性与召回精度的失衡。传统的RAG(检索增强生成)系统,其效果严重依赖于输入数据的质量。如果文档解析这第一步就错了——表格错行、多栏文本乱序、跨页内容断裂——那么后续的向量检索就如同在垃圾堆里寻宝,召回的相关信息大概率是无效的。另一方面,完全依赖人工处理,虽能保证一定精度,却彻底牺牲了敏捷性。审核一份复杂合同需要数小时,处理海量发票更是人力难以承受之重。企业陷入两难:要速度,就得忍受错误和风险;要精度,就得付出高昂的时间与人力成本。
这不仅仅是效率问题,更是数据资产的巨大浪费。企业积累的数十万份合同、技术手册、财务单据,本应是驱动决策的“数据石油”,却因无法被机器有效“阅读”和“理解”,变成了沉睡在硬盘里的“数据废矿”。智能数字员工要解决的,正是打通从“文档废矿”到“数据石油”的炼化之路。
技术协同:TextIn与火山引擎如何赋能数字员工
当企业决心引入“数字员工”时,面临的核心挑战并非缺乏大模型,而是如何让AI“看懂”复杂的业务文档,并“执行”连贯的业务流程。合合信息TextIn与火山引擎的协同,恰好提供了“结构化认知”与“自动化执行”的双引擎,将AI能力从实验室演示,转化为可稳定运行的生产力。
TextIn解析引擎:赋予AI“结构化认知”的核心
传统OCR或通用解析工具,在处理企业文档时,往往只能输出“文本字符串”,丢失了表格、版式、多语言等关键结构信息。这导致大模型“吃”进去的是低质量语料,自然“吐”不出可靠的答案,幻觉频发、答非所问成为常态。
TextIn解析引擎的突破在于,它为企业文档构建了“结构化认知”的基础。其核心能力体现在三个维度:
-
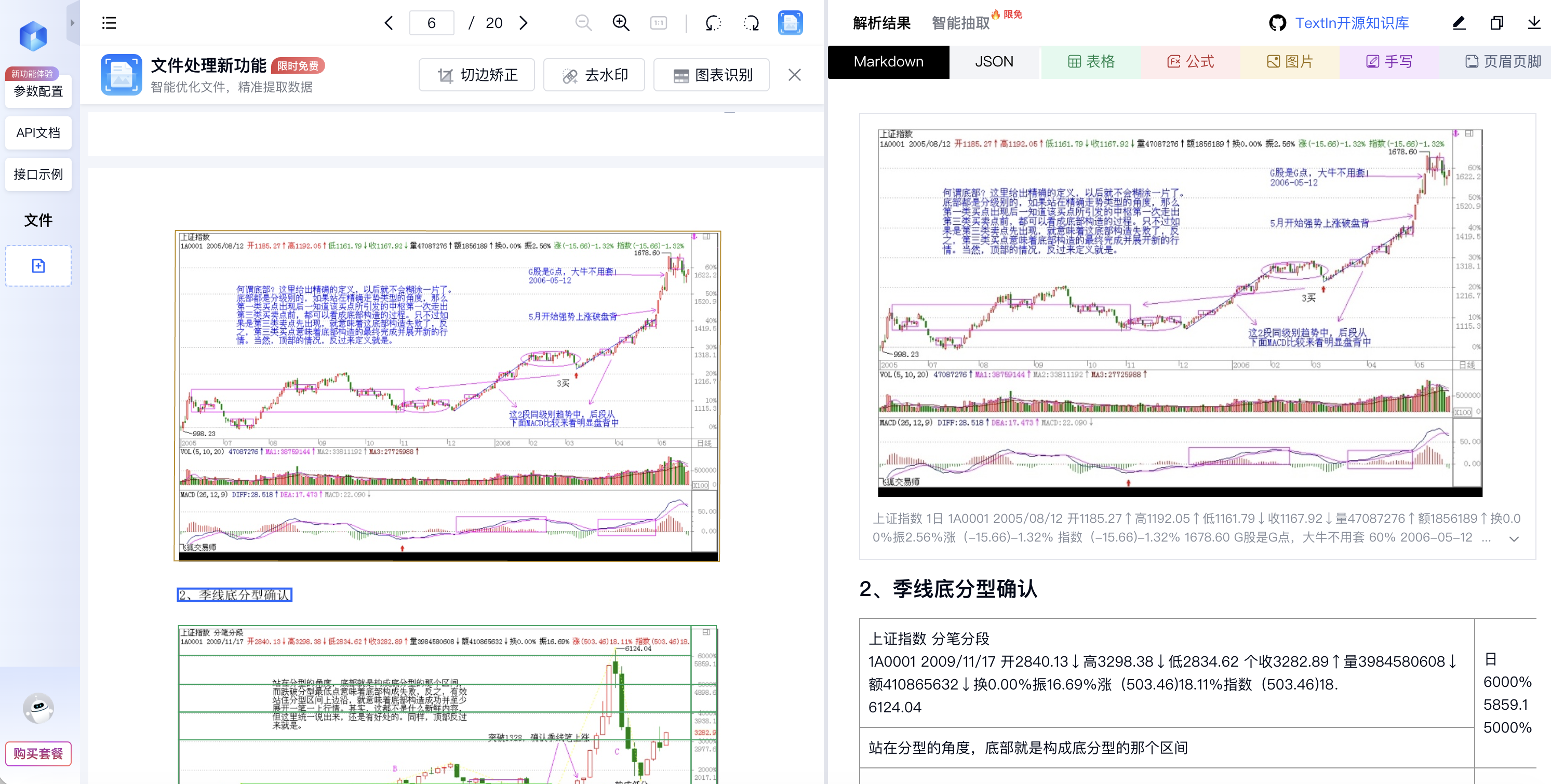
多模态与多格式的深度理解:支持超过50种语言和20余种文档格式(包括扫描件、CAD图纸等),能精准识别并还原文档中的段落、多级标题、复杂表格(含合并单元格)、图片标题及版面坐标(bbox)。这意味着,一份中德英三语的跨国采购合同,或一份图文混排的产品手册,能被一次性解析为包含完整逻辑关系的结构化数据。
-
“md+bbox”的输出范式:解析结果不仅是可读的Markdown文本,更附带了每个元素在原文中的精确坐标。这种输出直接为后续的精准向量化、内容高亮、版式还原提供了可能,让RAG检索从“纯文本匹配”升级为“多维度结构召回”。
-
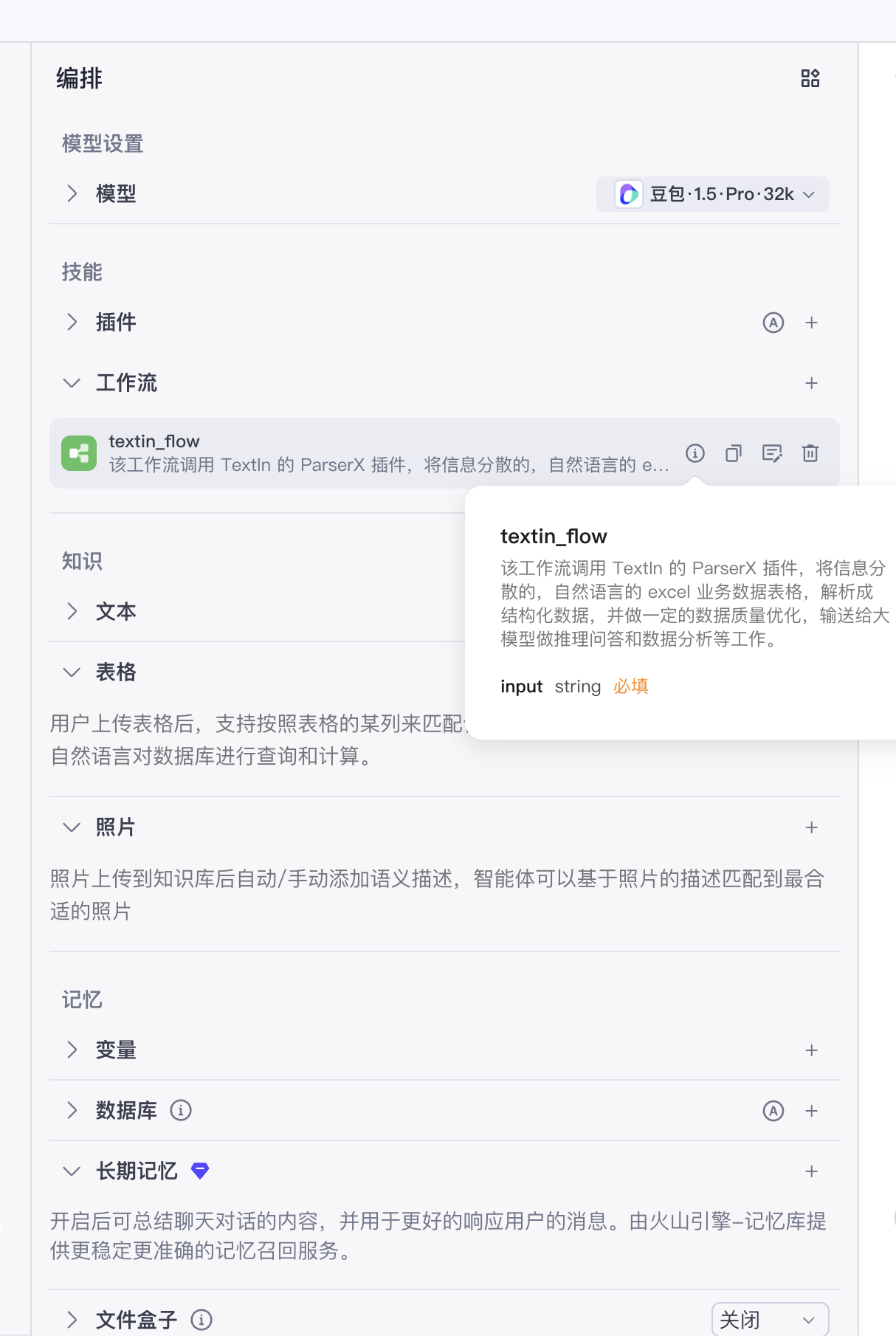
面向AI工程化的接口设计:通过提供标准化的API和MCP(Model-Component Protocol)Server服务,TextIn将复杂的解析能力封装为即插即用的“组件”。开发者无需关心底层模型,即可让Coze、Dify等各类AI平台上的大模型直接调用,大幅降低了高质量文档数据接入AI流程的门槛。
本质洞察:TextIn的价值不在于替代某个OCR工具,而在于将非结构化文档转化为高质量的“机器可读”语料,从根本上解决了大模型应用的“数据供给侧”质量问题。
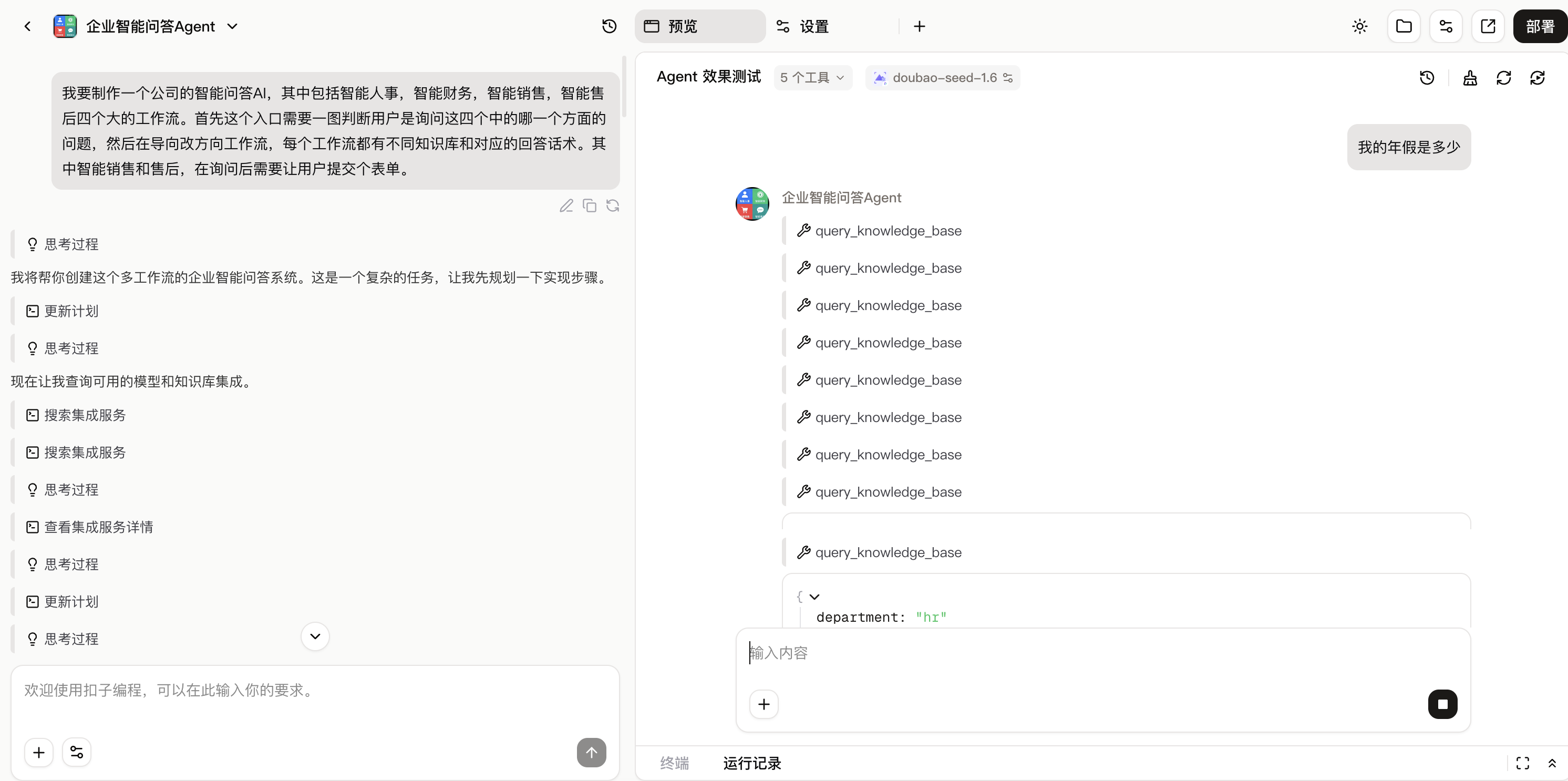
火山引擎平台:低代码串联解析、召回与处理的自动化链路
拥有了高质量的“结构化认知”数据,下一步是如何将其融入动态的业务流程。这正是火山引擎Coze/HiAgent等低代码平台发挥作用的舞台。它们的作用不是提供另一个大模型,而是成为连接数据、模型与业务系统的“自动化编排中枢”。
其赋能路径清晰且高效:
-
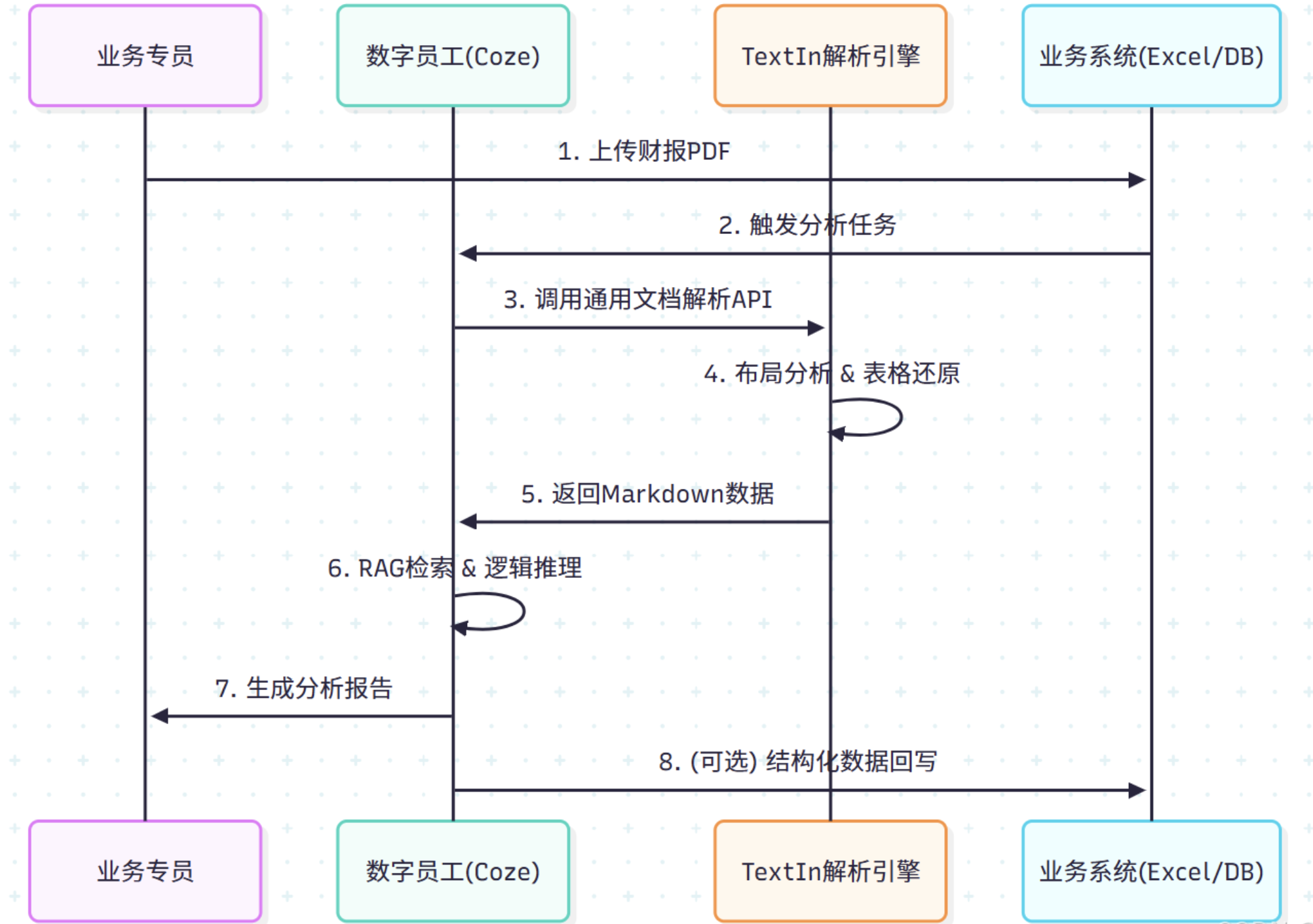
可视化拖拽,构建“数字员工”工作流:在Coze平台,开发者通过拖拽节点,就能直观搭建从“文档触发→TextIn解析→向量库召回→大模型处理→结果回写业务系统”的完整链路。资料中提到的“拖3个节点即可串成流程”,正是这种低代码敏捷性的体现。这解决了传统开发模式下,IT团队面对“业务需求一周三变”时迭代缓慢的痛点。
-
全链路可观测与工程化能力:平台不仅支持流程构建,更提供了热更新、灰度发布、全链路审计等企业级工程化特性。这意味着,“数字员工”的流程可以像软件一样进行版本管理、小流量测试和故障追踪,保障了其在生产环境中的稳定性和可维护性。
-
生态集成,激活数据价值:火山引擎平台充当了“连接器”,一端无缝集成TextIn的解析能力作为输入,另一端可灵活对接向量数据库、多种大模型以及企业的CRM、ERP等业务系统。这使得结构化后的文档数据,能够被轻松应用于智能问答、风险审核、内容生成等具体场景,形成从“文档解析”到“业务价值”的闭环。
两者的协同,本质上是一次精密的“分工”:TextIn专注于解决“AI如何精准读懂文档”这一底层难题,而火山引擎平台则解决“如何让读懂文档的AI去自动化办事”这一应用层难题。这种组合,让企业构建“数字员工”从一项需要深厚AI算法和工程背景的复杂项目,转变为一个更侧重业务逻辑梳理和流程设计的可落地任务。

三步实战:快速搭建可落地的智能数字员工
理论再完美,无法落地也是空谈。TextIn与火山引擎的组合,其核心价值在于将复杂的AI工程化能力,封装成开发者能在2小时内上手的“三步法”。这不仅是技术演示,更是企业从“观望”到“行动”的关键一跃。
环境配置与核心API对接
搭建数字员工的第一步,是打通“感知”世界的通道。整个过程的核心,是获取并配置两个关键资源:TextIn的解析API与火山引擎的平台权限。
import json
import requests
from typing import Dict, Optional
from dataclasses import dataclass
class OCRClient:
def __init__(self, app_id: str, secret_code: str):
self.app_id = app_id
self.secret_code = secret_code
def recognize(self, file_content: bytes, options: dict) -> str:
# 构建请求参数
params = {}
for key, value in options.items():
params[key] = str(value)
# 设置请求头
headers = {
"x-ti-app-id": self.app_id,
"x-ti-secret-code": self.secret_code,
"x-ti-client-source": "sample-code-v1.0",
# 方式一:读取本地文件
"Content-Type": "application/octet-stream"
# 方式二:使用URL方式
# "Content-Type": "text/plain"
}
# 发送请求
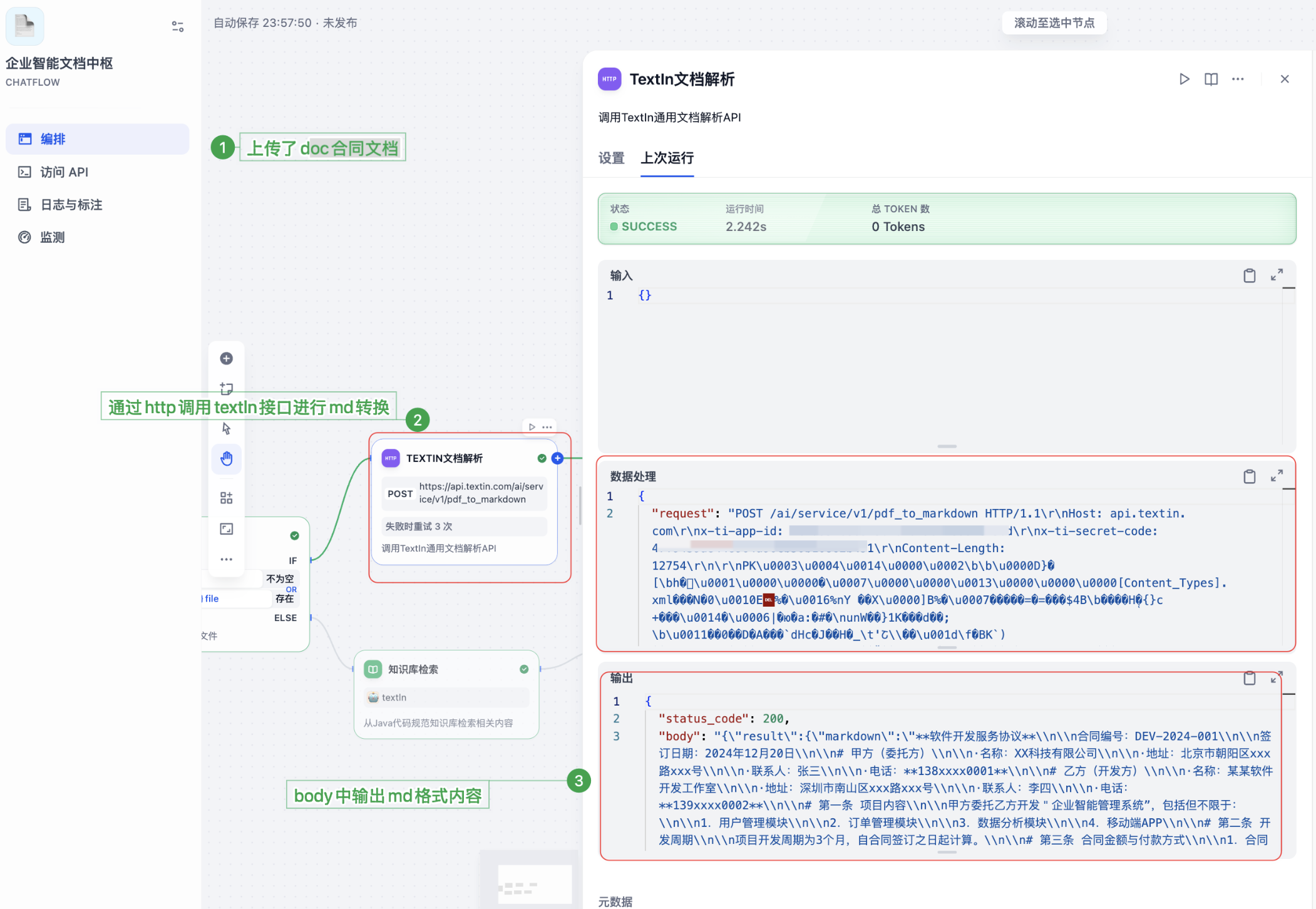
response = requests.post(
f"https://api.textin.com/ai/service/v1/pdf_to_markdown",
params=params,
headers=headers,
data=file_content
)
# 检查响应状态
response.raise_for_status()
return response.text
def main():
# 创建客户端实例
client = OCRClient("57c...", "3e9...")
# 读取图片文件
# 方式一:读取本地文件
with open("example.png", "rb") as f:
file_content = f.read()
# 方式二:使用URL方式(需要将headers中的Content-Type改为'text/plain')
# file_content = "https://example.com/path/to/your.pdf"
# 设置转换选项
options = dict(
)
try:
response = client.recognize(file_content, options)
# 保存完整的JSON响应到result.json文件
with open("result.json", "w", encoding="utf-8") as f:
f.write(response)
# 解析JSON响应以提取markdown内容
json_response = json.loads(response)
if "result" in json_response and "markdown" in json_response["result"]:
markdown_content = json_response["result"]["markdown"]
with open("result.md", "w", encoding="utf-8") as f:
f.write(markdown_content)
print(response)
except Exception as e:
print(f"Error: {e}")
if __name__ == "__main__":
main()
- 获取TextIn“通行证”:访问TextIn官网注册,新用户通常可获得数千页的免费解析额度。关键步骤是进入开发者后台,获取
app_id和secret_code。这两个密钥是调用其“通用文档解析”等核心API的凭证。TextIn API支持超过50种语言和20多种格式,其输出并非简单的文本流,而是包含段落、表格、标题及版面坐标(bbox)的结构化JSON或Markdown,这为后续的精准向量化和业务处理奠定了基础。 - 接入火山引擎“操作台”:注册火山引擎账号,并进入其AI开发平台(如Coze或HiAgent)。这里将成为你编排数字员工工作流的“画布”。你需要创建一个新的工作空间或项目,并确保网络环境能够稳定调用外部API(即TextIn的服务)。
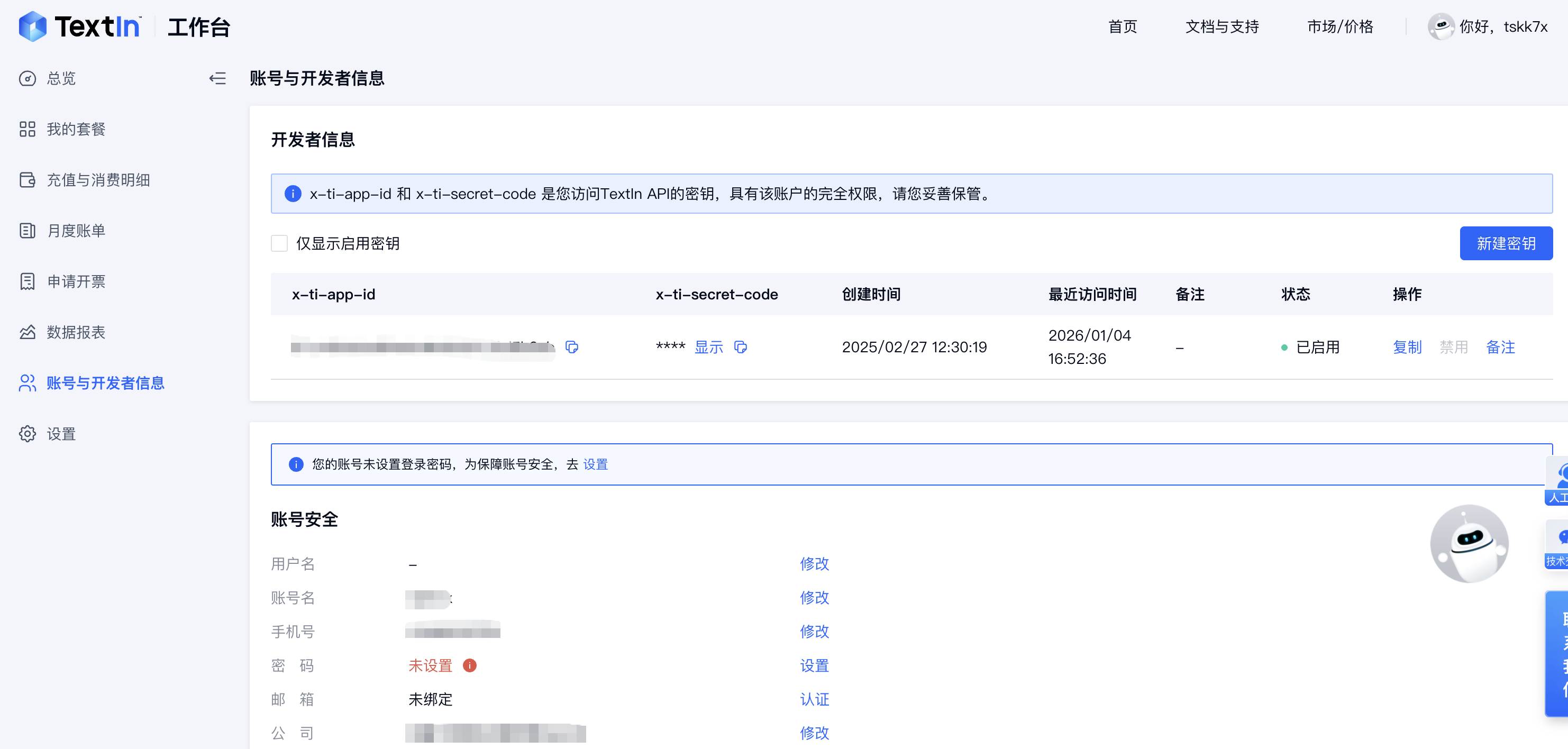
这一步的深度在于,它实质上是在为AI构建标准化的“感官输入”。传统自研OCR方案往往需要数月的数据标注、模型训练和调优,而通过API对接,企业直接接入了行业领先的解析能力,将技术门槛从“算法研发”降维到“服务集成”。
低代码拖拽:构建自动化工作流
配置好“感官”和“操作台”后,最体现效率革命的环节来了:无需编写复杂代码,通过可视化拖拽构建完整处理流水线。以在火山引擎Coze平台上创建一个“多语言合同审查数字员工”为例:
- 设置触发器:从节点库拖入“触发器”,可配置为“API调用”(供业务系统主动触发)或“定时任务”(如每日凌晨自动处理新文档)。
- 接入解析能力:添加“自定义插件”或搜索集成好的“TextIn通用文档解析”插件。在配置中填入之前获取的
app_id和secret_code,并设定输入为触发器传来的文件。 - 设计决策逻辑:这是数字员工的“大脑”。你可以拖入“条件判断”节点,例如,若解析出的“文档类型”为“采购合同”,则进入审查流程;若是“产品手册”,则进入翻译流程。
- 嵌入业务智能:在合同审查分支后,接入“大模型”节点。通过精心设计的Prompt(提示词),指令大模型基于TextIn解析出的结构化条款(标题、金额、交付节点),与预先录入的标准模板进行比对,并输出差异报告和风险提示。
- 完成价值闭环:最后,拖入“回写”节点,将审查结果通过HTTP请求自动写入公司的法务系统或合同管理系统,并发送邮件通知负责人。
整个过程就像拼接乐高。其颠覆性在于,业务逻辑的变更(如增加一种审核规则)不再需要开发团队排期、编码、测试、上线,而是由业务人员或产品经理在图形化界面上直接修改节点逻辑,实现“热更新”。这解决了传统开发模式中“业务需求一周三变,IT迭代慢如蜗牛”的核心矛盾。
效果验证:从数天到分钟的效能量化对比
数字员工的价值必须用数据说话。根据多个实战案例的测试反馈,效能的提升是数量级的:
- 跨国合同审查:一份涉及中、英、德三语的采购合同,传统人工逐条比对、查询术语、复核格式,平均需3小时。数字员工流程在接入后,从解析、跨语言比对到生成风险报告,P99耗时稳定在3分钟以内,且条款漏审率下降超过78%。
- 产品手册翻译同步:我们更新120页技术手册,需同步至英、日、西三种语言。传统流程依赖外包翻译与内部校审,周期长达5个工作日。通过数字员工自动化解析、调用专业翻译引擎、自动对比版本差异并标红,全流程压缩至4小时,版本错误率降低80%。
- 贸易单据核验:金融审单员核验发票、提单、保单三单信息是否一致,平均需45分钟且高度依赖经验。数字员工实现三单信息自动提取与交叉验证,将平均处理时间缩短至5分钟,审单人力得以释放至更复杂的异常处理环节。
这些数据揭示的不仅是效率提升,更是工作性质的变革:人从重复、繁琐的信息“搬运工”和“核对员”,转变为处理异常、做出最终决策的“监督者”和“分析师”。
然而,必须客观看待当前局限:数字员工在处理极度模糊、污损的扫描件,或理解需要深厚行业背景和上下文才能判断的“商业意图”时,准确率仍有波动。它并非万能,其设计初衷是处理海量、规则相对明确的文档任务,将人类从“体力劳动”中解放,而非替代所有“脑力劳动”。
效能革命与未来边界:数字员工是替代还是解放?
当智能数字员工从概念走向生产环境,企业最关心的问题已不再是“它能否工作”,而是“它能带来多大改变”以及“它的边界在哪里”。这场由TextIn与火山引擎驱动的效能革命,其价值已通过真实数据得到验证,但随之而来的,是关于AI角色与人类价值的深层思考。
成本与效率的跨越式提升:真实场景数据对比
数字员工的价值,最终要回归到商业世界的核心指标:成本与效率。从多个实战案例的数据来看,其带来的提升是跨越式的,而非简单的线性优化。
我们以跨国供应链技术规格审计为例:
- 效率维度:传统人工审核一份复杂的工业电机规格书,需要工程师花费5-10分钟进行阅读与数据比对。而基于TextIn+火山引擎的数字员工,从文档上传、解析到完成合规性校验并生成报告,P99耗时低于10秒,效率提升超过100倍。
- 成本维度:按工程师时薪折算,单份文档的人工处理成本约为5元。而数字员工通过API调用处理,单页成本可低至几分钱,成本下降了两个数量级。
- 质量维度:传统OCR方案在复杂表格上的字段抽取准确率可能因错行而骤降。而TextIn的结构化解析配合大模型推理,使字段抽取准确率达到98.5%,已无限接近人工审核的99%基准线。
这些数据揭示了一个核心事实:数字员工并非在“优化”原有流程,而是在“重构”它。 它将高度重复、规则明确的认知型劳动,从以“人时”为单位的线性增长,转变为以“毫秒”为单位的指数级处理能力,成本结构也随之发生断崖式变化。
当前技术局限与争议:AI能否完全取代复杂人工判断?
尽管数据亮眼,但我们必须清醒地认识到,当前的智能数字员工仍存在明确的边界。将其视为“完全替代”而非“能力增强”,是一种危险的误解。
主要局限体现在三个方面:
- 对复杂上下文与模糊规则的挑战:数字员工擅长处理结构化、有明确标准的信息。然而,企业中存在大量依赖行业经验、隐性知识、复杂谈判背景的文档。例如,一份涉及定制化条款、知识产权归属模糊的研发合同。大模型可能识别出条款文本,但难以精准评估其背后的商业风险、法律灰色地带或战略价值。这超出了当前技术对“语义理解”的范畴,进入了需要“情境智慧”的领域。

-
“幻觉”与溯源可信度问题:虽然TextIn的高精度解析极大降低了RAG系统的“幻觉”风险,但并未根除。当文档本身存在歧义或信息缺失时,大模型仍可能生成看似合理但错误的推断。尽管方案要求输出溯源(如页码),但在极端复杂的文档中,如何确保模型引用的“证据”片段足以支撑其全部结论,仍是一个工程难题。这要求关键决策节点必须保留“人工复核”的最终阀门。
-
对“非标”与动态变化的适应性局限:当前的数字员工擅长处理已知格式和规则的文档。一旦遇到全新类型的文档、极其不规范的扫描件,或是行业标准突然更新,系统可能需要重新调整解析策略。其“泛化能力”仍弱于经过训练的人类专家。人类可以凭借类比和常识快速适应,而AI则需要明确的再训练或指令调整。
因此,更准确的定位是:智能数字员工是人类的“超级协作者”而非“替代者”。它解放了人类从繁琐、重复的文档信息提取与初步核对中脱身,将宝贵的专业人力投入到更需要创造力、战略判断和复杂沟通的高价值工作中。
真正的效能革命,不是人的消失,而是人的升级。 当法务专家不再逐字核对合同,而是审核AI标出的风险条款并制定谈判策略时,人机协同的价值才真正显现。
那么,你认为在你所在的行业中,有哪些工作最可能被“数字员工”接管,又有哪些核心价值必须由人类牢牢把握?欢迎在评论区分享你的观察与思考。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 11
11 0
0- 0



 已为社区贡献41条内容
已为社区贡献41条内容

所有评论(0)