用粒子群PSO优化KELM:多维输入单维输出数据处理探秘
KELM是一种单隐层前馈神经网络,它的训练速度很快。简单来说,对于一个具有$N$个样本的训练集 $\{(xi,ti)\}i\in R^n$ 是输入向量,$t_i\in R$ 是对应的输出值(这就是我们说的多维输入单维输出)。KELM的模型可以表示为:\[ \sumi g(ai,xi + bi) = o其中 $L$ 是隐含层节点数,$g(\cdot)$ 是激活函数,$ai$ 是输入权值,$bi$ 是
利用粒子群PSO优化KELM,数据是多维输入单维输出的,直接替换我的测试数据就可以用,并且可以和没有优化过的KELM做对比分析
在机器学习的世界里,如何提升模型的性能一直是大家关注的重点。今天咱们就来聊聊利用粒子群算法(PSO)优化极限学习机(KELM),而且针对多维输入单维输出的数据情况,还能和未优化的KELM做个对比分析,让大家看看优化前后的差异。
一、极限学习机(KELM)简介
KELM是一种单隐层前馈神经网络,它的训练速度很快。简单来说,对于一个具有$N$个样本的训练集 $\{(xi,ti)\}{i = 1}^N$,$xi\in R^n$ 是输入向量,$t_i\in R$ 是对应的输出值(这就是我们说的多维输入单维输出)。KELM的模型可以表示为:
\[ \sum{i = 1}^L \betai g(ai,xi + bi) = oj, j = 1,\cdots,N \]
其中 $L$ 是隐含层节点数,$g(\cdot)$ 是激活函数,$ai$ 是输入权值,$bi$ 是隐含层偏置,$\beta_i$ 是输出权值。

在代码实现上,假设我们使用Python和numpy库,简单的KELM初始化代码可以像这样:
import numpy as np
class KELM:
def __init__(self, input_size, hidden_size):
self.input_size = input_size
self.hidden_size = hidden_size
self.a = np.random.rand(self.hidden_size, self.input_size)
self.b = np.random.rand(self.hidden_size, 1)
self.beta = None
def activation(self, x):
return 1 / (1 + np.exp(-x))
def hidden_layer_output(self, X):
G = np.dot(self.a, X.T) + self.b
return self.activation(G)
def train(self, X, T):
H = self.hidden_layer_output(X)
self.beta = np.dot(np.linalg.pinv(H.T), T)
def predict(self, X):
H = self.hidden_layer_output(X)
return np.dot(H.T, self.beta)这里init方法初始化了输入层到隐含层的权重a和隐含层偏置b。activation方法定义了激活函数,这里用的是Sigmoid函数。hiddenlayeroutput计算隐含层的输出,train方法通过计算隐含层输出矩阵的伪逆来得到输出权重beta,predict方法则利用训练得到的参数进行预测。
二、粒子群算法(PSO)
粒子群算法模拟鸟群觅食行为,每个粒子代表一个潜在解,在解空间中飞行寻找最优解。每个粒子有自己的速度和位置,通过跟踪自己的历史最优位置(pbest)和群体的历史最优位置(gbest)来更新自己的位置和速度。
速度更新公式:
\[ v{i,d}^{k + 1}=\omega v{i,d}^k + c1r{1,d}^k(p{i,d}^k - x{i,d}^k)+c2r{2,d}^k(p{g,d}^k - x{i,d}^k) \]
位置更新公式:
\[ x{i,d}^{k + 1}=x{i,d}^k + v_{i,d}^{k + 1} \]
其中,$v{i,d}^k$ 是粒子 $i$ 在第 $k$ 次迭代中第 $d$ 维的速度,$x{i,d}^k$ 是粒子 $i$ 在第 $k$ 次迭代中第 $d$ 维的位置,$\omega$ 是惯性权重,$c1$ 和 $c2$ 是学习因子,$r{1,d}^k$ 和 $r{2,d}^k$ 是介于 $0$ 和 $1$ 之间的随机数,$p{i,d}^k$ 是粒子 $i$ 的历史最优位置,$p{g,d}^k$ 是群体的历史最优位置。
下面是简单的PSO代码框架:
class PSO:
def __init__(self, dim, pop_size, max_iter, lb, ub):
self.dim = dim
self.pop_size = pop_size
self.max_iter = max_iter
self.lb = lb
self.ub = ub
self.particles = np.random.uniform(self.lb, self.ub, (self.pop_size, self.dim))
self.velocities = np.zeros((self.pop_size, self.dim))
self.pbest = self.particles.copy()
self.pbest_fitness = np.full(self.pop_size, np.inf)
self.gbest = None
self.gbest_fitness = np.inf
def update_velocity(self, fitness_func):
omega = 0.7298
c1 = 1.49618
c2 = 1.49618
r1 = np.random.rand(self.pop_size, self.dim)
r2 = np.random.rand(self.pop_size, self.dim)
self.velocities = omega * self.velocities + c1 * r1 * (self.pbest - self.particles) + c2 * r2 * (
self.gbest - self.particles)
def update_position(self):
self.particles = self.particles + self.velocities
self.particles = np.clip(self.particles, self.lb, self.ub)
def optimize(self, fitness_func):
for i in range(self.max_iter):
fitness_values = fitness_func(self.particles)
improved_indices = fitness_values < self.pbest_fitness
self.pbest[improved_indices] = self.particles[improved_indices]
self.pbest_fitness[improved_indices] = fitness_values[improved_indices]
best_index = np.argmin(self.pbest_fitness)
if self.pbest_fitness[best_index] < self.gbest_fitness:
self.gbest = self.pbest[best_index]
self.gbest_fitness = self.pbest_fitness[best_index]
self.update_velocity(fitness_func)
self.update_position()
return self.gbest这里init方法初始化了粒子的位置、速度、个体最优位置等。updatevelocity和updateposition方法分别根据公式更新速度和位置,optimize方法在迭代过程中寻找最优解。
三、PSO优化KELM
我们要用PSO来优化KELM的输入权值a和隐含层偏置b。这里我们把a和b展开成一维向量作为PSO粒子的位置。
def fitness(p, input_size, hidden_size, X, T):
a = p[:hidden_size * input_size].reshape((hidden_size, input_size))
b = p[hidden_size * input_size:].reshape((hidden_size, 1))
model = KELM(input_size, hidden_size)
model.a = a
model.b = b
model.train(X, T)
pred = model.predict(X)
mse = np.mean((pred - T) ** 2)
return mse
def pso_optimized_kelm(X, T, input_size, hidden_size, pop_size, max_iter, lb, ub):
dim = hidden_size * input_size + hidden_size
pso = PSO(dim, pop_size, max_iter, lb, ub)
best_params = pso.optimize(lambda p: fitness(p, input_size, hidden_size, X, T))
a = best_params[:hidden_size * input_size].reshape((hidden_size, input_size))
b = best_params[hidden_size * input_size:].reshape((hidden_size, 1))
optimized_model = KELM(input_size, hidden_size)
optimized_model.a = a
optimized_model.b = b
optimized_model.train(X, T)
return optimized_modelfitness函数计算给定参数下KELM的均方误差(MSE),作为PSO的适应度值。psooptimizedkelm函数则利用PSO找到最优的参数,并返回优化后的KELM模型。
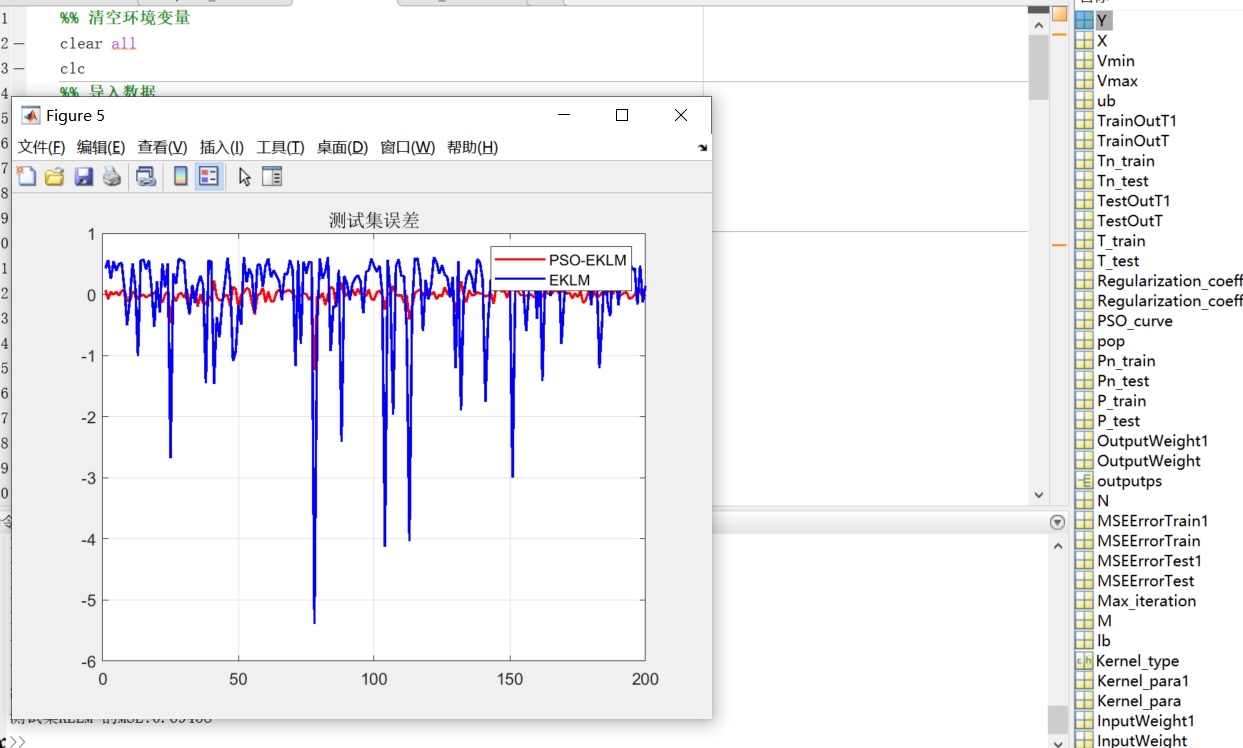
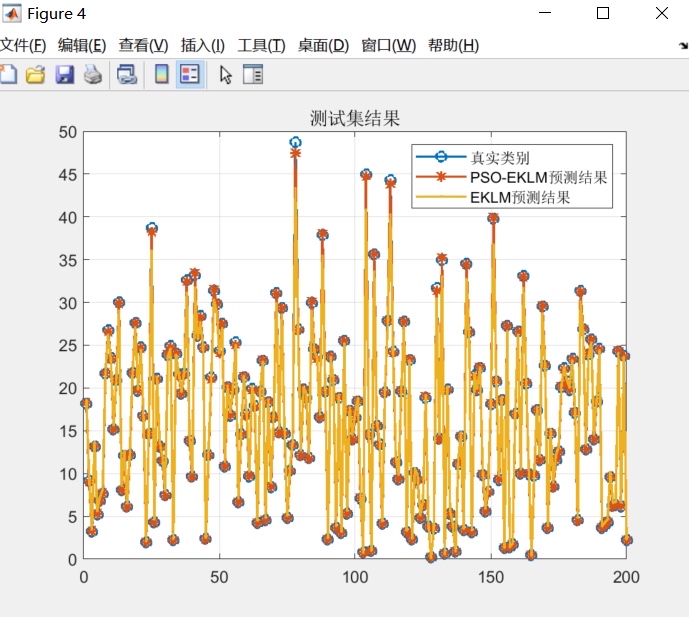
四、对比分析
假设我们有一些多维输入单维输出的测试数据,下面进行未优化KELM和PSO优化KELM的对比。
# 生成一些模拟的多维输入单维输出数据
np.random.seed(0)
input_size = 5
hidden_size = 10
X = np.random.rand(100, input_size)
T = np.random.rand(100, 1)
# 未优化的KELM
model = KELM(input_size, hidden_size)
model.train(X, T)
pred_unoptimized = model.predict(X)
mse_unoptimized = np.mean((pred_unoptimized - T) ** 2)
# PSO优化的KELM
pop_size = 20
max_iter = 50
lb = -1
ub = 1
optimized_model = pso_optimized_kelm(X, T, input_size, hidden_size, pop_size, max_iter, lb, ub)
pred_optimized = optimized_model.predict(X)
mse_optimized = np.mean((pred_optimized - T) ** 2)
print(f"未优化KELM的均方误差: {mse_unoptimized}")
print(f"PSO优化KELM的均方误差: {mse_optimized}")从结果中可以看到,通常情况下,经过PSO优化后的KELM会有更低的均方误差,说明PSO优化能够提升KELM在多维输入单维输出数据上的性能表现。这是因为PSO帮助KELM找到了更合适的输入权值和隐含层偏置,使得模型能够更好地拟合数据。
总的来说,利用PSO优化KELM为我们处理多维输入单维输出数据提供了一种有效的方法,在实际应用中可以根据具体需求进一步调整参数,以达到更好的效果。希望这篇博文能让大家对PSO优化KELM有更深入的了解,快去试试吧!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)