JDK8新特性
JDK 8(Java Development Kit 8)是 Java 发展史上最具里程碑意义的版本,被广泛认为是自 JDK 5 以来最重要的更新。即使在多年后的今天,JDK 8 依然是企业级开发中最主流的版本之一。
我为你将 JDK 8 的特性梳理为以下五大核心板块
Lambda 表达式与函数式编程
这是 JDK 8 最具标志性的特性,它让 Java 代码变得更加简洁、可读性更高。
Lambda 表达式
Lambda 表达式,也可称为闭包,它是推动 Java 8 发布的最重要新特性。Lambda 允许把函数作为一个方法的参数(函数作为参数传递进方法中)。使用 Lambda 表达式可以使代码变的更加简洁紧凑。
示例
首先定义三个接口,每个接口都包含一个方法
public interface MathOperation {
int operation(int a, int b);
}
public interface PlaceOperation {
void operation(String str);
}
public interface MessageOperation {
String operation(String str);
}测试类
public static void main(String[] args) {
MathOperation mathOperation = (a, b) -> a + b;
int operation = mathOperation.operation(1, 4);
System.out.println(operation);
PlaceOperation placeOperation = str -> System.out.println(str);
placeOperation.operation("我是谁?");
MessageOperation messageOperation = (str) -> {
System.out.println("hello" + str);
return "写完了";
};
String operation2 = messageOperation.operation("java");
System.out.println(operation2);
}运行结果

tips
lambda 表达式只能引用标记了 final 的外层局部变量,这就是说不能在 lambda 内部修改定义在域外的局部变量,否则会编译错误。
我们也可以直接在 lambda 表达式中访问外层的局部变量:lambda 表达式的局部变量可以不用声明为 final,但是必须不可被后面的代码修改(即隐性的具有 final 的语义)
int num = 1;
Converter<Integer, String> s = (param) -> System.out.println(String.valueOf(param + num));
s.convert(2);
num = 5;
//报错信息:Local variable num defined in an enclosing scope must be final or effectively
// final在 Lambda 表达式当中不允许声明一个与局部变量同名的参数或者局部变量。
String first = "";
Comparator<String> comparator = (first, second) -> Integer.compare(first.length(), second.length());
//编译会出错 函数式接口
在接口上添加注解@FunctionalInterface,这样做可以检查它是否是一个函数式接口,同时javac也会包含一条声明,说明这个接口是函数接口。
@FunctionalInterface
public interface MyInter {
void getOut();
}
//接口中使用泛型
@FunctionalInterface
public interface MyInter<T> {
T getOut(T t);
}其他类型的接口
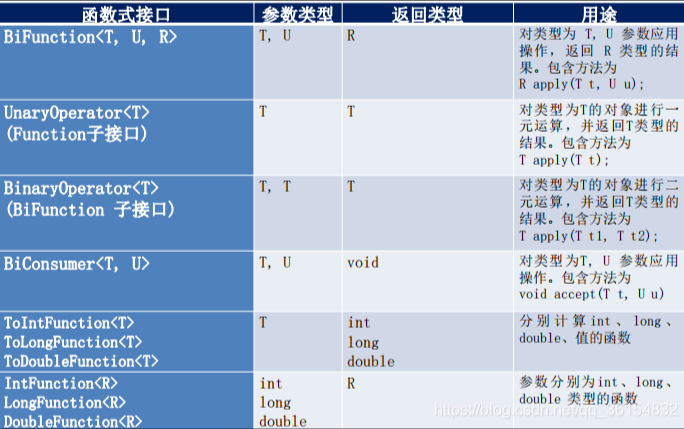
方法引用
当 Lambda 表达式只是简单地调用一个现成的方法时,可以用方法引用(::)来进一步简化代码;
//示例:类名::方法名 或 对象::实例方法名。
System.out::println 代替 (x) -> System.out.println(x)。接口的默认方法和静态方法
接口中可以包含带有实现的方法(使用 default 关键字)。这使得接口可以在不破坏现有实现类的前提下进行升级,接口中也可以定义静态方法,直接通过接口名调用。
为了让你更直观地理解,我为你编写了一个完整的示例。我们将创建一个接口,并展示如何在不修改旧有实现类的情况下,通过 default 方法给接口增加新功能。
假设我们有一个 Vehicle(交通工具)接口。起初,它只有一个抽象方法 start()。后来,我们想给所有交通工具增加一个“鸣笛”的功能 honk(),但我们不想去修改所有已经实现了 Vehicle 接口的类(比如 Car 和 Bike)。
// 1. 定义接口:Vehicle
interface Vehicle {
// 抽象方法(以前的传统写法)
void start();
// ==========================================
// ✅ 新特性 1:Default 默认方法
// ==========================================
// 这个方法有具体实现,且使用了 default 关键字
// 实现类如果不重写这个方法,就会使用这里的默认实现
default void honk() {
System.out.println("Vehicle is making a sound... 嘟嘟!");
}
// ==========================================
// ✅ 新特性 2:静态方法
// ==========================================
// 静态方法属于接口本身,不能被实现类继承或重写
// 只能通过 接口名.方法名 的方式调用
static void describe() {
System.out.println("这是一个描述交通工具的接口,包含默认方法和静态方法。");
}
}
// 2. 实现类 A:汽车
// 注意:这里我们并没有在 Car 类中实现 honk() 方法
class Car implements Vehicle {
@Override
public void start() {
System.out.println("Car is starting... 发动引擎!");
}
// Car 类可以选择重写 default 方法
@Override
public void honk() {
System.out.println("Car is honking... 嘟~~~~嘟~~~~ (汽车喇叭声)");
}
}
// 3. 实现类 B:自行车
// 注意:Bike 类完全没有提到 honk() 方法
class Bike implements Vehicle {
@Override
public void start() {
System.out.println("Bike is starting... 蹬车!");
}
// Bike 使用接口提供的默认 honk() 实现
}
// 4. 测试主类
public class InterfaceExample {
public static void main(String[] args) {
// 调用接口的静态方法
// ⚠️ 注意:只能通过 接口名.方法名 调用
System.out.println("=== 静态方法调用 ===");
Vehicle.describe();
System.out.println("\n=== 实例方法测试 ===");
Vehicle car = new Car();
Vehicle bike = new Bike();
// --- 测试抽象方法 start() ---
car.start(); // 输出: Car is starting...
bike.start(); // 输出: Bike is starting...
System.out.println("---");
// --- 测试 Default 方法 honk() ---
// Car 重写了 honk,所以执行 Car 的版本
car.honk(); // 输出: Car is honking... 嘟~~~~嘟~~~~
// Bike 没有重写 honk,所以执行接口默认的版本
bike.honk(); // 输出: Vehicle is making a sound... 嘟嘟!
}
}Stream 流式数据处理
JDK 8 引入的 Stream API 确实是 Java 开发史上的一次“革命”。它彻底改变了我们处理集合数据的方式——从以前的“告诉 JVM 怎么做”(命令式编程,写 for 循环),转变为“告诉 JVM 做什么”(声明式编程,写 SQL 风格的语句)。简单来说,Stream 不是集合,而是一种“计算流程”或“管道”。以下我为你详细拆解 Stream API 的核心概念、操作类型以及实战用法。
核心概念:Stream 到底是什么?
在深入代码之前,你需要理解 Stream 的三个核心特征:
- 不存储数据:Stream 本身不保存元素,它只是对数据源(集合、数组)进行计算的“视图”。
- 不可变性:Stream 操作不会修改原始数据源。例如
filter过滤后,原集合还在,返回的是一个全新的 Stream。 - 惰性求值:中间操作(如
filter)不会立即执行,只有当终端操作(如collect)被调用时,整个流水线才会“开闸放水”,一次性执行完成。
三大操作步骤
使用 Stream API 通常遵循以下三个步骤
1. 创建 Stream(数据源)
你需要一个起点,常见的数据源有集合、数组等。
// 1. 从集合创建(最常用)
List<String> list = Arrays.asList("a", "b", "c");
Stream<String> stream = list.stream();
// 2. 从数组创建
String[] arr = {"a", "b", "c"};
Stream<String> arrayStream = Arrays.stream(arr);
// 3. 使用 of 静态方法
Stream<String> ofStream = Stream.of("a", "b", "c");
// 4. 生成无限流(需配合 limit 使用)
Stream<Integer> infiniteStream = Stream.iterate(0, n -> n + 1); // 迭代
Stream<Double> randomStream = Stream.generate(Math::random); // 生成2. 中间操作(加工处理)
中间操作是“流水线”上的工序,它们会返回一个新的 Stream,支持链式调用。因为它们是惰性的,所以此时代码并没有运行。
| 方法 | 作用 | 示例 |
|---|---|---|
filter(Predicate) |
过滤:保留符合条件的元素 | stream.filter(s -> s.length() > 3) |
map(Function) |
映射:将元素转换成另一种形式 | stream.map(String::toUpperCase) |
flatMap(Function) |
扁平化:将流中的每个元素“摊平”并合并成一个流 | 将二维列表转为一维 |
distinct() |
去重:根据 hashCode() 和 equals() 去除重复元素 |
stream.distinct() |
sorted() |
排序:自然排序或自定义排序 | stream.sorted((a, b) -> b - a) |
limit(n) |
截断:使元素数量不超过 n 个 | stream.limit(10) |
skip(n) |
跳过:跳过前 n 个元素 | stream.skip(2) |
3. 终端操作(消费结果)
终端操作是流水线的终点。一旦执行终端操作,中间操作链才会真正开始计算,计算完成后该 Stream 就被“消费”掉了,不可复用34。
- 聚合操作:
count()、max()、min()、findFirst()、anyMatch()。 - 遍历操作:
forEach()。 - 收集操作(最常用):
collect()。它可以将流转换回集合、字符串等。
实战:代码对比
为了让你感受 Stream 的威力,我们来看一个经典的例子:
需求:从一个用户列表中,筛选出年龄大于 18 岁的用户,提取他们的姓名,转换为大写,并按字母排序,最后收集到一个新的列表中。
方式一:JDK 7 传统写法(命令式)
代码冗长,且充斥着“怎么做”的模板代码(循环、if 判断、集合初始化)。
List<String> result = new ArrayList<>();
for (User user : userList) {
if (user.getAge() > 18) {
result.add(user.getName().toUpperCase());
}
}
Collections.sort(result);方式二:JDK 8 Stream 写法(声明式)
代码简洁,逻辑清晰,一眼就能看出业务意图。
List<String> result = userList.stream() // 1. 获取流
.filter(user -> user.getAge() > 18) // 2. 中间操作:过滤
.map(user -> user.getName().toUpperCase()) // 2. 中间操作:映射+转大写
.sorted() // 2. 中间操作:排序
.collect(Collectors.toList()); // 3. 终端操作:收集结果高阶特性
1. 并行流
如果你的数据量非常大,想利用多核 CPU 的性能,只需将 stream() 改为 parallelStream(),或者在流上调用 .parallel()。
// 自动利用 Fork/Join 框架进行多线程并行处理
long count = list.parallelStream()
.filter(s -> s.length() > 3)
.count();注意:并行流不是万能的,如果操作涉及线程安全问题(如修改共享变量),或者数据量很小,使用并行流反而会因为线程开销导致性能下降410。
2. Optional 与 Stream 结合
Stream 中经常出现 findFirst()、findAny() 等方法,它们返回的是 Optional<T>,这能有效避免空指针异常。
Optional<String> first = list.stream()
.filter(s -> s.startsWith("A"))
.findFirst();
// 安全地获取值或提供默认值
String result = first.orElse("Default Value");3. Collectors 收集器
Collectors 类提供了非常强大的归约功能,是 Stream 的“瑞士军刀”。
- 分组:
Collectors.groupingBy(User::getCity)// 按城市分组 - 分区:
Collectors.partitioningBy(User::isAdult)// 按是否成年分区 - 连接字符串:
Collectors.joining(", ")// 将元素用逗号连接
总结
Stream API 的核心价值在于:代码优雅:链式调用,可读性强,像写 SQL 一样处理数据;性能优化:惰性求值机制会优化中间过程,减少不必要的内存占用;易于并行:轻松切换并行流,无需手动管理线程。在日常开发中,当你面对复杂的集合处理逻辑时,优先考虑使用 Stream API。
java.time新的日期时间 API
JDK 8 引入了一套全新的日期和时间 API(java.time 包),这套 API 是为了解决旧版 java.util.Date 和 java.util.Calendar 存在的线程安全问题、设计混乱以及时区处理麻烦等缺陷而设计的。这套新 API 的设计灵感来自于 Joda-Time 库,遵循了不可变对象、函数式编程和职责分离的原则。
以下我为你详细介绍 JDK 8 中最核心的时间类及其用法。
核心思想与特点
- 不可变性(Immutable):所有的核心类(如 LocalDateTime, LocalDate)都是 final 的,一旦创建就不能修改。任何修改操作(如加减日期)都会返回一个新的对象,这保证了线程安全。
- 职责分离:将日期(LocalDate)、时间(LocalTime)、日期+时间(LocalDateTime)拆分为不同的类,而不是像旧版 Date 那样混杂在一起。
- ISO-8601 标准:默认遵循国际标准格式(例如 yyyy-MM-dd)。
以下是 java.time 包中最常用的类
| 类名 | 作用 | 格式示例 | 适用场景 |
|---|---|---|---|
LocalDate |
仅表示日期(年月日) | 2024-05-12 |
生日、纪念日等不需要时间的场合 |
LocalTime |
仅表示时间(时分秒) | 16:38:54.158 |
记录一天中的某个时刻 |
LocalDateTime |
日期+时间(最常用) | 2024-05-12T16:38:54.158 |
替代旧版 Date,用于记录事件发生的时间 |
ZonedDateTime |
带时区的日期时间 | 2024-05-12T16:38:54.158+08:00[Asia/Shanghai] |
需要处理全球不同时区的业务 |
Instant |
时间戳(瞬时点) | 2024-05-12T08:38:54.158Z |
机器时间,用于记录日志、时间戳计算 |
Duration |
时间间隔(秒/纳秒) | - | 计算两个时间点之间的差(如耗时) |
Period |
日期间隔(年/月/日) | - | 计算两个日期之间的差(如年龄) |
DateTimeFormatter |
日期格式化与解析 | - | 替代旧版 SimpleDateFormat,线程安全 |
JVM 与底层架构优化
JDK 8 在虚拟机层面做了一些影响深远的改动,主要是为了解决内存溢出问题。
元空间取代永久代:
旧版:JDK 7 及之前使用“永久代”存储类的元数据,容易出现 java.lang.OutOfMemoryError: PermGen space 错误。
新版:JDK 8 移除了永久代,引入了元空间。元空间使用的是本地内存(Native Memory),不再占用 JVM 的堆内存,从而大大减少了内存溢出的风险。
新的垃圾回收器:
G1 收集器:虽然 G1 在 JDK 7 中已引入,但在 JDK 8 中得到了广泛应用和优化。它旨在替代 CMS 收集器,适合大内存、多核处理器的机器,能提供更可控的停顿时间。
其他重要特性与工具
| 特性 | 描述 |
|---|---|
| Optional 类 | 一个容器对象,用于优雅地处理 null 值,强制开发者显式地处理空指针情况,从而避免 NullPointerException。 |
| Nashorn JavaScript 引擎 | 取代了旧的 Rhino 引擎,提供了在 JVM 上运行 JavaScript 代码的能力,且性能更好。 |
| HashMap 优化 | 当链表长度超过阈值(默认为 8)时,链表会转换为红黑树,将查询时间从 O(n) 优化到 O(log n),极大地提升了极端情况下的性能。 |
| Base64 支持 | 在标准库中内置了 Base64 编码和解码的支持,不再需要依赖第三方库。 |
总结
JDK 8 的核心在于“化繁为简”和“与时俱进”。
Lambda + Stream 让你的业务逻辑代码行数减少一半,且更具可读性。
java.time 解决了困扰 Java 开发者多年的日期处理痛点。
Metaspace 解决了运维层面的内存溢出隐患。
如果你正在使用或计划深入学习 Java,掌握 JDK 8 的这些特性(特别是 Lambda、Stream 和新日期 API)是绝对必要的基础。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)