与时俱进 |V2A技术(Video to Audio)
谷歌DeepMind推出的V2A技术通过AI分析视频内容生成同步音轨,实现了视觉到听觉的跨模态转换。该技术采用扩散模型和预训练映射网络,显著提升了音频生成质量和效率。主要应用于影视制作、内容修复、游戏开发等领域,能自动生成背景音乐、环境音效等。尽管面临视频质量依赖、唇形同步等挑战,但通过模型轻量化、精细控制等优化方向,V2A技术正推动AIGC在音视频融合领域的发展。
V2A技术是由谷歌DeepMind率先推出的技术,通过分析视频像素并辅以文本提示,为无声视频生成丰富、同步的音轨。
目录
一、什么是V2A技术?
视频到音频生成技术,简称V2A,是一种将视觉信息转换为对应音频信号的人工智能技术。它的核心任务是理解视频内容,并生成与之在语义和时间上对齐的高质量音频。
在当前的AIGC浪潮中,视频生成模型发展迅速,但多数只能产生无声输出。为这些视频创建合适的音轨,是实现生成电影生命力的关键一步。
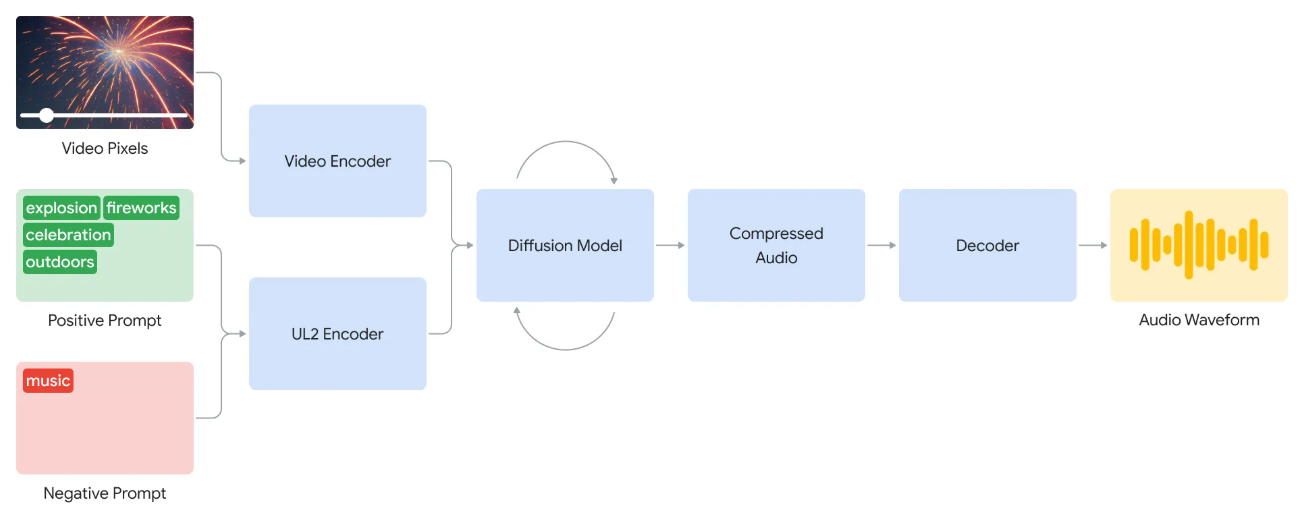
V2A技术并非简单的“看图说话”,而是需要模型理解视频中的动态变化、物体运动、场景特征以及事件逻辑,然后将这些视觉信息映射到相应的声音特性上。
从技术发展路径来看,早期方法倾向于从零开始构建复杂系统,使用规模有限的数据集进行训练。而最新研究则转向利用已有的大规模预训练模型,构建更高效、更轻量的解决方案。

二、核心原理与模型演进
V2A技术的核心挑战在于如何弥合视觉与听觉两种模态之间的“语义鸿沟”。视觉信息传达的是空间、形状、颜色和运动,而听觉信息则关乎时间、频率、音色和节奏。
目前的先进方法主要采用了多层映射和条件生成的技术路线,将视觉特征逐步转化为音频信号。
跨模态语义对齐是关键技术环节。研究人员发现,不同模态的预训练模型(如CLIP用于视觉,CLAP用于音频)虽然各自在其领域表现出色,但它们的潜在空间存在显著差异,这就是所谓的“域间鸿沟”。
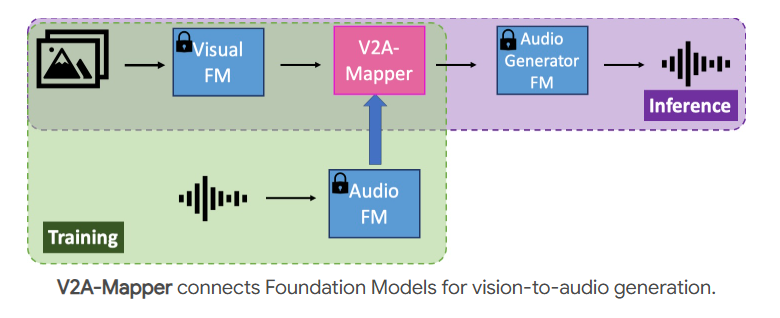
为解决这一问题,V2A-Mapper提出了一种轻量级的映射机制,专门负责在CLIP和CLAP两种表示空间之间进行翻译。这种方法只需训练映射网络,而无需重新训练整个音频生成模型,极大降低了计算成本。
从模型架构演进的角度看,目前主流V2A方法可分为三类:
| 模型名称 | 核心创新 | 技术特点 | 性能优势 |
|---|---|---|---|
| V2A-Mapper | 连接视觉与音频基础模型 | 轻量映射网络,分离训练与生成 | 减少86%参数,FD提升53%,CS提升19% |
| DeepMind V2A | 视频像素直接理解 | 扩散模型生成,支持文本提示引导 | 生成高保真、同步音频,无需手动对齐 |
| Stable-V2A | 两阶段生成控制 | RMS-Mapper + Stable-Foley,精确时间控制 | 优化语义和时间对齐,音效合成质量高 |
| ThinkSound | 思维链推理机制 | 多阶段解析画面内容,结构化音频生成 | 在VGGSound测试集上多项指标提升15%以上 |
扩散模型成为音频生成的主流选择。在实验中,研究人员发现基于扩散的方法在音频生成方面提供了最真实和引人入胜的结果,能够有效同步视频和音频信息。
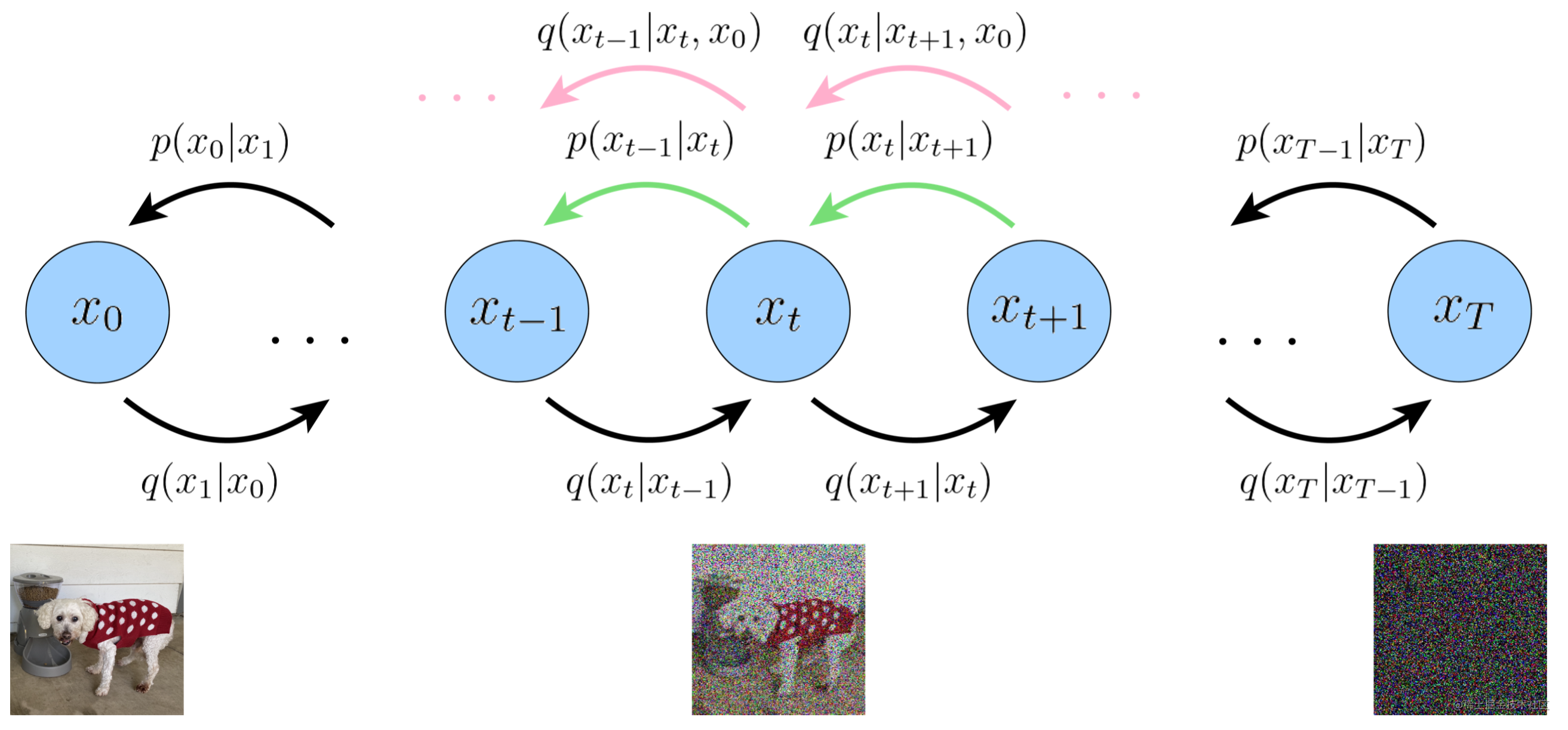
扩散模型的工作原理是通过一个迭代优化过程,从随机噪声中逐步生成音频,每一步都受到视觉输入和可能的文本提示引导,确保最终输出与视频内容高度相关。
最新的研究如阿里ThinkSound模型,首次将思维链技术应用于音频生成领域,解决了现有V2A技术对画面动态细节和事件逻辑理解不足的问题。[模型信息,详见于:\N]
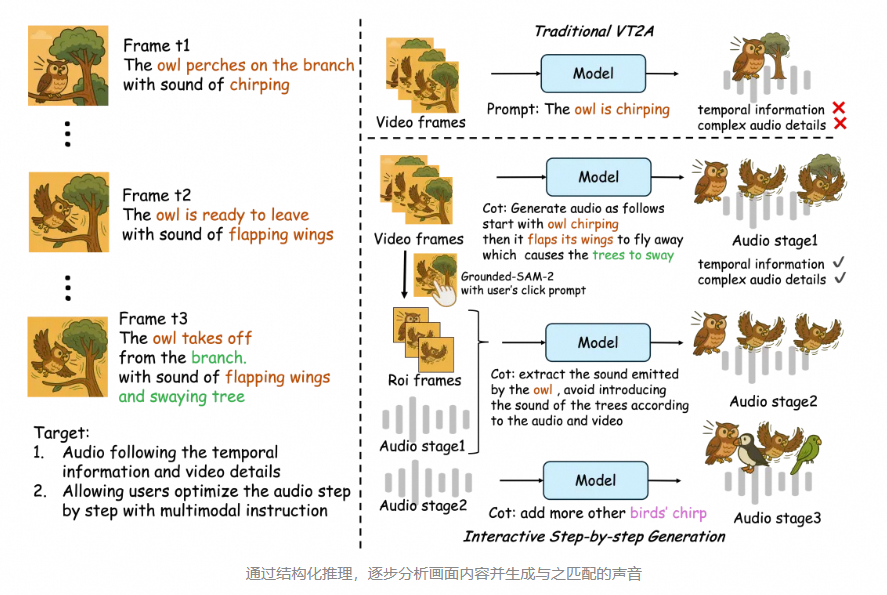
该模型由多模态大语言模型负责推理,统一音频生成模型负责输出声音,能够按照“理解整体画面 - 聚焦具体物体 - 响应用户指令”三个阶段逐步解析画面内容,生成精准对位的音频效果。
三、关键应用场景
电影与视频制作领域是V2A技术最直接的应用场景。传统的音效制作流程复杂且耗时,需要声音设计师寻找合适素材,并手动调整与画面的同步;而V2A系统能够为无声视频自动生成背景音乐、环境音效甚至角色对话,大幅提升了音效制作的效率。

更重要的是,V2A技术可以为任何视频输入生成无限数量的音轨,创作者可以通过定义“正向提示”来引导生成所需的声音,或使用“负向提示”来避免不需要的声音。
这种灵活性让电影制作人能够快速试验不同的音效组合,找到最匹配其创作意图的声音方案。
内容修复与增强、游戏和虚拟现实领域同样受益于V2A技术。历史档案视频、无声电影等珍贵资料往往缺少原始音轨或音质较差。通过V2A技术,这些历史材料可以被赋予新的生命,根据画面内容生成符合时代背景和环境特征的音频,增强观看体验。
在这些游戏和虚拟现实场景中,需要大量与环境、动作、事件相对应的音效,传统方法需要预先录制或制作大量音频素材;而V2A技术能够根据实时生成的视觉内容动态产生合适的音效,显著提升了沉浸感和真实感。
| 应用领域 | 主要应用场景 | 技术价值 | 典型案例 |
|---|---|---|---|
| 影视制作 | 音效自动生成,背景音乐创作 | 提升创作效率,提供多样化选择 | 为无声视频生成同步音轨 |
| 内容修复 | 历史影像声音恢复,老电影音轨制作 | 文化保护,提升观看体验 | 无声电影添加环境音效 |
| 游戏与VR | 实时音效生成,环境声音模拟 | 增强沉浸感,减少预制作内容 | 根据玩家动作生成相应音效 |
| 安防监控 | 监控视频声音还原,异常声音检测 | 丰富信息维度,提升分析能力 | 为无声监控视频生成环境声 |
| 创意工具 | 社交媒体内容创作,个人视频编辑 | 降低创作门槛,激发创意表达 | 为短视频添加创意音效 |
四、技术实践挑战
V2A技术目前也面临着挑战。例如,音频输出质量依赖于视频输入质量,当视频中包含超出模型训练分布的伪影或失真时,音频质量可能会显著下降。
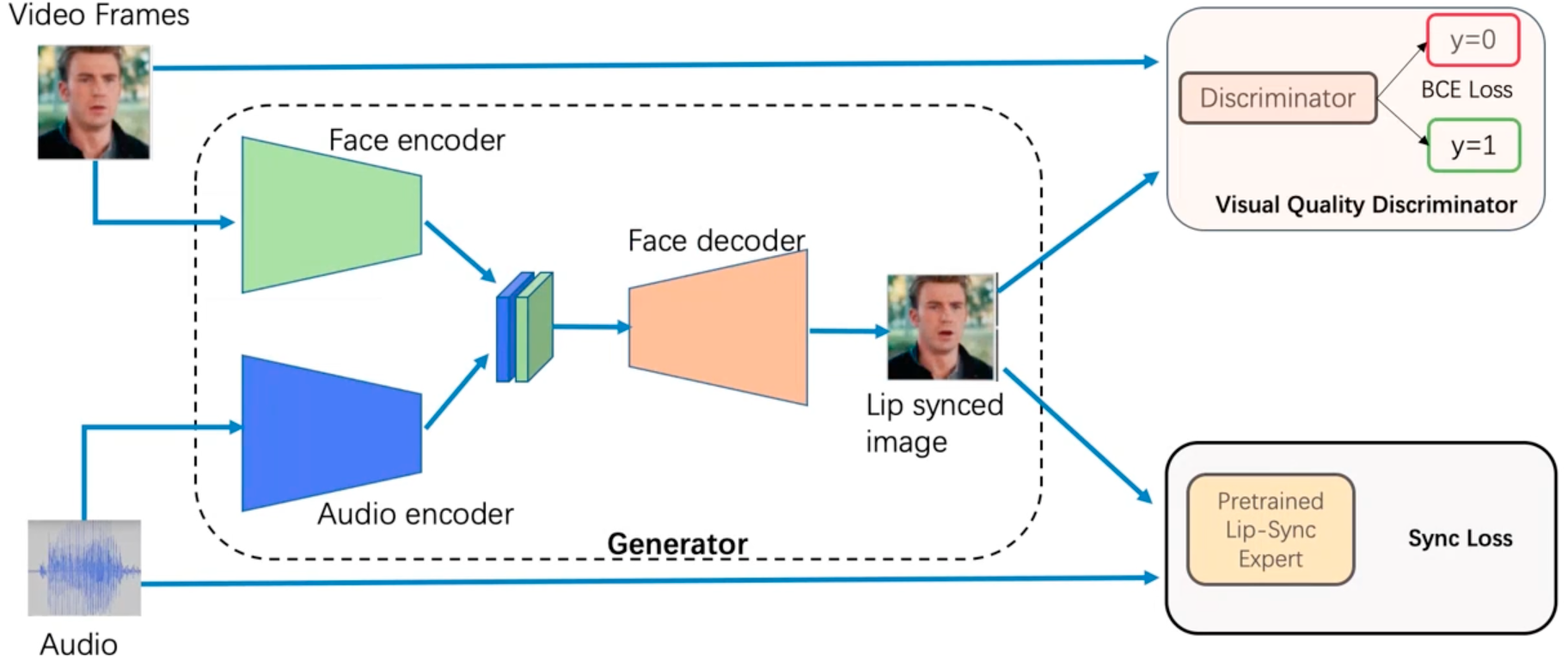
对于涉及语音的视频,唇形同步也是技术难点之一——V2A尝试从输入转录生成语音并将其与角色唇部动作同步,但若视频生成模型没有以转录为条件,就会造成不匹配,导致不自然的唇形同步。
随着技术不断发展,V2A领域的模型轻量化和效率提升是研究的首要方向。如V2A-Mapper所示,通过连接现有基础模型而非从零开始训练,可以大幅减少参数数量和训练成本,使技术更加实用和可部署。
新一代V2A系统不仅支持文本提示,还引入更精细的控制机制。如Stable-V2A通过RMS包络实现时间控制,通过音频嵌入实现语义控制,为声音设计师提供了更精细的调节手段。
另外,数据集和评估标准的完善也是未来发展的关键,而安全和责任同样是重点考虑。一些研究团队已经将水印技术集成到V2A系统中,如DeepMind将SynthID工具包集成到V2A研究中,为所有AI生成的内容添加水印。
在考虑向更广泛公众开放访问之前,V2A技术需要经过严格的安全评估和测试,确保其不会被滥用。
SPIE会议征稿中:CIMSP 2026
我们诚挚发起本次“2026年智能计算与多模态信号处理国际学术会议 (CIMSP 2026)”的征稿,旨在汇聚全球顶尖学者、研发工程师与青年学子,共同搭建一个深度交流、碰撞思想、孕育合作的高端平台。

【组织单位】浙江大学伊利诺伊大学厄巴纳香槟校区联合学院(ZJUI)、信德农业大学信息技术中心、波兰技术与艺术大学(ATA)、新加坡机器人学会(RSS)
【会议出版】所有论文将由会议委员会的2-3名专家评审员进行评审。经过仔细的审查过程,所有被接受的论文都将发表在SPIE-The International Society for Optical Engineering《会议论文集》上,并提交给EI Compendex和Scopus进行索引。
【审稿流程】投稿 (全英WORD+PDF) - 稿件收到确认 (1个工作日) - 初审 (3个工作日内) - 告知结果 (接受/拒稿)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 24
24 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)