在移动端如何部署本地知识库+大模型
Phi-2 / Phi-3-mini(Microsoft):参数量小(2.7B/3.8B),性能强,支持 INT4 量化。Gemma-2B / Gemma-1.1B(Google):支持 GGUF 格式,适合 llama.cpp。Llama-3-8B-Instruct(量化版):若设备性能较强(如高端手机),可用 4-bit 量化版本。将知识文档切片 → 使用轻量嵌入模型(如 all-MiniLM
在移动端部署本地知识库 + 大模型,主要目标是在设备上(如手机、平板)实现离线问答、语义理解、内容生成等功能。由于移动端资源有限(CPU/GPU 性能、内存、存储),需要对模型和知识库进行轻量化处理,并选择合适的推理框架。以下是完整的部署思路与技术方案:

- 整体架构
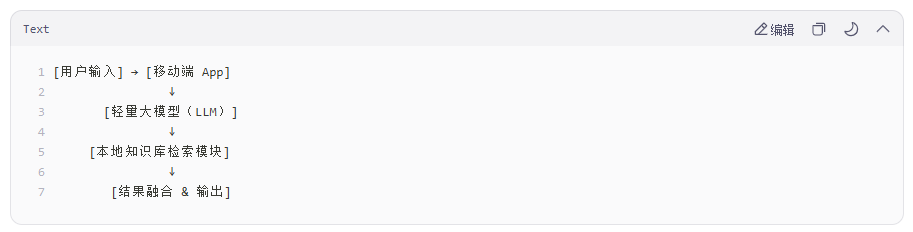
- 关键技术选型
1. 轻量级大模型(On-device LLM)
推荐使用以下开源、可量化、支持移动端推理的模型:
Phi-2 / Phi-3-mini(Microsoft):参数量小(2.7B/3.8B),性能强,支持 INT4 量化。
TinyLlama(1.1B):专为边缘设备优化。
Gemma-2B / Gemma-1.1B(Google):支持 GGUF 格式,适合 llama.cpp。
Qwen-1.8B / Qwen-0.5B(通义千问):中文友好,支持量化。
Llama-3-8B-Instruct(量化版):若设备性能较强(如高端手机),可用 4-bit 量化版本。
2. 推理引擎(Runtime)
选择支持移动端、低延迟、低内存占用的推理框架:
|
框架 |
支持平台 |
特点 |
|
llama.cpp |
Android/iOS(C++) |
支持 GGUF 模型,纯 CPU 推理,社区活跃 |
|
MLC LLM |
Android/iOS/Web |
Apache TVM 后端,支持 Vulkan/Metal 加速 |
|
Core ML |
iOS |
Apple 官方,支持 Metal GPU 加速 |
|
TensorFlow Lite |
Android/iOS |
适合小型 Transformer,需转换模型 |
|
ONNX Runtime Mobile |
Android/iOS |
支持 ONNX 模型,可 CPU/GPU |
3. 本地知识库构建
方案 A:向量数据库 + 语义检索(RAG)
将知识文档切片 → 使用轻量嵌入模型(如 all-MiniLM-L6-v2)生成向量 → 存入本地向量库。
移动端嵌入模型可使用:
Sentence-BERT (MiniLM):约 80MB,支持 ONNX/TFLite。
bge-m3 / bge-small-zh(中文优化)。
向量存储:
FAISS-mobile(Facebook 开源,支持 iOS/Android)
HNSWLib(轻量近似最近邻)
SQLite + 向量扩展(如 SQLite with vector extension)
注意:嵌入模型也需量化或裁剪以适应移动端。
方案 B:关键词/规则匹配(简单场景)
若知识结构化程度高(如 FAQ),可用 SQLite + 全文搜索(FTS5)。
优点:无需嵌入模型,节省资源。
- 部署流程(以 Android 为例)
步骤 1:准备模型

步骤 2:集成 llama.cpp 到 App
使用 CMake 构建 llama.cpp 的 JNI 接口。
将 .gguf 模型文件放入 assets 或外部存储。
调用 llama_eval() 进行推理。
步骤 3:构建本地知识库
预处理知识文档 → 用 MiniLM 生成向量 → 存入 FAISS 索引文件。
App 启动时加载 FAISS 索引到内存。
步骤 4:实现 RAG 流程
用户提问 → 用嵌入模型生成 query 向量。
在 FAISS 中检索 top-k 相关段落。
构造 prompt:"基于以下信息回答问题:{retrieved_text}\n\n问题:{query}"
输入给 LLM 生成答案。

- 性能优化建议
模型量化:优先使用 q4_k_m 或 q5_k_m 平衡速度与精度。
内存管理:避免同时加载多个大模型;使用 mmap 加载模型减少内存占用。
异步推理:在后台线程运行 LLM,避免 UI 卡顿。
缓存机制:缓存常见问题的答案或检索结果。
动态卸载:长时间不用时释放模型内存。
- 参考项目
MLC LLM: https://mlc.ai/mlc-llm/
llama.cpp Android Demo: https://github.com/ggerganov/llama.cpp/tree/master/examples/android
LocalAI on Mobile(实验性)
Ollama Mobile(非官方,探索中)
- 限制与挑战
|
问题 |
说明 |
|
内存限制 |
大多数手机 RAM <8GB,4-bit 7B 模型需 ~6GB 内存 |
|
推理速度 |
CPU 推理 7B 模型约 1~3 token/s(中端机) |
|
存储占用 |
模型 + 向量库可能 >2GB |
|
中文支持 |
优先选择中文预训练模型(如 Qwen、ChatGLM3-6B-int4) |

- 简化方案(低配设备)
如果设备性能较弱(如 4GB RAM):
使用 1B 以下模型(如 Phi-1.5、TinyLlama)
知识库采用 SQLite + 关键词匹配
不使用 RAG,仅依赖模型自身知识

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 15
15 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)